利用 Spring AI、Vertex AI 和 BigQuery 在 Java 中构建检索增强生成(RAG)系统
使用 Spring Boot、Vertex AI 嵌入、BigQuery 矢量搜索以及用于交互式 PDF 问答的网页界面,构建一个 Java RAG 应用。
检索增强生成(RAG)正迅速成为人工智能应用中最强大的设计模式之一。它弥合了通用大型语言模型(LLM)与您具体企业数据之间的差距。在本文中,我们将讲解如何利用 Spring Boot、Vertex AI 的 Gemini 嵌入、Apache PDFBox 和 BigQuery 向量搜索,在 Java 中构建完整的 RAG 流水线。
你将看到如何实现以下作,采用带有简单网页界面的 Spring Boot 应用:
- 上传PDF
- 使用 Vertex AI 生成嵌入
- 它们存储在BigQuery
- 根据你的文件提出自然语言问题
什么是RAG?
检索增强生成(RAG)系统通过结合检索(搜索)和生成(LLM响应)来增强LLM的输出。它通过获取最相关的文档片段来生成答案,确保回答上下文准确、最新且基于来源。
以下是概念的流畅:
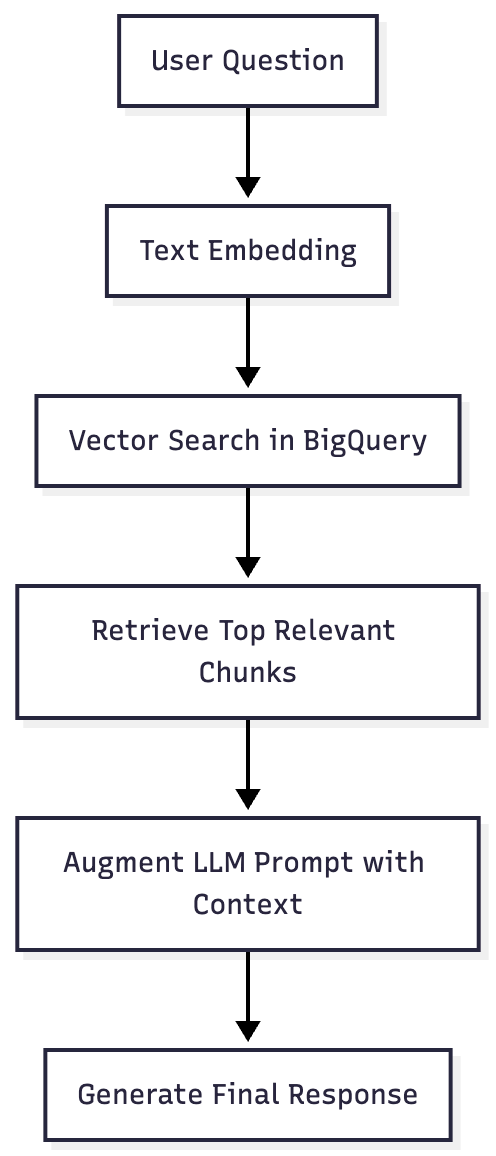
春季人工智能介绍
虽然像LangChain这样的框架主导着基于Python的生成式人工智能开发,但Java开发者现在有了原生且准备好生产的替代方案:Spring AI。由Spring团队构建和维护,Spring AI将熟悉的Spring Boot生态系统扩展到大型语言模型应用领域。
春季AI的功能
Spring AI 提供了一个简单且一致的抽象层,用于调用 AI 模型——文本生成、嵌入或聊天——无需处理原始的 REST 端点或认证样板。它会自动管理:
- 模型配置通过
application.properties - 提示编排与消息处理
- 使用 Google Cloud、OpenAI 或其他提供商进行凭证解析
- 与您的 Spring Boot 应用栈无缝集成
在本项目中,Spring AI 处理与 Vertex AI 模型的通信,简化了嵌入生成的 API 调用,同时保持与 Spring WebFlux 和依赖注入的完全兼容。gemini-embedding-001
为什么这里有用
整合Spring AI让我们能够:
- 使用相同的Spring术语(Beans、Controllers、Configuration)来构建生成式AI应用
- 可以轻松切换不同供应商的嵌入和聊天模型
- 保持应用轻量级,适合云端部署
- 保持与企业 Spring Boot 服务一致的可测试性和可观察性
工作原理
1. PDF 上传与解析
当用户通过网页界面上传PDF时,会被Apache PDFBox处理——这是一个可靠的从PDF文档中提取文本的库。
PDFTextStripper stripper = new PDFTextStripper(); stripper = new PDFTextStripper();String text = stripper.getText(document); text = stripper.getText(document);然后将文本拆分为易于管理的块(例如500字符,重叠100字符),以便检索更精确。
private List<String> chunkText(String text, int chunkSize, int overlap) { List<String> chunkText(String text, int chunkSize, int overlap) { List<String> chunks = new ArrayList<>();List<String> chunks = new ArrayList<>(); for (int i = 0; i < text.length(); i += (chunkSize - overlap)) {for (int i = 0; i < text.length(); i += (chunkSize - overlap)) { chunks.add(text.substring(i, Math.min(text.length(), i + chunkSize)));chunks.add(text.substring(i, Math.min(text.length(), i + chunkSize))); } return chunks;return chunks;}2. 使用顶点人工智能生成嵌入
每个块都被发送到Vertex AI的模型,以获得一个3072维的嵌入向量,代表其语义意义。gemini-embedding-001
String url = String.format( url = String.format( "/v1/projects/%s/locations/%s/publishers/google/models/gemini-embedding-001:predict","/v1/projects/%s/locations/%s/publishers/google/models/gemini-embedding-001:predict", projectId, locationprojectId, location);String body = "{ \"instances\": [{\"content\": \"" + text + "\"}] }"; body = "{ \"instances\": [{\"content\": \"" + text + "\"}] }";String response = webClient.post() response = webClient.post() .uri(url)uri(url) .bodyValue(body)bodyValue(body) .retrieve()retrieve() .bodyToMono(String.class)bodyToMono(String.class) .block();block();所得的嵌入矢量以列形式存储在BigQuery中。ARRAY<FLOAT64>
3. 在 BigQuery 中存储和搜索
每个嵌入,连同其文本块和元数据,都入到BigQuery表中:
CREATE TABLE rag_dataset.doc_embeddings ( TABLE rag_dataset.doc_embeddings ( doc_id STRING, chunk_id STRING, content STRING, embedding ARRAY<FLOAT64>);该应用使用 BigQuery Java SDK 来插入行:
TableId tableId = TableId.of("rag_dataset", "doc_embeddings"); tableId = TableId.of("rag_dataset", "doc_embeddings");InsertAllRequest insertRequest = InsertAllRequest.newBuilder(tableId) insertRequest = InsertAllRequest.newBuilder(tableId) .addRow(Map.of(addRow(Map.of( "doc_id", docId,"doc_id", docId, "chunk_id", chunkId,"chunk_id", chunkId, "content", content,"content", content, "embedding", embedding"embedding", embedding )) .build();build();bigQuery.insertAll(insertRequest);.insertAll(insertRequest);当用户提问时,应用会以同样的方式嵌入问题,并在BigQuery中使用函数进行向量相似度搜索:VECTOR_SEARCH
SELECT content contentFROM VECTOR_SEARCH( VECTOR_SEARCH( TABLE rag_dataset.doc_embeddings,TABLE rag_dataset.doc_embeddings, 'embedding','embedding', (SELECT [0.12, 0.45, -0.23, ...] AS embedding),SELECT [0.12, 0.45, -0.23, ...] AS embedding), top_k => 3,3, distance_type => 'COSINE''COSINE');4. 通过网页界面呈现答案
应用将语义相关的片段返回给网页界面,为用户提供即时且丰富的上下文响应。
基于Thymeleaf的简单前端允许你:
- 上传PDF
- 提问
- 实时查看结果
<form action="/api/upload" method="post" enctype="multipart/form-data">form action="/api/upload" method="post" enctype="multipart/form-data"> <input type="file" name="file" /><input type="file" name="file" /> <button type="submit">Upload</button><button type="submit">Upload</button></form>form><form id="askForm">form id="askForm"> <input type="text" id="question" name="question" placeholder="Ask your question" /><input type="text" id="question" name="question" placeholder="Ask your question" /> <button type="submit">Ask</button><button type="submit">Ask</button></form>form>构建与运行应用程序
先决条件
- Java 17+
- Maven 3.8+
- Google Cloud SDK 支持了 Vertex AI 和 BigQuery API
- 应用默认凭证(
gcloud auth application-default login)
建造与运行
mvn clean installmvn spring-boot:run然后打开 http://localhost:8080 访问界面。
数据集和表格设置
使用BigQuery控制台或CLI创建你的数据集和表格:
bq mk rag_datasetbq query --use_legacy_sql=false \--use_legacy_sql=false \<span style="color:#aa1111">'CREATE TABLE rag_dataset.doc_embeddings (</span> doc_id STRING, chunk_id STRING, content STRING, embedding ARRAY<FLOAT64>);'' 结论
只需几百行 Java 和 Spring Boot 代码,你就能搭建一个由 Google Cloud 驱动的生产准备 RAG 流水线。该架构干净利落地将摄取、嵌入和检索分开,成为企业AI应用的有力启动。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)