【第四章:大模型(LLM)】01.Embedding is all you need-(1)Why embedding is all you need?
大模型的核心基石:Embedding技术解析 摘要:Embedding(嵌入表示)是现代大模型处理离散数据的核心技术,它将文本、图像等转化为连续的向量表示。作为连接原始数据与神经网络的桥梁,Embedding不仅能捕捉语义关系和上下文信息,还具有强大的通用性和迁移能力。在Transformer架构中,注意力机制等核心操作都在Embedding空间完成。研究表明,构建高质量的表示空间可以简化模型结构
第四章: 大模型(LLM)
第一部分:Embedding is all you need
第一节:Why embedding is all you need?
一、引言
在现代大模型中(如GPT、BERT、T5),embedding(嵌入表示) 是模型感知世界的第一步。它将离散的数据(文本、图像、音频等)转化为连续的、高维的向量表示,是连接原始数据与深度神经网络的桥梁。
而“Embedding is all you need”背后的核心观点是:
只要构建合理的表示空间,很多任务都可以用简单模型在向量空间中完成。
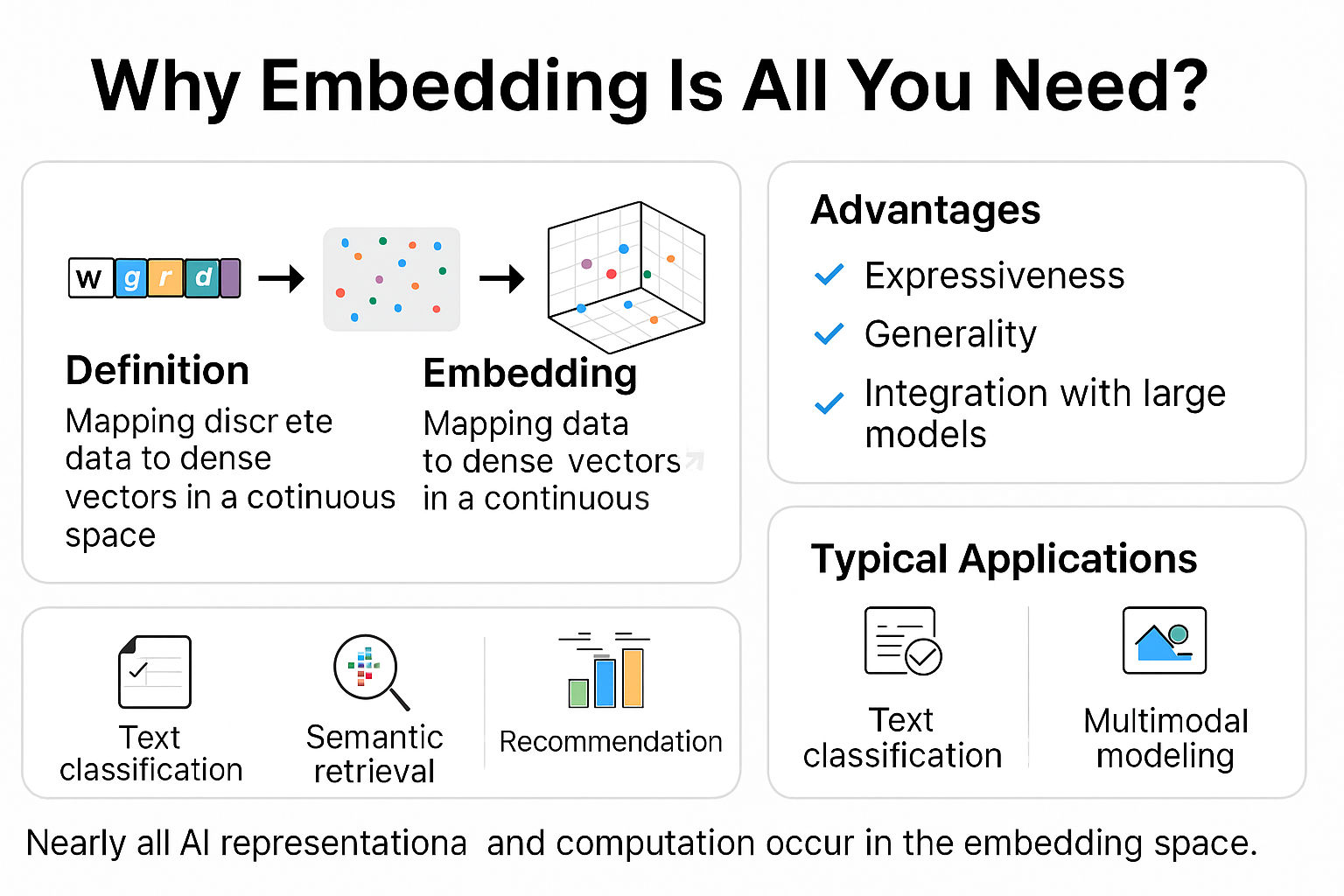
二、什么是 Embedding?
-
定义: 将离散数据(如词、句子、类别)映射为固定维度的稠密向量。
-
本质: 在一个连续空间中捕捉语义、结构或上下文信息。
-
常见类型:
-
词向量(word2vec、GloVe)
-
句向量(BERT embedding、Sentence-BERT)
-
图节点嵌入(GraphSAGE、Node2Vec)
-
图像/音频嵌入(CNN/RNN输出层)
-
三、为什么 Embedding 如此关键?
表达力强
-
将符号数据转为可学习的连续表示;
-
捕捉数据间隐含的语义距离与上下文结构。
通用性强
-
同一个 embedding 可迁移应用于多种任务(分类、生成、检索、推荐等);
-
支持端到端训练,也可预训练 + 微调。
与大模型深度结合
-
LLM 的输入/输出层几乎全基于 embedding;
-
Attention 机制就是在 embedding 空间内进行加权交互;
-
多模态融合(图文、语音)本质是多模态 embedding 对齐。
四、典型应用场景
| 任务 | 嵌入的使用方式 |
|---|---|
| 文本分类 | 文本向量 → 分类器 |
| 语义检索 | Query 向量 ↔ 文档向量相似度 |
| 推荐系统 | 用户/物品嵌入 + 交互预测 |
| 多模态建模 | 图像/文本/语音 → 向量融合 |
| LLM 输入输出 | Token Embedding + Position Embedding |
五、为什么“is all you need”?
-
几乎所有的 AI 表征与计算都在 embedding 空间内完成;
-
Transformer 中,注意力、残差连接、前馈网络都处理的是 embedding;
-
模型推理阶段主要是在 embedding 空间进行“几何操作”;
-
越强的 embedding,越少依赖复杂模型,甚至可直接基于 embedding 相似性完成任务。
六、总结
| 项目 | 内容说明 |
|---|---|
| 作用 | 连接原始输入与神经网络 |
| 优势 | 可微、稠密、语义表达强、可迁移 |
| 应用广泛性 | NLP、CV、音频、推荐、图神经网络、跨模态等领域 |
| 核心观点 | 表征质量越高,模型结构可以越简单 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)