Qwen2 大模型指令微调入门实战
大模型指令微调(Instruction Tuning)是一种针对大型预训练语言模型的微调技术,其核心目的是增强模型理解和执行特定指令的能力,使模型能够根据用户提供的自然语言指令准确、恰当地生成相应的输出或执行相关任务。
本文是笔者在 Mac 上复现林泽毅的微调流程,方便其他读者在本地实验!整个执行在一个半小时(Mac 配置:Mac M1 Pro,16G)。
教程文章:https://zhuanlan.zhihu.com/p/702491999
显存要求:10GB左右
实验过程:https://swanlab.cn/@ZeyiLin/Qwen2-fintune/runs/cfg5f8dzkp6vouxzaxlx6/chart
GitHub:https://github.com/Zeyi-Lin/LLM-Finetune
实验目标
大模型指令微调(Instruction Tuning)是一种针对大型预训练语言模型的微调技术,其核心目的是增强模型理解和执行特定指令的能力,使模型能够根据用户提供的自然语言指令准确、恰当地生成相应的输出或执行相关任务。
指令微调特别关注于提升模型在遵循指令方面的一致性和准确性,从而拓宽模型在各种应用场景中的泛化能力和实用性。
在实际应用中,指令微调更多把LLM看作一个更智能、更强大的传统NLP模型(比如Bert),来实现更高精度的文本预测任务。所以这类任务的应用场景覆盖了以往NLP模型的场景,甚至很多团队拿它来标注互联网数据。
实验数据
本实验使用的是zh_cls_fudan-news(https://modelscope.cn/datasets/swift/zh_cls_fudan-news/files)数据集,该数据集主要被用于训练文本分类模型。
zh_cls_fudan-news由几千条数据,每条数据包含text、category、output三列:
-
text是训练语料,内容是书籍或新闻的文本内容; -
category是text的多个备选类型组成的列表; -
output则是text唯一真实的类型。
示例数据:
{"text": "【 文献号 】2-1367\t【原文出处】学术研究\t【原刊地名】广州\t【原刊期号】199904\t【原刊页号】47~49\t【分 类 号】F13\t【分 类 名】社会主义经济理论与实践\t【复印期号】199906\t【 标 题 】充分认识我国现阶段私营经济的特殊性\t【 作 者 】张振宇\t【作者简介】中共广东省委政策研究室,广东 广州 510080\t【 正 文 】\t〔中图分类号〕F121・23 〔文献标识码〕A 〔文章编号〕1000―7326(1999)04―0047―03一我们对社会主义条件下的私营经济的性质、特点、地位和作用的认识是逐步深化的。因而对它的态度和政策经历了一个从彻底否定、到部分肯定、再到充分肯定的过程。个体、私营经济作为一种政策性经济,也经历了一个曲折发展的过程:开始认为它是社会主义的异己力量,从而需要被改造、被消灭,到承认其是社会主义经济的有益补充,允许存在,但要加强监督管理,做到兴利除弊,直到党的“十五大”前后,进一步承认其是社会主义市场经济的重要组成部分,需要鼓励、引导,并放手让其发展。如果我们摒除“左”的思想影响,着眼于社会主义初级阶段的实际,不从书本概念或某些条条框框出发,具体分析我国现阶段的政治、经济情况,正确认识社会主义条件下私营经济的状况、性质、特点和作用,就会对它获得真理性的认识和制订出正确的政策。不可否认,私营经济是私人占有生产资料,通过私人资本、雇佣劳动而实现生产经营的经济。但是,这种私营经济是在我国改革开放年代涌现出来的。它受到我国社会主义政治制度和经济制度的制约和影响,受到国家对社会经济发展的宏观管理、调控和监督。现阶段的私营经济,是在建国后消灭了私人资本后,又经过30多年的社会主义建设而重新发展起来的经济。它既不同于我国50年代的民族资本,更不同于当代世界的资本主义经济。它是社会主义社会大环境里成长起来的一种新型的私营经济。在企业主构成、资产性质、分配关系和主雇关系等方面,与一般意义上的资本主义经济,有着许多质的差别。1、 从他们的资本积累来看:私营企业主原来都是社会主义的劳动者。他们或是国家干部、职工,或是教育、科技人员,或是农村基层干部、企业管理人员,或是农村专业大户。他们乘改革开放的东风,依靠国家政策,利用自己的知识、技术和创业才能,进行劳动积累,从少到多、日积月累,而使自己的资本和经营规模逐步扩大起来。2、从雇工和主雇关系来看:现阶段私营企业的雇工, 同其它职工一样,在政治上和经济上是独立的。他们有自己的生产资料;受雇的主要原因不是为了生存,而是为了多挣收入,学点技术、知识和经营本领,为今后创业取得更多收入创造条件。主雇之间在政治上是平等的、自由的。被雇时被迫的成分少,自愿的成分多。3、从其利润分配情况看:看了许多调查材料, 发现目前私营企业主普遍地把企业盈利的绝大部分用之于扩大再生产,使之成为社会财富的一部分;那种进行大肆挥霍、高消费的现象很少。其中许多人积极参加社会文化、公益、救灾等光彩事业。因此,我赞同这样一种看法:现阶段作为与社会主义制度相联系的私营经济,其资产具有私有和社会所有双重属性,成为社会主义社会总资产的一个组成部分。4、从企业主群体的构成来看:如上所述, 在改革开放中成长起来的私营企业主,原来都是国家干部职工、教师、科技人员、农村基层组织和企业干部等。这些人长期接受过社会主义教育,有很高的爱国心、事业心。其中许多人从事生产经营,是希望以自己的知识、技术和才能,干出一番事业,为社会多作贡献。这是我国社会生活中新生的一个社会群体。其中不少人视自己的资本为社会共同财富。有些人昨天是企业主,今天就成了国家的职工或基层干部。我在调查农村基层建设情况时,在南海、番禺、高明等市就发现不少私营企业主被聘为农村党政基层组织的负责人。他们用自己的才能、经验,甚至资财,迅速把当地的集体经济、两个文明建设搞起来成为受群众和领导欢迎和称赞的好干部。二改革开放以来,广东社会经济发展很快,其中一个重要因素,就是非公有制经济迅猛发展。国民经济结构中,非公有制经济比重迅速上升,现在几乎与公有制经济平起平坐。目前工商业仍是我国国民经济中最重要的领域,也是非公有制经济发展的最主要的领域。据省统计年鉴材料,1997年,全省工业总产值中,公有制工业已下降到占43.2%(其中国有工业只占11.1%),而非公有制工业占到50.8%,其它股份、联营经济占6.1%。在全省社会商品零售额中,公有制经济占37.6 %(其中国有商业占21.3%),非公有制经济占46.4%,其它股份、联营经济占15.8%。非公有制经济的发展,改变了广东省经济的微观基础,为社会经济的发展注入了巨大活力,促进了国有经济的改革进程,促进了市场竞争和市场机制的建立,调动了各方发展社会经济的热情,加强了全省的经济实力,促成了广东社会经济发展进入黄金时期。但是,进一步剖析非公有制经济时,就会了解到主要是外资和港澳台资占的比重大,私营经济相对来说发展不快、不足。仍以1997年的情况为例,在非公有制工业产值中, 外商和港澳台商投资的工业占了46.4%,个体工业占10.7%,私营工业只占0.5%,简直微不足道。 在非公有制的社会商品零售额中,主要是个体商业占36.7%,私营商业只占5.7%。这就说明,通过20年的改革开放,广东的私营经济虽有重大发展,但增长速度不快,与兄弟省市比尚有差距(广东个体、私营户数已从前三年排全国第4位下降到现在的第8位;私营经济年增长率为15%,也低于全国平均增长25%的水平),潜力仍未充分发挥出来。因此,今后应该重视做好这方面的工作,把积极发展个体、私营经济作为广东社会经济增创新优势的重要内容之一来抓。三当前,需要进一步解放思想,扫清思想障碍,才能放手发展私营经济。1、当前全党全国的工作中心,是千方百计地迅速把经济搞上去,邓小平同志指出,社会主义的根本任务就是解放生产力,发展生产力。目前,私营经济以其自身的潜力和条件,其解放和发展生产力的作用是有目共睹的。党的“十五大”提出,非公有制经济是我国社会主义市场经济的重要组成部分;以公有制经济为主体的多种所有制经济结构是我国社会主义初级阶段的一项基本经济制度。发展个体、私营经济,是增加生产投资,充分利用资源,吸纳就业人口,增加物质产品,增大出口创汇,增强经济实力,推动社会生产力发展的重要途径。特别在当前进行国有企业改革,大量干部职工下岗,需要解决他们的就业出路和减轻国家负担之时,强调和着力发展个体和私营经济,更有其特殊重要的经济意义和政治意义。2、实事求是地认识我国现阶段私营经济的历史进步性。 有人总是从消极方面、从社会主义的异己力量角度去看待私营经济。他们害怕私人资本,特别害怕私人资本的发展壮大。他们没有认识到私营经济在我国社会主义初级阶段的历史进步性。其实,在社会主义社会这个大环境里,只要私营企业的税后利润投资于再生产(国家规定,私营企业的税后利润用于发展生产的部分不得低于50%,而且对这部分免征个人所得税,鼓励其发展生产)。只要私有资产在社会再生产过程中运行,这种私有资本就成为社会资本。这样,法律意义上的所有权就会显得次要了,私有的生产资料与公有的生产资料一样,都在发展社会生产力,都在为国家和社会创造财富,共同构成了社会的经济基础。从这个意义上说,我国现阶段私营企业发展得多,规模扩大,吸纳社会劳动力越多,创造社会的财富越多,缴纳国家的财税越多,对社会主义建设的贡献就越大。3、应当承认, 目前对我国发展私营经济的错误认识和政策上的歧视现象已在逐步减少,但长期来形成的“一大二公”、“左”的观念和由此而来的对私营经济的社会偏见,却不能低估,并且在短时期内也难以消失。由此引发的党政有关部门在制定和掌握政策、措施中,对私营企业的“宁左勿右”、“宁紧勿松”现象,仍在很大程度上制约着私营经济的发展。表现在私营经济在经营范围、项目、信贷、融资、进出口等方面,或是渠道不通,或是通而不畅;在法律保护、社会保障等方面,与公有制经济“一视同仁”还相去甚远,从而使许多个体工商户、私营企业至今在“挂靠”,戴着“红帽子”而不肯取下。因此,要使私有经济能够放胆地、健康地发展,人们的思想观念必须有一个新的升华。要摒弃经济建设上的“唯成份论”。要按社会主义市场经济的原则,真正实现多种经济成份的共同发展,做到公平竞争,互相促进,共同为发展社会主义社会的生产力而努力。【责任编辑】谭湛明\t", "category": ["Electronics", "Agriculture", "Literature", "Sports", "Economy", "Philosophy"], "output": "Economy"}开始实验
注意:笔者使用的是
juypter notebook
Step 1
git clone https://github.com/Zeyi-Lin/LLM-Finetune.git# 安装相关依赖pip install torch swanlab modelscope transformers datasets peft pandas accelerate
Step 2
-
文本分类任务-数据集下载:在
huangjintao/zh_cls_fudan-news(https://modelscope.cn/datasets/swift/zh_cls_fudan-news/files)下载train.jsonl和test.jsonl到根目录下。 -
命名实体识别任务-数据集下载:在
qgyd2021/chinese_ner_sft(https://huggingface.co/datasets/qgyd2021/chinese_ner_sft/tree/main/data)下载ccfbdci.jsonl到根目录下。
Step 3
cd notebook# 查看 notebook 文件ls -ltotal 134440-rw-r--r-- 1 xxx staff 13467306 3 24 21:50 new_test.jsonl-rw-r--r-- 1 xxx staff 55294790 3 24 21:50 new_train.jsonldrwxr-xr-x 3 xxx staff 96 3 24 22:14 outputdrwxr-xr-x 4 xxx staff 128 3 24 22:08 qwen-rw-r--r-- 1 xxx staff 11527 3 24 21:43 train_glm4.ipynb-rw-r--r-- 1 xx staff 12657 3 24 21:43 train_glm4_ner.ipynb-rw-r--r-- 1 xx staff 24152 3 24 22:48 train_qwen2.ipynb-rw-r--r-- 1 xx staff 13251 3 24 21:43 train_qwen2_ner.ipynb
打开 train_qwen2.ipynb。
Step 4 - 数据集加载
将train.jsonl和test.jsonl进行处理,转换成new_train.jsonl和new_test.jsonl。
注意:文件路径需要根据实际位置调整
[代码]
# 2.将train.jsonl和test.jsonl进行处理,转换成new_train.jsonl和new_test.jsonlimport jsonimport pandas as pdimport osdef dataset_jsonl_transfer(origin_path, new_path):"""将原始数据集转换为大模型微调所需数据格式的新数据集"""messages = []# 读取旧的JSONL文件with open(origin_path, "r") as file:for line in file:# 解析每一行的json数据data = json.loads(line)context = data["text"]catagory = data["category"]label = data["output"]message = {"instruction": "你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型","input": f"文本:{context},类型选型:{catagory}","output": label,}messages.append(message)# 保存重构后的JSONL文件with open(new_path, "w", encoding="utf-8") as file:for message in messages:file.write(json.dumps(message, ensure_ascii=False) + "\n")# 加载、处理数据集和测试集train_dataset_path = "../train.jsonl"test_dataset_path = "../test.jsonl"train_jsonl_new_path = "new_train.jsonl"test_jsonl_new_path = "new_test.jsonl"if not os.path.exists(train_jsonl_new_path):dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)if not os.path.exists(test_jsonl_new_path):dataset_jsonl_transfer(test_dataset_path, test_jsonl_new_path)train_df = pd.read_json(train_jsonl_new_path, lines=True)[:1000] # 取前1000条做训练(可选)test_df = pd.read_json(test_jsonl_new_path, lines=True)[:10] # 取前10条做主观评测
Step 5 - 下载/加载模型和tokenizer
from modelscope import snapshot_download, AutoTokenizerfrom transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seqimport torch# 在modelscope上下载Qwen模型到本地目录下model_dir = snapshot_download("qwen/Qwen2-1.5B-Instruct", cache_dir="./", revision="master")# Transformers加载模型权重tokenizer = AutoTokenizer.from_pretrained("./qwen/Qwen2-1___5B-Instruct/", use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained("./qwen/Qwen2-1___5B-Instruct/", device_map="auto", torch_dtype=torch.bfloat16)model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
输出:
Downloading Model from https://www.modelscope.cn to directory: ./qwen/Qwen2-1.5B-InstructStep 6 - 预处理训练数据
def process_func(example):"""将数据集进行预处理"""MAX_LENGTH = 384input_ids, attention_mask, labels = [], [], []instruction = tokenizer(f"<|im_start|>system\n你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n",add_special_tokens=False,)response = tokenizer(f"{example['output']}", add_special_tokens=False)input_ids = (instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id])attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]labels = ([-100] * len(instruction["input_ids"])+ response["input_ids"]+ [tokenizer.pad_token_id])if len(input_ids) > MAX_LENGTH: # 做一个截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}from datasets import Datasettrain_ds = Dataset.from_pandas(train_df)train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)
输出:
ounter(lineMap: 100%|██████████| 1000/1000 [01:07<00:00, 14.88 examples/s]
Step 7 - 设置 LORA 参数
from peft import LoraConfig, TaskType, get_peft_modelconfig = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",],inference_mode=False, # 训练模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.1, # Dropout 比例)model = get_peft_model(model, config)
Step 8 - 训练
args = TrainingArguments(output_dir="./output/Qwen2",per_device_train_batch_size=4,gradient_accumulation_steps=4,logging_steps=10,num_train_epochs=2,save_steps=100,learning_rate=1e-4,save_on_each_node=True,gradient_checkpointing=True,report_to="none",)from swanlab.integration.huggingface import SwanLabCallbackimport swanlabswanlab_callback = SwanLabCallback(project="Qwen2-fintune",experiment_name="Qwen2-1.5B-Instruct",description="使用通义千问Qwen2-1.5B-Instruct模型在zh_cls_fudan-news数据集上微调。",config={"model": "qwen/Qwen2-1.5B-Instruct","dataset": "huangjintao/zh_cls_fudan-news",},)trainer = Trainer(model=model,args=args,train_dataset=train_dataset,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),callbacks=[swanlab_callback],)trainer.train()# ====== 训练结束后的预测 ===== #def predict(messages, model, tokenizer):device = "cuda"text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)generated_ids = [output_ids[len(input_ids) :]for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)return responsetest_text_list = []for index, row in test_df.iterrows():instruction = row["instruction"]input_value = row["input"]messages = [{"role": "system", "content": f"{instruction}"},{"role": "user", "content": f"{input_value}"},]response = predict(messages, model, tokenizer)messages.append({"role": "assistant", "content": f"{response}"})result_text = f"{messages[0]}\n\n{messages[1]}\n\n{messages[2]}"test_text_list.append(swanlab.Text(result_text, caption=response))swanlab.log({"Prediction": test_text_list})swanlab.finish()
输出:
swanlab: Using SwanLab to track your experiments. Please refer to https://docs.swanlab.cn for more information.swanlab: (1) Create a SwanLab account.swanlab: (2) Use an existing SwanLab account.swanlab: (3) Don't visualize my results.swanlab: Enter your choice: 2swanlab: You chose 'Use an existing swanlab account'swanlab: Logging into https://swanlab.cnswanlab: You can find your API key at: https://swanlab.cn/space/~/settingsswanlab: Paste an API key from your profile and hit enter, or press 'CTRL + C' to quit:········swanlab: Tracking run with swanlab version 0.5.3swanlab: Run data will be saved locally in /Users/wangtianqing/Project/LLM-Finetune/notebook/swanlog/run-20250324_221653-a3b1799dswanlab: 👋 Hi grissom, welcome to swanlab!swanlab: Syncing run Qwen2-1.5B-Instruct to the cloudswanlab: 🏠 View project at https://swanlab.cn/@grissom/Qwen2-fintuneswanlab: 🚀 View run at https://swanlab.cn/@grissom/Qwen2-fintune/runs/eiuw8o6i2xqy06zjmhpir
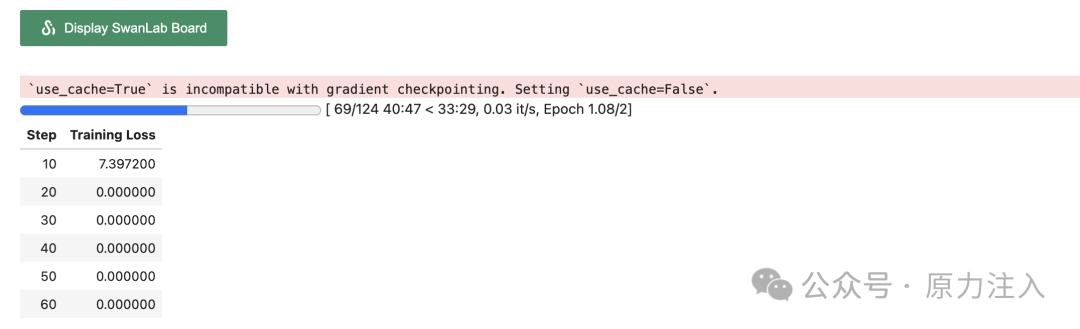
注意你需要预先在 swanlab(https://swanlab.cn/) 上注册账号,并获得 API Key。并且在如下提示时输入:
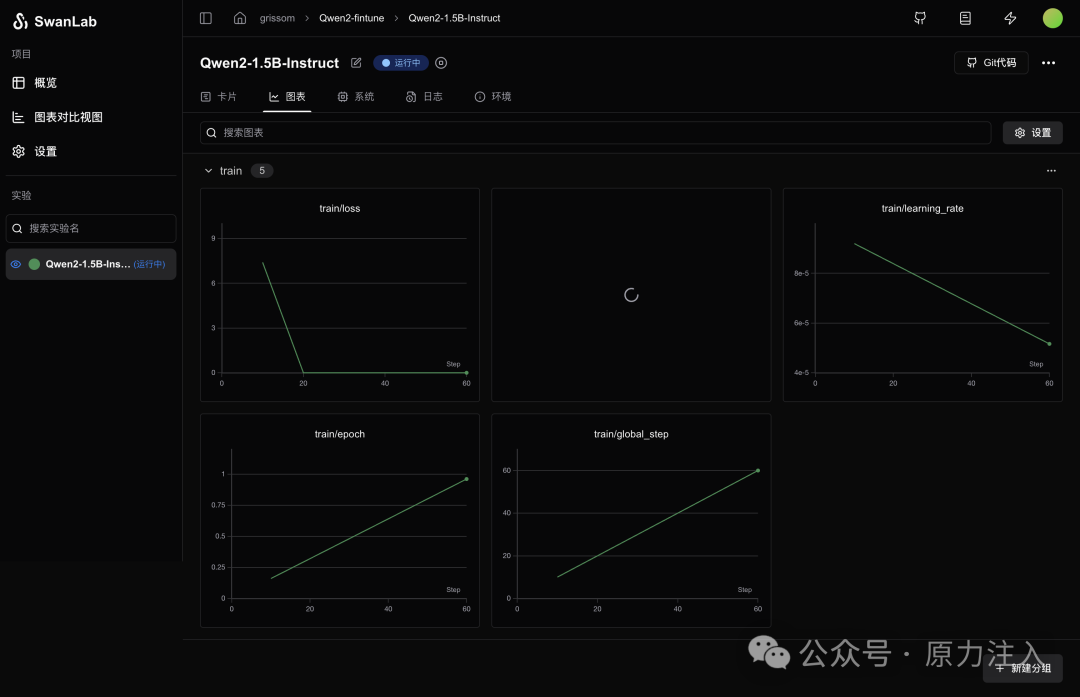
swanlab: Paste an API key from your profile and hit enter, or press 'CTRL + C' to quit: Swanlab 上查看输出
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献481条内容
已为社区贡献481条内容

所有评论(0)