【论文阅读笔记】What does CLIP know about a red circle? Visual prompt engineering for VLMs
大规模视觉语言模型(例如 CLIP)学习了强大的图像文本表示,这些表示已在从零样本分类到文本到图像生成等众多应用中得到应用。尽管如此,它们通过提示解决新型判别任务的能力仍落后于大型语言模型(例如 GPT-3)。在这里,我们探索了视觉提示工程的想法,通过在图像空间而不是文本中进行编辑来解决分类以外的计算机视觉任务。具体来说,我们发现了 CLIP 的一项新兴能力,只需在对象周围画一个红色圆圈,我们就可
动机
视觉语言模型通过提示解决判别任务的能力落后于大型语言模型,因此本文探索了一种视觉提示工程的思想,通过在图像空间而不是文本中进行编辑来解决分类以外的计算机视觉任务
创新点
提出了一种视觉提示工程的方法,并探讨了大型语言-视觉模型存在的一些潜在的伦理问题。
摘要
大规模视觉语言模型(例如 CLIP)学习了强大的图像文本表示,这些表示已在从零样本分类到文本到图像生成等众多应用中得到应用。尽管如此,它们通过提示解决新型判别任务的能力仍落后于大型语言模型(例如 GPT-3)。在这里,我们探索了视觉提示工程的想法,通过在图像空间而不是文本中进行编辑来解决分类以外的计算机视觉任务。具体来说,我们发现了 CLIP 的一项新兴能力,只需在对象周围画一个红色圆圈,我们就可以将模型的注意力引导到该区域,同时还可以保留全局信息。我们通过在零样本指称表达式理解中实现最先进的水平和在关键点定位任务中的出色表现,展示了这种简单方法的强大功能。最后,我们提请大家注意大型语言视觉模型的一些潜在道德问题。
1.引言
第一段:介绍大语言模型的强大功能(零样本领域)
第二段:介绍大规模视觉-语言模型(如clip)具备的能力
第三段:介绍对VLMs模型进行提示,文本提示工程和视觉提示工程,其中,视觉提示工程能够表达更多位置等空间属性
第四段:因此,本文提出了一种视觉提示工程,介绍本文的两个目的(第一个目标是贡献一个更实用的工具,以零样本方式从 VLM 中提取有用的信息;第二个目标是描述VLM 及其训练数据的有趣且意外属性,包括识别一些可能引发道德问题的行为)
第五段:介绍本文最令人惊讶的一项发现:一种特定类型的视觉提示的有效性(在图像上方绘制一个纯红色圆圈)注意:用圆圈提示也适用于更细粒度的定位,标记特定的对象部分或关键点,而不仅仅是整个对象
第六段:对比标记与裁剪两种方法的有效性
第七段:我们通过实证研究证明,在众多可能的标记(圆圈、方框、箭头等的变体)中,用红色圆圈标记是最佳选择。(VLM 可以理解红色圆圈,可能是因为它们在训练语料库(即互联网)中出现的频率足够高——如果想要使用它,要考虑这一点,即是否会有效)
第八段:我们测试了不同尺寸/容量的模型,并表明只有较大的模型才能可靠地表现出这种行为
第九段:红色圆圈在训练数据中可能具有负面含义,因此视觉提示工程也会引发不良行为
2.相关工作
主要介绍了大语言模型与大规模视觉-语言与训练模型、REC任务、提示VLMs、无监督REC任务、使用大型预训练模型进行视觉推理
3.方法
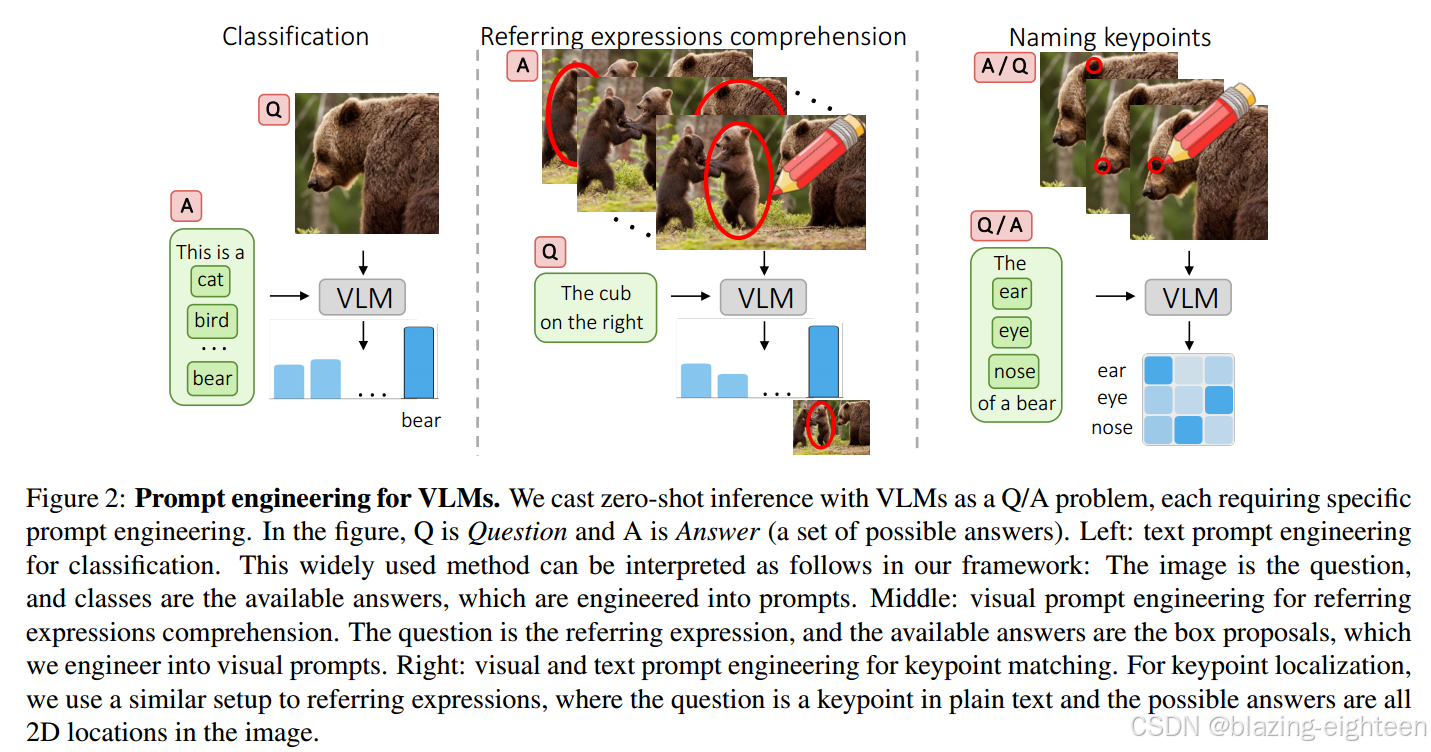
本文通过三个任务来研究基于标记的视觉提示工程:命名关键点、定位关键点、REC任务
【没看懂的地方】首先,怎么生成视觉提示工程的???好像没看到有写;其次,为什么有的又包括了边界框,这不是零样本吗??
【注意】传统的视觉提示的方法是围绕所需位置裁剪图像;而本文的方法是在图像上做标记,直观地指示需要的位置

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)