深入 Transformers 库 Pipeline 内部:从文本到情感分析的全流程解析
Hugging Face 的 Pipeline 就像一个高效的 NLP 生产线,将文本处理、模型推理和结果解析三个环节有机结合起来。通过Tokenizer、基础模型和模型头的分工协作,它能够轻松应对各种 NLP 任务。理解 Pipeline 的内部机制,不仅能让我们更高效地调用预训练模型,还能根据实际需求进行灵活定制。希望本文能帮助你深入理解 Hugging Face Pipeline 的工作原理
在使用 Transformers 库 进行自然语言处理任务时,我们常常会惊叹于pipeline的便捷 —— 一行代码就能完成情感分析、文本生成等复杂任务。但你是否好奇过,这背后究竟隐藏着怎样的魔法?今天,我们就以情感分析为例,一起拆解 Transformers 库 Pipeline 的核心机制,揭开预处理、模型计算到后处理的全流程面纱。
一、Pipeline:NLP 任务的全流程自动化引擎
Hugging Face 的pipeline是 Transformers 库中最具标志性的功能之一,它通过标准化流程编排将复杂的 NLP 任务抽象为 "输入文本→输出结果" 的黑箱操作。例如,一行代码pipeline("sentiment-analysis")("这部电影太精彩了!")就能返回情感分类结果,但其内部实则是一个由预处理、模型计算、后处理三大核心环节构成的精密流水线。这三个环节既独立解耦又紧密协作,形成了从原始文本到业务洞察的完整处理链路。
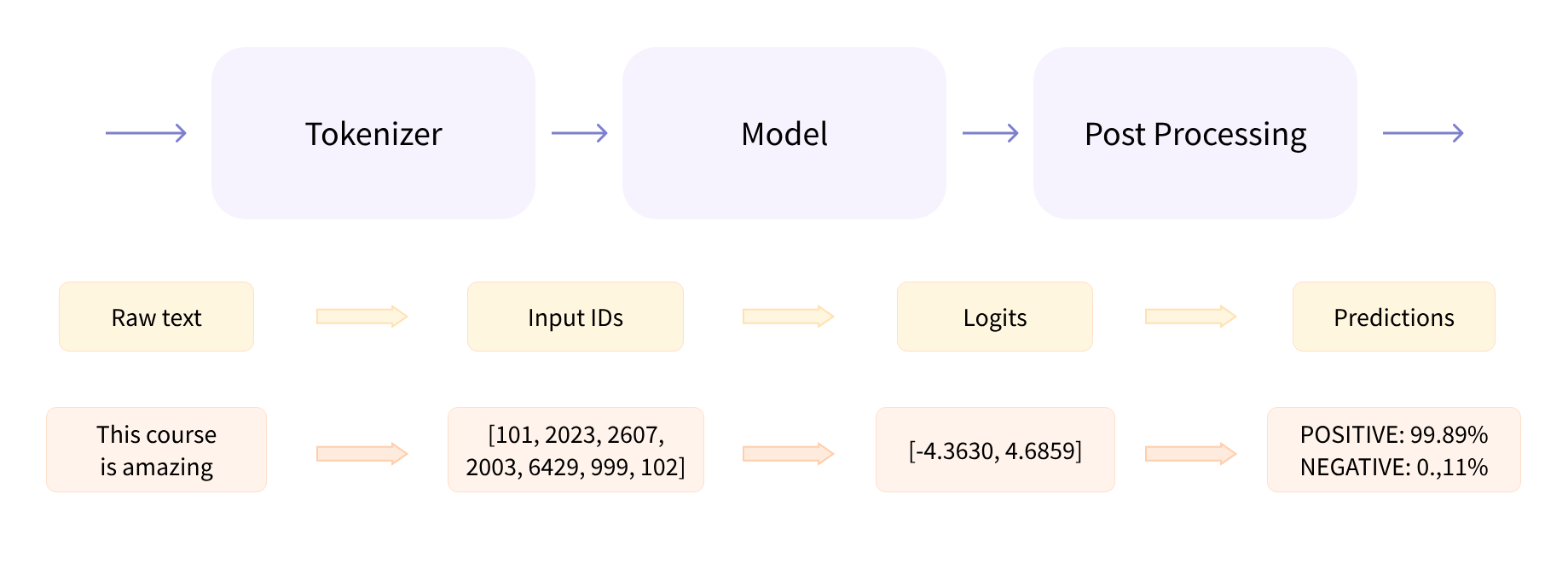
(一)、预处理:让文本成为模型能 “看懂” 的语言
1. Tokenizer:文本数字化的核心枢纽
Transformer 模型无法直接处理原始文本,就像人类无法直接理解二进制代码一样。这时,Tokenizer就成为了关键的 “翻译官”。它的职责主要有三个:
- 分词:将输入文本拆分为单词、子单词或符号,这些最小单位被称为
token。比如 “I've” 可能会被拆分为 “I” 和 “'ve”。 - 映射 ID:为每个
token分配一个唯一的数字 ID,即input ID,让模型能够识别和处理。 - 添加特殊标记:根据模型需求,添加如
[CLS](用于分类任务的句子起始标记)、[SEP](句子结束标记)等特殊标记,以及位置编码、段落标记等信息。
2. 代码实践:轻松加载与使用 Tokenizer
我们可以通过AutoTokenizer类轻松加载预训练好的分词器。以情感分析为例,其默认的 checkpoint 是distilbert-base-uncased-finetuned-sst-2-english,代码如下:
python
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
加载好分词器后,就可以将句子传入其中。通过return_tensors参数,我们可以指定输出的张量类型(PyTorch、TensorFlow 或 NumPy)。同时,padding和truncation参数会自动处理句子长度不一致的问题,确保输入模型的张量具有统一的形状。
python
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
输出结果是一个包含input_ids和attention_mask的字典。input_ids是每个句子中token的 ID 列表,attention_mask则用于标识有效token的位置(1 表示有效,0 表示无效)。
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
])
}(二)、模型计算:从隐状态到任务专属输出
1. 基础模型:捕捉通用语义特征
Transformers 库 提供的AutoModel类包含了基本的 Transformer 模块,它的作用是对预处理后的输入进行特征提取,输出高维的隐状态(hidden states)。这些隐状态是模型对输入文本的上下文理解,是后续任务处理的基础。
python
from transformers import AutoModel
model = AutoModel.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.last_hidden_state.shape) # 输出:torch.Size([2, 16, 768])
这里的输出形状包含三个维度:Batch size(一次处理的句子数)、Sequence length(句子分词后的token长度)、Hidden size(每个token的特征维度)。
2. 模型头:赋予模型任务专属能力
AutoModel输出的隐状态虽然包含了丰富的语义信息,但并不能直接用于具体的任务,比如情感分类。这时,就需要模型头(Model Head)来发挥作用了。模型头是附加在基础模型之上的特定任务层,通常由一个或几个线性层组成,它的作用是将高维的隐状态投影到任务所需的维度。
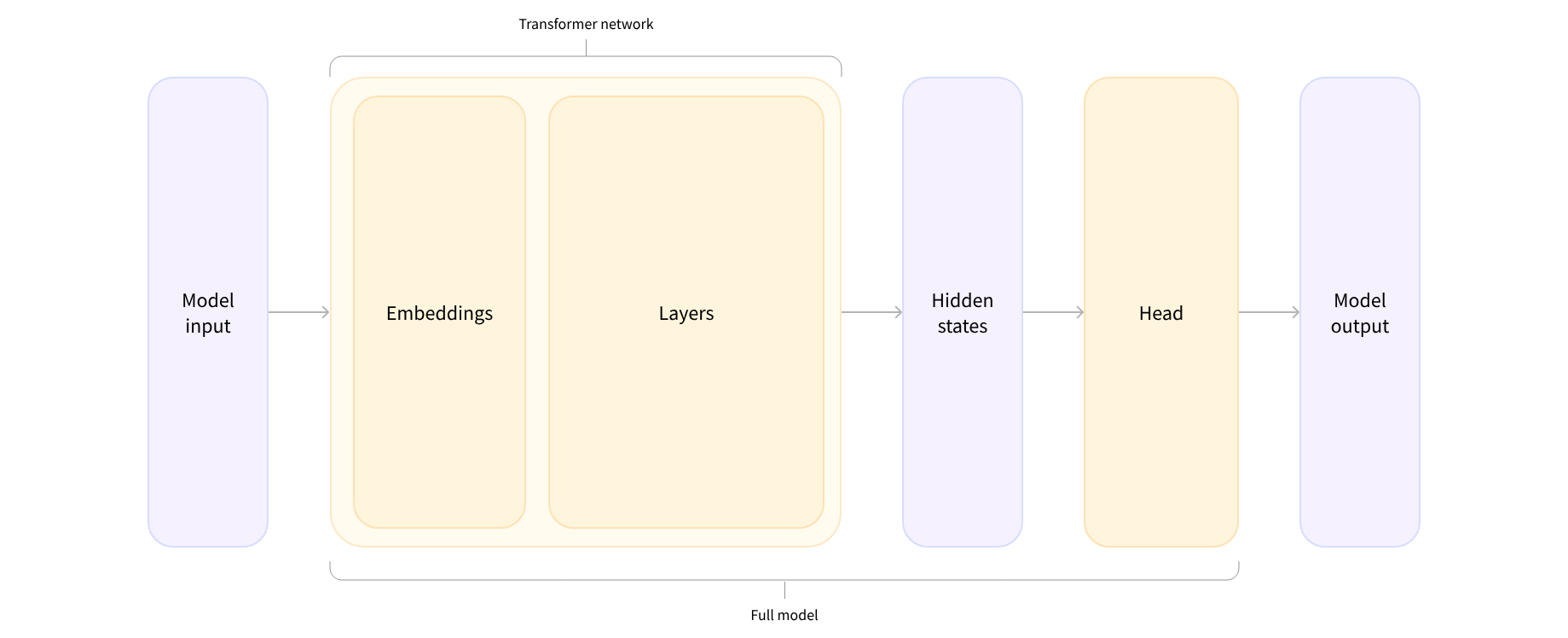
以情感分类为例,我们需要使用AutoModelForSequenceClassification类,它在AutoModel的基础上添加了一个序列分类头。这个分类头会将 768 维的隐状态映射为 2 维的logits(对应积极和消极两种标签的分数)。
python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape) # 输出:torch.Size([2, 2])
不同的任务需要不同的模型头,比如因果语言生成任务需要Causal LM Head,问答任务需要Question Answering Head等。通过选择正确的模型类,我们可以轻松获得任务相关的输出。
(三)、后处理:从原始分数到可读结果
1. Logits 转概率:SoftMax 层的魔法
模型输出的logits是未标准化的分数,不能直接作为概率使用。我们需要通过 SoftMax 层将其转换为概率分布,这样就能得到每个标签的概率值了。
python
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
输出结果中,每个元素代表对应句子属于某个标签的概率,比如第一句的积极概率为 0.9598,消极概率为 0.0402。
2. 标签映射:id2label 的作用
为了将概率值对应到具体的标签名称,我们可以通过模型配置的id2label属性来获取标签映射关系。
python
print(model.config.id2label) # 输出:{0: 'NEGATIVE', 1: 'POSITIVE'}
这样,我们就可以将模型的输出转换为人类可读的结果,比如 “POSITIVE” 和 “NEGATIVE”。
二、手动复现 Pipeline 全流程
现在,我们已经了解了 Pipeline 的三个核心步骤,接下来就可以手动复现情感分析的全流程了。
python
# 1. 预处理
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer(["积极句子", "消极句子"], return_tensors="pt")
# 2. 模型推理
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
outputs = model(**inputs)
# 3. 后处理
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
labels = [model.config.id2label[pred.argmax()] for pred in predictions]
print(labels) # 输出:['POSITIVE', 'NEGATIVE']
三、实践建议:让 Pipeline 为你所用
1. 标准化优势:快速上手,提升效率
Hugging Face 的pipeline封装了预处理、模型计算和后处理的全流程,让我们无需重复造轮子,能够快速实现各种 NLP 任务。对于新手来说,这是一个非常友好的功能,能够大大降低学习成本。
2. 定制化空间:灵活扩展,满足需求
如果我们需要对某个环节进行深度优化,比如自定义预处理逻辑、替换模型头,或者调整后处理方式,都可以将 Pipeline 拆解开来,单独实现每个环节。这样既能利用预训练模型的优势,又能满足特定场景的需求。
3. 模型选择:根据任务,精准匹配
不同的任务需要选择对应的模型类,下表列出了常见任务及其对应的模型类:
| 任务类型 | 对应模型类(带任务头) | 输出类型 |
|---|---|---|
| 序列分类 | AutoModelForSequenceClassification | logits([batch, num_labels]) |
| 因果语言生成 | AutoModelForCausalLM | logits([batch, seq_len, vocab_size]) |
| 问答任务 | AutoModelForQuestionAnswering | start/end logits |
通过正确选择模型类,我们可以避免 “加载基础模型却无法获得任务结果” 的常见误区。
总结
Hugging Face 的 Pipeline 就像一个高效的 NLP 生产线,将文本处理、模型推理和结果解析三个环节有机结合起来。通过Tokenizer、基础模型和模型头的分工协作,它能够轻松应对各种 NLP 任务。理解 Pipeline 的内部机制,不仅能让我们更高效地调用预训练模型,还能根据实际需求进行灵活定制。
希望本文能帮助你深入理解 Hugging Face Pipeline 的工作原理,在实际项目中更好地应用这些技术。如果你在使用过程中遇到任何问题,或者有想了解的其他 NLP 技术,欢迎在评论区留言讨论。别忘了点赞收藏,后续我们会分享更多 Hugging Face 的进阶技巧,让我们一起在 NLP 的世界里不断探索!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 38
38 0
0- 0



 已为社区贡献249条内容
已为社区贡献249条内容

所有评论(0)