我抓通义灵码当“壮丁”,让Qwen3-Coder“爆肝”一个CNN训练平台
使用Qwen3-Coder搭建CNN训练平台体验
千问团队前一段时间搞出了一个大动静,开源Qwen3-Coder模型。据千问团队描述:Qwen3-Coder-480B-A35B-Instruct 在 Agentic Coding、Agentic Browser-Use 和 Agentic Tool-Use 上取得了开源模型的 SOTA 效果,可以与 Claude Sonnet4 媲美。[Qwen3-Coder: 在世界中自主编程 | Qwen]
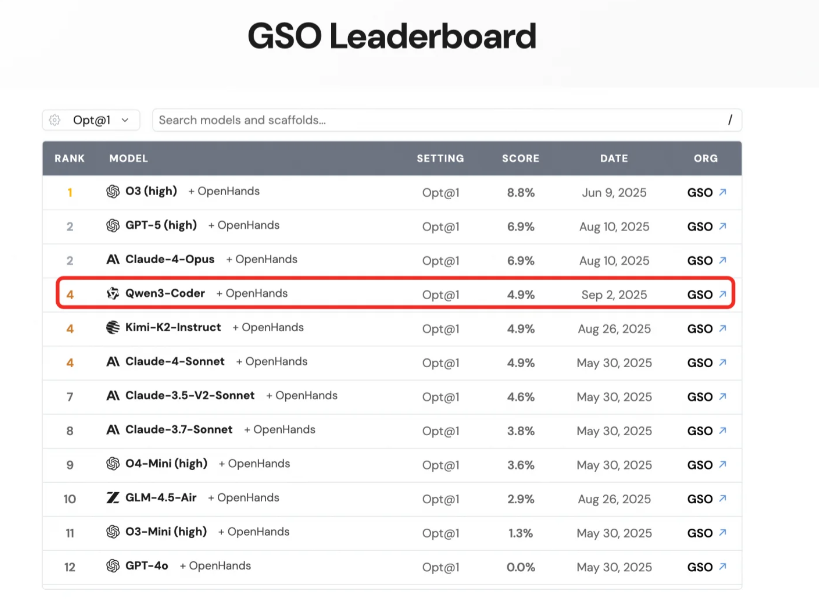
各大平台如公众号、CSDN等纷纷涌现出大量关于Qwen3-Coder的讨论,既有对其卓越性能和流畅使用体验的赞誉,也不乏质疑之声。
所以,Qwen3-Coder究竟是能真正分担核心开发任务的“伙伴”,还是仅限于代码补全和函数生成的“高级玩具”?
为了测评Qwen3-Coder的编程能力,我基于vscode插件通义灵码,利用Qwen3-Coder作为核心开发工具,从零构建一个功能完备的卷积神经网络(CNN)模型训练平台。本文将详细记录这一过程,分享Qwen3-Coder在不同开发阶段的能力表现、亮点以及遇到的瓶颈。
目前,该项目已经初步完成,所有源代码和详细说明文档均已上传至GitHub,欢迎感兴趣的读者前往查阅和体验。
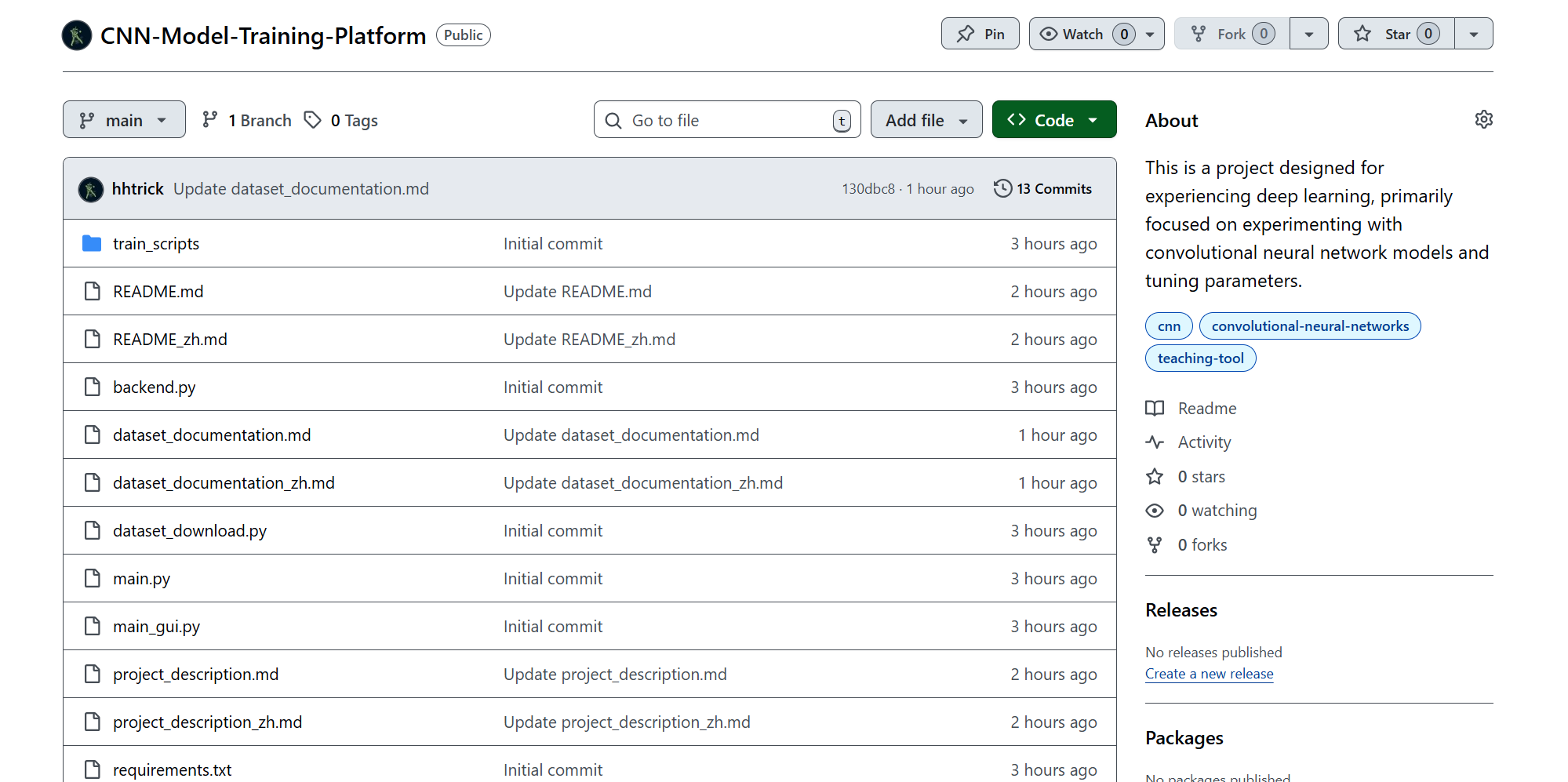
先“晒一晒”最终成果
首先,让我们看看最终的成果。这个平台不是一个简单的玩具项目,它具备了研究和学习所需的核心功能:
-
内置10种经典CNN模型:从开山鼻祖 LeNet 及其四大魔改(ReLU、Dropout、BN),到里程碑式的 AlexNet、VGG、NiN,再到深度学习时代的王者 ResNet 系列(ResNet-18/34),一应俱全。
-
支持多种主流数据集:囊括了经典的 MNIST、FashionMNIST,更复杂的 EMNIST(含6个子集),以及一个更具挑战性的树叶分类数据集 classify-leaves。
-
双操作界面:提供了简洁高效的 命令行(CLI) 和直观易用的 图形界面(GUI),满足不同场景下的使用需求。
-
完善的训练与可视化:支持实时显示损失和准确率曲线,并提供模型保存、加载和日志记录等全套管理功能。
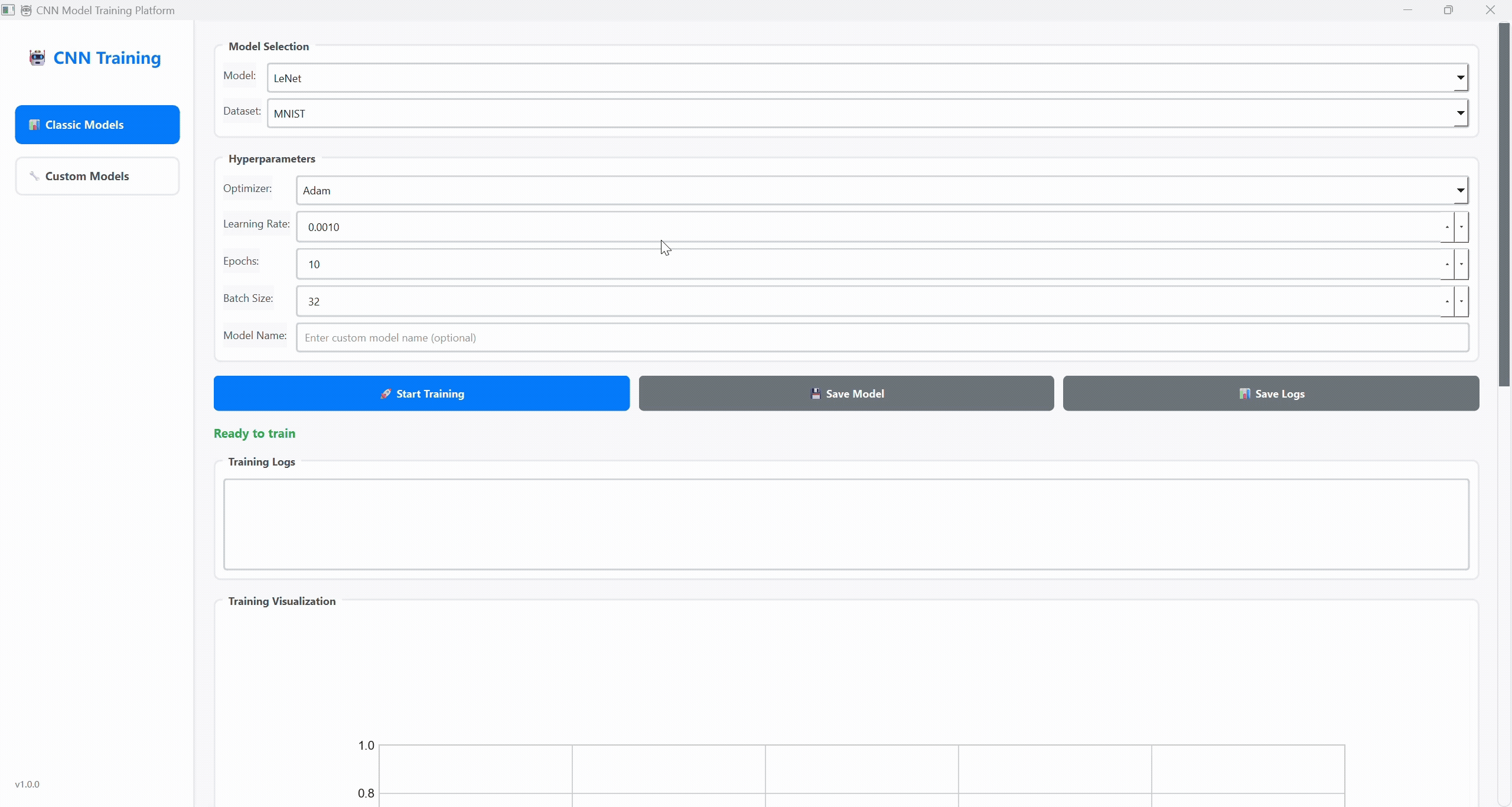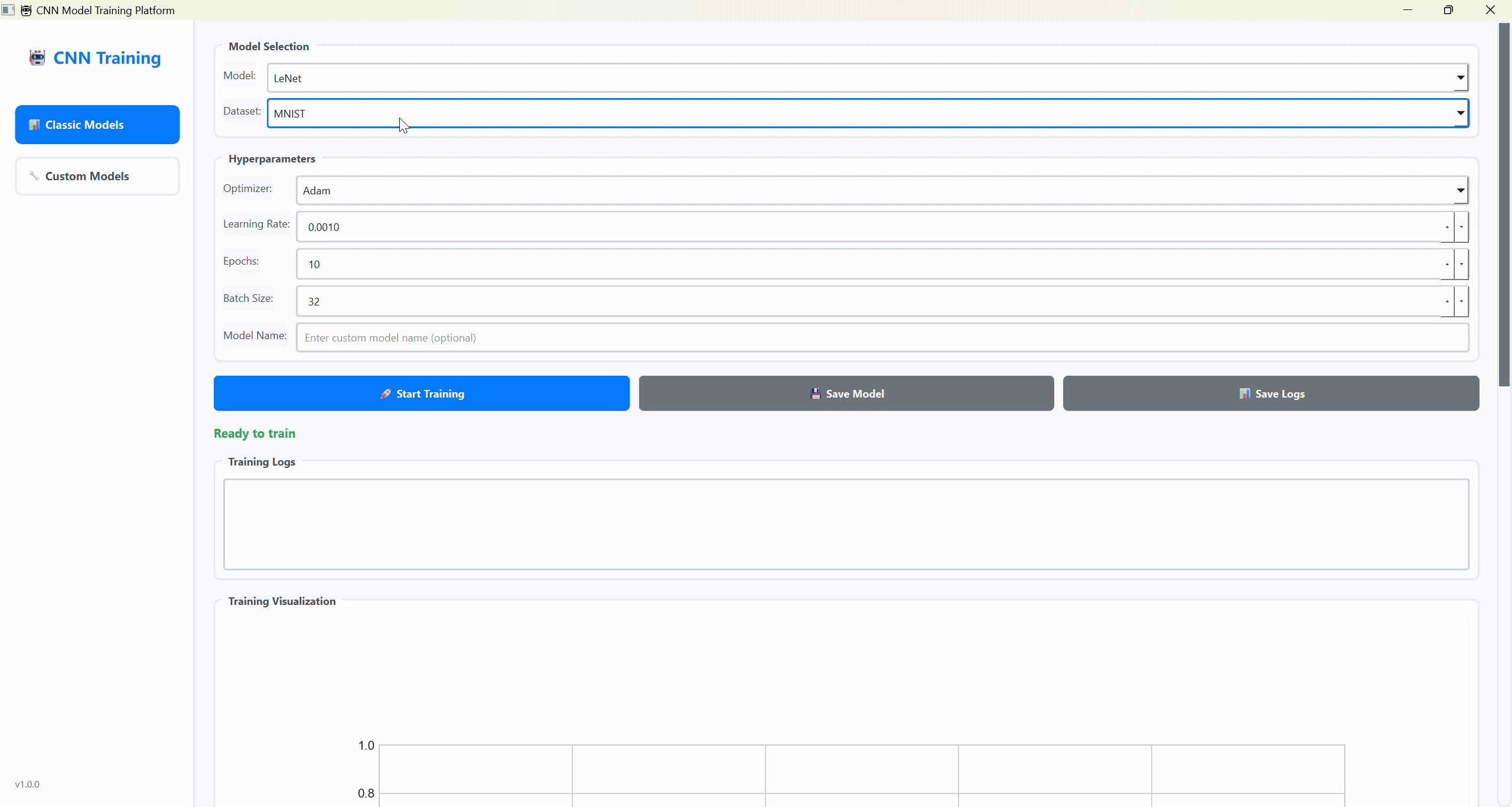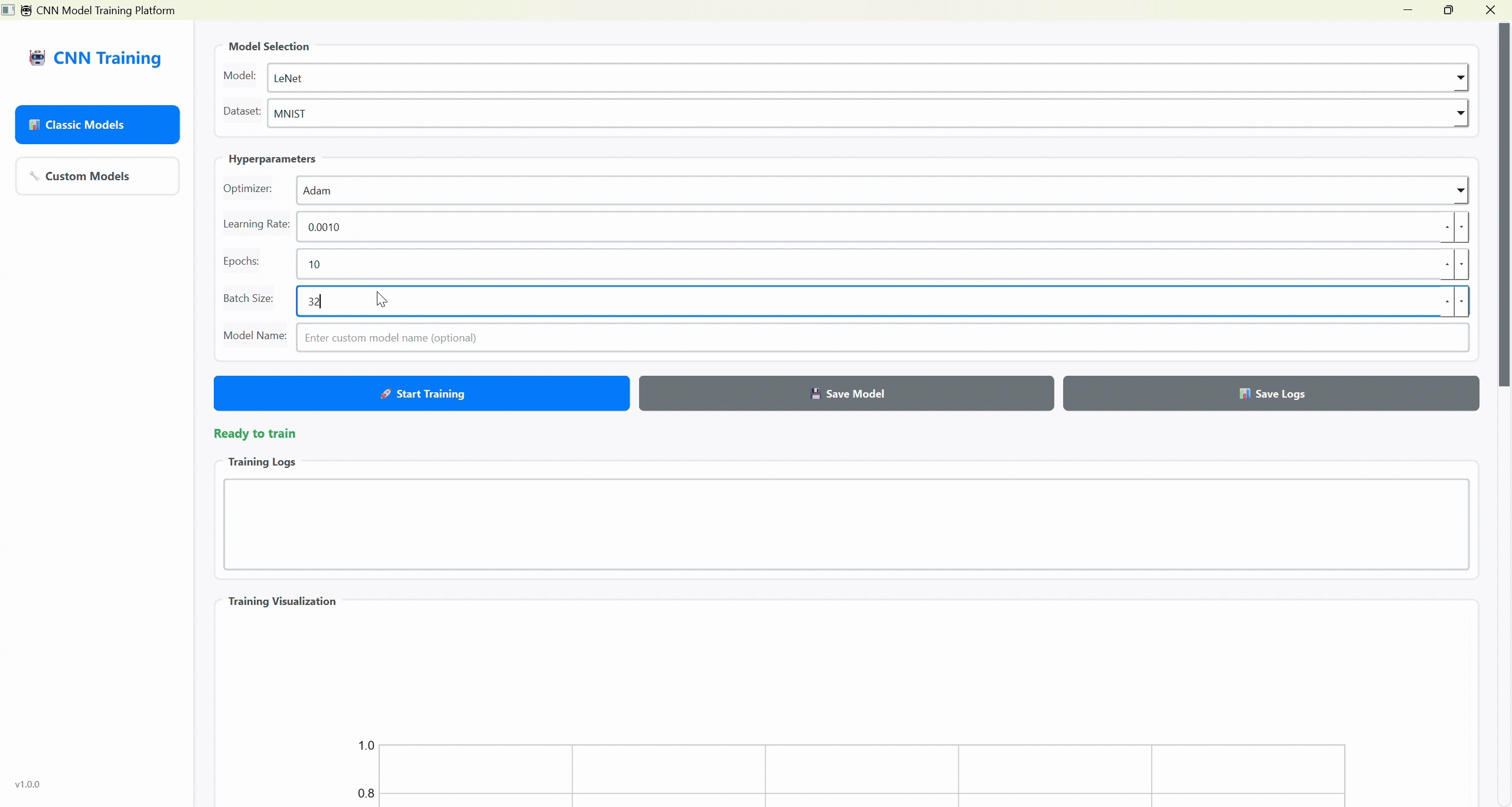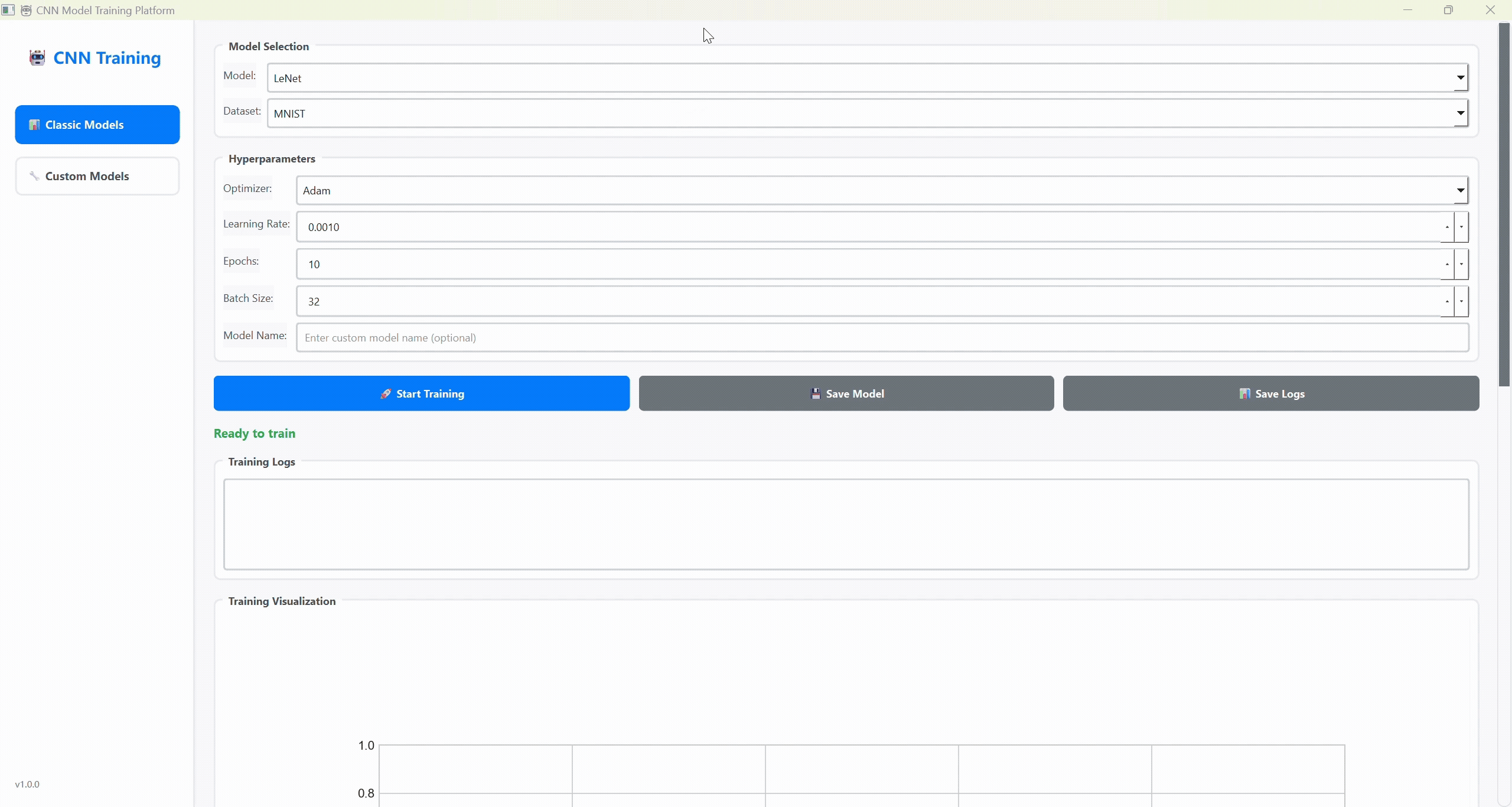
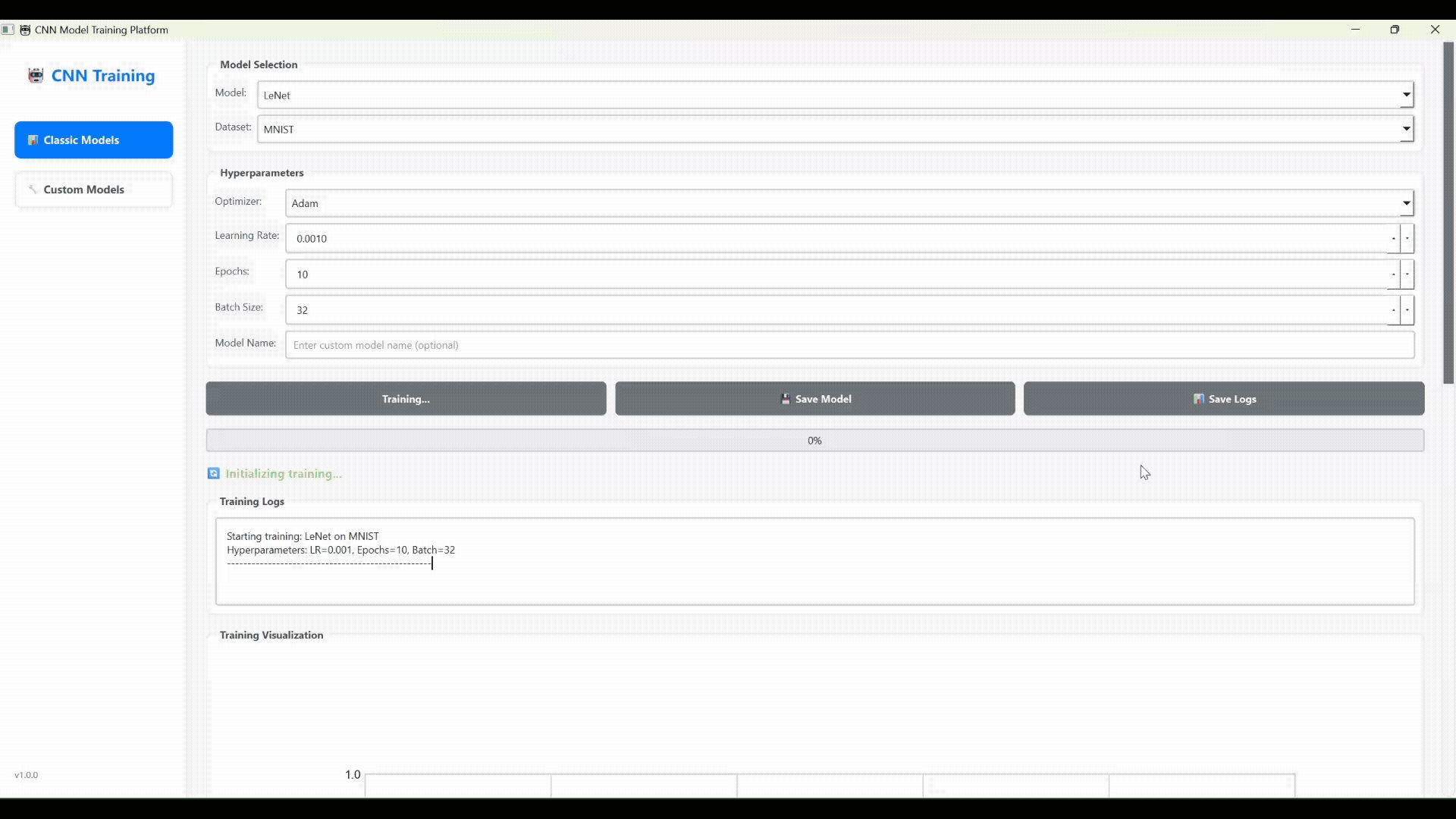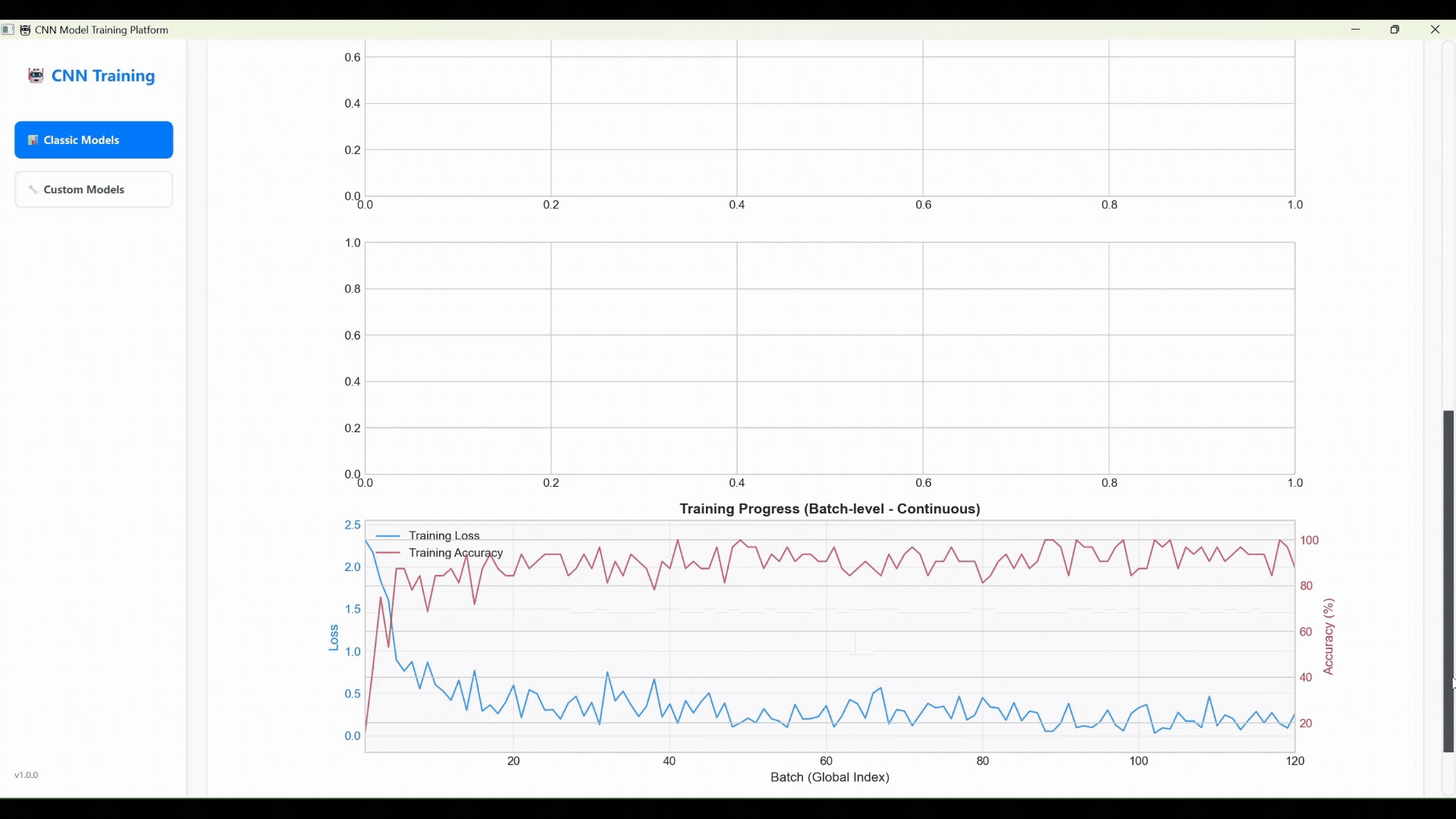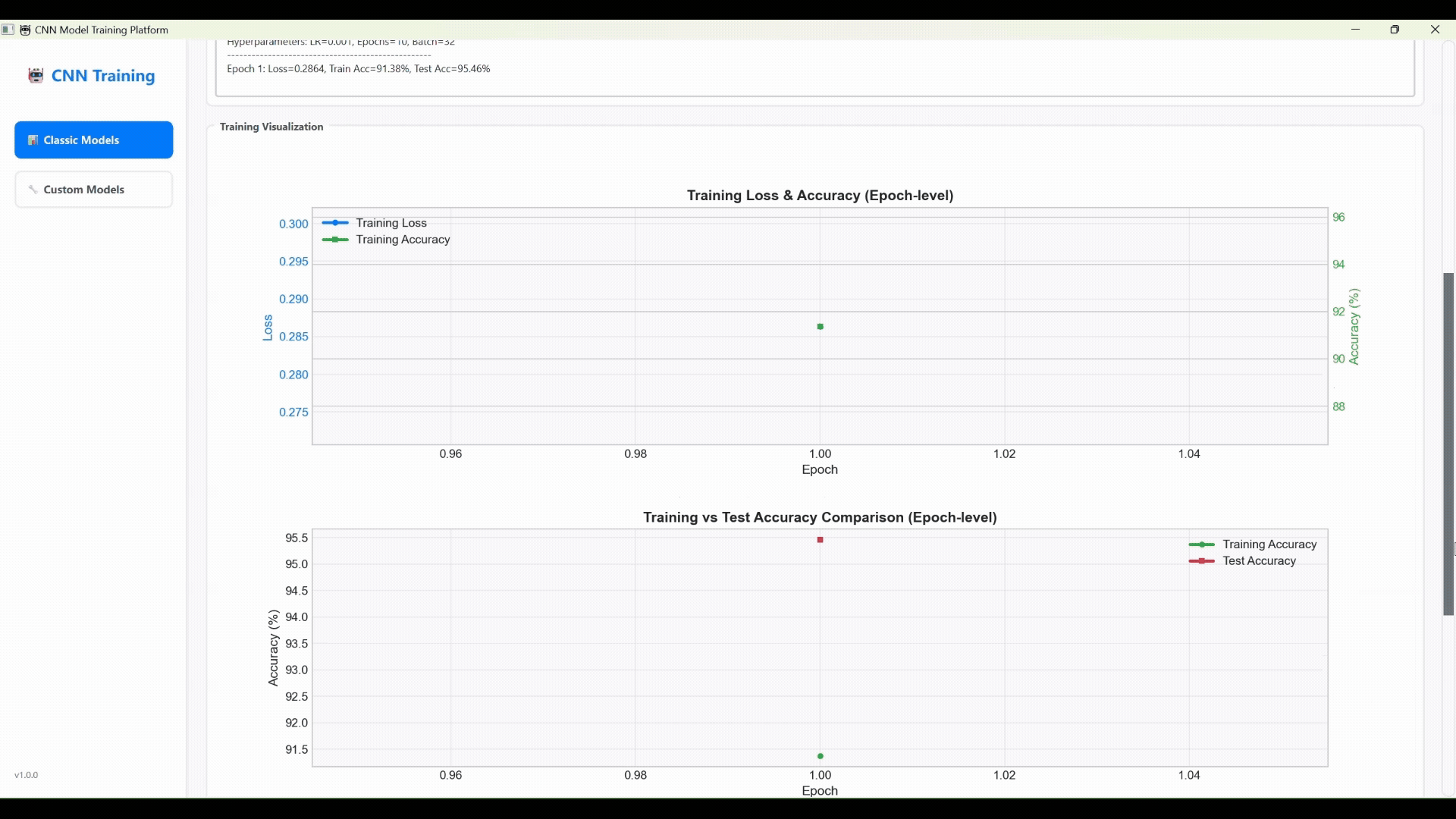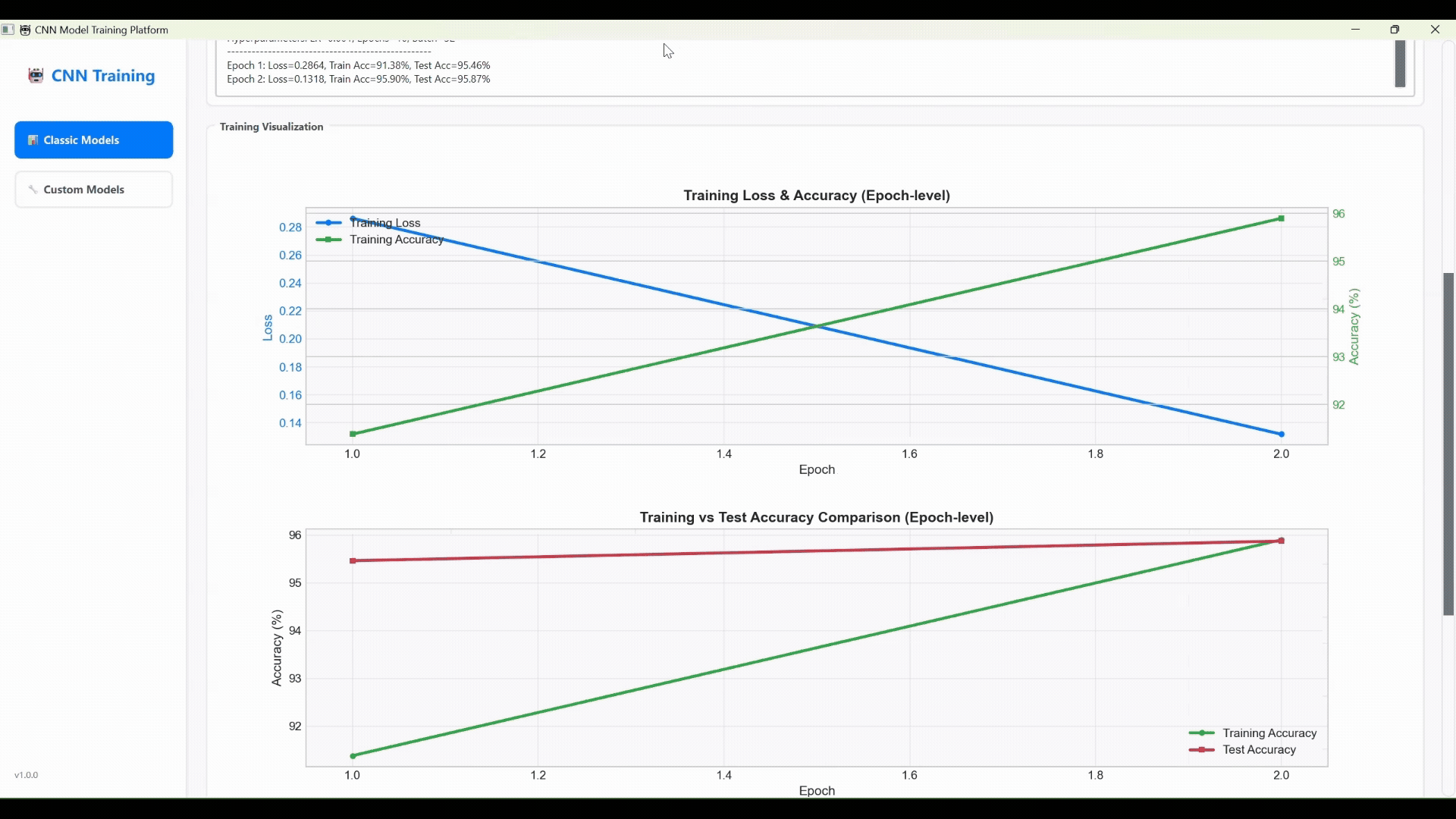
高光时刻:这位AI副驾,真有点东西!
在项目初期,通义灵码的表现简直让我惊呼“未来已来”,尤其是在这几个方面:
1. 代码生成:指哪打哪,干净利落
对于目标明确的单个任务,Qwen3-Coder 的效率高得离谱。train_scripts/ 目录下的所有模型脚本,还有那些数据处理的小工具(dataset_download.py, split_classify_leaves.py),几乎都是一次生成就未做多余的改动和debug。比如,当我告诉它要实现LeNet网络结构时,它一次性就完成编写,我只需要在输入通道数等细节上稍作调整,就能直接运行。
# 示例:LeNet模型代码片段
class LeNet(nn.Module):
def __init__(self, num_classes=10, input_channels=1):
super(LeNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(input_channels, 6, kernel_size=5), # 动态输入通道
nn.AvgPool2d(2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.AvgPool2d(2, stride=2)
)
# ... 其他代码2. 知识储备:比我想象的还要丰富
更让我惊讶的是,Qwen3-Coder对深度学习领域的知识掌握得相当扎实。无论是各种经典CNN模型的结构细节,还是各个数据集的特点和使用方法,它都能娓娓道来并且准确实现。
比如在处理EMNIST数据集时,它清楚地知道这个数据集有6个不同的分割(byclass、bymerge、balanced、letters、digits、mnist),并且能正确地为每个分割下载数据。这种专业程度,让我这个"半吊子"都自愧不如。
# Qwen3-Code编写的dataset_download.py中的EMNIST数据集下载代码
emnist_splits = ['byclass', 'bymerge', 'balanced', 'letters', 'digits', 'mnist']
for split in emnist_splits:
print(f"Downloading EMNIST {split}...")
try:
emnist_train = datasets.EMNIST(root='datasets', split=split, train=True, download=True, transform=transform)
emnist_test = datasets.EMNIST(root='datasets', split=split, train=False, download=True, transform=transform)
print(f"EMNIST {split} train set size: {len(emnist_train)}")
print(f"EMNIST {split} test set size: {len(emnist_test)}")
except Exception as e:
print(f"Failed to download EMNIST {split}: {e}")
```在编写模型文档时,它也能按照规范详细描述模型结构:
###Qwen3-Coder编写的LeNet模型介绍文档
LeNet是Yann LeCun等人在1998年提出的用于手写数字识别的卷积神经网络,是最早的卷积神经网络之一。
- 第一层:卷积层(C1),使用6个5×5的卷积核,输出特征图尺寸为28×28×6
- 第二层:池化层(S2),使用2×2的平均池化,步长为2,输出特征图尺寸为14×14×6
- 第三层:卷积层(C3),使用16个5×5的卷积核,输出特征图尺寸为10×10×16
- 第四层:池化层(S4),使用2×2的平均池化,步长为2,输出特征图尺寸为5×5×16
- 第五层:全连接层(F5),16×5×5输入,120个神经元输出
- 第六层:全连接层(F6),120个神经元输入,84个神经元输出
- 第七层:输出层,84个神经元输入,对应类别数的输出
激活函数:Sigmoid或Tanh
这种全面性让我意识到,Qwen3-Coder不仅仅是一个代码生成器,更像是一个深度学习领域的"百科全书"。
3. 文档撰写:它甚至比我还懂我的项目
项目收尾阶段,最神奇的一幕发生了。我抱着尝试的心态,没给任何提示,只说了一句:“当前目录下是一个完整的项目,查看整个项目的结构与代码,撰写文档:README.md,一版中文,一版英文。”
结果,它扫描了整个项目文件,反手就甩给我一份格式精美、内容全面的 README_zh.md。从功能介绍到安装使用,从命令行参数到项目结构,无一遗漏,甚至连 PyTorch、PySide6 等依赖库的版本都精确地列了出来。这表明它具备了相当不错的项目整体理解能力。
# CNN 模型训练平台
本项目提供了一个全面的平台,用于在各种数据集上训练和实验经典的卷积神经网络(CNN)模型。该项目专为机器学习研究人员、学生和深度学习爱好者设计,帮助他们理解和实验基础的CNN架构。
## 功能特点
### 10种经典CNN模型
- **LeNet系列**:
- LeNet (原始版本,使用Sigmoid/Tanh激活函数)
- LeNet-ReLU (使用ReLU激活函数)
- LeNet-ReLU-Dropout (使用ReLU和Dropout)
- LeNet-ReLU-Dropout-BN (使用ReLU、Dropout和批归一化)
- **ResNet系列**:
- ResNet (可配置深度)
- ResNet-18 (18层残差网络)
- ResNet-34 (34层残差网络)
- **其他经典模型**:
- AlexNet (2012年ImageNet竞赛冠军)
- VGG (视觉几何组网络)
- NiN (网络中的网络)
### 多数据集支持
- MNIST (手写数字)
- FashionMNIST (时尚物品)
- EMNIST (扩展版,包含字母和数字)
- byclass (62个类别)
- bymerge (47个类别)
- balanced (47个类别)
- letters (26个类别)
- digits (10个类别)
- mnist (10个类别)
- classify-leaves (叶子分类数据集)
### 双界面操作
- **命令行界面(CLI)**: 快速训练和实验
- **图形用户界面(GUI)**: 交互式模型训练和可视化瓶颈出现:跨文件协作的“鸿沟”
然而,当项目从“组件开发”阶段进入“系统集成”阶段时,Qwen3-Coder 遇到了巨大的挑战。
问题集中在 main.py(命令行入口)和 main_gui.py(图形界面入口)这两个核心文件的编写上。这两个文件需要调用和整合项目中其他多个模块的功能,例如:
-
从 backend.py 中调用统一的训练/评估逻辑。
-
根据用户选择,动态地从 models/classic_model/ 中加载不同的模型类。
-
处理数据集加载、超参数传递、线程管理(尤其在GUI中)等复杂逻辑。
在这一阶段,Qwen3-Coder 暴露了其在跨文件、跨模块编程上的短板。 它似乎很难理解不同文件之间的函数调用关系和数据流转。我反复尝试让它生成和修改代码,但结果往往是:
-
生成的代码存在明显的逻辑错误或接口误用。
-
在修复一个 bug 后,它可能会在其他地方引入新的 bug。
-
随着修改次数的增加,代码的混乱程度不降反增,最终陷入无法运行的困境。
最终,为了保证项目的顺利完成,main.py 和 main_gui.py 这两个关键的“粘合剂”文件,我在让 Qwen3-Coder 生成了基础框架后,转而使用了其他模型,并结合了一定的手动编码才最终完成。
总结:一位优秀的“组件工程师”,而非“项目架构师”
通过这次实战,我对Qwen3-Coder有了清晰的画像:
-
它是一位极其出色的“组件工程师”:对于定义清晰、范围可控的“原子任务”(如实现一个算法、编写一个工具函数、生成一段文档),它快、准、狠,能极大地将开发者从重复性工作中解放出来。
-
它还不是一位合格的“项目架构师”或“系统集成师”:当任务涉及到复杂的跨模块协作和深层逻辑依赖时,它会显得力不从心,难以维系全局的正确性。
对于开发者而言,现阶段与 AI 协作的最佳模式,或许是“人机结对编程”:我们作为“架构师”负责顶层设计、模块划分和最终集成;而 AI 作为“高效执行者”,负责快速实现我们设计的各个具体组件。
尽管Qwen3-Coder目前仍存在一些不足之处,但它所展现出的惊人潜力已然令人瞩目。在处理简单任务时,Qwen3-Coder完全有能力替代如Claude等闭源且价格昂贵的大型模型,为开发者提供更具性价比的解决方案。期待在千问团队的持续努力和不断优化下,Qwen3-Coder系列模型能够日益强大,不仅在简单任务上表现出色,更能在复杂场景中展现出卓越的性能,为广大开发者带来更多惊喜与便利。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)