LangChain 实战课- 开篇词 & 启程篇
既然 LangChain 这么棒,又这么新,我们怎么学?谁来指导?不怕!在这门课程中,我为你精心设计了 4 大模块。带你从各个角度把LangChain的精髓吃透。启程篇:从0到1在这个模块中,我会介绍LangChain系统的安装流程,以及如何进行快速的入门操作。同时,详细指导你如何使用LangChain来构建一个基于“易速鲜花”本地知识库的智能问答系统,让你直接感受LangChain强大的功能。基
开篇词|带你亲证AI应用开发的“奇点”时刻
可能你对我并不陌生,这已经是我第三次和极客时间合作课程了,另外我也是书籍《零基础学机器学习》和《数据分析咖哥十话》的作者。现在在新加坡科研局,任职首席研究员,这些年来一直从事AI科研,尤其是大语言模型的研究。我的主要任务就是为最新的AI技术寻找实际应用场景。想必你应该能理解,学术研究与实际应用是两个完全不同的领域,架设它们之间的桥梁是极具挑战的。
然而,当ChatGPT和GPT-4横空出世时,全人类都在为之震撼——通用人工智能的奇点,真的即将来临了吗?作为科研人员,我们也惊喜地发现, 最前沿的AI技术与最实用的落地应用之间的距离,竟然如此之近!
更为关键的是,ChatGPT不仅是技术革命,它还能为企业提供便捷的服务。在类似ChatGPT这样的模型基础上所开发出的应用,可以助力企业优化客户服务、提升客户服务质量、加强市场营销、优化产品设计、改进供应链管理…ChatGPT 所代表的大语言模型落地场景,覆盖千行百业的方方面面。
AI 应用开发——新的历史节点
事实上,没有任何一种突破能够不经历重重失败,不体验一轮轮的痛苦,就能直接展现在人类面前。AI技术自诞生之初直至今日,其发展之路从未一帆风顺——辉煌与寒冬交替,希望与失望交织。现代AI的核心驱动力神经网络,70年间两落三起;自然语言处理技术亦不例外,在ChatGPT和GPT-4出现之前,NLP技术也曾受过质疑,长期经历低谷期。
每一次AI新技术突然流行之时,总会有人发问:这次,会不会又是昙花一现?
在我看来,这次大模型领域的突破的的确确是真切的、清晰可见的。“ChatGPT将引发巨变!” 诸多业界“真大佬”掷地有声地给出了同样肯定的答案。
阿里巴巴集团董事会主席张勇在2023年阿里云峰会宣布:“AI大模型的出现是一个划时代的里程碑,就像工业革命一样,大模型将会被各行各业广泛应用,带来生产力的巨大提升,并深刻改变我们的生活方式。”“ 面向AI时代,所有产品都值得用大模型重新升级。”
英伟达的创始人、CEO黄仁勋也在英伟达 GTC 线上大会上将 ChatGPT 称为AI的 “iPhone时刻”。
更有人认为,“iPhone 时刻”把ChatGPT和大模型的技术影响力和未来前景说小了。其实,这并不是iPhone时刻,而是互联网时刻。因为很多互联网应用比平台都大,而在人工智能基础功能平台上,会成长出超过平台的企业,也就是说, 未来的人工智能应用企业有可能会超过 Apple、微软、谷歌等平台企业。
无论如何,有一点毋庸置疑。我们正站在一个崭新的历史节点上。
在这个节点上,ChatGPT、GPT-4和其他大语言模型为我们提供了新的视角和新的可能性,在大语言模型的基础上,有可能成长出跨平台的企业,改变未来的科技格局。
在这个节点上,LangChain 这个以大模型为引擎的全新应用开发框架从天而降,几乎和 ChatGPT 一起面世。作为程序设计者的我们,现在 可以利用大模型的潜能以及LangChain的便捷,开发出令人惊叹的智能应用。LangChain作为新一代AI开发框架,必将受到程序员的追捧,点燃AI应用开发的新热潮。
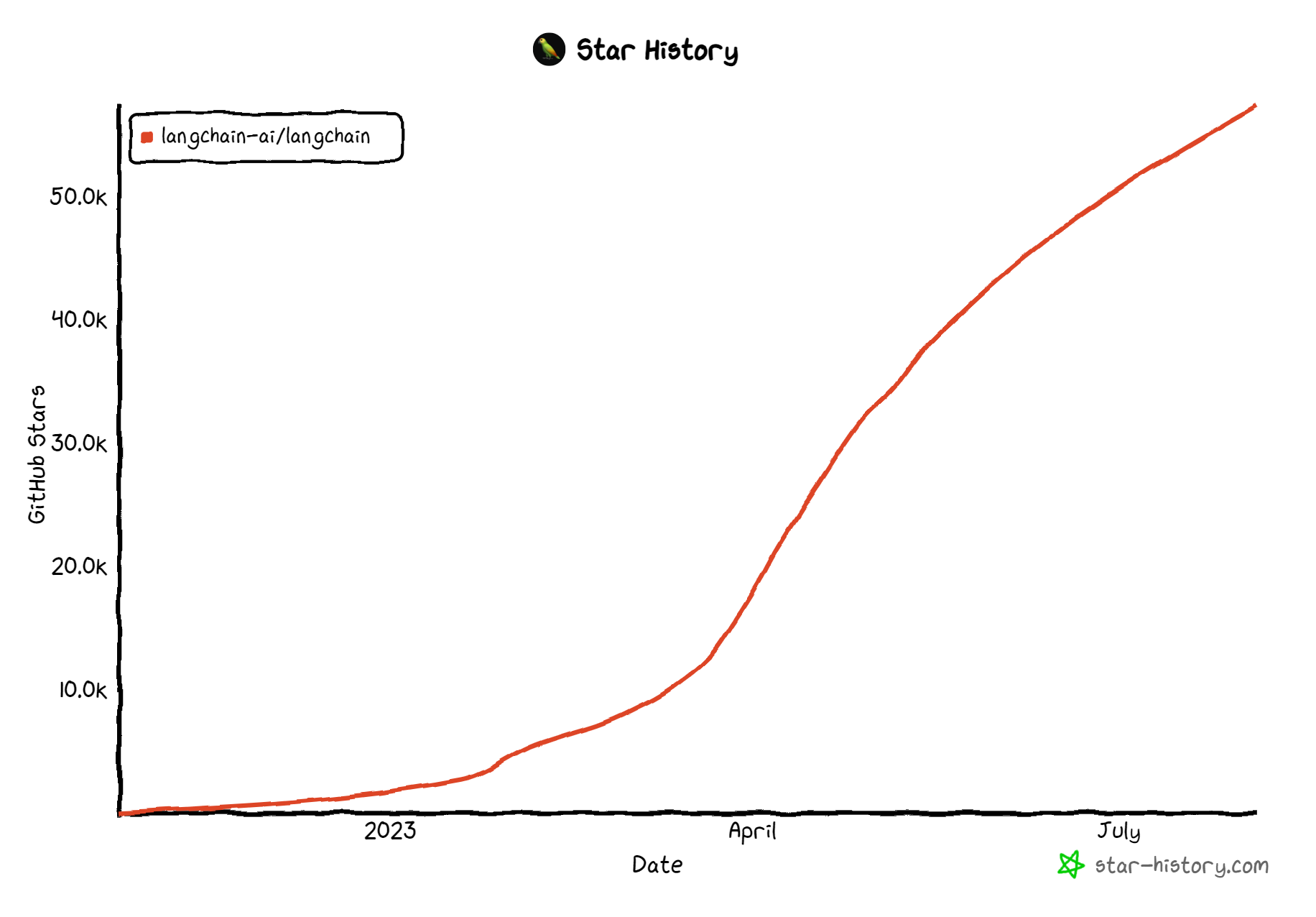
这样的预期,正是我们开设这门课程,以及邀请你来学习这门课程的原因。
何谓 LangChain?释放大语言模型潜能的利器
在这门课程中,我们将共同探索如何使用LangChain。那么如何理解 LangChain 呢?
作为一种专为开发基于语言模型的应用而设计的框架,通过LangChain,我们不仅可以通过API调用如 ChatGPT、GPT-4、Llama 2 等大型语言模型,还可以实现更高级的功能。
我们相信,真正有潜力且具有创新性的应用,不仅仅在于能通过API调用语言模型,更重要的是能够具备以下两个特性:
- 数据感知: 能够将语言模型与其他数据源连接起来,从而实现对更丰富、更多样化数据的理解和利用。
- 具有代理性: 能够让语言模型与其环境进行交互,使得模型能够对其环境有更深入的理解,并能够进行有效的响应。
因此,LangChain框架的设计目标,是使这种AI类型的应用成为可能,并帮助我们最大限度地释放大语言模型的潜能。
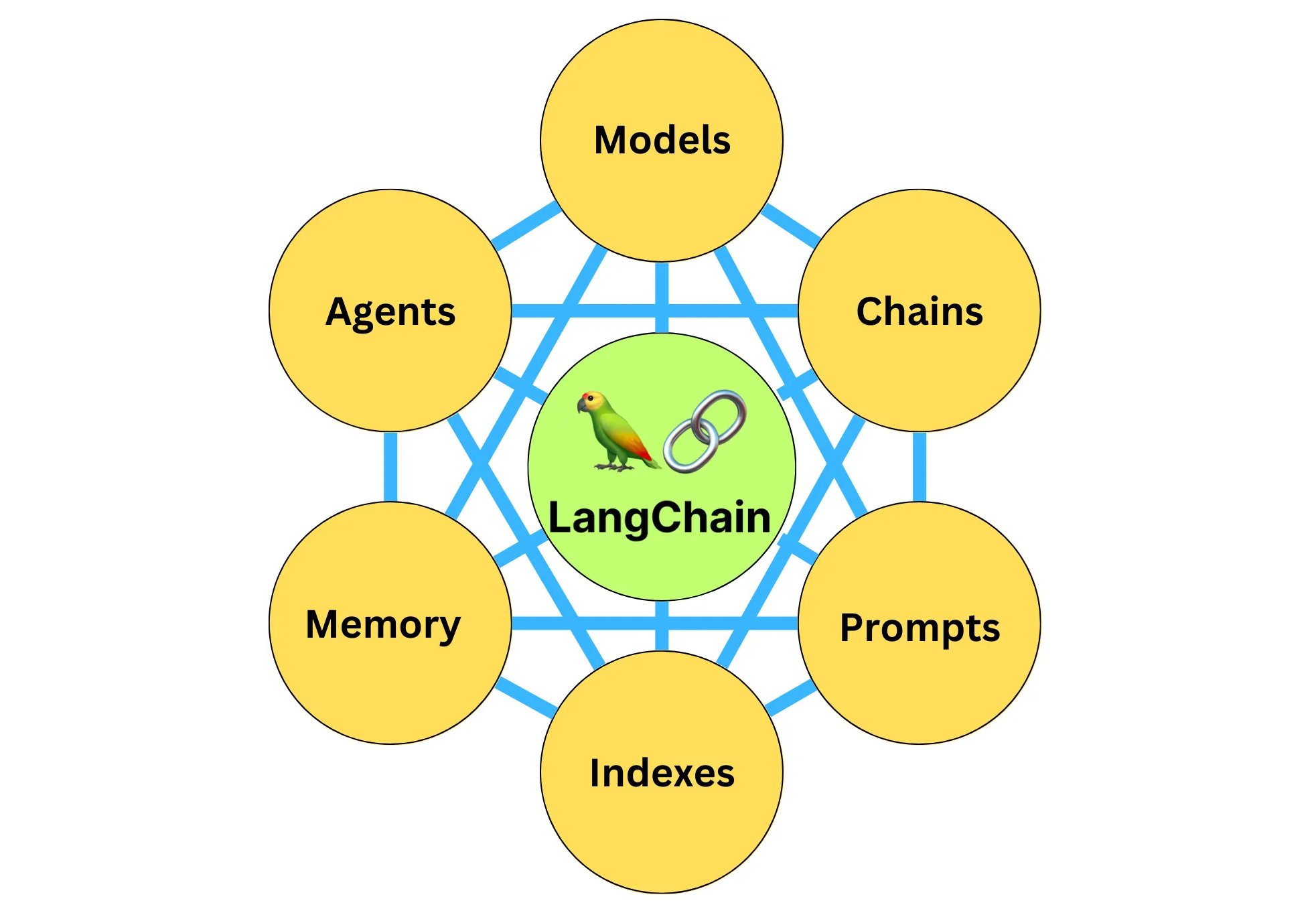
现在你应该已经知道,LangChain是一个基于大语言模型(LLMs)用于构建端到端语言模型应用的框架,它可以让开发者使用语言模型来实现各种复杂的任务,例如文本到图像的生成、文档问答、聊天机器人等。LangChain提供了一系列工具、套件和接口,可以简化创建由LLMs和聊天模型提供支持的应用程序的过程。
打通 LangChain 从原理到应用的最后一公里
既然 LangChain 这么棒,又这么新,我们怎么学?谁来指导?
不怕!在这门课程中,我为你精心设计了 4 大模块。带你从各个角度把LangChain的精髓吃透。
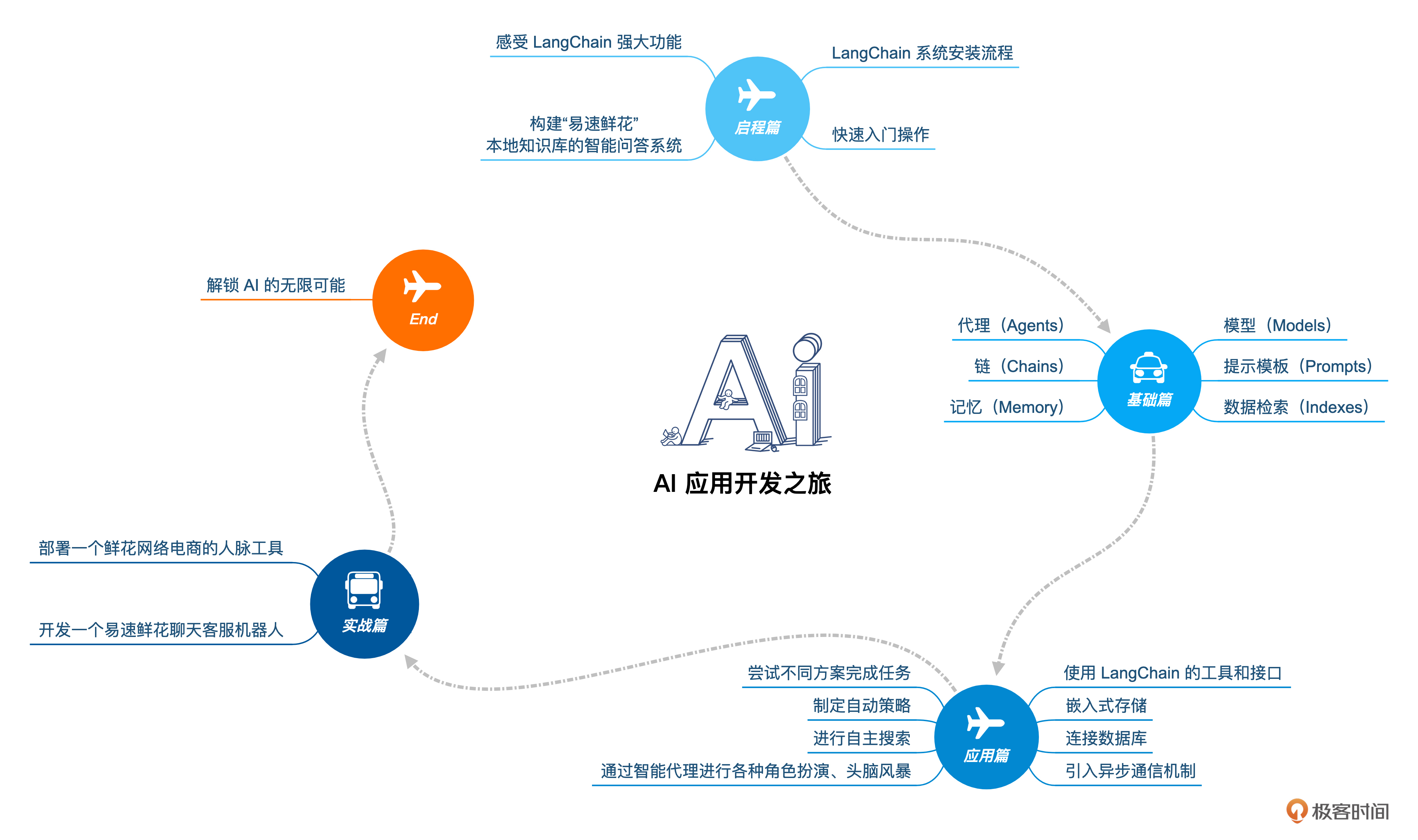
启程篇:从0到1
在这个模块中,我会介绍LangChain系统的安装流程,以及如何进行快速的入门操作。同时,详细指导你如何使用LangChain来构建一个基于“易速鲜花”本地知识库的智能问答系统,让你直接感受LangChain强大的功能。
基础篇:深入 6 大组件
LangChain中的具体组件包括:
- 模型(Models),包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。
- 提示模板(Prompts),使提示工程流线化,进一步激发大语言模型的潜力。
- 数据检索(Indexes),构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。
- 记忆(Memory),通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你是谁。
- 链(Chains),是LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成常见用例。
- 代理(Agents),是另一个LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使强大的“智能化”自主Agent成为可能! 你的 App 将产生自驱力!
这些组件是LangChain的基石,是赋予其智慧和灵魂的核心要素,它们相互协作,形成一个强大而灵活的系统。在基础篇中,我们将深入探索这些组件的工作原理和使用方法,并给出大量用例,夯实你对这些组件的理解和应用能力。
应用篇 :积累 场景中的智慧
在这个模块中,我们会展示如何将LangChain组件应用到实际场景中。你将学会如何使用LangChain的工具和接口,进行嵌入式存储,连接数据库,引入异步通信机制,通过智能代理进行各种角色扮演、头脑风暴,并进行自主搜索,制定自动策略,尝试不同方案完成任务。
我们将不仅仅是讲解这些组件的功能,还会通过实际应用场景来展示它们是如何互相配合,共同完成复杂任务的。本模块中的很多机制都来源于最新论文,其中对AI智能代理机制的各种使用方式将令你大开脑洞,或许你会哈哈一笑,或许你会击节赞叹,钦佩设计者思路之清奇。
实战篇 : 动手!
你将学习如何部署一个鲜花网络电商的人脉工具,并开发一个易速鲜花聊天客服机器人。从模型的调用细节,到数据连接的策略,再到记忆的存储与检索,每一个环节都是为了打造出一个更加智能、更加人性化的系统。
至此,你将能够利用LangChain构建出属于自己的智能问答系统,不论是用于企业的应用开发,还是个人的日常应用,都能够得心应手,游刃有余。
LangChain 有趣用例抢先看
也许,你已经听说过太多大语言模型和LangChain的神奇妙用,迫不及待地想见识见识。那样也好,百闻不如一见,下面我就给你展示两个使用大语言模型和LangChain的具体应用,一起来看看它有多好用。
在我上一个专栏 《零基础实战机器学习》中,我创建了一个虚拟的电商平台“易速鲜花”,并围绕着这个电商场景,构建了很多机器学习应用,如销售量预测、渠道优化、A/B测试、推广裂变策略等等。在《LangChain实战课》中,咱们就继续运营“易速鲜花”,看看大语言模型能够帮我们做些什么。当然,这两门课内容上是完全独立的,没看过另一门也不要紧,并不影响你从这里的起步。
应用1:情人节玫瑰宣传语
情人节到啦,你的花店需要推销红色玫瑰,那么咱们让大语言模型做的第一个应用,就是给咱们生成简短的宣传语。
这个需求极为简单,你直接去ChatGPT网站,或者用文心一言、星火认知等大模型,都做得到。不过,怎样通过LangChain来用程序的方式实现呢?也很容易。
第一步是安装两个包,通过 pip install langchain 来安装LangChain,通过 pip install openai 来安装OpenAI。
第二步,你还需要在OpenAI网站注册属于自己的OpenAI Key。(当然,LangChain也支持其他的开源大语言模型,但是推理效果没有GPT那么好,所以我们这个课程里面的大多数示例都是用OpenAI的GPT系列模型来完成。)
完成了上面两个步骤,就可以写代码了。
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI Key'
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003",max_tokens=200)
text = llm("请给我写一句情人节红玫瑰的中文宣传语")
print(text)
这里,我们先导入了OpenAI的API Key,然后从LangChain中导入OpenAI的Text模型接口,并初始化这个大语言模型,把我们的需求作为提示信息,传递给大语言模型。
运行程序,我得到了好几个漂亮的文案。而且每次运行都会有新的惊喜。
你也许会觉得,这个应用太简单了,直接去大模型的网页上问更方便。的确如此,那下面我们再来一个无法直接在网页上完成的应用。
应用2:海报文案生成器
你已经制作好了一批鲜花的推广海报,想为每一个海报的内容,写一两句话,然后post到社交平台上,以期图文并茂。
这个需求,特别适合让AI帮你批量完成,不过,ChatGPT网页可不能读图。下面,我们就用LangChain的“代理”调用“工具”来完成自己做不到的事情。

我们就用一段简单的代码实现上述功能。这段代码主要包含三个部分:
- 初始化图像字幕生成模型(HuggingFace中的image-caption模型)。
- 定义LangChain图像字幕生成工具。
- 初始化并运行LangChain Agent(代理),这个Agent是OpenAI的大语言模型,会自动进行分析,调用工具,完成任务。
不过,这段代码需要的包比较多。在运行这段代码之前,你需要先更新LangChain到最新版本,安装HuggingFace的Transformers库(开源大模型工具),并安装 Pillow(Python图像处理工具包)和 PyTorch(深度学习框架)。
pip install --upgrade langchain
pip install transformers
pip install pillow
pip install torch torchvision torchaudio
#---- Part 0 导入所需要的类
import os
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
from langchain.tools import BaseTool
from langchain import OpenAI
from langchain.agents import initialize_agent, AgentType
#---- Part I 初始化图像字幕生成模型
# 指定要使用的工具模型(HuggingFace中的image-caption模型)
hf_model = "Salesforce/blip-image-captioning-large"
# 初始化处理器和工具模型
# 预处理器将准备图像供模型使用
processor = BlipProcessor.from_pretrained(hf_model)
# 然后我们初始化工具模型本身
model = BlipForConditionalGeneration.from_pretrained(hf_model)
#---- Part II 定义图像字幕生成工具类
class ImageCapTool(BaseTool):
name = "Image captioner"
description = "为图片创作说明文案."
def _run(self, url: str):
# 下载图像并将其转换为PIL对象
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
# 预处理图像
inputs = processor(image, return_tensors="pt")
# 生成字幕
out = model.generate(**inputs, max_new_tokens=20)
# 获取字幕
caption = processor.decode(out[0], skip_special_tokens=True)
return caption
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
#---- PartIII 初始化并运行LangChain智能代理
# 设置OpenAI的API密钥并初始化大语言模型(OpenAI的Text模型)
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'
llm = OpenAI(temperature=0.2)
# 使用工具初始化智能代理并运行它
tools = [ImageCapTool()]
agent = initialize_agent(
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
tools=tools,
llm=llm,
verbose=True,
)
img_url = 'https://mir-s3-cdn-cf.behance.net/project_modules/hd/eec79e20058499.563190744f903.jpg'
agent.run(input=f"{img_url}\n请给出合适的中文文案")
根据输入的图片URL,由OpenAI大语言模型驱动的LangChain Agent,首先利用图像字幕生成工具将图片转化为字幕,然后对字幕做进一步处理,生成中文推广文案。
运行结果1:

运行结果2:

运行结果3:

说明:因为temperature=0.2代表模型拥有一定的随机性,所以大模型每次的推理过程生成的文案都不尽相同。
针对上面的鲜花图片,程序进入了AgentExecutor链,开始思考推理,并采取行动——调用Image Cationer工具,接收该工具给出的结果,并根据其返回的内容,再次进行思考推理,最后给出的文案是:“ 爱,让每一天充满美丽,让每一个心情都充满甜蜜。” 多么浪漫而又富有创意,大模型懂我!
当然,这个过程中还有很多很多的细节,比如大模型是怎么思考的?LangChain调用大模型时传入的具体提示文本是什么?代理是什么?AgentExecutor Chain 是什么?它究竟是怎样调度工具的?你现在可能有很多的疑惑。
在后续的课程中,我会带着你手撕 LangChain 内部源代码,把所有这些一点一滴地剖析清楚。
关于 LangChain,我想向你分享的还有太多太多,短短的开篇词已经无法容纳了。那么,就让我最后告诉你:玩 LangChain,真的很有意思,越深入,越发觉大语言模型是一个无尽的宝藏。在这样的系统中, 我们并不是生硬的去设计什么固定的逻辑,而是由语言模型通过理解和推理来决定执行什么操作以及执行的顺序。
现在你准备好了吗?让我们一同投身到LangChain的世界中,解锁AI的无限可能!
01|LangChain系统安装和快速入门
在我们开始正式的学习之前,先做一些基本知识储备。虽然大语言模型的使用非常简单,但是如果我们通过API来进行应用开发,那么还是有些基础知识应该先了解了解,比如什么是大模型,怎么安装LangChain,OpenAI的API有哪些类型,以及常用的开源大模型从哪里下载等等。
什么是大语言模型
大语言模型是一种人工智能模型,通常使用深度学习技术,比如神经网络,来理解和生成人类语言。这些模型的“大”在于它们的参数数量非常多,可以达到数十亿甚至更多,这使得它们能够理解和生成高度复杂的语言模式。
你可以 将大语言模型想象成一个巨大的预测机器,其训练过程主要基于“猜词”:给定一段文本的开头,它的任务就是预测下一个词是什么。模型会根据大量的训练数据(例如在互联网上爬取的文本),试图理解词语和词组在语言中的用法和含义,以及它们如何组合形成意义。它会通过不断地学习和调整参数,使得自己的预测越来越准确。
比如我们给模型一个句子:“今天的天气真”,模型可能会预测出“好”作为下一个词,因为在它看过的大量训练数据中,“今天的天气真好”是一个常见的句子。这种预测并不只基于词语的统计关系,还包括对上下文的理解,甚至有时能体现出对世界常识的认知,比如它会理解到,人们通常会在天气好的时候进行户外活动。因此也就能够继续生成或者说推理出相关的内容。
但是,大语言模型并不完全理解语言,它们没有人类的情感、意识或理解力。它们只是通过复杂的数学函数学习到的语言模式,一个概率模型来做预测,所以有时候它们会犯错误,或者生成不合理甚至偏离主题的内容。
咱们当然还是主说LangChain。 LangChain 是一个全方位的、基于大语言模型这种预测能力的应用开发工具,它的灵活性和模块化特性使得处理语言模型变得极其简便。不论你在何时何地,都能利用它流畅地调用语言模型,并基于语言模型的“预测”或者说“推理”能力开发新的应用。
LangChain 的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain 提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain支持Python和JavaScript两个开发版本,我们这个教程中全部使用Python版本进行讲解。
安装LangChain
LangChain的基本安装特别简单。
pip install langchain
这是安装 LangChain 的最低要求。这里我要提醒你一点,LangChain 要与各种模型、数据存储库集成,比如说最重要的OpenAI的API接口,比如说开源大模型库HuggingFace Hub,再比如说对各种向量数据库的支持。默认情况下,是没有同时安装所需的依赖项。
也就是说,当你 pip install langchain 之后,可能还需要 pip install openai、 pip install chroma(一种向量数据库)……
用下面两种方法,我们就可以在安装 LangChain 的方法时,引入大多数的依赖项。
安装LangChain时包括常用的开源LLM(大语言模型) 库:
pip install langchain[llms]
安装完成之后,还需要更新到 LangChain 的最新版本,这样才能使用较新的工具。
pip install --upgrade langchain
如果你想从源代码安装,可以克隆存储库并运行:
pip install -e
我个人觉得非常好的学习渠道也在这儿分享给你。
LangChain 的 GitHub 社区非常活跃,你可以在这里找到大量的教程和最佳实践,也可以和其他开发者分享自己的经验和观点。
LangChain也提供了详尽的 API 文档,这是你在遇到问题时的重要参考。不过呢,我觉得因为 LangChain太新了,有时你可能会发现文档中有一些错误。在这种情况下,你可以考虑更新你的版本,或者在官方平台上提交一个问题反馈。
当我遇到问题,我通常会在LangChain的GitHub开一个Issue,很快就可以得到解答。
跟着LangChain其快速的更新步伐,你就能在这个领域取得显著的进步。
OpenAI API
下面我想说一说OpenAI的API。
关于ChatGPT和GPT-4,我想就没有必要赘言了,网上已经有太多资料了。但是要继续咱们的LangChain实战课,你需要对OpenAI的API有进一步的了解。因为, LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些API,搭建起来的一些框架、模块和接口。
因此,要了解LangChain的底层逻辑,需要了解大模型的API的基本设计思路。而目前接口最完备的、同时也是最强大的大语言模型,当然是OpenAI提供的GPT家族模型。
当然,要使用OpenAI API,你需要先用科学的方法进行注册,并得到一个API Key。
有了OpenAI的账号和Key,你就可以在面板中看到各种信息,比如模型的费用、使用情况等。下面的图片显示了各种模型的访问数量限制信息。其中,TPM和RPM分别代表tokens-per-minute、requests-per-minute。也就是说,对于GPT-4,你通过API最多每分钟调用200次、传输40000个字节。
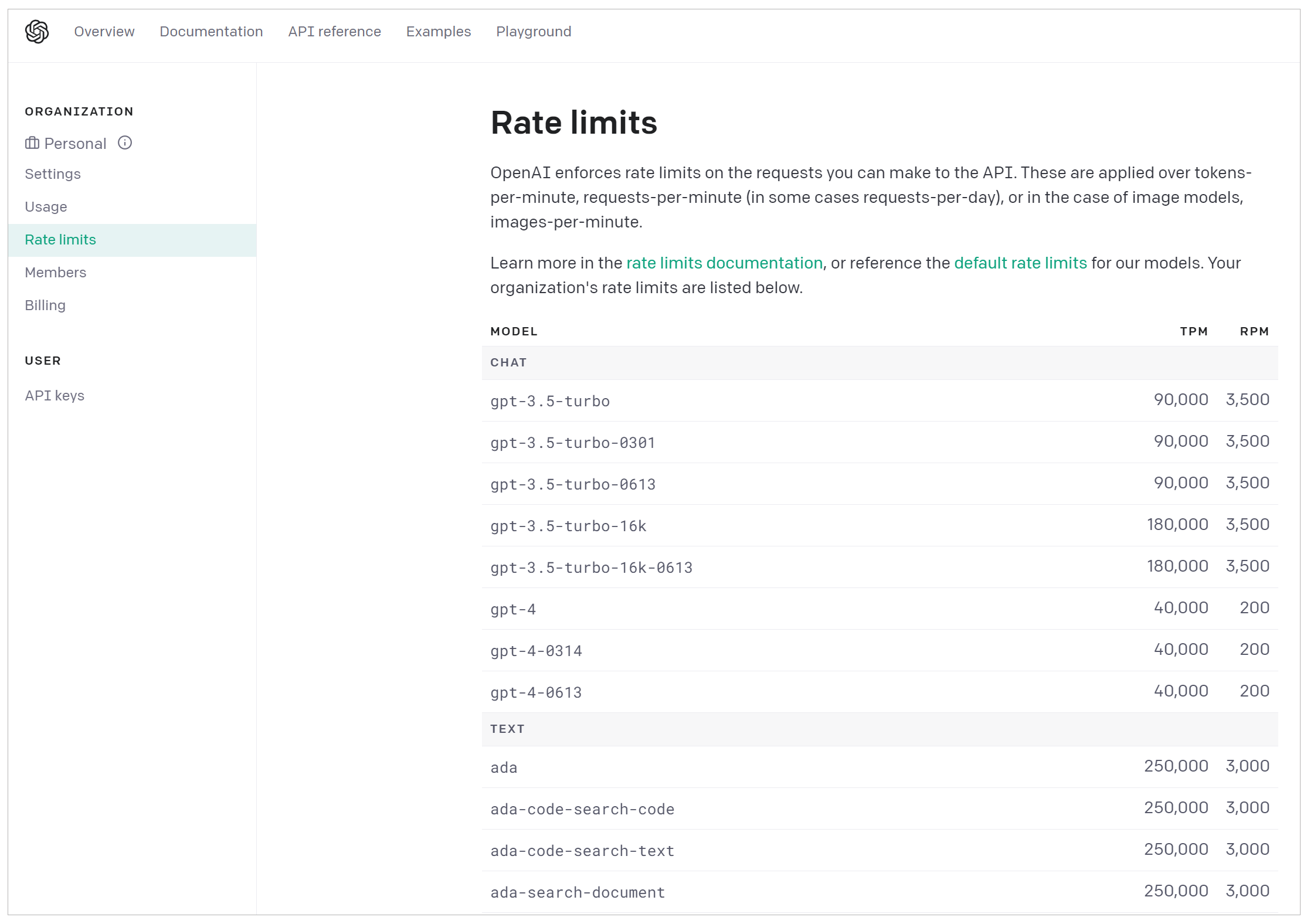
这里,我们需要重点说明的两类模型,就是图中的Chat Model和Text Model。这两类Model,是大语言模型的代表。当然,OpenAI还提供Image、Audio和其它类型的模型,目前它们不是LangChain所支持的重点,模型数量也比较少。
- Chat Model,聊天模型,用于产生人类和AI之间的对话,代表模型当然是gpt-3.5-turbo(也就是ChatGPT)和GPT-4。当然,OpenAI还提供其它的版本,gpt-3.5-turbo-0613代表ChatGPT在2023年6月13号的一个快照,而gpt-3.5-turbo-16k则代表这个模型可以接收16K长度的Token,而不是通常的4K。(注意了,gpt-3.5-turbo-16k并未开放给我们使用,而且你传输的字节越多,花钱也越多)
- Text Model,文本模型,在ChatGPT出来之前,大家都使用这种模型的API来调用GPT-3,文本模型的代表作是text-davinci-003(基于GPT3)。而在这个模型家族中,也有专门训练出来做文本嵌入的text-embedding-ada-002,也有专门做相似度比较的模型,如text-similarity-curie-001。
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫prompt),返回回答文本(output,也叫response)。但是,它们的调用方式和要求的输入格式是有区别的,这个我们等下还会进一步说明。
下面我们用简单的代码段说明上述两种模型的调用方式。先看比较原始的Text模型(GPT3.5之前的版本)。
调用Text模型
第1步,先注册好你的API Key。
第2步,用 pip install openai 命令来安装OpenAI库。
第3步,导入 OpenAI API Key。
导入API Key有多种方式,其中之一是通过下面的代码:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
OpenAI库就会查看名为OPENAI_API_KEY的环境变量,并使用它的值作为API密钥。
也可以像下面这样先导入OpenAI库,然后指定api_key的值。
import openai
openai.api_key = '你的Open API Key'
当然,这种把Key直接放在代码里面的方法最不可取,因为你一不小心共享了代码,密钥就被别人看到了,他就可以使用你的GPT-4资源!所以,建议你给自己的OpenAI账户设个上限,比如每月10美元啥的。
所以更好的方法是在操作系统中定义环境变量,比如在Linux系统的命令行中使用:
export OPENAI_API_KEY='你的Open API Key'
或者,你也可以考虑把环境变量保存在.env文件中,使用python-dotenv库从文件中读取它,这样也可以降低API密钥暴露在代码中的风险。
第4步,导入OpenAI库。(如果你在上一步导入OpenAI API Key时并没有导入OpenAI库)
import openai
第5步,调用Text模型,并返回结果。
response = openai.Completion.create(
model="text-davinci-003",
temperature=0.5,
max_tokens=100,
prompt="请给我的花店起个名")
在使用OpenAI的文本生成模型时,你可以通过一些参数来控制输出的内容和样式。这里我总结为了一些常见的参数。
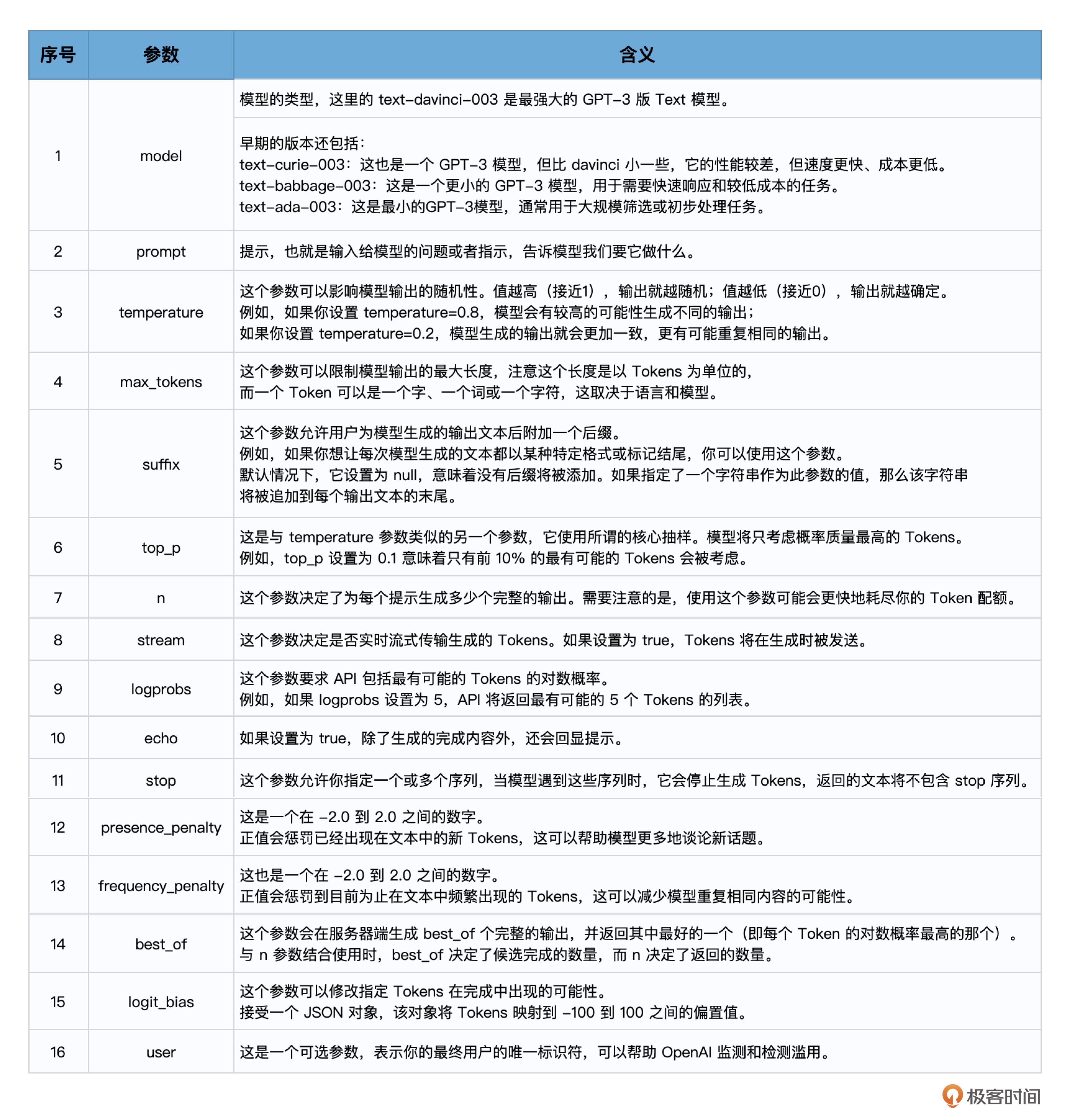
第6步,打印输出大模型返回的文字。
print(response.choices[0].text.strip())
当你调用OpenAI的Completion.create方法时,它会返回一个响应对象,该对象包含了模型生成的输出和其他一些信息。这个响应对象是一个字典结构,包含了多个字段。
在使用Text模型(如text-davinci-003)的情况下,响应对象的主要字段包括:

choices字段是一个列表,因为在某些情况下,你可以要求模型生成多个可能的输出。每个选择都是一个字典,其中包含以下字段:
- text:模型生成的文本。
- finish_reason:模型停止生成的原因,可能的值包括 stop(遇到了停止标记)、length(达到了最大长度)或 temperature(根据设定的温度参数决定停止)。
所以, response.choices[0].text.strip() 这行代码的含义是:从响应中获取第一个(如果在调用大模型时,没有指定n参数,那么就只有唯一的一个响应)选择,然后获取该选择的文本,并移除其前后的空白字符。这通常是你想要的模型的输出。
至此,任务完成,模型的输出如下:
心动花庄、芳华花楼、轩辕花舍、簇烂花街、满园春色
不错。下面,让我们再来调用Chat模型(GPT-3.5和GPT-4)。
调用Chat模型
整体流程上,Chat模型和Text模型的调用是完全一样的,只是输入(prompt)和输出(response)的数据格式有所不同。
示例代码如下:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a creative AI."},
{"role": "user", "content": "请给我的花店起个名"},
],
temperature=0.8,
max_tokens=60
)
print(response['choices'][0]['message']['content'])
这段代码中,除去刚才已经介绍过的temperature、max_tokens等参数之外,有两个专属于Chat模型的概念,一个是消息,一个是角色!
先说 消息,消息就是传入模型的提示。此处的messages参数是一个列表,包含了多个消息。每个消息都有一个role(可以是system、user或assistant)和content(消息的内容)。系统消息设定了对话的背景(你是一个很棒的智能助手),然后用户消息提出了具体请求(请给我的花店起个名)。模型的任务是基于这些消息来生成回复。
再说 角色,在OpenAI的Chat模型中,system、user和assistant都是消息的角色。每一种角色都有不同的含义和作用。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的AI助手。系统消息通常在对话开始时给出。
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用API发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
在使用Chat模型生成内容后,返回的 响应,也就是response会包含一个或多个choices,每个choices都包含一个message。每个message也都包含一个role和content。role可以是system、user或assistant,表示该消息的发送者,content则包含了消息的实际内容。
一个典型的response对象可能如下所示:
{
'id': 'chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-4',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': '你的花店可以叫做"花香四溢"。'
},
'finish_reason': 'stop',
'index': 0
}
]
}
以下是各个字段的含义:
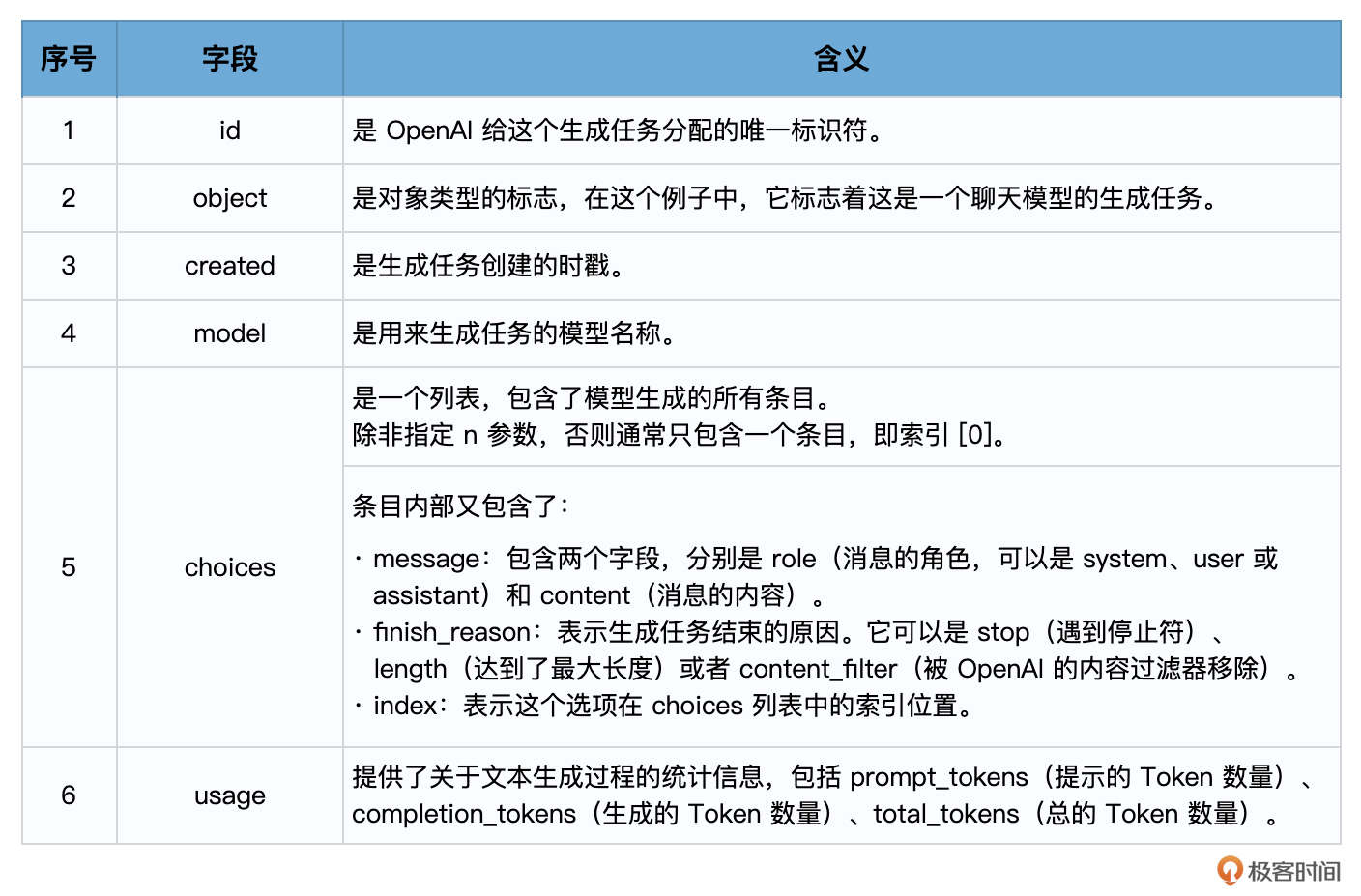
这就是response的基本结构,其实它和Text模型返回的响应结构也是很相似,只是choices字段中的Text换成了Message。你可以通过解析这个对象来获取你需要的信息。例如,要获取模型的回复,可使用 response[‘choices’][0][‘message’][‘content’]。
Chat模型 vs Text模型
Chat模型和Text模型都有各自的优点,其适用性取决于具体的应用场景。
相较于Text模型,Chat模型的设计更适合处理对话或者多轮次交互的情况。这是因为它可以接受一个消息列表作为输入,而不仅仅是一个字符串。这个消息列表可以包含system、user和assistant的历史信息,从而在处理交互式对话时提供更多的上下文信息。
这种设计的主要优点包括:
- 对话历史的管理:通过使用Chat模型,你可以更方便地管理对话的历史,并在需要时向模型提供这些历史信息。例如,你可以将过去的用户输入和模型的回复都包含在消息列表中,这样模型在生成新的回复时就可以考虑到这些历史信息。
- 角色模拟:通过system角色,你可以设定对话的背景,给模型提供额外的指导信息,从而更好地控制输出的结果。当然在Text模型中,你在提示中也可以为AI设定角色,作为输入的一部分。
然而,对于简单的单轮文本生成任务,使用Text模型可能会更简单、更直接。例如,如果你只需要模型根据一个简单的提示生成一段文本,那么Text模型可能更适合。从上面的结果看,Chat模型给我们输出的文本更完善,是一句完整的话,而Text模型输出的是几个名字。这是因为ChatGPT经过了对齐(基于人类反馈的强化学习),输出的答案更像是真实聊天场景。
好了,我们对OpenAI的API调用,理解到这个程度就可以了。毕竟我们主要是通过LangChain这个高级封装的框架来访问Open AI。
通过LangChain调用Text和Chat模型
最后,让我们来使用LangChain来调用OpenAI的Text和Chat模型,完成了这两个任务,我们今天的课程就可以结束了!
调用Text模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.llms import OpenAI
llm = OpenAI(
model="text-davinci-003",
temperature=0.8,
max_tokens=60,)
response = llm.predict("请给我的花店起个名")
print(response)
输出:
花之缘、芳华花店、花语心意、花风旖旎、芳草世界、芳色年华
这只是一个对OpenAI API的简单封装:先导入LangChain的OpenAI类,创建一个LLM(大语言模型)对象,指定使用的模型和一些生成参数。使用创建的LLM对象和消息列表调用OpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。没有什么需要特别解释之处。
调用Chat模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model="gpt-4",
temperature=0.8,
max_tokens=60)
from langchain.schema import (
HumanMessage,
SystemMessage
)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名")
]
response = chat(messages)
print(response)
这段代码也不难理解,主要是通过导入LangChain的ChatOpenAI类,创建一个Chat模型对象,指定使用的模型和一些生成参数。然后从LangChain的schema模块中导入LangChain的SystemMessage和HumanMessage类,创建一个消息列表。消息列表中包含了一个系统消息和一个人类消息。你已经知道系统消息通常用来设置一些上下文或者指导AI的行为,人类消息则是要求AI回应的内容。之后,使用创建的chat对象和消息列表调用ChatOpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。
输出:
content='当然可以,叫做"花语秘境"怎么样?'
additional_kwargs={} example=False
从响应内容“ 当然可以,叫做‘花语秘境’怎么样?”不难看出,GPT-4的创造力真的是胜过GPT-3,她给了我们这么有意境的一个店名,比我自己起的“易速鲜花”好多了。
另外,无论是langchain.llms中的OpenAI(Text模型),还是langchain.chat_models中的ChatOpenAI中的ChatOpenAI(Chat模型),其返回的结果response变量的结构,都比直接调用OpenAI API来得简单一些。这是因为,LangChain已经对大语言模型的output进行了解析,只保留了响应中最重要的文字部分。
总结时刻
好了,今天课程的内容不少,我希望你理解OpenAI从Text模型到Chat模型的进化,以及什么时候你会选用Chat模型,什么时候会选用Text模型。另外就是这两种模型的最基本调用流程,掌握了这些内容,我们就可以继续后面的学习。
另外,大语言模型可不是OpenAI一家独大,知名的大模型开源社群HugginFace网站上面提供了很多开源模型供你尝试使用。就在我写这节课的时候,Meta的Llama-2最受热捧,而且通义千问(Qwen)则刚刚开源。这些趋势,你点击下面的图片就看得到。
两点提醒,一是这个领域进展太快,当你学这门课程的时候,流行的开源模型肯定变成别的了;二是这些新的开源模型,LangChain还不一定提供很好的接口,因此通过LangChain来使用最新的开源模型可能不容易。
不过LangChain作为最流行的LLM框架,新的开源模型被封装进来是迟早的事情。而且,LangChain的框架也已经定型,各个组件的设计都基本固定了。
思考题
最后给你留几个有难度的思考题,有些题目你可能现在没有答案,但是我希望你带着这些问题去继续学习后续课程。
-
从今天的两个例子看起来,使用LangChain并不比直接调用OpenAI API来得省事?而且也仍然需要OpenAI API才能调用GPT家族模型。那么LangChain的核心价值在哪里?至少从这两个示例中没看出来。针对这个问题,你仔细思考思考。
提示:这个问题没有标准答案,仁者见仁智者见智,等学完了课程,我们可以再回过头来回答一次。
-
LangChain支持的可绝不只有OpenAI模型,那么你能否试一试HuggingFace开源社区中的其它模型,看看能不能用。
提示:你要选择Text-Generation、Text-Text Generation和Question-Answer这一类的文本生成式模型。
from langchain import HuggingFaceHub
llm = HuggingFaceHub(model_id="bigscience/bloom-1b7")
-
上面我提到了生成式模型,那么,大语言模型除了文本生成式模型,还有哪些类别的模型?比如说有名的Bert模型,是不是文本生成式的模型?
提示:如果你没有太多NLP基础知识,建议你可以看一下我的专栏《零基础实战机器学习》和公开课《ChatGPT和预训练模型实战课》。
期待在留言区看到你的思考,如果你觉得内容对你有帮助,也欢迎分享给有需要的朋友!最后如果你学有余力,可以进一步学习下面的延伸阅读。
延伸阅读
- LangChain官方文档( Python版)( JavaScript版),这是你学习专栏的过程中,有任何疑惑都可以随时去探索的知识大本营。我个人觉得,目前LangChain的文档还不够体系化,有些杂乱,讲解也不大清楚。但是,这是官方文档,会维护得越来越好。
- OpenAI API 官方文档,深入学习OpenAI API的地方。
- HuggingFace 官方网站,玩开源大模型的好地方。
02|用LangChain快速构建基于“易速鲜花”本地知识库的智能问答系统
在深入讲解LangChain的每一个具体组件之前,我想带着你从头完成一个很实用、很有意义的实战项目。目的就是让你直观感受一下LangChain作为一个基于大语言模型的应用开发框架,功能到底有多么强大。好的,现在就开始!
项目及实现框架
我们先来整体了解一下这个项目。
项目名称:“易速鲜花”内部员工知识库问答系统。
项目介绍:“易速鲜花”作为一个大型在线鲜花销售平台,有自己的业务流程和规范,也拥有针对员工的SOP手册。新员工入职培训时,会分享相关的信息。但是,这些信息分散于内部网和HR部门目录各处,有时不便查询;有时因为文档过于冗长,员工无法第一时间找到想要的内容;有时公司政策已更新,但是员工手头的文档还是旧版内容。
基于上述需求,我们将开发一套基于各种内部知识手册的 “Doc-QA” 系统。这个系统将充分利用LangChain框架,处理从员工手册中产生的各种问题。这个问答系统能够理解员工的问题,并基于最新的员工手册,给出精准的答案。
开发框架:下面这张图片描述了通过LangChain框架实现一个知识库文档系统的整体框架。
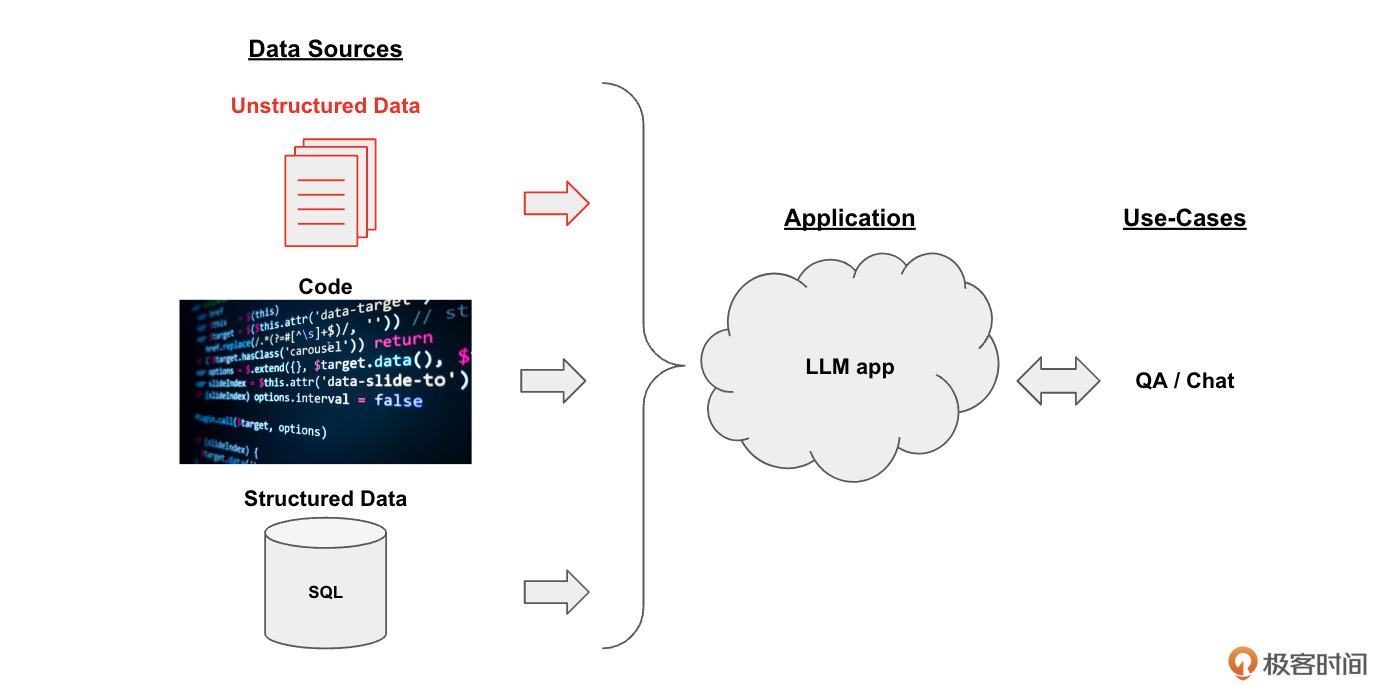
整个框架分为这样三个部分。
- 数据源(Data Sources):数据可以有很多种,包括PDF在内的非结构化的数据(Unstructured Data)、SQL在内的结构化的数据(Structured Data),以及Python、Java之类的代码(Code)。在这个示例中,我们聚焦于对非结构化数据的处理。
- 大模型应用(Application,即LLM App):以大模型为逻辑引擎,生成我们所需要的回答。
- 用例(Use-Cases):大模型生成的回答可以构建出QA/聊天机器人等系统。
核心实现机制: 这个项目的核心实现机制是下图所示的数据处理管道(Pipeline)。
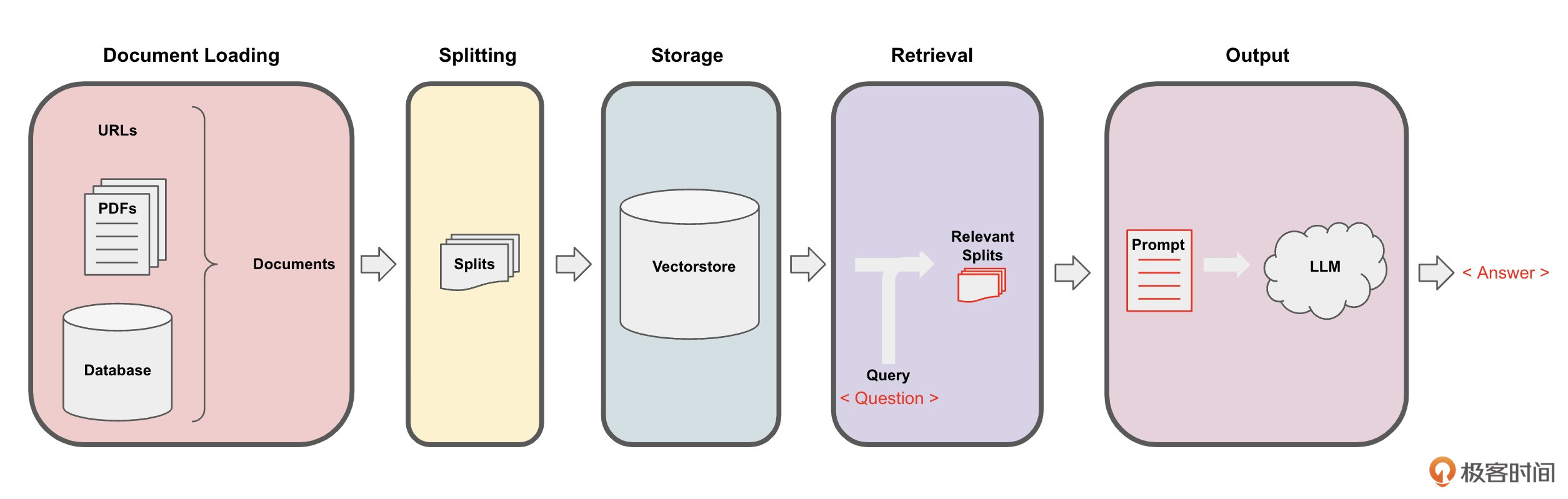
在这个管道的每一步中,LangChain都为我们提供了相关工具,让你轻松实现基于文档的问答功能。
具体流程分为下面5步。
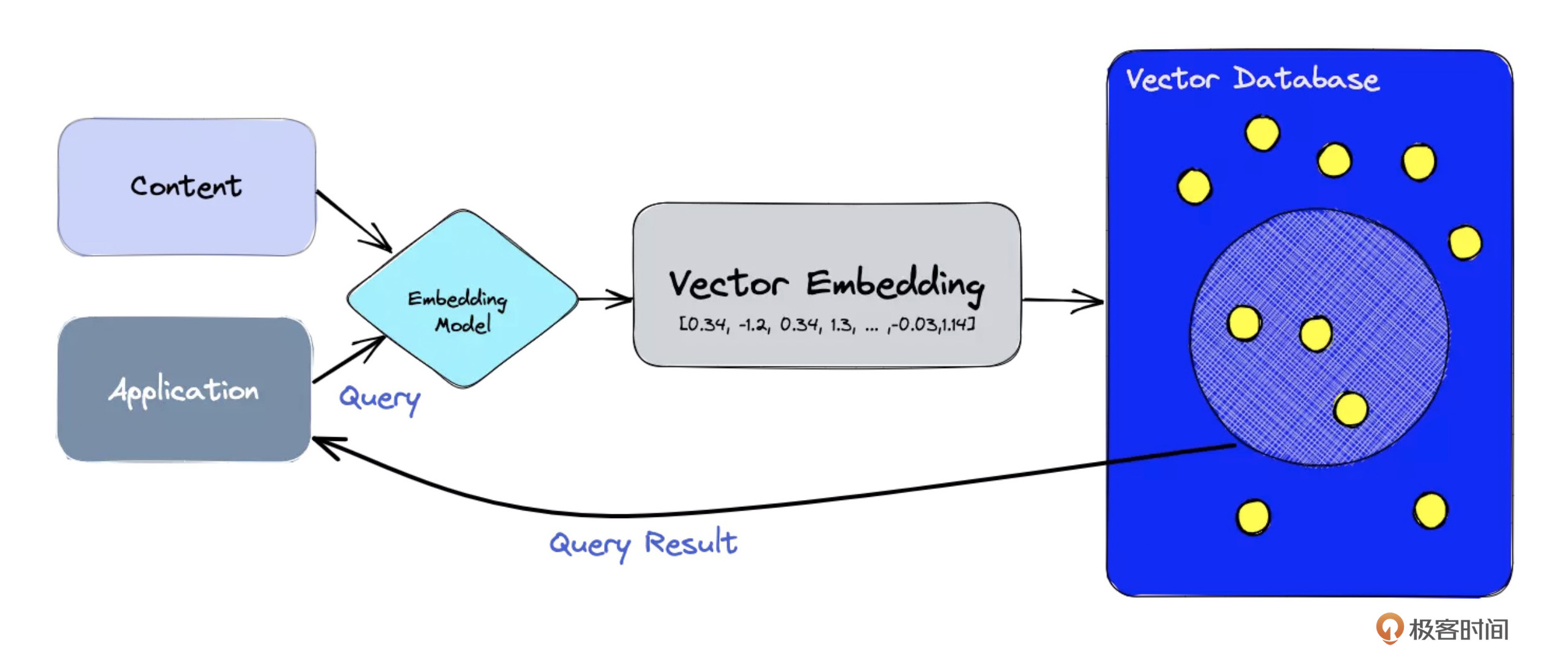
- Loading:文档加载器把Documents 加载 为以LangChain能够读取的形式。
- Splitting:文本分割器把Documents 切分 为指定大小的分割,我把它们称为“文档块”或者“文档片”。
- Storage:将上一步中分割好的“文档块”以“嵌入”(Embedding)的形式 存储 到向量数据库(Vector DB)中,形成一个个的“嵌入片”。
- Retrieval:应用程序从存储中 检索 分割后的文档(例如通过比较余弦相似度,找到与输入问题类似的嵌入片)。
- Output:把问题和相似的嵌入片传递给语言模型(LLM),使用包含问题和检索到的分割的提示 生成答案。
上面5个环节的介绍都非常简单,有些概念(如嵌入、向量存储)是第一次出现,理解起来需要一些背景知识,别着急,我们接下来具体讲解这5步。
数据的准备和载入
“易速鲜花”的内部资料包括 pdf、word 和 txt 格式的各种文件,我已经放在 这里 供你下载。
其中一个文档的示例如下:

我们首先用LangChain中的document_loaders来加载各种格式的文本文件。(这些文件我把它放在OneFlower这个目录中了,如果你创建自己的文件夹,就要调整一下代码中的目录。)
在这一步中,我们从 pdf、word 和 txt 文件中加载文本,然后将这些文本存储在一个列表中。(注意:可能需要安装PyPDF、Docx2txt等库)
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'
## 1.Load 导入Document Loaders
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader
## 加载Documents
base_dir = '.\OneFlower' ## 文档的存放目录
documents = []
for file in os.listdir(base_dir):
## 构建完整的文件路径
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())
这里我们首先导入了OpenAI的API Key。因为后面我们需要利用Open AI的两种不同模型做以下两件事:
- 用OpenAI的Embedding模型为文档做嵌入。
- 调用OpenAI的GPT模型来生成问答系统中的回答。
当然了,LangChain所支持的大模型绝不仅仅是Open AI而已,你完全可以遵循这个框架,把Embedding模型和负责生成回答的语言模型都替换为其他的开源模型。
在运行上面的程序时,除了要导入正确的Open AI Key之外,还要注意的是工具包的安装。使用LangChain时,根据具体的任务,往往需要各种不同的工具包(比如上面的代码需要PyPDF和Docx2txt工具)。它们安装起来都非常简单,如果程序报错缺少某个包,只要通过 pip install 安装相关包即可。
文本的分割
接下来需要将加载的文本分割成更小的块,以便进行嵌入和向量存储。这个步骤中,我们使用 LangChain中的RecursiveCharacterTextSplitter 来分割文本。
## 2.Split 将Documents切分成块以便后续进行嵌入和向量存储
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
现在,我们的文档被切成了一个个200字符左右的文档块。这一步,是为把它们存储进下面的向量数据库做准备。
向量数据库存储
紧接着,我们将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中。在这个例子中,我们使用了 OpenAIEmbeddings 来生成嵌入,然后使用 Qdrant 这个向量数据库来存储嵌入(这里需要pip install qdrant-client)。
如果文本的“嵌入”这个概念对你来说有些陌生的话,你可以看一下下面的说明。
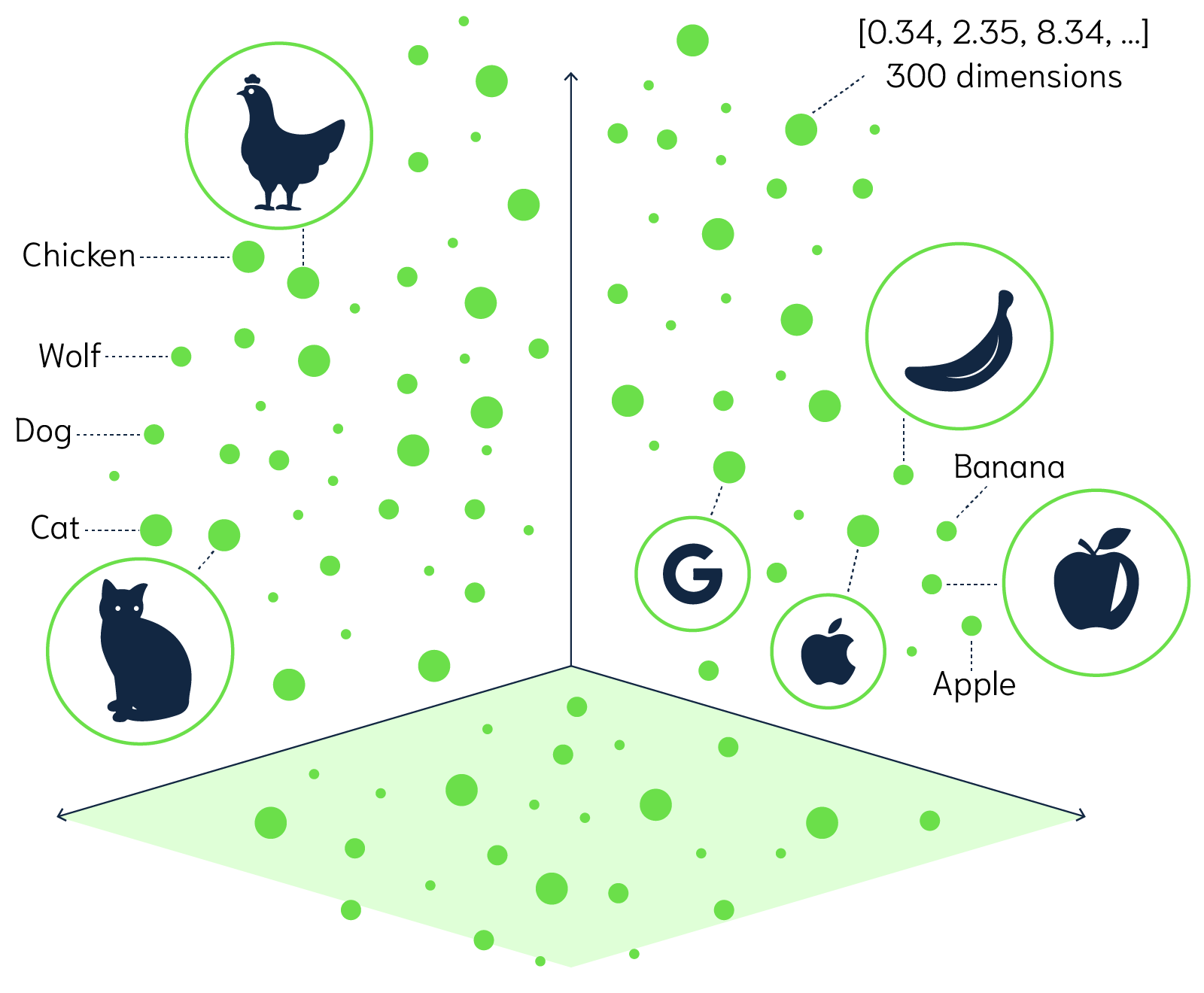
词嵌入(Word Embedding)是自然语言处理和机器学习中的一个概念,它将文字或词语转换为一系列数字,通常是一个向量。简单地说,词嵌入就是一个为每个词分配的数字列表。这些数字不是随机的,而是捕获了这个词的含义和它在文本中的上下文。因此,语义上相似或相关的词在这个数字空间中会比较接近。
举个例子,通过某种词嵌入技术,我们可能会得到:
“国王” -> [1.2, 0.5, 3.1, …]
“皇帝” -> [1.3, 0.6, 2.9, …]
“苹果” -> [0.9, -1.2, 0.3, …]
从这些向量中,我们可以看到“国王”和“皇帝”这两个词的向量在某种程度上是相似的,而与“苹果”这个词相比,它们的向量则相差很大,因为这两个概念在语义上是不同的。
词嵌入的优点是,它提供了一种将文本数据转化为计算机可以理解和处理的形式,同时保留了词语之间的语义关系。这在许多自然语言处理任务中都是非常有用的,比如文本分类、机器翻译和情感分析等。
你也可以对照下面的讲解学习一下向量数据库这个概念,它最近因为大语言模型的流行变得非常火爆。
向量数据库,也称为矢量数据库或者向量搜索引擎,是一种专门用于存储和搜索向量形式的数据的数据库。在众多的机器学习和人工智能应用中,尤其是自然语言处理和图像识别这类涉及大量非结构化数据的领域,将数据转化为高维度的向量是常见的处理方式。这些向量可能拥有数百甚至数千个维度,是对复杂的非结构化数据如文本、图像的一种数学表述,从而使这些数据能被机器理解和处理。然而,传统的关系型数据库在存储和查询如此高维度和复杂性的向量数据时,往往面临着效率和性能的问题。因此,向量数据库被设计出来以解决这一问题,它具备高效存储和处理高维向量数据的能力,从而更好地支持涉及非结构化数据处理的人工智能应用。
向量数据库有很多种,比如Pinecone、Chroma和Qdrant,有些是收费的,有些则是开源的。
LangChain中支持很多向量数据库,这里我们选择的是开源向量数据库Qdrant。(注意,需要安装qdrant-client)
具体实现代码如下:
## 3.Store 将分割嵌入并存储在矢量数据库Qdrant中
from langchain.vectorstores import Qdrant
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Qdrant.from_documents(
documents=chunked_documents, ## 以分块的文档
embedding=OpenAIEmbeddings(), ## 用OpenAI的Embedding Model做嵌入
location=":memory:", ## in-memory 存储
collection_name="my_documents",) ## 指定collection_name
目前,易速鲜花的所有内部文档,都以“文档块嵌入片”的格式被存储在向量数据库里面了。那么,我们只需要查询这个向量数据库,就可以找到大体上相关的信息了。
相关信息的获取
当内部文档存储到向量数据库之后,我们需要根据问题和任务来提取最相关的信息。此时,信息提取的基本方式就是把问题也转换为向量,然后去和向量数据库中的各个向量进行比较,提取最接近的信息。
向量之间的比较通常基于向量的距离或者相似度。在高维空间中,常用的向量距离或相似度计算方法有欧氏距离和余弦相似度。
- 欧氏距离:这是最直接的距离度量方式,就像在二维平面上测量两点之间的直线距离那样。在高维空间中,两个向量的欧氏距离就是各个对应维度差的平方和的平方根。
- 余弦相似度:在很多情况下,我们更关心向量的方向而不是它的大小。例如在文本处理中,一个词的向量可能会因为文本长度的不同,而在大小上有很大的差距,但方向更能反映其语义。余弦相似度就是度量向量之间方向的相似性,它的值范围在-1到1之间,值越接近1,表示两个向量的方向越相似。
这两种方法都被广泛应用于各种机器学习和人工智能任务中,选择哪一种方法取决于具体的应用场景。
当然这里你肯定会问了,那么到底什么时候选择欧式距离,什么时候选择余弦相似度呢?
简单来说,关心数量等大小差异时用欧氏距离,关心文本等语义差异时用余弦相似度。
具体来说,欧氏距离度量的是绝对距离,它能很好地反映出向量的绝对差异。当我们关心数据的绝对大小,例如在物品推荐系统中,用户的购买量可能反映他们的偏好强度,此时可以考虑使用欧氏距离。同样,在数据集中各个向量的大小相似,且数据分布大致均匀时,使用欧氏距离也比较适合。
余弦相似度度量的是方向的相似性,它更关心的是两个向量的角度差异,而不是它们的大小差异。在处理文本数据或者其他高维稀疏数据的时候,余弦相似度特别有用。比如在信息检索和文本分类等任务中,文本数据往往被表示为高维的词向量,词向量的方向更能反映其语义相似性,此时可以使用余弦相似度。
在这里,我们正在处理的是文本数据,目标是建立一个问答系统,需要从语义上理解和比较问题可能的答案。因此,我建议使用余弦相似度作为度量标准。通过比较问题和答案向量在语义空间中的方向,可以找到与提出的问题最匹配的答案。
在这一步的代码部分,我们会创建一个聊天模型。然后需要创建一个 RetrievalQA 链,它是一个检索式问答模型,用于生成问题的答案。
在RetrievalQA 链中有下面两大重要组成部分。
- LLM是大模型,负责回答问题。
- retriever(vectorstore.as_retriever())负责根据问题检索相关的文档,找到具体的“嵌入片”。这些“嵌入片”对应的“文档块”就会作为知识信息,和问题一起传递进入大模型。本地文档中检索而得的知识很重要,因为 从互联网信息中训练而来的大模型不可能拥有“易速鲜花”作为一个私营企业的内部知识。
具体代码如下:
## 4. Retrieval 准备模型和Retrieval链
import logging ## 导入Logging工具
from langchain.chat_models import ChatOpenAI ## ChatOpenAI模型
from langchain.retrievers.multi_query import MultiQueryRetriever ## MultiQueryRetriever工具
from langchain.chains import RetrievalQA ## RetrievalQA链
## 设置Logging
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
## 实例化一个大模型工具 - OpenAI的GPT-3.5
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
## 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
## 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
现在我们已经为后续的步骤做好了准备,下一步就是接收来自系统用户的具体问题,并根据问题检索信息,生成回答。
生成回答并展示
这一步是问答系统应用的主要UI交互部分,这里会创建一个 Flask 应用(需要安装Flask包)来接收用户的问题,并生成相应的答案,最后通过 index.html 对答案进行渲染和呈现。
在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上。
## 5. Output 问答系统的UI实现
from flask import Flask, request, render_template
app = Flask(__name__) ## Flask APP
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
## 接收用户输入作为问题
question = request.form.get('question')
## RetrievalQA链 - 读入问题,生成答案
result = qa_chain({"query": question})
## 把大模型的回答结果返回网页进行渲染
return render_template('index.html', result=result)
return render_template('index.html')
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000)
相关HTML网页的关键代码如下:
<body>
<div class="container">
<div class="header">
<h1>易速鲜花内部问答系统</h1>
<img src="{{ url_for('static', filename='flower.png') }}" alt="flower logo" width="200">
</div>
<form method="POST">
<label for="question">Enter your question:</label><br>
<input type="text" id="question" name="question"><br>
<input type="submit" value="Submit">
</form>
{% if result is defined %}
<h2>Answer</h2>
<p>{{ result.result }}</p>
{% endif %}
</div>
</body>
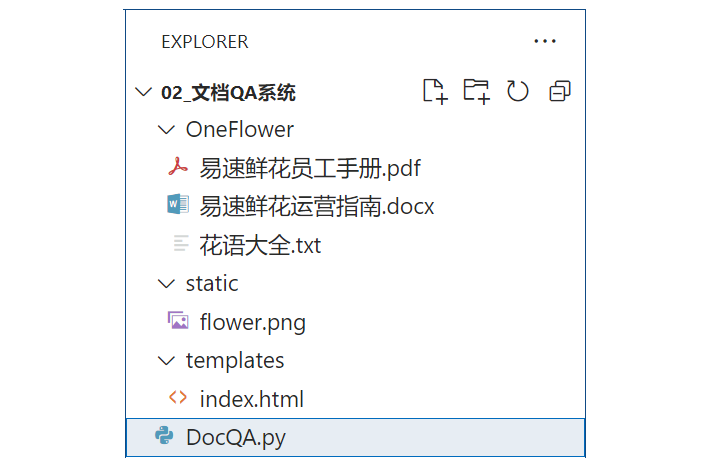
这个项目的目录结构如下:
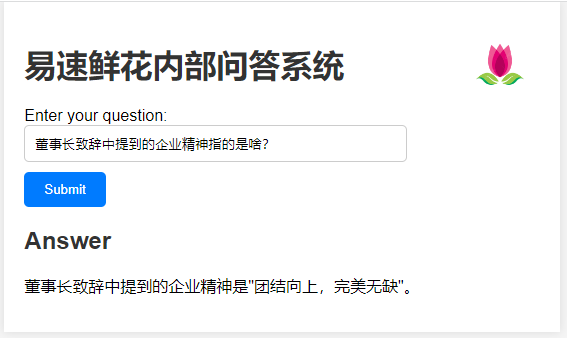
运行程序之后,我们跑起一个网页 http://127.0.0.1:5000/。与网页进行互动时,可以发现,问答系统完美生成了专属于异速鲜花内部资料的回答。
总结时刻
来回顾一下上面的流程。正如下图所示,我们先把本地知识切片后做Embedding,存储到向量数据库中,然后把用户的输入和从向量数据库中检索到的本地知识传递给大模型,最终生成所想要的回答。
怎么样,你是不是觉得整个流程特别简单易懂?
对了,LangChain+LLM的配置就是使原本复杂的东西变得特别简单,特别易于操作。而这个任务,在大模型和LangChain出现之前,要实现起来可不是这么简单的。
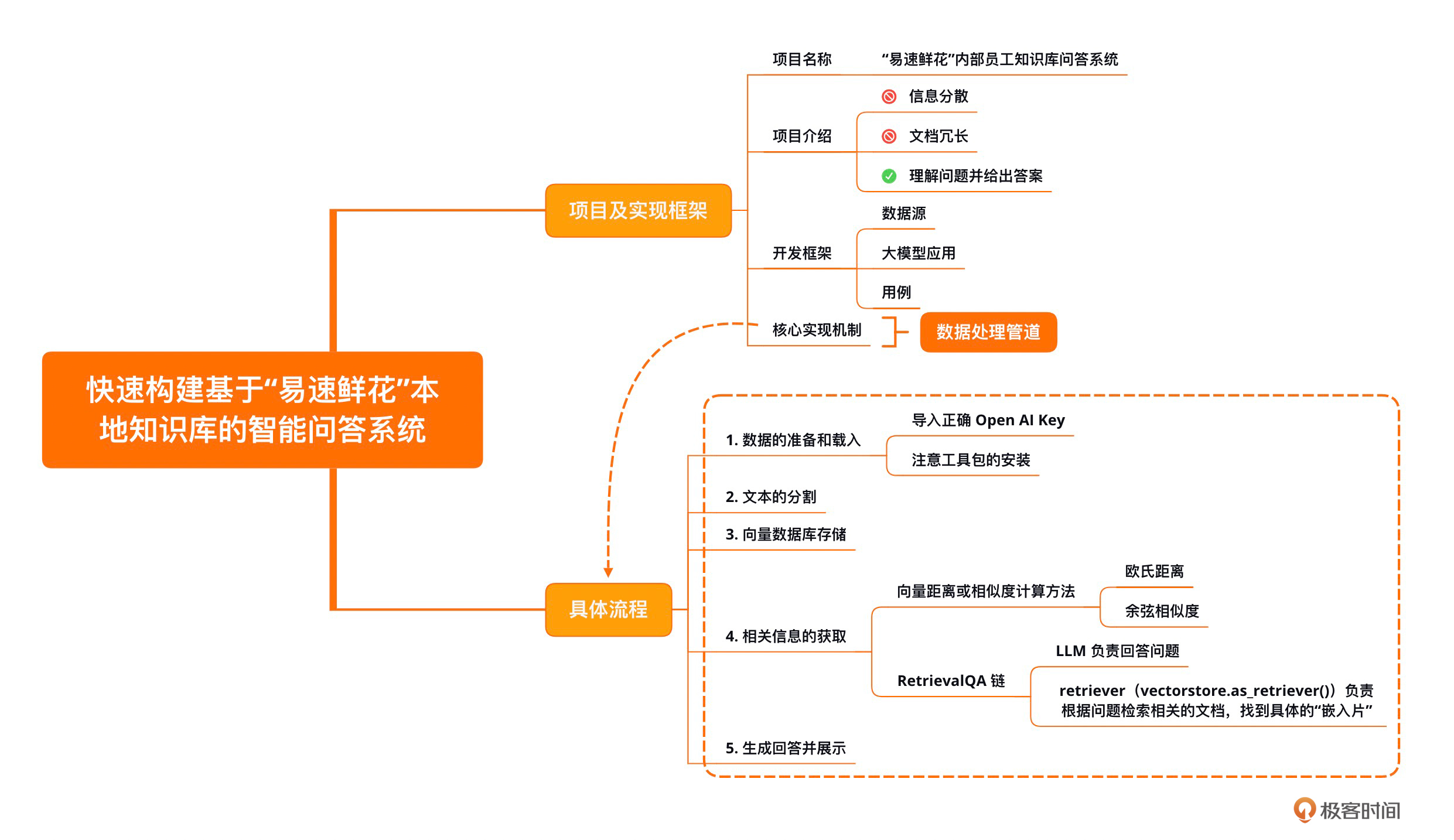
如果这个示例让你了解到了LangChain的威力,那么这节课的目标也就完成了。除了流程图的回顾,我也为你准备了一个详细版的脑图,你可以对照着复习。
在后面几节课中,我们即将对LangChain的模型、链、内存、代理等组件进行详细拆解,我会带着你实现更多任务,开发出更奇妙的应用。
思考题
- 请你用自己的话简述一下这个基于文档的QA(问答)系统的实现流程?
- LangChain支持很多种向量数据库,你能否用另一种常用的向量数据库Chroma来实现这个任务?
- LangChain支持很多种大语言模型,你能否用HuggingFace网站提供的开源模型 google/flan-t5-x1 代替GPT-3.5完成这个任务?
题目较多,可以选择性尝试,期待在留言区看到你的分享。如果你觉得内容对你有帮助,也欢迎分享给有需要的朋友!最后如果你学有余力,可以进一步学习下面的延伸阅读。
延伸阅读
- LangChain官方文档对 Document QA 系统 设计及实现的详细说明
- HuggingFace官网上的 文档问答 资源
- 论文 开放式表格与文本问题回答,Chen, W., Chang, M.-W., Schlinger, E., Wang, W., & Cohen, W. W. (2021). Open Question Answering over Tables and Text. ICLR 2021.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)