RAG框架简介(LangFlow、LlamaIndex、Haystack)
RAG技术的核心在于构建一个“检索-生成”的协作体系。当用户提出问题时,检索器会从外部知识库(如企业文档库、专业数据库、网页内容等)中,依据关键词匹配、语义相似性等策略检索相关信息;随后,检索到的信息与用户问题一同被输入至生成器,经过处理后输出更准确、可靠的回答[28]。在RAG技术生态中,商用框架多由大型企业主导研发,这类框架通常具备功能完备、稳定性强、技术支持体系完善等优势,但存在使用成本高、
《大模型应用开发 鲍亮,李倩 清华大学出版社》【摘要 书评 试读】- 京东图书
目录
RAG技术的核心在于构建一个“检索-生成”的协作体系。当用户提出问题时,检索器会从外部知识库(如企业文档库、专业数据库、网页内容等)中,依据关键词匹配、语义相似性等策略检索相关信息;随后,检索到的信息与用户问题一同被输入至生成器,经过处理后输出更准确、可靠的回答[28]。在RAG技术生态中,商用框架多由大型企业主导研发,这类框架通常具备功能完备、稳定性强、技术支持体系完善等优势,但存在使用成本高、定制化难度大等问题;开源框架则依托全球开发者社区的力量,具有极高的灵活性与扩展性,开发者可自由修改和优化代码,不过其技术支持相对薄弱,稳定性也参差不齐[29]。
6.3.1 LangFlow
1. 框架概况
LangFlow诞生于RAG技术逐渐普及但开发门槛较高的背景下,由社区开发者为降低技术使用难度而创建。作为一款基于Python开发的开源RAG框架,它以突破性的可视化界面设计,重新定义了RAG技术的开发模式,一经推出便在开发者群体中引发强烈反响[30]。
LangFlow的开发初衷是让更多开发者,尤其是缺乏深厚编程经验的人员,也能轻松参与到RAG应用开发中。其核心团队由来自不同领域的开发者组成,他们致力于将复杂的RAG技术流程转化为直观的可视化操作。自发布以来,LangFlow不断迭代更新,社区规模持续扩大,吸引了众多开发者贡献代码、反馈使用体验,逐步成为RAG领域备受关注的开源项目。

图6.1 LangFlow框架设计图
2. 特点
LangFlow采用模块化的先进架构设计,将RAG系统中的关键组件,如检索器、生成器、知识库连接器等,进行高度抽象与封装。用户仅需通过浏览器访问其可视化界面,即可像搭建积木一样,通过简单的拖拽和连线操作,快速完成RAG工作流的搭建。以搭建电商产品问答系统为例,用户只需从组件库中拖出“文档检索器”,将其与电商平台的产品说明文档库连接;再拖出“语言生成器”,选择对接GPT-3.5 Turbo API;最后通过连线将两者串联,一个基础且功能完备的问答系统框架便搭建完成。经实际测试,使用LangFlow搭建简易问答系统的时间,相较于传统代码开发方式,效率提升幅度高达约70%[31]。
在功能特性方面,LangFlow展现出强大的兼容性与适应性。其支持TF-IDF稀疏检索和基于Transformer的稠密检索两种主流检索技术。TF-IDF稀疏检索适用于数据规模较小、对文本关键词匹配要求较高的场景,如小型企业的内部FAQ系统。某小型服装企业借助TF-IDF检索,能够快速精准地定位到用户问题对应的产品信息。而基于Transformer的稠密检索,则在处理大规模文本数据时表现卓越,例如在新闻资讯类问答系统中,面对海量新闻文章,它能够在每秒处理上千条用户查询的情况下,将响应时间严格控制在数百毫秒内,快速准确地找到相关新闻内容。此外,LangFlow与众多开源和商用语言模型高度兼容,除了广为人知的GPT系列,还支持LLaMA、Falcon等开源模型。同时,它为开发者提供了丰富的参数自定义配置选项,开发者可以根据实际需求,灵活调整检索器的相关性阈值、修改生成器的最大生成长度等。例如,在开发智能客服系统时,将生成器的最大生成长度设置为300字,既能保证回答内容的完整性,又避免了回复过于冗长;调低检索器的相关性阈值,则可以获取更多可能相关的信息,从而提高回答的全面性[32]。
然而,LangFlow也存在一些不容忽视的局限性。由于其高度依赖外部语言模型,在使用性能卓越的商用模型时,会产生较高的调用成本。以GPT-4为例,按照OpenAI的官方定价,每1000个tokens的输入成本为0.03美元,输出成本为0.06美元,对于高频使用的企业应用而言,每月的调用成本可达数万美元,这无疑给企业带来了巨大的经济压力。此外,虽然可视化界面极大地降低了开发门槛,但在处理复杂逻辑,如多轮对话管理、基于复杂条件判断的知识检索等场景时,其灵活性相对不足。并且,作为开源框架,LangFlow在法律、医疗等特定专业领域的优化和针对性功能开发尚不完善,开发者往往需要投入额外的时间和精力进行二次开发[33]。
6.3.2 LlamaIndex
1. 框架概况
LlamaIndex在学术界对知识处理需求日益增长,以及工业界追求更高效智能应用的背景下应运而生,迅速在RAG技术领域崭露头角,成为Python生态下备受瞩目的开源框架[34]。
该框架由一群致力于推动知识管理与自然语言处理融合的研究者和开发者共同创建。他们洞察到在处理海量数据时,传统方法难以满足高效检索和精准生成的需求,于是着手开发LlamaIndex。项目启动后,凭借其创新的设计理念和强大的功能潜力,吸引了众多开发者和研究机构的关注与参与。随着时间推移,LlamaIndex不断吸收社区反馈,优化功能,逐渐形成了一套成熟且完善的RAG解决方案,在学术界的知识图谱构建、工业界的智能客服等领域都得到了广泛应用。
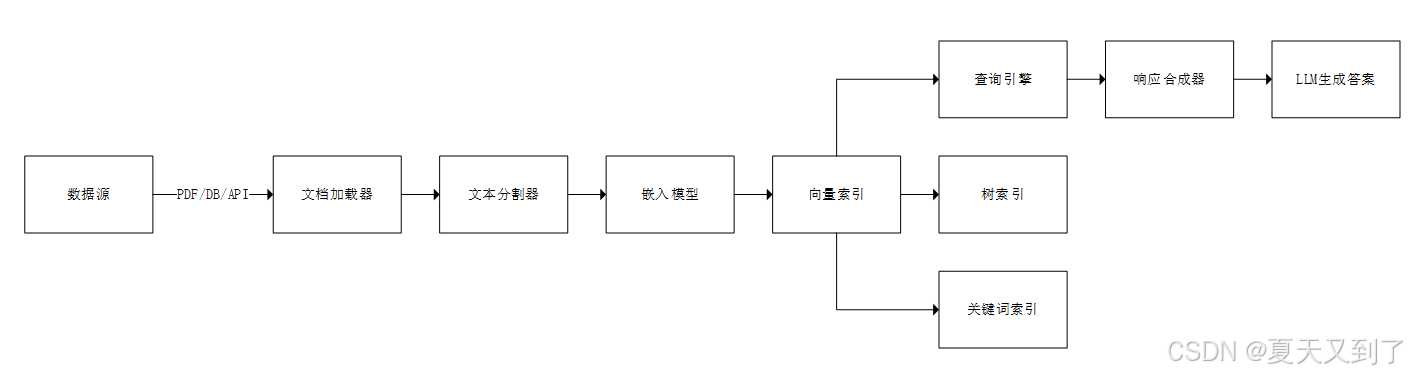
图6.2 LlamaIndex框架设计图
2. 特点
LlamaIndex的核心竞争力在于其强大且全面的知识处理能力。在数据源接入方面,它几乎支持所有常见的数据格式和存储类型,堪称数据处理的“多面手”。对于结构化数据,如MySQL、PostgreSQL数据库中的表格数据,LlamaIndex能够通过SQL查询语句,精准提取相关内容,并将其转化为适合检索的格式。在处理销售数据时,可依据时间、地区等条件,通过编写SQL语句快速提取特定时间段、特定地区的销售记录。对于非结构化数据,如PDF文档、Markdown文件、网页内容等,它内置的智能解析器能够自动识别文本结构,进行高效的解析和索引构建。在处理企业年度报告这类包含大量图表、公式的复杂PDF文档时,LlamaIndex可通过先进的布局分析和OCR技术,准确提取文本信息,并构建相应的知识图谱或向量索引。某科研机构曾使用Llama Index处理上万篇学术论文,借助其自动解析和索引功能,将原本需要数周时间的论文处理工作缩减至短短数天,显著提升了工作效率。
在检索策略上,LlamaIndex创新地采用混合检索策略。该策略先利用稀疏检索,快速过滤出可能相关的文档,缩小检索范围;再通过稠密检索,在缩小后的范围内进行语义层面的精准匹配,这种方式在保证检索效率的同时,显著提高了检索的准确性。有实验数据表明,在处理包含10万篇文档的大型知识库时,LlamaIndex的混合检索策略相较于单一的稀疏检索或稠密检索,检索准确率提升幅度超过25%[35]。在与语言模型的集成方面,LlamaIndex不仅支持常见的开源模型,还针对不同模型的特点进行了深度优化适配。它提供了一系列功能强大的工具和接口,方便开发者对模型进行微调。以医疗领域为例,开发者可以基于开源的医疗领域专用模型,结合医院的病历数据,利用LlamaIndex进行针对性微调,使模型能够更好地回答患者关于疾病诊断、治疗方案等方面的问题。某三甲医院采用此方法微调后的模型,在回答患者常见问题时,准确率从原来的70%大幅提升至90%。此外,LlamaIndex的智能路由功能也是一大亮点,它能够根据用户的查询内容,动态选择最合适的知识源和处理路径。当用户询问“如何治疗糖尿病”时,系统会优先从专业医学文献库中检索信息,而不是普通的科普文章库,从而确保提供的回答更加专业、准确[36]。
尽管Llama Index功能强大,但在使用过程中也面临一些挑战。由于其功能丰富、架构复杂,涉及数据节点(Node)、索引(Index)、查询引擎(QueryEngine)等诸多核心概念,对于初学者来说,学习成本相对较高,需要花费大量时间和精力去理解和掌握。而且,在处理大规模数据时,索引构建和检索的性能会受到一定影响。实验数据显示,当索引的文档数量超过10万篇时,首次索引构建时间可能超过2小时,检索延迟也会增加至数百毫秒,严重影响系统的响应速度,此时需要进行额外的优化和配置。虽然Llama Index社区提出了分布式索引构建、近似最近邻搜索等优化方案,但这些方案的实施难度较大,对开发者的技术能力要求较高[37]。
6.3.3 Haystack
1. 框架概况
Haystack在开放域问答系统需求不断增长,对RAG技术灵活性要求日益提高的背景下诞生,是一个专注于构建开放域问答系统的Python开源框架,在RAG技术的实际应用中占据重要地位[38]。Haystack框架设计图如图6.3所示。
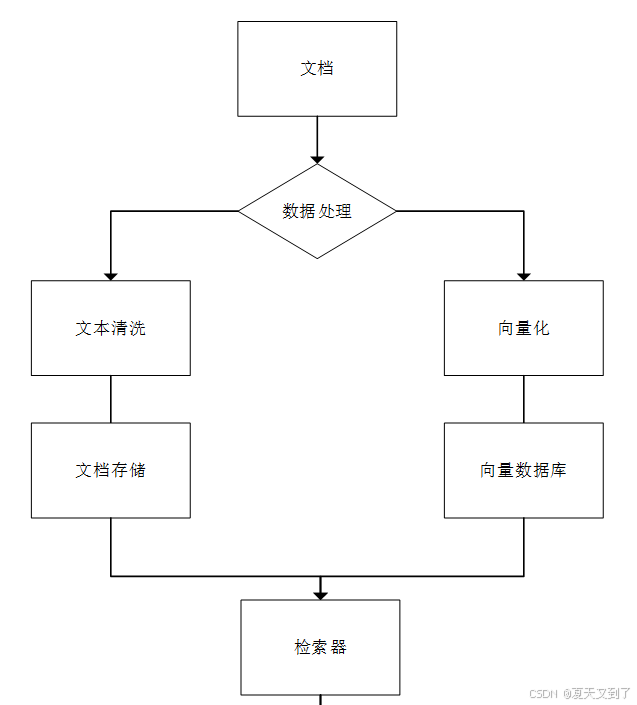
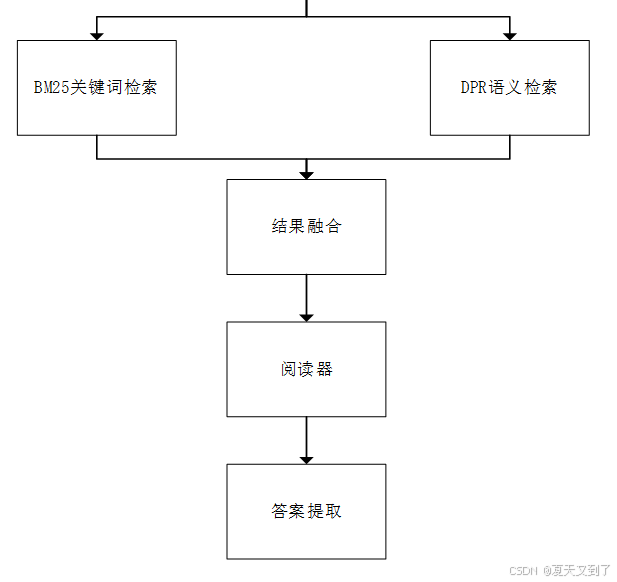
图6.3 Haystack框架设计图
该框架由一群专注于自然语言处理和信息检索的开发者发起,旨在为开发者提供一个灵活、可扩展的工具,以满足不同领域对问答系统的多样化需求。项目初期,开发者们深入研究了现有RAG框架的优缺点,结合开放域问答的特点,设计了Haystack的模块化架构。随着开发的推进,Haystack吸引了来自全球各地的开发者加入,他们贡献了丰富的功能模块和应用案例。因此,Haystack逐渐成为开发者构建问答系统的首选框架之一,广泛应用于法律、金融、教育等多个领域。
2. 特点
Haystack的架构采用模块化和可插拔的设计理念,这种设计赋予了框架极高的灵活性和扩展性。其主要由文档存储、检索模块、阅读器模块等核心部分组成。在文档存储方面,Haystack支持多种存储方式,包括Elasticsearch、FAISS、SQLite等。Elasticsearch适用于大规模分布式数据存储和快速检索,在处理互联网级别的海量数据时表现出色;FAISS则在向量存储和相似性搜索方面具有独特优势,非常适合基于语义的稠密检索场景;SQLite则便于在小型应用或本地开发中使用,具有轻量级、易部署的特点。检索模块提供了基于关键词的传统检索和基于语义的稠密检索等多种算法,并且支持开发者根据实际需求自定义检索策略。阅读器模块可以集成各种语言模型,如BERT、RoBERTa、Flan-T5等,用于对检索到的文档进行深入理解和答案提取[39]。
在实际应用中,Haystack的灵活性和可扩展性得到了充分体现。以构建法律问答系统为例,开发者可以使用Haystack连接法律条文数据库作为知识源,通过自定义的检索策略,如结合法律条款的章节结构进行检索,快速筛选出相关法律文献;再利用针对法律领域微调的RoBERTa模型作为阅读器,对检索到的文献进行深度分析,提取出准确的答案。某法律科技公司基于Haystack开发的智能法律咨询系统,在处理日常法律问题时,能够快速从庞大的法律条文库中找到相关依据,并生成专业、准确的回答。此外,Haystack还提供了丰富的工具和示例资源,包括数据预处理工具、模型评估工具等,以及“从零搭建问答系统”的详细教程,这些资源已帮助超过5000名开发者成功构建自己的应用,极大地降低了开发门槛,提高了开发效率[40]。
但Haystack也存在一些不足之处。由于其模块化设计,在系统搭建和配置过程中,需要开发者对各个模块有较深入的了解,否则很容易出现模块之间的兼容性问题。在混合使用不同版本的检索模块和阅读器模块时,可能会因为接口不匹配导致系统无法正常运行。而且,在处理复杂问题,如需要多轮推理、跨文档综合分析的问题时,多个模块协同工作可能会导致性能瓶颈。有研究显示,在处理包含100个以上文档的复杂查询时,系统响应时间可能会超过5秒,严重影响用户体验,此时需要开发者进行精细的调优工作[41]。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)