小白入门大模型:LangChain(附教程)
模型在高层次上有两种不同类型的模型:语言模型(language models)和文本嵌入模型(text embedding models)。文本嵌入模型将文本转换为数字数组,然后我们可以将文本视为向量空间。在上面这个图像中,我们可以看到在一个二维空间中,“king”是“man”,“queen”是“woman”,它们代表不同的事物,但我们可以看到一种相关性模式。这使得语义搜索成为可能,我们可以在向量
一、什么是LangChain
Langchain是一个语言模型的开发框架,主要是利用大型LLMs的强大得few-shot以及zero-shot泛化能力作为基础,以Prompt控制为核心基础,让开发者可以根据需求,往上快速堆叠应用,简单来说:
LangChain 是基于提示词工程(Prompt Engineering),提供一个桥接大型语言模型(LLMs)以及实际应用App的胶水层框架。
优势:
简单快速:不需要训练特定任务模型就能完成各种应用的适配,而且代码入口单一简洁,简单拆解LangChain底层无非就是Prompt指定,大模型API,以及三方应用API调用三个个核心模块。
泛用性广:基于自然语言对任务的描述进行模型控制,对于任务类型没有任何限制,只有说不出来,没有做不到的事情。这也是ChatGPT Plugin能够快速接入各种应用的主要原因。
劣势
大模型替换困难:LangChain主要是基于GPT系列框架进行设计,其适用的Prompt不代表其他大模型也能有相同表现,所以如果要自己更换不同的大模型(如:文心一言,通义千问…等),则很有可能底层prompt都需要跟著微调。
迭代优化困难:在实际应用中,我们很常定期使用用户反馈的bad cases持续迭代模型,但是Prompt Engeering的工程是非常难进行的微调的,往往多跟少一句话对于效果影响巨大,因此这类型产品达到80分是很容易的,但是要持续迭代到90分甚至更高基本上是不太很能的。
新手应该了解哪些模块?
目前有七个模块在 LangChain 中提供,新手应该了解这些模块,包括模型(models)、提示(prompts)、索引(indexes)、内存(memory)、链(chains)和代理(agents)。
核心模块的概述
模型在高层次上有两种不同类型的模型:语言模型(language models)和文本嵌入模型(text embedding models)。文本嵌入模型将文本转换为数字数组,然后我们可以将文本视为向量空间。
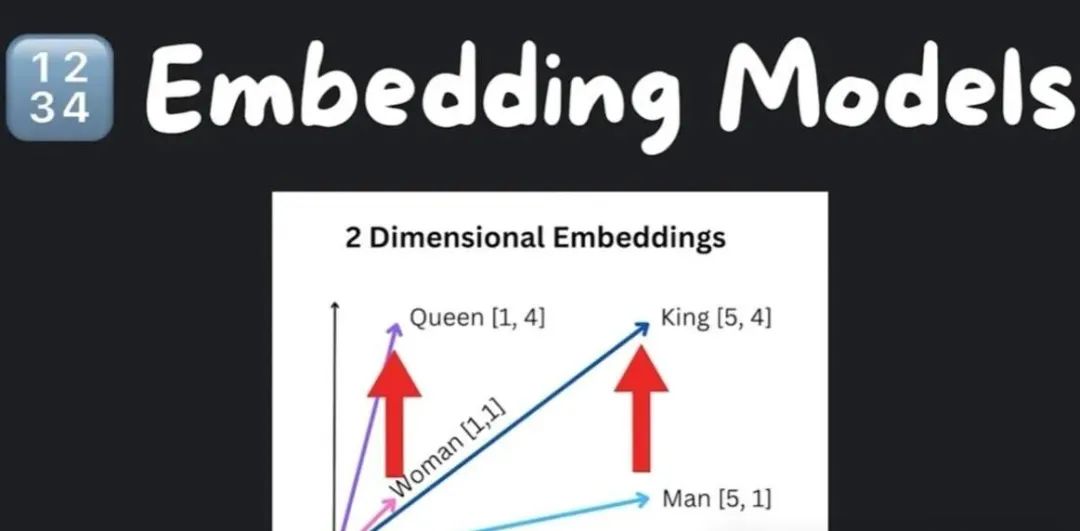
在上面这个图像中,我们可以看到在一个二维空间中,“king”是“man”,“queen”是“woman”,它们代表不同的事物,但我们可以看到一种相关性模式。这使得语义搜索成为可能,我们可以在向量空间中寻找最相似的文本片段,以满足给定的论点。
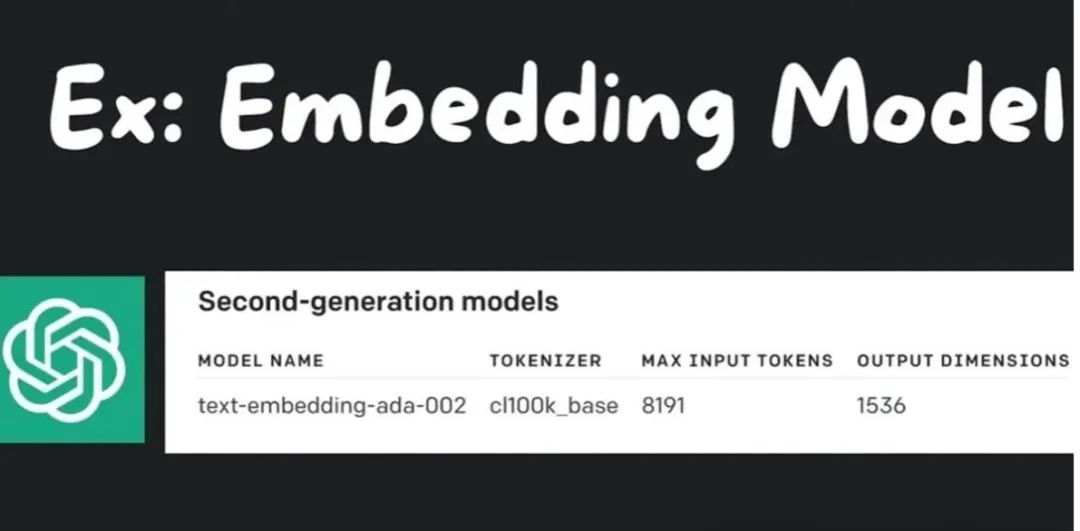
例如,OpenAI 的文本嵌入模型可以精确地嵌入大段文本,具体而言,8100 个标记,根据它们的词对标记比例 0.75,大约可以处理 6143 个单词。它输出 1536 维的向量。
我们可以使用 LangChain 与多个嵌入提供者进行接口交互,例如 OpenAI 和 Cohere 的 API,但我们也可以通过使用 Hugging Faces 的开源嵌入在本地运行,以达到 免费和数据隐私 的目的。

现在,您可以使用仅四行代码在自己的计算机上创建自己的嵌入。但是,维度数量可能会有所不同,嵌入的质量可能会较低,这可能会导致检索不太准确。
LangChain中的模块,每个模块如何使用?
前提:运行一下代码,需要OPENAI_API_KEY(OpenAI申请的key),同时统一引入这些库:
# 导入LLM包装器
from langchain import OpenAI, ConversationChain
from langchain.agents import initialize_agent
from langchain.agents import load_tools
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
LLM:从语言模型中输出预测结果,和直接使用OpenAI的接口一样,输入什么就返回什么。
llm = OpenAI(model_name="text-davinci-003", temperature=0.9) // 这些都是OpenAI的参数
text = "What would be a good company name for a company that makes colorful socks?"
print(llm(text))
// 以上就是打印调用OpenAI接口的返回值,相当于接口的封装,实现的代码可以看看github.com/hwchase17/langchain/llms/openai.py的OpenAIChat
以上代码运行结果:
Cozy Colours Socks.
Prompt Templates:管理LLMs的Prompts,就像我们需要管理变量或者模板一样。
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
// 以上是两个参数,一个输入变量,一个模板字符串,实现的代码可以看看github.com/hwchase17/langchain/prompts
// PromptTemplate实际是基于StringPromptTemplate,可以支持字符串类型的模板,也可以支持文件类型的模板
以上代码运行结果:
What is a good name for a company that makes colorful socks?
Chains:将LLMs和prompts结合起来,前面提到提供了OpenAI的封装和你需要问的字符串模板,就可以执行获得返回了。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt) // 通过LLM的llm变量,Prompt Templates的prompt生成LLMChain
chain.run("colorful socks") // 实际这里就变成了实际问题:What is a good name for a company that makes colorful socks?
Agents:基于用户输入动态地调用chains,LangChani可以将问题拆分为几个步骤,然后每个步骤可以根据提供个Agents做相关的事情。
# 导入一些tools,比如llm-math
# llm-math是langchain里面的能做数学计算的模块
tools = load_tools(["llm-math"], llm=llm)
# 初始化tools,models 和使用的agent
agent = initialize_agent(
tools, llm, agent="zero-shot-react-description", verbose=True)
text = "12 raised to the 3 power and result raised to 2 power?"
print("input text: ", text)
agent.run(text)
通过如上的代码,运行结果(拆分为两个部分):
> Entering new AgentExecutor chain...
I need to use the calculator for this
Action: Calculator
Action Input: 12^3
Observation: Answer: 1728
Thought: I need to then raise the previous result to the second power
Action: Calculator
Action Input: 1728^2
Observation: Answer: 2985984
Thought: I now know the final answer
Final Answer: 2985984
> Finished chain.
Memory:就是提供对话的上下文存储,可以使用Langchain的ConversationChain,在LLM交互中记录交互的历史状态,并基于历史状态修正模型预测。
# ConversationChain用法
llm = OpenAI(temperature=0)
# 将verbose设置为True,以便我们可以看到提示
conversation = ConversationChain(llm=llm, verbose=True)
print("input text: conversation")
conversation.predict(input="Hi there!")
conversation.predict(
input="I'm doing well! Just having a conversation with an AI.")
通过多轮运行以后,就会出现:
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI: Hi there! It's nice to meet you. How can I help you today?
Human: I'm doing well! Just having a conversation with an AI.
AI: That's great! It's always nice to have a conversation with someone new. What would you like to talk about?
具体代码
如下:
# 导入LLM包装器
from langchain import OpenAI, ConversationChain
from langchain.agents import initialize_agent
from langchain.agents import load_tools
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 初始化包装器,temperature越高结果越随机
llm = OpenAI(temperature=0.9)
# 进行调用
text = "What would be a good company name for a company that makes colorful socks?"
print("input text: ", text)
print(llm(text))
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
print("input text: product")
print(prompt.format(product="colorful socks"))
chain = LLMChain(llm=llm, prompt=prompt)
chain.run("colorful socks")
# 导入一些tools,比如llm-math
# llm-math是langchain里面的能做数学计算的模块
tools = load_tools(["llm-math"], llm=llm)
# 初始化tools,models 和使用的agent
agent = initialize_agent(tools,
llm,
agent="zero-shot-react-description",
verbose=True)
text = "12 raised to the 3 power and result raised to 2 power?"
print("input text: ", text)
agent.run(text)
# ConversationChain用法
llm = OpenAI(temperature=0)
# 将verbose设置为True,以便我们可以看到提示
conversation = ConversationChain(llm=llm, verbose=True)
print("input text: conversation")
conversation.predict(input="Hi there!")
conversation.predict(
input="I'm doing well! Just having a conversation with an AI.")
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)