[ICML 2025]MindLLM: A Subject-Agnostic and Versatile Model for fMRI-to-Text Decoding
计算机-人工智能-fMRI解码多任务大模型

论文网址:[2502.15786] MindLLM: A Subject-Agnostic and Versatile Model for fMRI-to-Text Decoding
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.3. Brain Instruction Tuning (BIT)
2.5.4. Unseen Subject Generalization
2.5.7. Visualizations and Interpretations
1. 心得
(1)做了很多工作
2. 论文逐段精读
2.1. Abstract
①Challenges: suboptimal performance, limited task variety, and poor generalization across subjects
2.2. Introduction
①Design and implement of MindLLM:
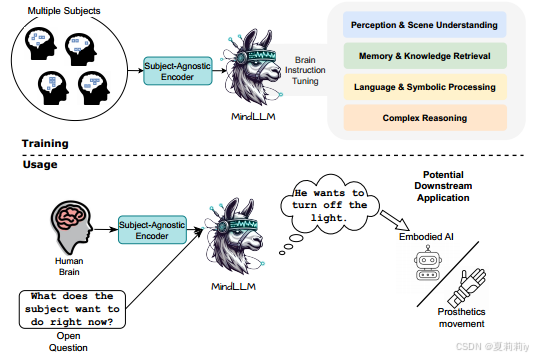
②Responsive voxel selected will cause different voxel number when brings higher performance. Pooling or sampling them to the same number may cause loss of information
③Their method aims to complete tasks of perception & scene understanding, memory & knowledge retrieval, language & symbolic processing, and complex reasoning
prosthesis n.假体(如假肢、假眼或假牙)
2.3. Related Works
①⭐VQA responds answers which is not relevant to β value
②⭐Cross-subject methods did not deal well with voxel differentiation, flattening or samling may cause spatial/individual information loss:
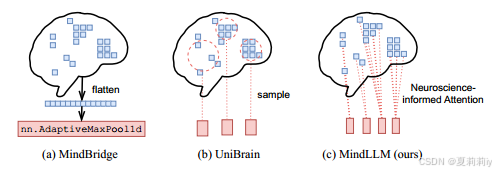
③Designing different encoder for different person actually limits. And caption annotation only is also a limitation
2.4. Method
2.4.1. Method Overview
①Overall framework of MindLLM:
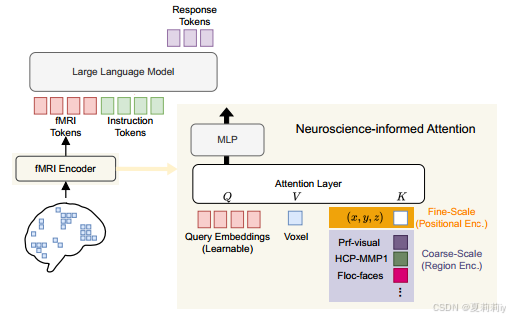
where LLM is Vicuna-7b(适合开放对话??长文本理解??)
②Input brain signal of each subject: ,
denotes voxels
③fMRI encoder encodes
to fMRI tokens
with
dimension and
tokens
2.4.2. fMRI Encoder
①在注意力里面,V是某个体素激活,K是那个体素的傅里叶坐标和很多个属于不同脑图谱ROI的区域嵌入:
② is the output of attention layer and then employed a MLP:
2.4.3. Brain Instruction Tuning (BIT)
①Tasks of MindLLM:
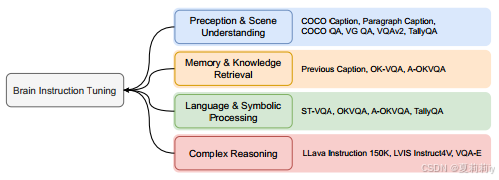
signifier n.能指(语言符号的形式)
②Multi-run conversation with
number of runs,
message from the assistant and
message is from the user for each sample
③Training object:
④Examples of Q&A:

2.5. Experiments
2.5.1. Settings
①Datasets: NSD and other downstream datasets
2.5.2. Brain Captioning
①Captioning performance:

where CIDEr is scaled by a factor of 100
2.5.3. Versatile Decoding
①Performance of versatile decoding:
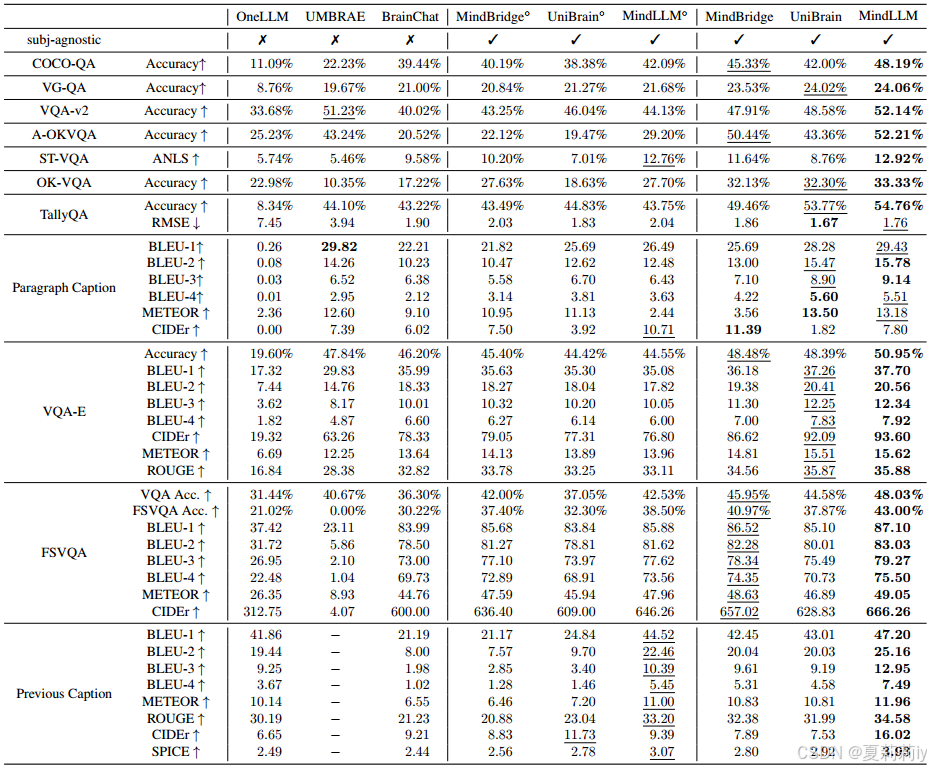
2.5.4. Unseen Subject Generalization
①Train on 1~7 subjects but evaluate on the 8:
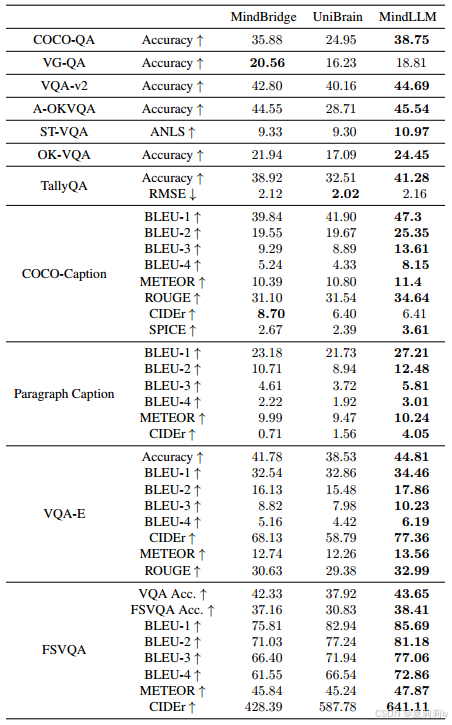
2.5.5. Adapting to New Tasks
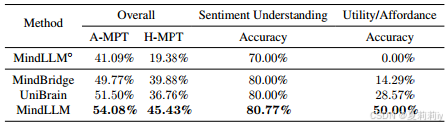
①Performance on sentiment understanding and utility/affordance tasks:
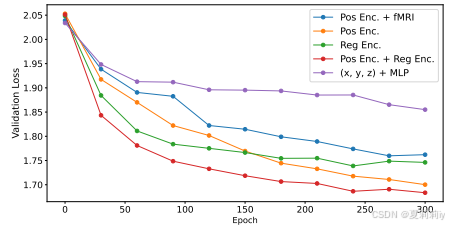
2.5.6. Ablation Study
①Ablation of position encoding:
2.5.7. Visualizations and Interpretations
①Attention of brain voxels:

2.6. Conclusion
~

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)