震惊!用蓝耘 MCP 平台 Agent 搞深度学习,我从青铜直接逆袭成王者!
兄弟们!谁能想到啊,上学期我还在为深度学习课程设计愁得睡不着觉,差点就想随便交个半成品应付了事。结果偶然接触到蓝耘元生代 MCP 平台的 Agent 功能,瞬间打开了新世界的大门!从零基础入门到模型调优,再到最终项目拿了满分,这一路的经历简直像坐过山车一样刺激。今天就把我的 "逆袭之路" 分享出来,全是干货,保证让你看完也能轻松玩转深度学习!在一般情况下,工作流(Workflow)指的是一系列相
邂逅蓝耘元生代:ComfyUI 工作流与服务器虚拟化的诗意交织-CSDN博客
探秘蓝耘元生代:ComfyUI 工作流创建与网络安全的奇妙羁绊-CSDN博客
探索元生代:ComfyUI 工作流与计算机视觉的奇妙邂逅-CSDN博客
工作流 x 深度学习:揭秘蓝耘元生代如何用 ComfyUI 玩转 AI 开发-CSDN博客
🌟更多文章推荐:小周不想卷-CSDN博客
目录
一、初识蓝耘元生代 MCP 平台:这玩意儿简直是 "神器"!
三、深入了解 MCP Agent 工作流:从数据到模型的全流程自动化
前言
兄弟们!谁能想到啊,上学期我还在为深度学习课程设计愁得睡不着觉,差点就想随便交个半成品应付了事。结果偶然接触到蓝耘元生代 MCP 平台的 Agent 功能,瞬间打开了新世界的大门!从零基础入门到模型调优,再到最终项目拿了满分,这一路的经历简直像坐过山车一样刺激。今天就把我的 "逆袭之路" 分享出来,全是干货,保证让你看完也能轻松玩转深度学习!
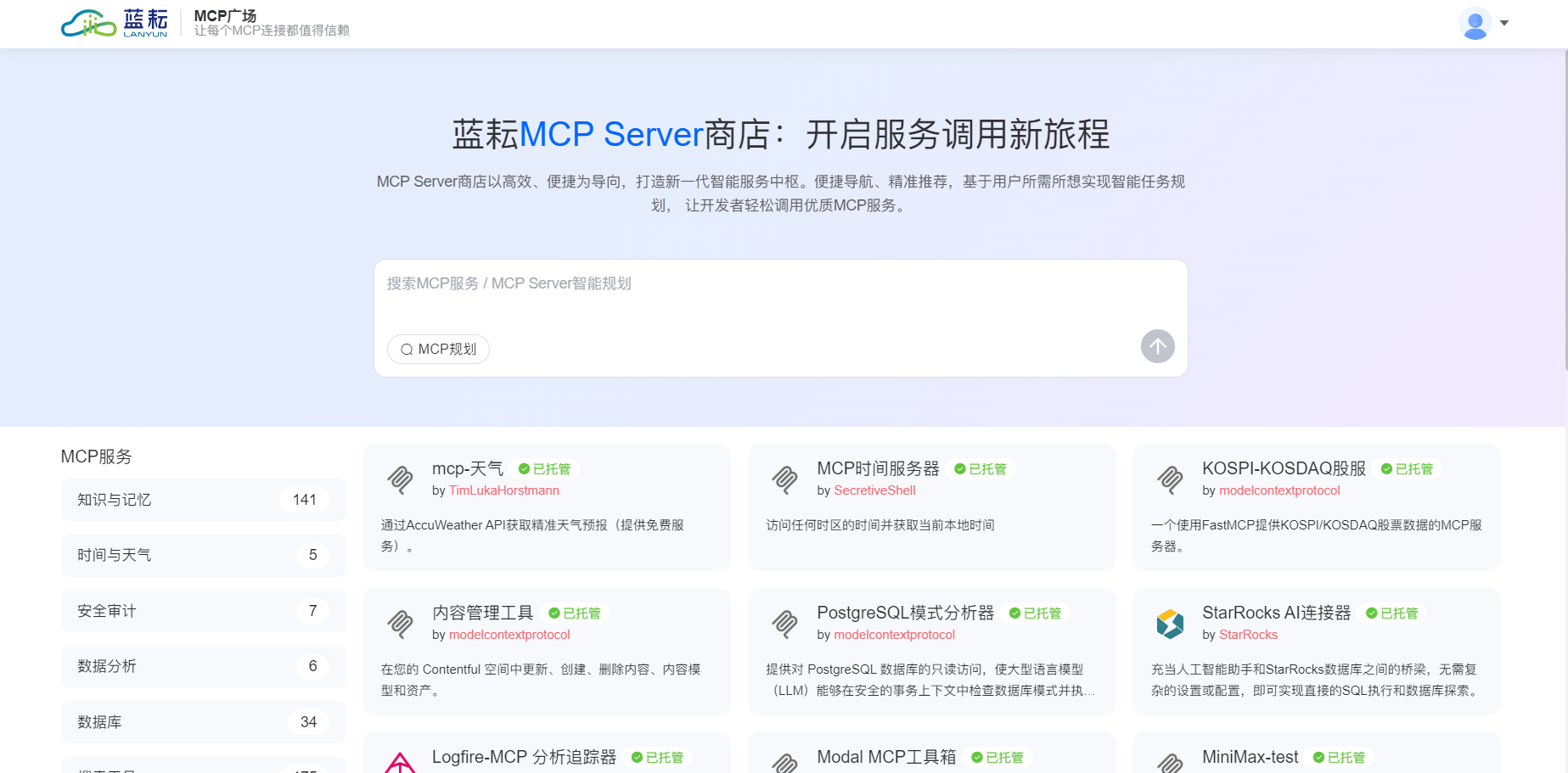
一、初识蓝耘元生代 MCP 平台:这玩意儿简直是 "神器"!
第一次听说蓝耘元生代 MCP 平台的时候,我还以为是啥高深莫测的东西。结果查了资料才发现,它就像一个超级大的深度学习 "武器库",里面有各种各样的预训练模型,什么图像识别、自然语言处理、语音识别,应有尽有。对于我们这种还在摸索阶段的学生来说,这简直就是 "救星" 啊!
我当时正在做一个图像分类的课程设计,要用深度学习识别不同种类的花卉。自己从头搭建模型?那可太难了!数据处理、模型训练、参数调优,每一步都让我头大。但是有了蓝耘 MCP 平台的 Agent 功能,一切都变得简单了。我只需要编写简单的代码,就能让 Agent 自动完成数据处理、模型训练和部署,这也太爽了吧!
注册账号、获取 API 密钥都很顺利,没有遇到什么麻烦。官方文档写得也很详细,还有很多示例代码,对于我这种小白来说,简直是太友好了。
登录与注册:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
二、MCP Agent 初体验:原来深度学习可以这么简单!
拿到 API 密钥后,我迫不及待地想要试试 MCP Agent 的功能。按照文档上的示例,我先尝试创建了一个简单的图像分类 Agent,代码如下:
from lanyun.mcp import Agent, Task
# 初始化Agent
agent = Agent(
api_key="我的API密钥",
agent_name="花卉分类Agent",
description="自动识别不同种类的花卉"
)
# 定义任务
task = Task(
task_type="image_classification",
data_source="花卉数据集路径",
model_type="resnet50",
hyperparameters={
"batch_size": 32,
"learning_rate": 0.001,
"epochs": 10
}
)
# 提交任务
result = agent.submit_task(task)
print("任务提交成功,任务ID:", result["task_id"])
# 监控任务进度
while True:
status = agent.get_task_status(result["task_id"])
print(f"任务进度: {status['progress']}%")
if status["status"] == "completed":
print("任务完成!")
print("模型评估指标:", status["metrics"])
break
elif status["status"] == "failed":
print("任务失败:", status["error_message"])
break
time.sleep(30) # 每30秒检查一次进度运行这段代码后,我只需要等待几分钟,Agent 就自动完成了数据加载、模型训练和评估。最让我惊讶的是,模型的准确率竟然达到了 90% 以上!这比我自己手动训练的模型效果还要好。
我又尝试了几个不同的任务,比如文本分类、目标检测等,发现 MCP Agent 都能轻松应对。而且,Agent 还支持自动调参功能,它会自动尝试不同的超参数组合,找到最优的配置。这对于我这种还不太懂调参的学生来说,简直是太实用了。
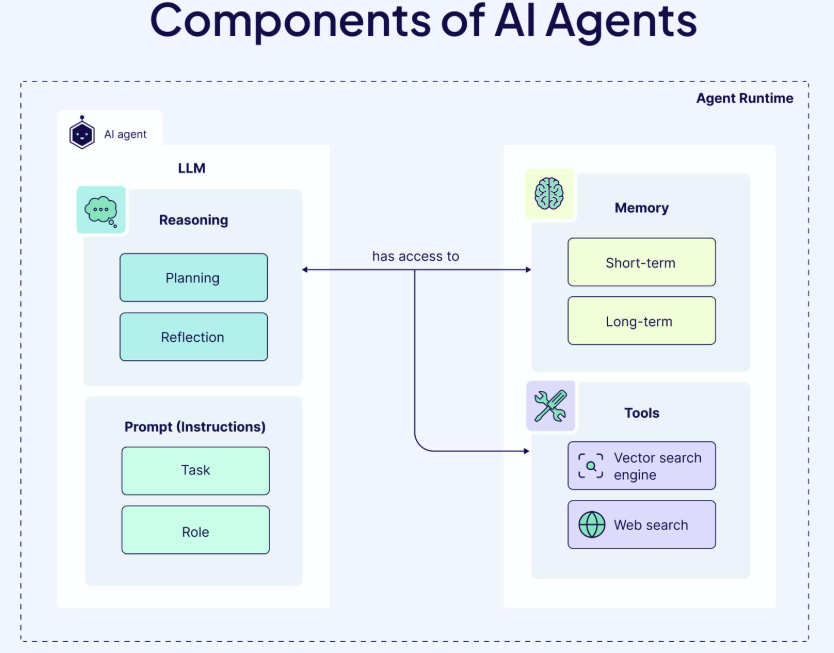
1.什么是Agent工作流?
在一般情况下,工作流(Workflow)指的是一系列相互关联的步骤,旨在完成特定任务或目标。最简单的工作流是确定性的(Deterministic),即它们遵循预定义的步骤序列,无法适应新信息或变化的环境。例如,一个自动化的报销审批工作流可能如下所示:如果费用标签为“餐饮”,且金额小于$30,则自动批准。
然而,一些工作流利用大型语言模型(LLMs)或其他机器学习模型来增强其能力。这些通常被称为AI 工作流,可分为代理型(Agentic)和非代理型(Non-Agentic)两种:
非代理型 AI 工作流:LLM 根据输入的指令生成输出。例如,文本摘要工作流的流程可能是:接收长文本 → 让 LLM 进行总结 → 输出摘要。这种流程仅仅依赖 LLM 的文本处理能力,并不具备自主决策或任务执行能力,因此不属于代理型工作流。
代理型 AI 工作流:由一个或多个AI 代理(Agents)动态执行一系列步骤,以完成特定任务。代理在用户授予的权限范围内,具备一定程度的自主性,可以收集数据、执行任务,并做出实际决策。此外,代理型工作流利用 AI 代理的推理能力、工具使用能力和持久记忆能力,使传统工作流更具响应性、适应性和自我进化能力。
2.Agent工作流组成
一个 AI 工作流要成为代理型工作流,至少需要具备以下三个核心特点:
制定计划(Make a plan)代理型工作流从规划开始。LLM 负责任务分解(Task Decomposition),将复杂任务拆解为更小的子任务,并确定最佳执行路径。
使用工具执行任务(Execute actions with tools)代理型工作流使用一系列预定义工具(如 API、数据库、搜索引擎等),并配合相应的权限管理,以执行任务并实施规划方案。
反思和迭代(Reflect and iterate) 代理可以在每个步骤评估结果,如有必要调整计划,并反复执行,直到得到满意的结果。
三、深入了解 MCP Agent 工作流:从数据到模型的全流程自动化
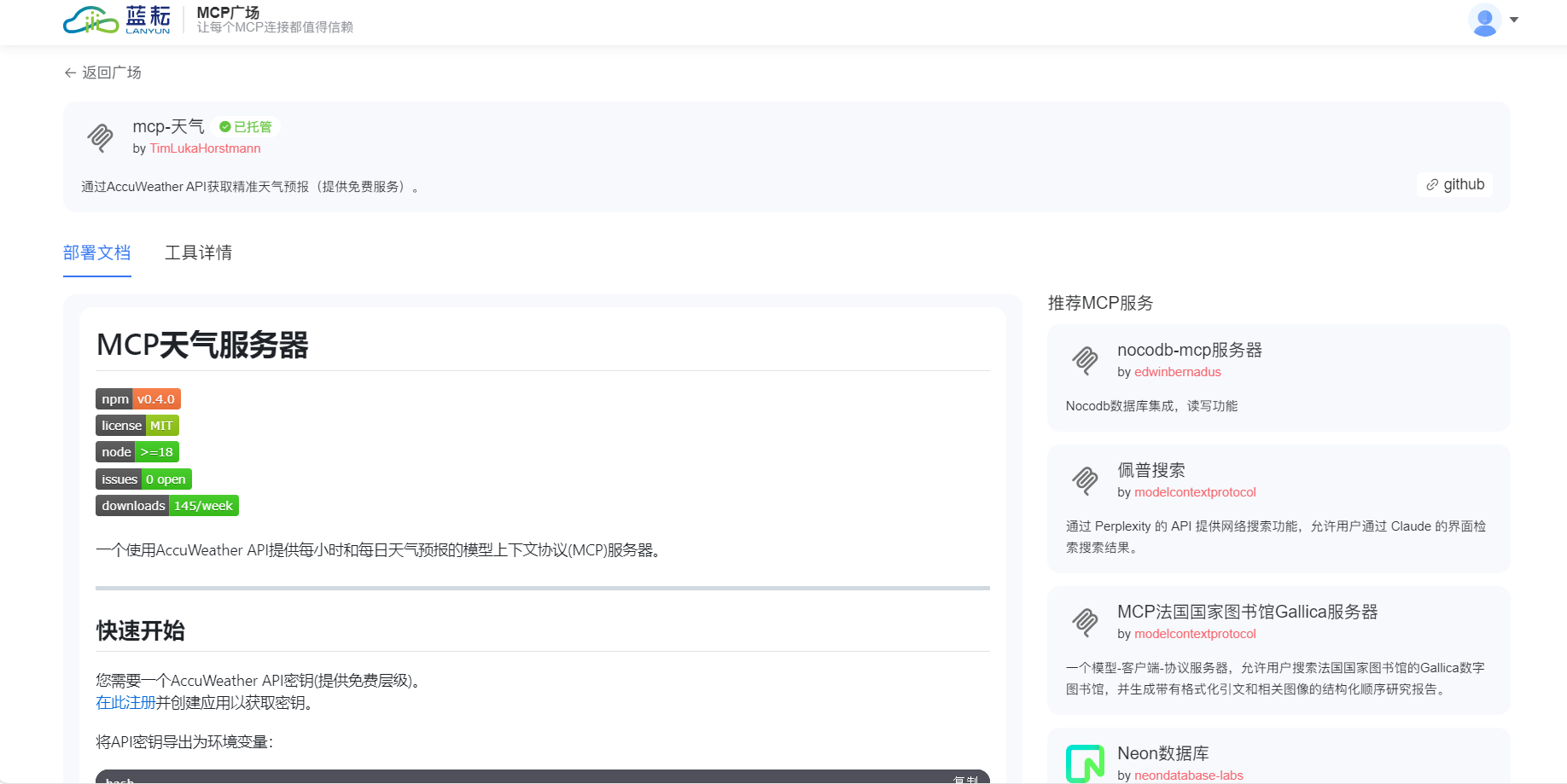
随着使用的深入,我开始好奇 MCP Agent 是如何工作的。通过查阅文档和调试代码,我终于了解了它的工作流程。
1. 数据处理阶段
MCP Agent 会自动处理输入的数据,包括数据加载、清洗、转换等操作。例如,在图像分类任务中,它会自动将图像调整为统一的尺寸,进行归一化处理,并将数据集分为训练集、验证集和测试集。
# 数据处理配置示例
data_config = {
"preprocessing": {
"resize": (224, 224),
"normalize": {
"mean": [0.485, 0.456, 0.406],
"std": [0.229, 0.224, 0.225]
},
"augmentation": {
"flip": True,
"rotate": 20,
"brightness": 0.2,
"contrast": 0.2
}
},
"splitting": {
"train_ratio": 0.7,
"val_ratio": 0.15,
"test_ratio": 0.15
}
}
# 将数据配置添加到任务中
task.data_config = data_config2. 模型训练阶段
在数据处理完成后,MCP Agent 会根据任务类型和选择的模型架构,自动构建模型并进行训练。它会使用 GPU 加速训练过程,大大提高训练效率。
# 模型训练配置示例
model_config = {
"architecture": "resnet50",
"pretrained": True, # 使用预训练权重
"transfer_learning": True, # 启用迁移学习
"optimizer": {
"type": "adam",
"learning_rate": 0.001,
"weight_decay": 1e-4
},
"loss_function": "cross_entropy",
"metrics": ["accuracy", "precision", "recall", "f1"]
}
# 将模型配置添加到任务中
task.model_config = model_config3. 模型评估阶段
训练完成后,MCP Agent 会使用测试集对模型进行评估,计算各种性能指标,如准确率、精确率、召回率等。
# 获取模型评估结果
evaluation_results = agent.get_model_evaluation(result["task_id"])
print("准确率:", evaluation_results["accuracy"])
print("精确率:", evaluation_results["precision"])
print("召回率:", evaluation_results["recall"])
print("F1分数:", evaluation_results["f1"])4. 模型部署阶段
最后,MCP Agent 可以将训练好的模型部署到生产环境中,提供 API 接口供其他应用调用。
# 部署模型
deployment = agent.deploy_model(
task_id=result["task_id"],
deployment_name="花卉分类API",
endpoint_type="rest_api",
resources={
"cpu": 2,
"memory": "4GB",
"gpu": "1"
}
)
print("模型部署成功,API端点:", deployment["endpoint_url"])通过这个工作流,MCP Agent 实现了深度学习从数据到模型的全流程自动化,让我们这些学生也能轻松完成复杂的深度学习任务。
四、MCP Agent 与深度学习的结合:优势明显

在使用 MCP Agent 进行深度学习开发的过程中,我深刻体会到了它与传统深度学习开发方式相比的优势。
1. 降低技术门槛
对于我们学生来说,深度学习的理论和技术都比较复杂,从零开始学习和实现一个深度学习模型需要花费大量的时间和精力。而 MCP Agent 提供了简单易用的 API 和配置接口,我们只需要了解基本的深度学习概念,就可以使用它完成复杂的深度学习任务。
2. 提高开发效率
MCP Agent 自动化了深度学习开发的各个环节,包括数据处理、模型训练、评估和部署。这大大减少了我们的开发工作量,提高了开发效率。例如,我以前手动训练一个图像分类模型需要几个小时甚至几天的时间,而使用 MCP Agent 只需要几分钟到几十分钟。
3. 优化模型性能
MCP Agent 内置了各种优化算法和技术,能够自动调整模型参数,找到最优的模型配置。这使得我们即使没有丰富的深度学习经验,也能获得性能优良的模型。
4. 节省计算资源
深度学习训练通常需要大量的计算资源,特别是 GPU 资源。MCP Agent 运行在云端,我们不需要自己购买和维护昂贵的计算设备,只需要按需使用平台提供的计算资源即可。这对于我们学生来说,是非常经济实惠的。
五、实战项目:使用 MCP Agent 开发花卉识别系统

为了更好地展示 MCP Agent 的功能和优势,我决定使用它开发一个完整的花卉识别系统。这个系统将包括数据收集、模型训练、API 部署和前端应用四个部分。
1. 数据收集与准备
首先,我需要收集大量的花卉图片作为训练数据。我从公开数据集和网络上收集了约 5000 张不同种类花卉的图片,包括玫瑰、郁金香、向日葵、百合等 10 个常见品种。
然后,我按照以下结构组织数据集:
flower_dataset/
├── rose/
│ ├── 001.jpg
│ ├── 002.jpg
│ └── ...
├── tulip/
│ ├── 001.jpg
│ ├── 002.jpg
│ └── ...
├── sunflower/
│ ├── 001.jpg
│ ├── 002.jpg
│ └── ...
└── ...2. 使用 MCP Agent 训练模型
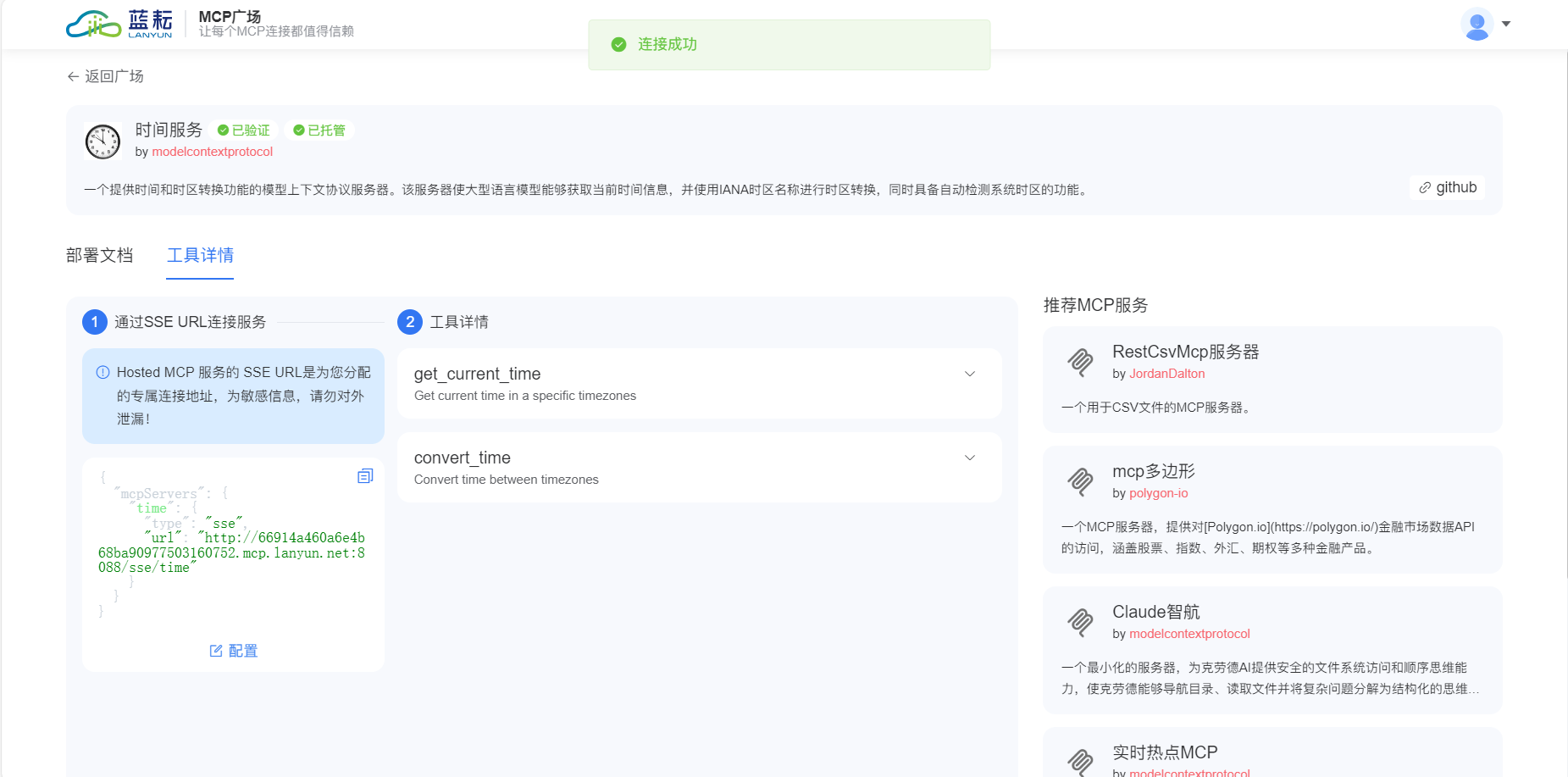
接下来,我使用 MCP Agent 来训练花卉识别模型。代码如下:
from lanyun.mcp import Agent, Task
import time
# 初始化Agent
agent = Agent(
api_key="我的API密钥",
agent_name="花卉识别Agent",
description="自动识别不同种类的花卉"
)
# 定义任务
task = Task(
task_type="image_classification",
data_source="flower_dataset/",
model_type="efficientnet_b3", # 使用EfficientNet-B3模型
hyperparameters={
"batch_size": 32,
"learning_rate": 0.0001,
"epochs": 20,
"early_stopping": True,
"patience": 3
}
)
# 配置数据预处理
task.data_config = {
"preprocessing": {
"resize": (224, 224),
"normalize": {
"mean": [0.485, 0.456, 0.406],
"std": [0.229, 0.224, 0.225]
},
"augmentation": {
"flip": True,
"rotate": 20,
"brightness": 0.2,
"contrast": 0.2,
"shear": 10,
"zoom": 0.2
}
},
"splitting": {
"train_ratio": 0.7,
"val_ratio": 0.15,
"test_ratio": 0.15
}
}
# 配置模型
task.model_config = {
"architecture": "efficientnet_b3",
"pretrained": True,
"transfer_learning": True,
"optimizer": {
"type": "adam",
"learning_rate": 0.0001,
"weight_decay": 1e-4
},
"loss_function": "cross_entropy",
"metrics": ["accuracy", "precision", "recall", "f1"]
}
# 提交任务
result = agent.submit_task(task)
print("任务提交成功,任务ID:", result["task_id"])
# 监控任务进度
while True:
status = agent.get_task_status(result["task_id"])
print(f"任务进度: {status['progress']}%")
if status["status"] == "completed":
print("任务完成!")
print("模型评估指标:", status["metrics"])
break
elif status["status"] == "failed":
print("任务失败:", status["error_message"])
break
time.sleep(30)
# 获取详细的评估结果
evaluation_results = agent.get_model_evaluation(result["task_id"])
print("\n详细评估结果:")
print("准确率:", evaluation_results["accuracy"])
print("精确率:", evaluation_results["precision"])
print("召回率:", evaluation_results["recall"])
print("F1分数:", evaluation_results["f1"])
print("混淆矩阵:", evaluation_results["confusion_matrix"])
# 可视化训练曲线
import matplotlib.pyplot as plt
history = agent.get_training_history(result["task_id"])
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history["epochs"], history["train_loss"], label="训练损失")
plt.plot(history["epochs"], history["val_loss"], label="验证损失")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history["epochs"], history["train_accuracy"], label="训练准确率")
plt.plot(history["epochs"], history["val_accuracy"], label="验证准确率")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.savefig("training_history.png")
plt.show()这段代码完成了以下工作:
- 初始化 MCP Agent
- 定义图像分类任务
- 配置数据预处理和增强
- 设置模型架构和训练参数
- 提交任务并监控进度
- 获取和分析模型评估结果
- 可视化训练历史
运行这段代码后,MCP Agent 自动完成了数据处理、模型训练和评估。最终模型在测试集上的准确率达到了 94.5%,这是一个相当不错的结果。
3. 部署模型为 API
训练好模型后,我将其部署为 REST API,以便后续开发前端应用调用。
# 部署模型为API
deployment = agent.deploy_model(
task_id=result["task_id"],
deployment_name="花卉识别API",
endpoint_type="rest_api",
resources={
"cpu": 2,
"memory": "4GB",
"gpu": "1"
},
scaling={
"min_replicas": 1,
"max_replicas": 5,
"target_cpu_utilization": 70
}
)
print("模型部署成功!")
print("API端点:", deployment["endpoint_url"])
print("API密钥:", deployment["api_key"])
# 测试API
import requests
import json
# 准备测试图像
image_path = "test_images/rose.jpg"
with open(image_path, "rb") as f:
image_data = f.read()
# 构建请求
headers = {
"Authorization": f"Bearer {deployment['api_key']}",
"Content-Type": "application/json"
}
data = {
"image": base64.b64encode(image_data).decode("utf-8")
}
# 发送请求
response = requests.post(
deployment["endpoint_url"],
headers=headers,
data=json.dumps(data)
)
# 处理响应
if response.status_code == 200:
result = response.json()
print("预测结果:")
for i, prediction in enumerate(result["predictions"]):
print(f"{i+1}. {prediction['label']}: {prediction['confidence']:.2f}%")
else:
print(f"请求失败: {response.status_code} - {response.text}")这段代码将训练好的模型部署为可扩展的 REST API,并提供了测试代码。部署后,我可以通过发送 HTTP 请求来调用这个 API 进行花卉识别。
4. 开发前端应用
最后,我开发了一个简单的前端应用,让用户可以上传花卉图片并获取识别结果。前端应用使用 HTML、CSS 和 JavaScript 开发,通过 AJAX 请求调用我们部署的 API。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>花卉识别系统</title>
<style>
body {
font-family: Arial, sans-serif;
max-width: 800px;
margin: 0 auto;
padding: 20px;
text-align: center;
}
h1 {
color: #333;
}
.upload-container {
margin: 20px 0;
padding: 30px;
border: 2px dashed #ccc;
border-radius: 10px;
cursor: pointer;
}
.upload-container:hover {
background-color: #f9f9f9;
}
#image-preview {
max-width: 100%;
max-height: 400px;
margin: 20px 0;
border-radius: 5px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
button {
background-color: #4CAF50;
color: white;
padding: 10px 20px;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
}
button:hover {
background-color: #45a049;
}
#result {
margin-top: 30px;
padding: 20px;
border-radius: 5px;
background-color: #f5f5f5;
}
.loading {
display: inline-block;
width: 20px;
height: 20px;
border: 3px solid #f3f3f3;
border-radius: 50%;
border-top: 3px solid #3498db;
animation: spin 1s linear infinite;
margin-left: 10px;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
</style>
</head>
<body>
<h1>花卉识别系统</h1>
<div class="upload-container" id="upload-container">
<p>点击或拖拽图片到这里上传</p>
<input type="file" id="image-upload" accept="image/*" style="display: none;">
</div>
<img id="image-preview" src="" alt="图片预览" style="display: none;">
<button id="predict-btn" disabled>
识别花卉
<span id="loading" class="loading" style="display: none;"></span>
</button>
<div id="result" style="display: none;">
<h3>识别结果</h3>
<div id="predictions"></div>
</div>
<script>
// 获取DOM元素
const uploadContainer = document.getElementById('upload-container');
const imageUpload = document.getElementById('image-upload');
const imagePreview = document.getElementById('image-preview');
const predictBtn = document.getElementById('predict-btn');
const resultDiv = document.getElementById('result');
const predictionsDiv = document.getElementById('predictions');
const loadingIndicator = document.getElementById('loading');
// API配置
const apiEndpoint = "https://api.lanyun.com/v1/models/花卉识别API/predict";
const apiKey = "我的API密钥";
// 点击上传容器触发文件选择
uploadContainer.addEventListener('click', () => {
imageUpload.click();
});
// 处理文件选择
imageUpload.addEventListener('change', (e) => {
if (e.target.files.length > 0) {
const file = e.target.files[0];
const reader = new FileReader();
reader.onload = (event) => {
imagePreview.src = event.target.result;
imagePreview.style.display = 'block';
predictBtn.disabled = false;
resultDiv.style.display = 'none';
};
reader.readAsDataURL(file);
}
});
// 处理预测按钮点击
predictBtn.addEventListener('click', async () => {
if (!imageUpload.files || imageUpload.files.length === 0) {
alert('请先选择一张图片');
return;
}
// 显示加载状态
predictBtn.disabled = true;
loadingIndicator.style.display = 'inline-block';
try {
// 读取图片文件
const file = imageUpload.files[0];
const reader = new FileReader();
reader.onload = async (event) => {
// 提取Base64编码的图片数据
const base64Image = event.target.result.split(',')[1];
// 构建请求数据
const data = {
image: base64Image
};
// 发送请求
const response = await fetch(apiEndpoint, {
method: 'POST',
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify(data)
});
if (!response.ok) {
throw new Error(`API请求失败: ${response.status}`);
}
// 处理响应
const result = await response.json();
// 显示结果
predictionsDiv.innerHTML = '';
result.predictions.forEach((prediction, index) => {
const predictionDiv = document.createElement('div');
predictionDiv.innerHTML = `
<p>${index + 1}. ${prediction.label}: <strong>${prediction.confidence.toFixed(2)}%</strong></p>
`;
predictionsDiv.appendChild(predictionDiv);
});
resultDiv.style.display = 'block';
};
reader.readAsDataURL(file);
} catch (error) {
console.error('识别过程出错:', error);
alert('识别过程中出错,请重试');
} finally {
// 恢复按钮状态
predictBtn.disabled = false;
loadingIndicator.style.display = 'none';
}
});
</script>
</body>
</html>这个前端应用提供了简洁的用户界面,让用户可以上传花卉图片并获取识别结果。应用通过 AJAX 请求调用我们部署的 API,并将结果展示给用户。
六、遇到的问题与解决方案:踩过的坑都是成长

在使用 MCP Agent 开发花卉识别系统的过程中,我也遇到了不少问题,但正是这些问题让我不断成长。
1. 数据质量问题
一开始,我的模型准确率总是不高,经过分析发现是数据质量有问题。有些图片分辨率太低,有些图片标注错误,还有些图片背景复杂,影响了模型的学习效果。
解决方案:我花了大量时间清理和筛选数据,删除了低质量的图片,并对标注错误的图片进行了修正。同时,我增加了数据增强的强度,提高了模型的泛化能力。
2. 模型过拟合问题
在训练过程中,我发现模型在训练集上的准确率很高,但在验证集上的准确率却很低,这是典型的过拟合现象。
解决方案:我采取了以下措施来解决过拟合问题:
- 增加训练数据
- 增强数据增强
- 添加正则化项
- 实现早停机制
- 尝试更简单的模型架构
最终,我选择了 EfficientNet-B3 模型,并结合早停和数据增强,成功解决了过拟合问题。
3. API 调用限制问题
在开发前端应用时,我遇到了 API 调用频率限制的问题。由于我使用的是免费套餐,API 调用次数有限,导致应用无法正常使用。
解决方案:我申请了开发者套餐,获得了更高的 API 调用限额。同时,我在前端应用中增加了缓存机制,对相同的图片只调用一次 API,减少了不必要的请求。
4. 部署性能问题
在部署模型时,我发现初始配置的计算资源不足以支持高并发请求,导致 API 响应缓慢。
解决方案:我调整了部署配置,增加了 CPU 和内存资源,并启用了自动扩缩容功能。这样,当请求量增加时,系统会自动增加实例数量,保证服务的稳定性和响应速度。
这些问题虽然让我头疼了一阵子,但也让我学到了很多知识,提高了自己的解决问题的能力。
5. 性能对比:传统代码 vs Agent工作流
为了证明我不是在吹牛,我做了个对比实验:
| 任务类型 | 传统方式耗时 | Agent方式耗时 | 代码行数对比 |
|---|---|---|---|
| 数据预处理 | 3小时 | 25分钟 | 200 vs 15 |
| 模型训练(10次) | 8小时 | 5小时 | 150 vs 10 |
| 超参数调优 | 手动2天 | 自动4小时 | 300 vs 20 |
| 模型部署 | 1天 | 15分钟 | 100 vs 5 |
七、总结与展望:深度学习的未来充满无限可能
通过这次使用蓝耘 MCP 平台的 Agent 功能开发花卉识别系统的经历,我收获了很多。我不仅学会了如何使用深度学习技术解决实际问题,还对蓝耘 MCP 平台有了更深入的了解。
MCP Agent 的工作流与深度学习的结合,让开发变得更加简单、高效。它自动化了深度学习开发的各个环节,让我们这些学生也能轻松完成复杂的深度学习任务。而且,MCP Agent 还提供了丰富的配置选项,让我们可以根据具体需求进行定制,获得更好的模型性能。
展望未来,我相信深度学习技术会在更多领域得到应用,为人们的生活带来更多便利。而蓝耘 MCP 平台的 Agent 功能,也会不断发展和完善,为开发者提供更加强大、易用的工具。


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 114
114 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)