强化学习教学:Pytorch 实现9种DRL算法,开启你的强化学习之旅
这9种DRL算法涵盖了基于策略梯度、基于价值以及二者结合的多种方法,对于强化学习初学者来说,是非常好的学习资源。通过实践这些算法,你能深入理解强化学习的核心概念,掌握使用Pytorch进行强化学习算法开发的技能。赶紧动手试试吧!
强化学习教学 Pytorch 实现的9种 DRL 算法 包括以下9种:REINFORCE、Actor-Critic、Rainbow-DQN、PPO-discrete、PPO-continous、DDPG、TD3、SAC、PPO-discrete-RNN 非常适合强化学习初学者 环境要求: python==3.7.9 numpy==1.19.4 pytorch==1.12.0 tensorboard==0.6.0 gym==0.21.0
嘿,强化学习的初学者们!今天要给大家分享超棒的内容,使用Pytorch实现9种深度强化学习(DRL)算法,带你快速上手强化学习。
一、环境要求
在开始之前,先确保咱们的环境配置好。这里需要的版本如下:
python==3.7.9:作为主流的Python版本,它的稳定性和兼容性都非常不错,适合进行各类开发,咱们的强化学习代码也不例外。numpy==1.19.4:这个强大的数学计算库,在处理矩阵运算、数组操作等方面效率极高,强化学习中大量的数据处理都离不开它。pytorch==1.12.0:本次实现算法的核心框架,PyTorch以其动态计算图和易于理解的代码结构受到广泛喜爱。tensorboard==0.6.0:用于可视化训练过程,让你清晰看到算法的学习曲线,了解训练进展。gym==0.21.0:OpenAI Gym,提供了丰富的环境供强化学习算法进行训练和测试,从简单的CartPole到复杂的Atari游戏环境都有。
二、9种DRL算法实现
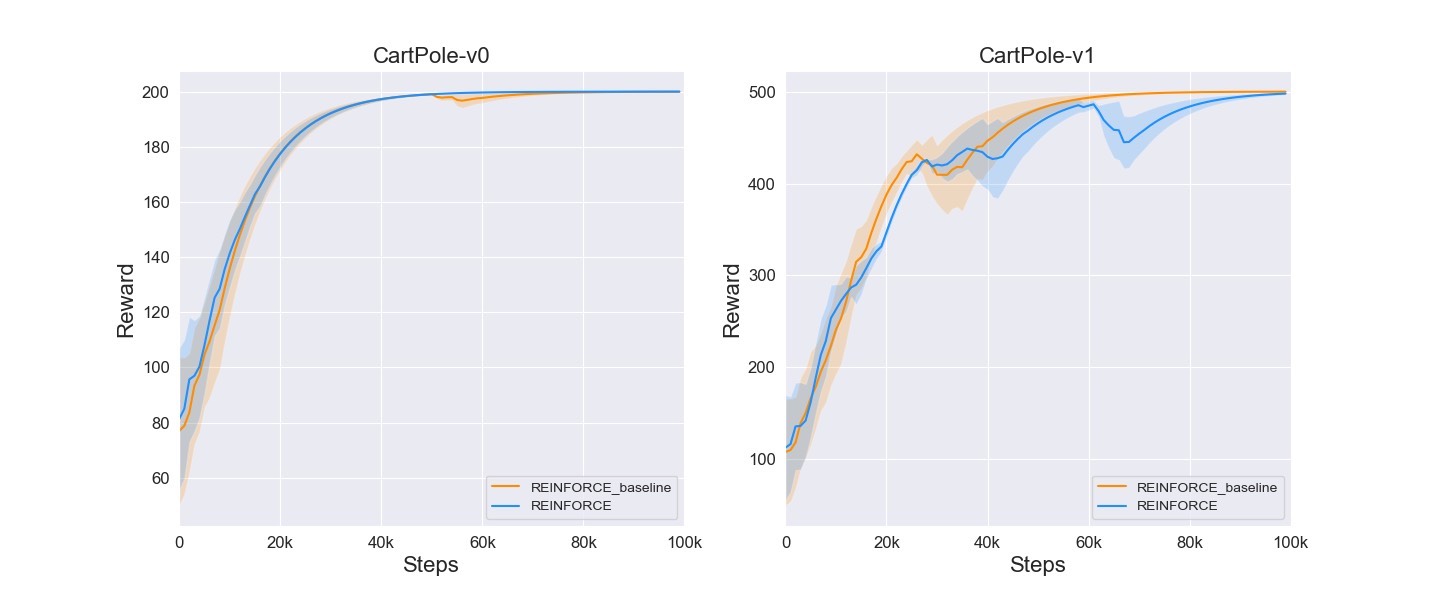
1. REINFORCE
REINFORCE算法是基于策略梯度的算法。简单来说,它通过不断采样轨迹,根据奖励来调整策略网络的参数,使得智能体采取的行动能获得更高的奖励。
import torch
import torch.nn as nn
import torch.optim as optim
import gym
class Policy(nn.Module):
def __init__(self, state_dim, action_dim):
super(Policy, self).__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
action_probs = torch.softmax(self.fc2(x), dim=1)
return action_probs
def reinforce(env, policy, optimizer, num_episodes, gamma=0.99):
rewards_all_episodes = []
for episode in range(num_episodes):
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
rewards_current_episode = []
while True:
action_probs = policy(state)
dist = torch.distributions.Categorical(action_probs)
action = dist.sample()
next_state, reward, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
rewards_current_episode.append(reward)
state = next_state
if done:
break
rewards_all_episodes.append(sum(rewards_current_episode))
returns = []
G = 0
for r in rewards_current_episode[::-1]:
G = r + gamma * G
returns.insert(0, G)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + 1e-9)
log_probs = []
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
while True:
action_probs = policy(state)
dist = torch.distributions.Categorical(action_probs)
action = dist.sample()
log_probs.append(dist.log_prob(action))
next_state, _, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
state = next_state
if done:
break
log_probs = torch.stack(log_probs)
loss = - (log_probs * returns).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
return rewards_all_episodes2. Actor - Critic
Actor - Critic结合了策略梯度(Actor部分)和价值函数估计(Critic部分)。Actor负责选择行动,Critic负责评估Actor的行动价值。
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
action_probs = torch.softmax(self.fc2(x), dim=1)
return action_probs
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
value = self.fc2(x)
return value
def actor_critic(env, actor, critic, actor_optimizer, critic_optimizer, num_episodes, gamma=0.99):
rewards_all_episodes = []
for episode in range(num_episodes):
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
rewards_current_episode = []
while True:
action_probs = actor(state)
dist = torch.distributions.Categorical(action_probs)
action = dist.sample()
next_state, reward, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
rewards_current_episode.append(reward)
state = next_state
if done:
break
rewards_all_episodes.append(sum(rewards_current_episode))
returns = []
G = 0
for r in rewards_current_episode[::-1]:
G = r + gamma * G
returns.insert(0, G)
returns = torch.tensor(returns)
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
values = []
while True:
value = critic(state)
values.append(value)
action_probs = actor(state)
dist = torch.distributions.Categorical(action_probs)
action = dist.sample()
next_state, _, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
state = next_state
if done:
break
values = torch.cat(values)
advantages = returns - values.detach()
actor_loss = - (torch.stack([dist.log_prob(action) for dist, action in zip([torch.distributions.Categorical(actor(state)) for state in states], actions)]) * advantages).mean()
critic_loss = advantages.pow(2).mean()
actor_optimizer.zero_grad()
actor_loss.backward(retain_graph=True)
actor_optimizer.step()
critic_optimizer.zero_grad()
critic_loss.backward()
critic_optimizer.step()
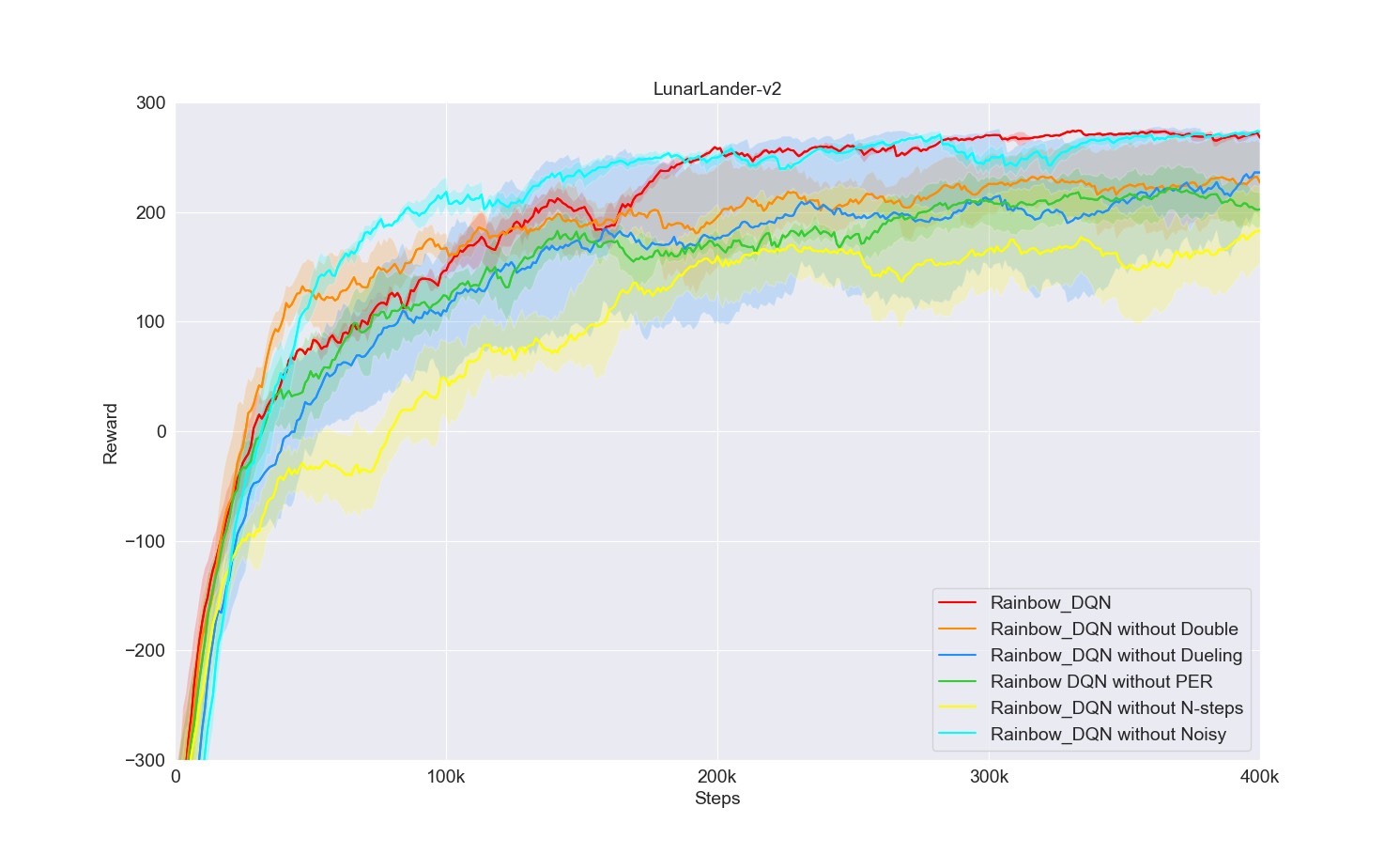
return rewards_all_episodes3. Rainbow - DQN
Rainbow - DQN融合了多种DQN改进技术,像Double DQN、Dueling DQN、Prioritized Experience Replay等,提升了算法的稳定性和效率。
4. PPO - discrete
近端策略优化(PPO)离散版本,它通过优化一个裁剪的目标函数来更新策略,防止策略更新过大。
5. PPO - continous
PPO连续版本,适用于连续动作空间的环境。
6. DDPG
深度确定性策略梯度(DDPG),结合了DQN和确定性策略梯度,用于连续动作空间。
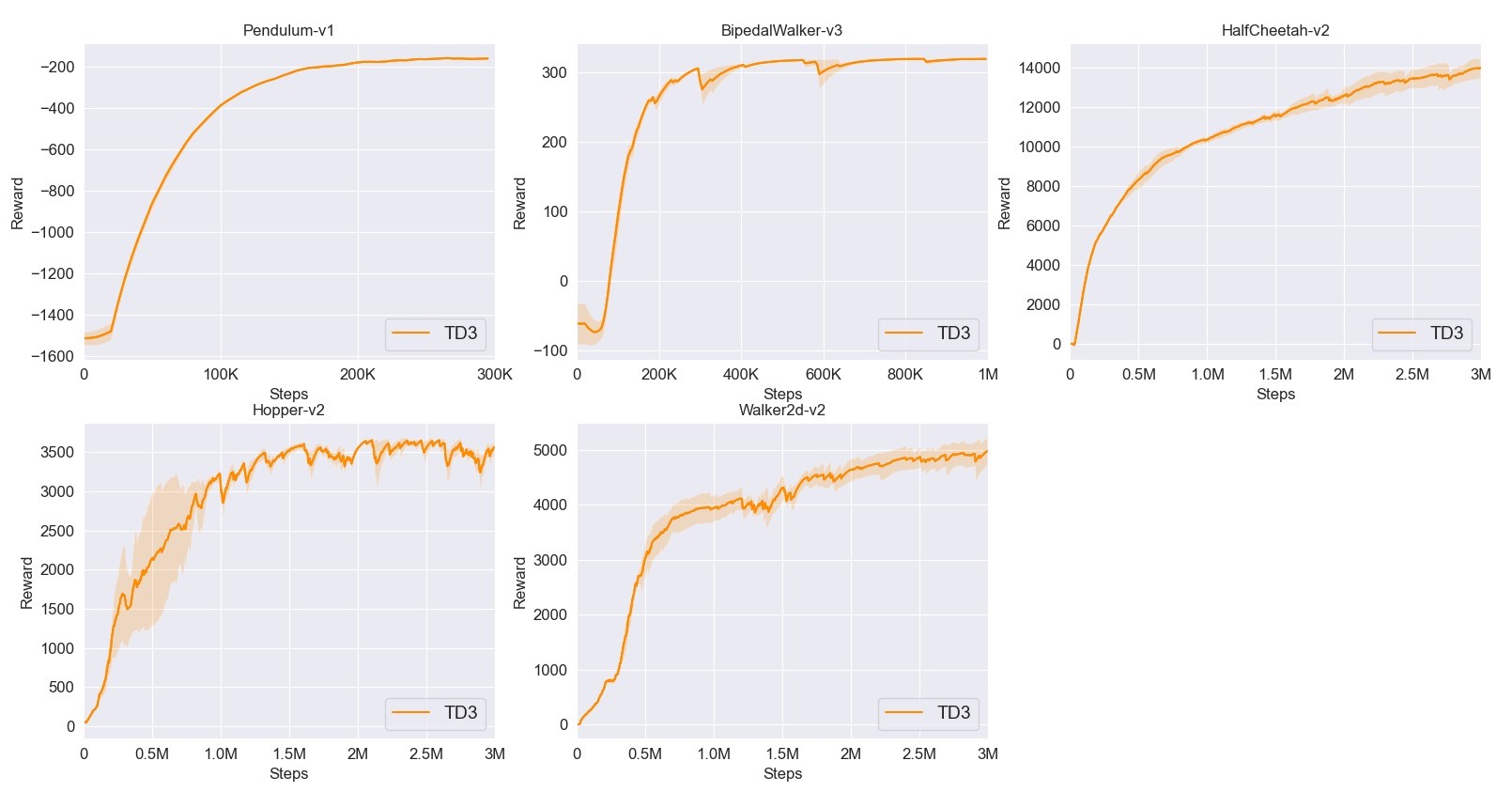
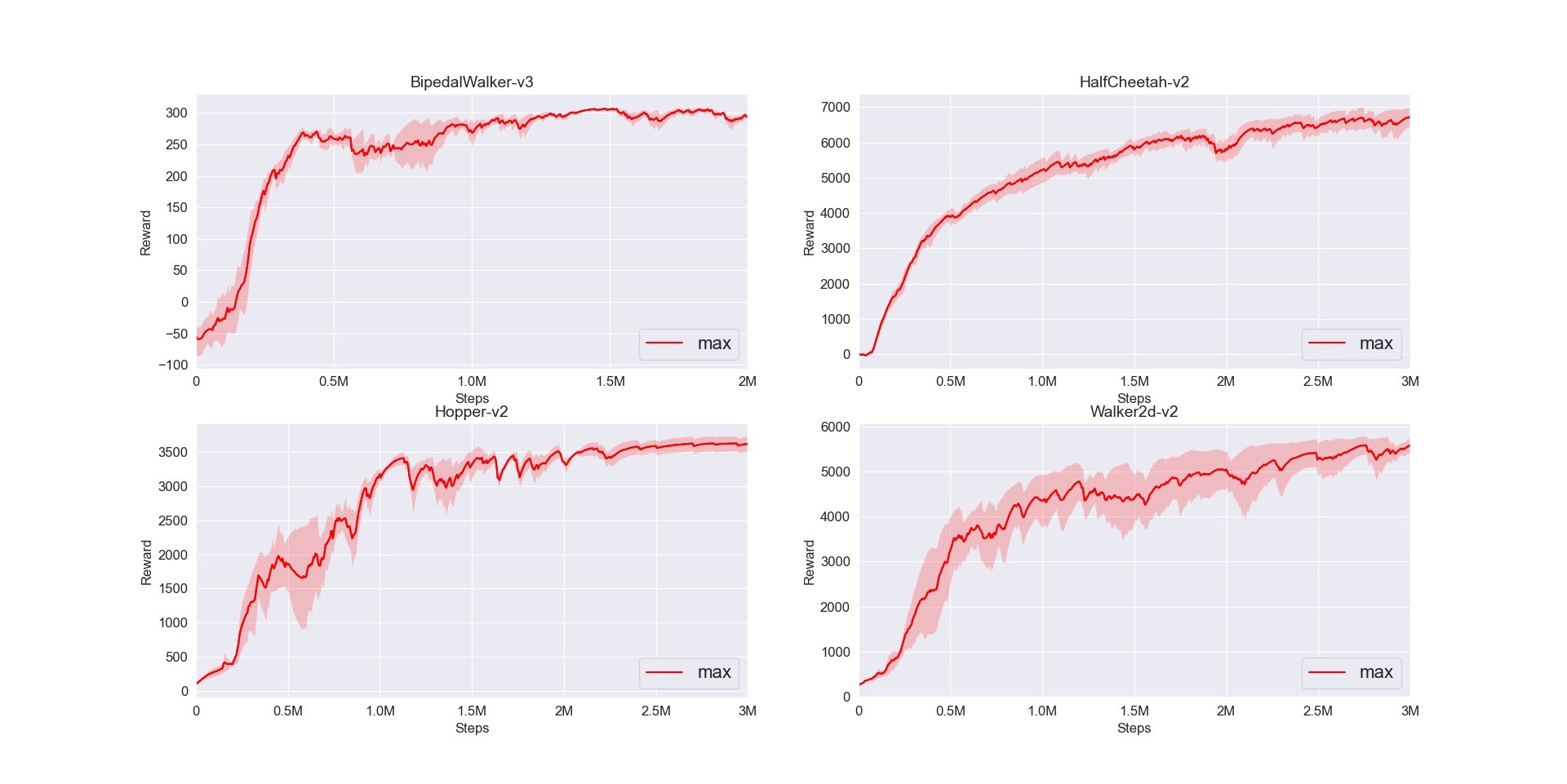
7. TD3
TD3是对DDPG的改进,通过延迟策略更新、双Q网络等方法,提升算法稳定性。
8. SAC
软演员 - 评论家(SAC),基于最大熵原理,在学习最优策略的同时最大化策略的熵,增加探索性。
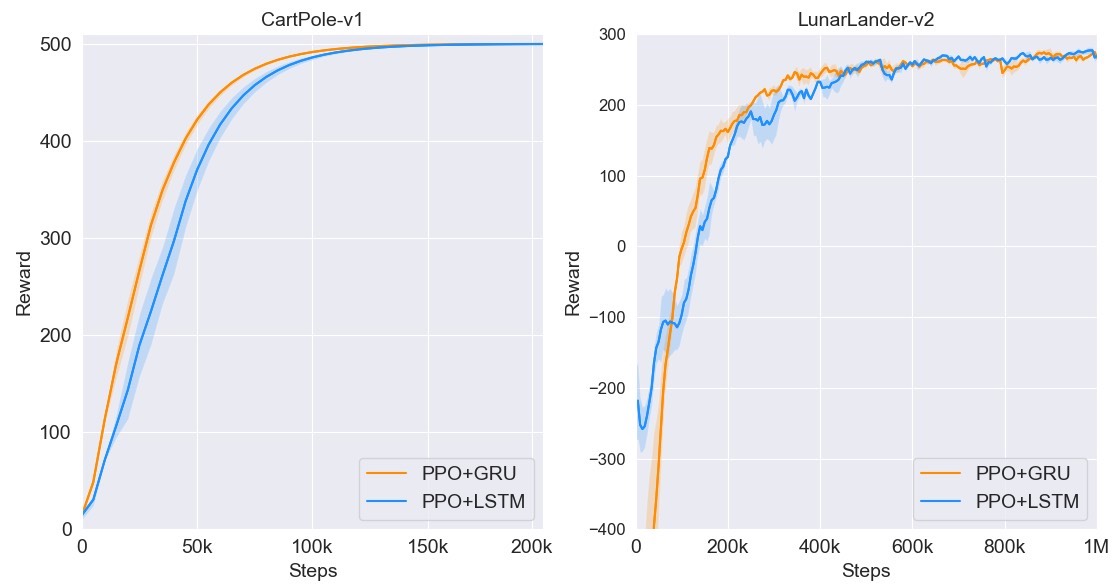
9. PPO - discrete - RNN
带有循环神经网络(RNN)的离散PPO版本,适用于处理序列相关的状态信息。
三、总结
这9种DRL算法涵盖了基于策略梯度、基于价值以及二者结合的多种方法,对于强化学习初学者来说,是非常好的学习资源。通过实践这些算法,你能深入理解强化学习的核心概念,掌握使用Pytorch进行强化学习算法开发的技能。赶紧动手试试吧!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)