最新最强的TTS语音合成技术来了!
最强的TTS语音模型
前言
在LLM大模型技术快速发展的同时,语音技术也在相应的借鉴得到了快速发展,之前的语音系列中笔者已经给大家解释过实时的端到端语音生成的一些前言技术,感兴趣的小伙伴可以穿越。
《端到端实时语音交互模型》:https://zhuanlan.zhihu.com/p/21004704888
今天要给大家介绍的是TTS领域最新的进展,其是由MiniMax于5月份刚推出的最新成果,效果非常强且支持多语种,而且其在公开的榜单上已sota(截止5.12),超越openai等国内外强劲模型。
大家可以去官方感受下以及可以亲自体验下demo,上面都有很多具体例子,我把链接放到下面
官方技术报告和demo:https://minimax-ai.github.io/tts_tech_report/
论文:https://arxiv.org/pdf/2505.07916
废话不多说,老规矩:我们来重点看下技术上到底是怎么具体实现的?
方法
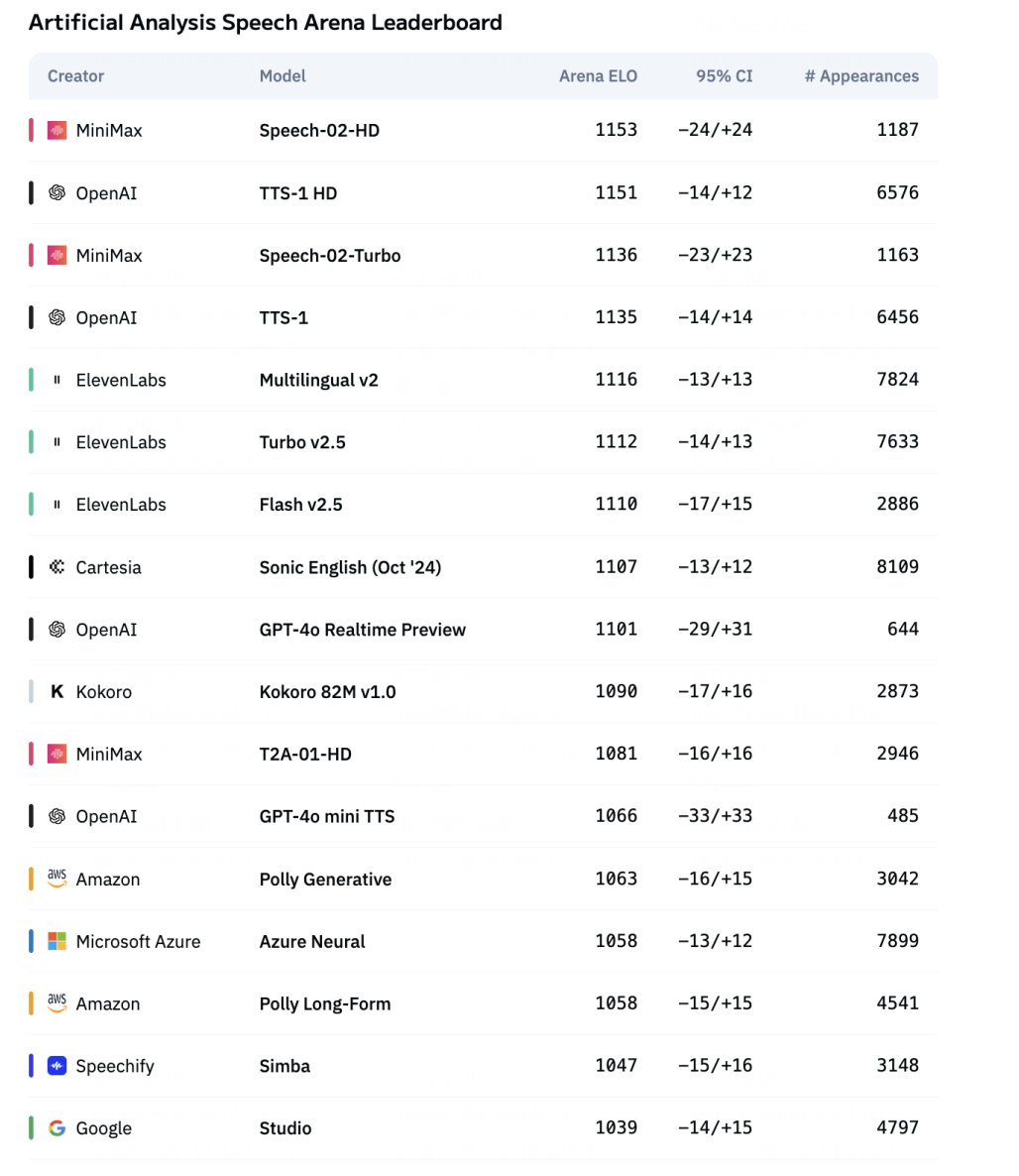
整体框架如下,可以看到整体采用的依然是Transformer,其最主要的创新在于两大块即图中的speaker encoder以及流模型(Flow Matching和Flow-VAE Decoder)。下面我们来分别看看。
(1)Autoregressive Transformer
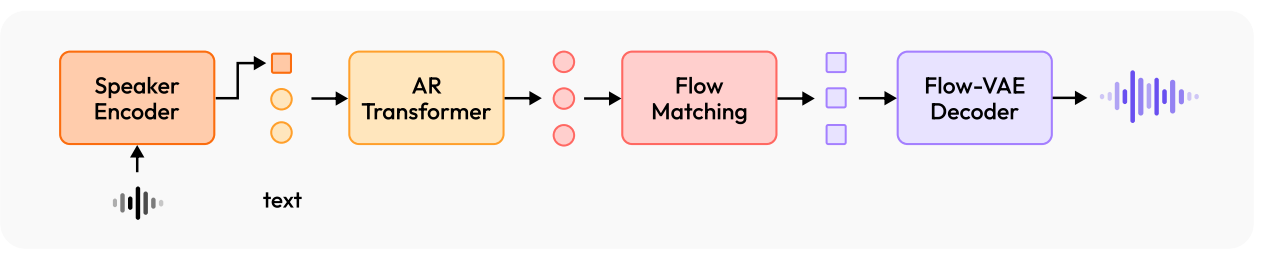
首先其采用的是autoregressive Transformer,这个其实没啥,最关键的是其引入了一个speaker encoder(这也没啥),然后学习的时候让其和autoregressive Transformer一起联动学习,换句话说speaker encoder是可被学习的,这和以往的大部分TTS模型做法大不相同(之前的做法都是选定好一个pre-trained的encoder)。
这一个改动就会带来诸多好处,比如最直接的就是效果的提升(这是显而易见的,毕竟学习了),还有就是能支持更多的语种(只要是训练过的都可以,而pre-trained的encoder只能支持好之前预训练过的语种),当然最大的好处也是本篇paper重点强调的zero-shot能力,下面我们展开来说说。
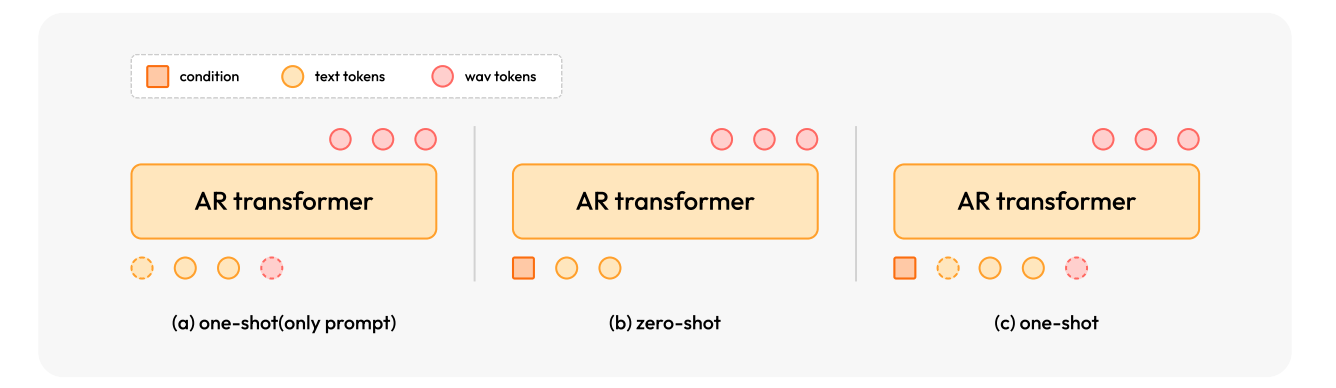
之前的一些工作诸如VALL-E、CosyVoice 2等大都需要同时提供被模仿者的语音+对应文本才能进行TTS(如图c),而本篇则去掉了“对应文本”即只需要被模仿者的语音即可(如图b),其将该语音通过上述说的可学习的encode表征成图中的condition,其只关注被模仿者的音色和韵律风格等而忽略说话的内容,做到了真真的端到端。这种方式被其称为zero-shot(不需要对应文本)。当然,文章也提到其也支持语音+对应文本这种方式即图c,这种方式被称为one-shot(需要一个对应的文本)。
虽然one-shot在精细控制等方面可能存在一定好处,但是本篇文章重点其实想说的还是其zero-shot的独特设计,因为其有很多优势比如:
(a) Text-Free Reference:不再需要对模仿者音频进行文本转录,真真做到上述说的只关注被模仿者的音色和韵律风格等而不受说话的内容的限制,把两者解藕开了(实际上在TTS场景,我们确实需要的仅仅是被模仿者的音色,而具体内容是由我们提供的)
(b) Rich Prosodic Variation and Flexible Decoding:由于其不用文本,所以就不用受特定文本音频韵律的限制,从而就可以有更广阔的解码空间,使得输出能够高度保真地还原被模仿者独特的声音特征。
© Robust Cross-Lingual Synthesis:由于encode能学习到与文本语言无关的声音特征,所以进而增强了跨语言合成。特别是在目标语言和参考语言不一样或语义不匹配的时候。
(d) Foundation for Extensibility:这个编码器可以提供的稳健且解耦的说话人表征,也为各种下游应用提供了灵活的基础比如情感控制等等(作者也在论文中举了很多例子,感兴趣的可以看看)
可以看到虽然前前后后说了很多好处,但其实具体做法改动就一个:仅仅使用语音作为encode的输入,而且其要连同整个模型一起被学习
(2)Latent Flow Matching
之前工作都是先要得到梅尔谱图,然后再由根据其解码得到声波。而这么做就不可避免的在到梅尔谱图这一终结步骤带来信息损失。
所以作者把这一步进行了隐式表征,具体来说如下
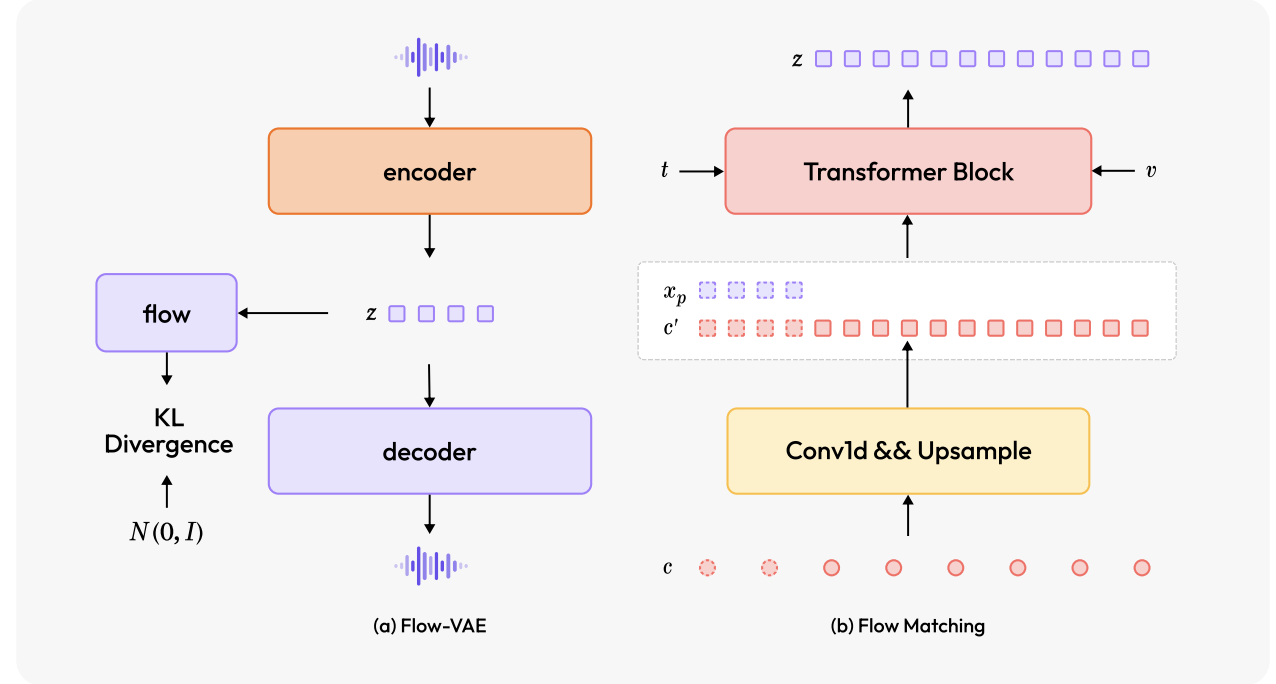
首先看图(a),其把之前的梅尔谱图中间过程替换成了隐式表征z即连续语音特征。而解码器decoder需要根据z恢复为波形而不是带有一定信息损失的梅尔谱图(当然这里可能说的有点不准确,因为隐式表征也会有信息损失,但是一般来说隐式表征的信息更丰富鲁棒)。
同时我们注意到图(a)里面还有一个flow model即所谓的流模型,其主要是将连续语音特征z的分布转换为标准正态分布,具体来说就是到时候会和标准整体分布做一个KL loss,让其更容易预测,也更紧凑,增强编码器的信息表达能力。
现在我们可以清晰的看到Flow-VAE相比于之前VAE最大的特点就是直接端到端的利用隐式连续语音特征z进行解码,避免中间态带来的信息损失。
那怎么得到隐式连续语音特征z,为此又搞了一个图b的流匹配模型Flow Matching来支持(图a命名为Flow-VAE,那为了配合这里就命名为Flow Matching来支持)。
注意哈Flow Matching是在Flow-VAE之前的适配模块,位于AR transformer和Flow-VAE之间。其最终目标输出就是式连续语音特征z。其应用的输入肯定就是有AR transformer的输出c,说话者的表征v,时间t。其中图中虚框的部分就是前一节讲的one-shot,在训练的时候按比例的添加(一部分加&一部分不加),进而实现同时支持zero-shot和one-shot。
效果
一些量化的指标当然都是比较好的了,比如最常用的两个指标词错误率和语音相似度都不错
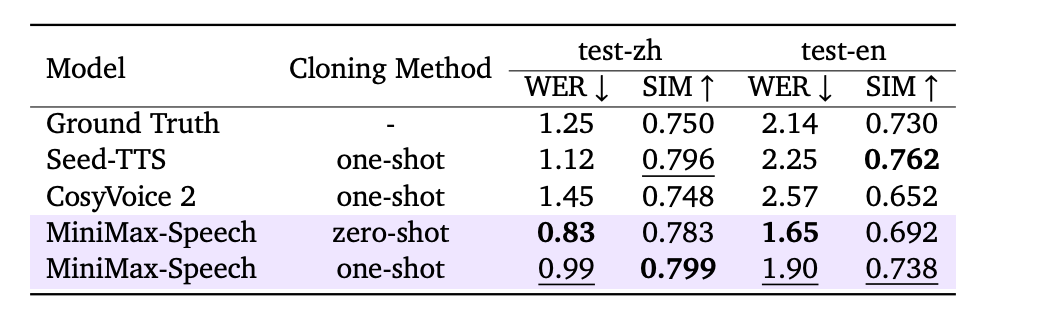
还有一些在多语种上面的指标
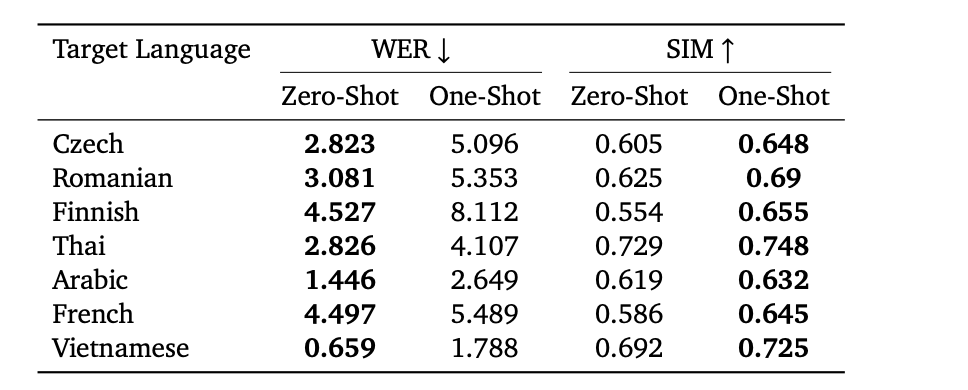
更多的指标大家感兴趣的话看原论文就好了,笔者不再在这里累述了。
总结
笔者觉得LLM的发展以及本篇的技术思路都体现一个大的底层逻辑或者方法那就是端到端隐式学习,尽可能的去掉一些中间有可能带来折损的层(但凡有就不可避免的带来某些方面的信息损失比如梅尔谱图),而全部换成隐式连续表征去端到端的学习,这样的话模型能够更好的学到知识,效果大概率会不错。
关注

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)