使用Ollama部署大模型
ollama部署大模型,ollama,gte-Qwen2-7B-instruct,
1. Ollama 简介
Ollama 是一个开源工具,专注于在本地计算机上高效运行和部署大型语言模型(LLM)。它简化了模型下载、管理和运行的过程,支持多种主流开源模型(如 Qwen、DeepSeek、Gemma 等),并通过命令行提供直观的交互方式。用户无需复杂的配置即可在本地进行文本生成、代码补全等任务,同时支持自定义模型微调。Ollama 兼顾性能与隐私,适合开发者、研究人员或任何希望离线探索 AI 能力的用户。
特点:
- 一键部署,跨平台(macOS/Linux/Windows)
- 丰富的预训练模型库
- 本地运行,保障数据隐私
- 支持模型量化(降低硬件需求)
网站:ollama.ai
2. 安装Ollama
2.1 在线安装
如果主机能够访问ollama网络,直接执行下面的命令即可完成ollama的安装。
curl -fsSL https://ollama.com/install.sh | sh
2.2 离线安装
如果Linux主机不能访问ollama网络,可以在有网络的电脑上准备好安装包,再上传至服务器,完成离线安装。
- 通过Git命令下载安装脚本
git clone https://github.com/yangkx111/deploy_llm.git
或者直接在浏览器中下载
https://github.com/yangkx111/deploy_llm/archive/refs/heads/main.zip
- 下载ollama安装包,放到deploy_llm下的ollama目录中
https://ollama.com/download/ollama-linux-amd64.tgz
-
如果有必要,可以修改deploy_llm/ollama目录下的deploy_ollama.sh脚本,设置ollama用户的Home目录,因为后续注册到ollama的大模型都会存储到这个目录中,所以改目录需要保证有足够的磁盘空间,所以需要依据服务器实际磁盘空间情况进行修改。

-
如果有必要,可以修改deploy_llm/ollama目录下ollama.service,这是ollama服务的配置文件。可以依据实际情况修改里面相应的配置,比如端口。
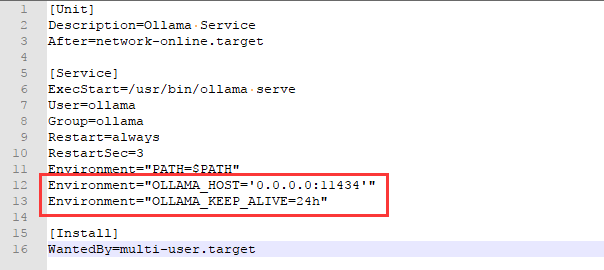
-
将deploy_llm上传至服务器
-
cd到deploy_llm/ollama目录,执行deploy_ollama.sh
./deploy_ollama.sh
2.3 测试Ollama
- 测试ollama状况
# 如果更改了ollma的端口,这里需要做相应的修改
curl localhost:11434; echo

- ollama服务状态
# 查看服务状态
systemctl status ollama
# 启动服务
systemctl start ollama
# 停止服务
systemctl stop ollama
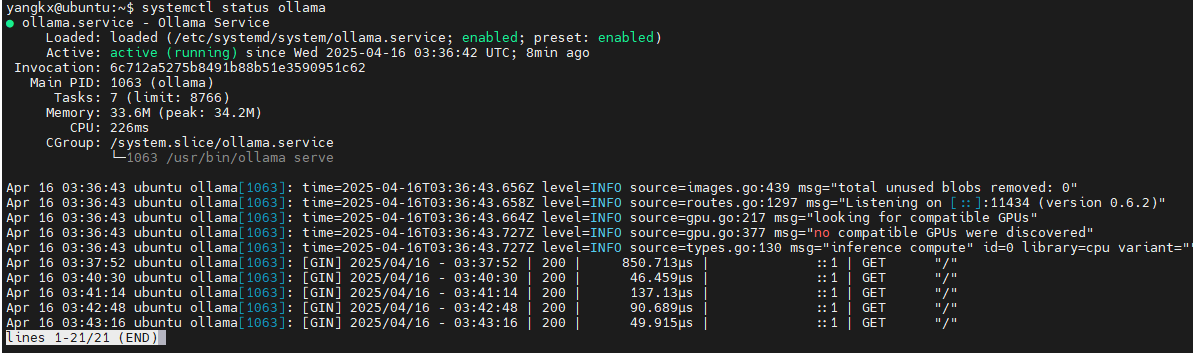
- 查看ollama日志
journalctl -u ollama

- 修改ollama客户端端口配置
ollama服务端口修改之后(默认是11434),ollama ps等命令会报错:
Error: could not connect to ollama app, is it running?
这是因为ollama ps等命令还是尝试使用默认11434端口去链接ollama服务,所以失败。解决办法就是通过环境变量OLLAMA_HOST定义ollama服务的端口:
# 将端口8080修改为你实际部署的端口
echo 'export OLLAMA_HOST="0.0.0.0:8080"' >> ~/.bashrc
source ~/.bashrc
3. 部署大模型
3.1 部署gte-Qwen2-7B-instruct
3.1.1 搜索模型
-
在ollama官网搜索模型,选择量化版本Q8_0,拷贝出运行指令:ollama run since2006/gte-Qwen2-7B-instruct:Q8_0
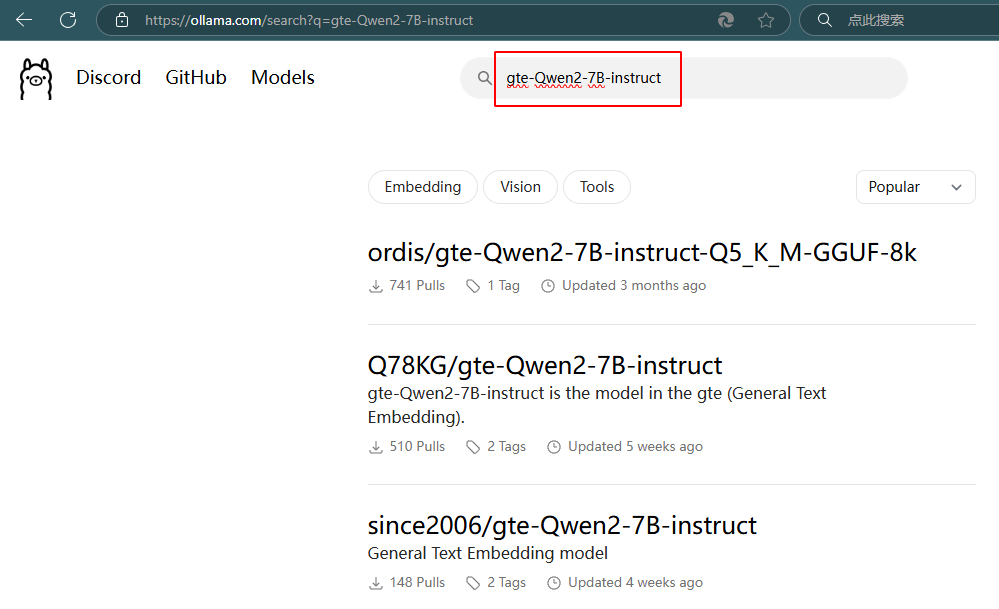
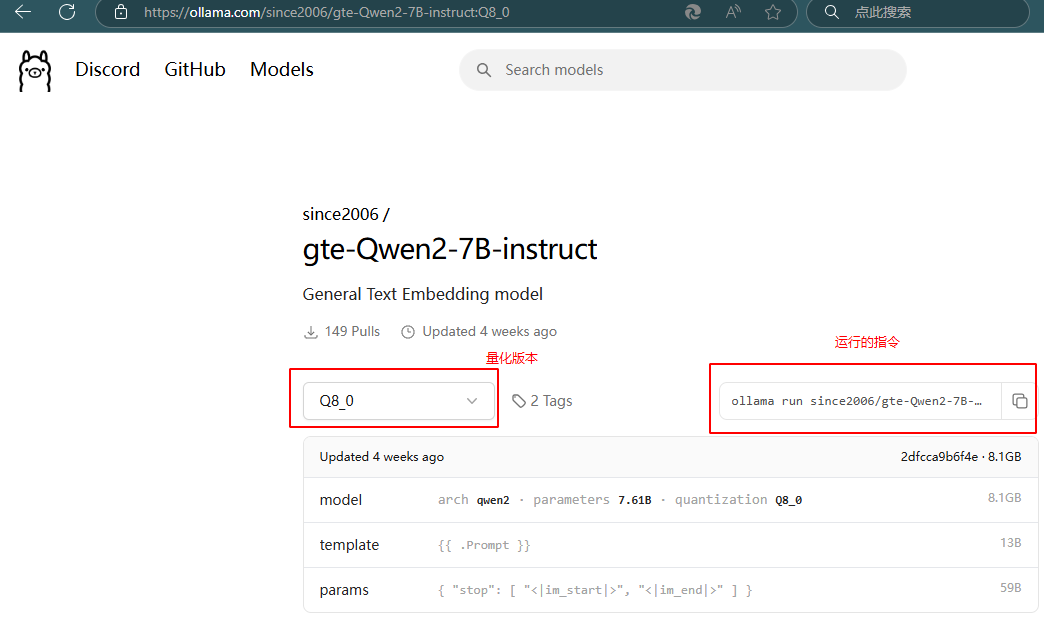
-
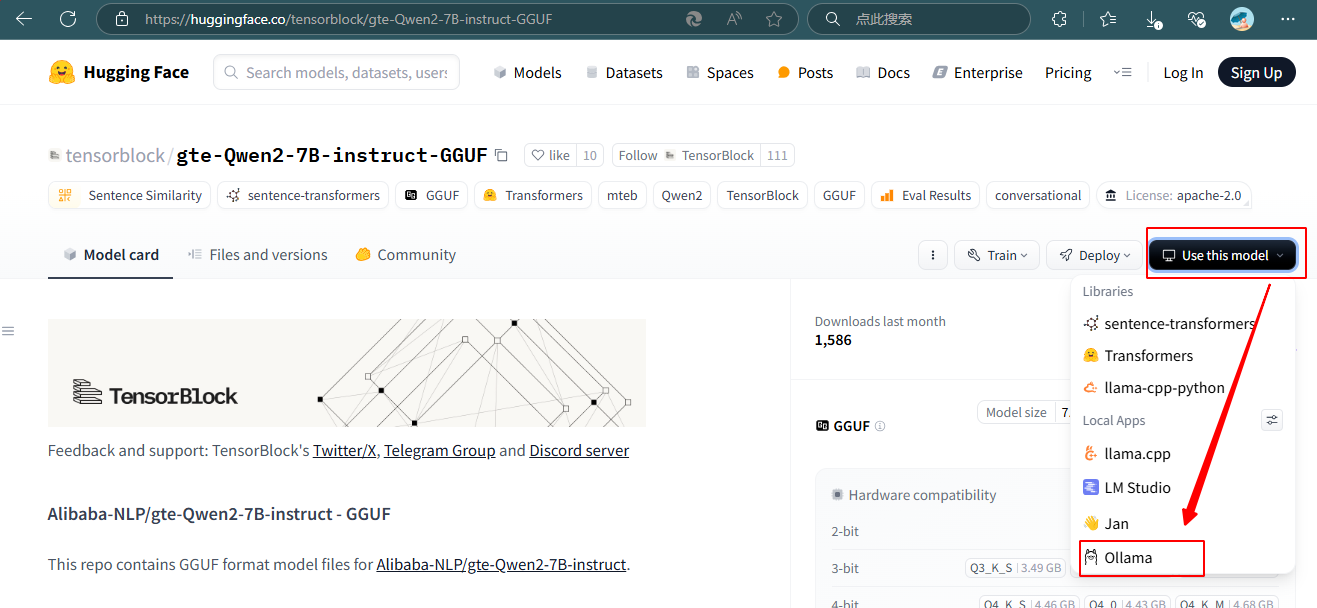
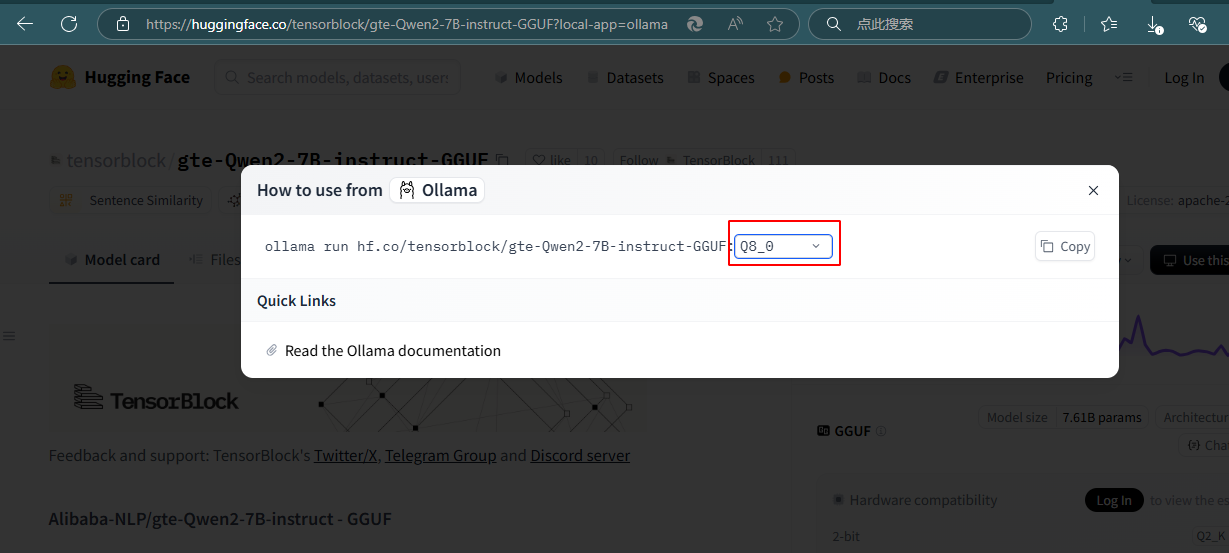
如果在ollma中搜索不到合适的模型,可以在huggingface搜索模型,找到量化版本Q8_0,拷贝出运行指令:ollama run hf.co/tensorblock/gte-Qwen2-7B-instruct-GGUF:Q8_0
3.1.2 在线安装
直接运行上面取到的指令
# from ollama
ollama run since2006/gte-Qwen2-7B-instruct:Q8_0
# from huggingface
ollama run hf.co/tensorblock/gte-Qwen2-7B-instruct-GGUF:Q8_0
3.1.3 离线安装
离线安装需要手动从huggingface下载量化文件,然后注册到ollama中,再运行。
-
从huggingface下载对应版本的gguf文件
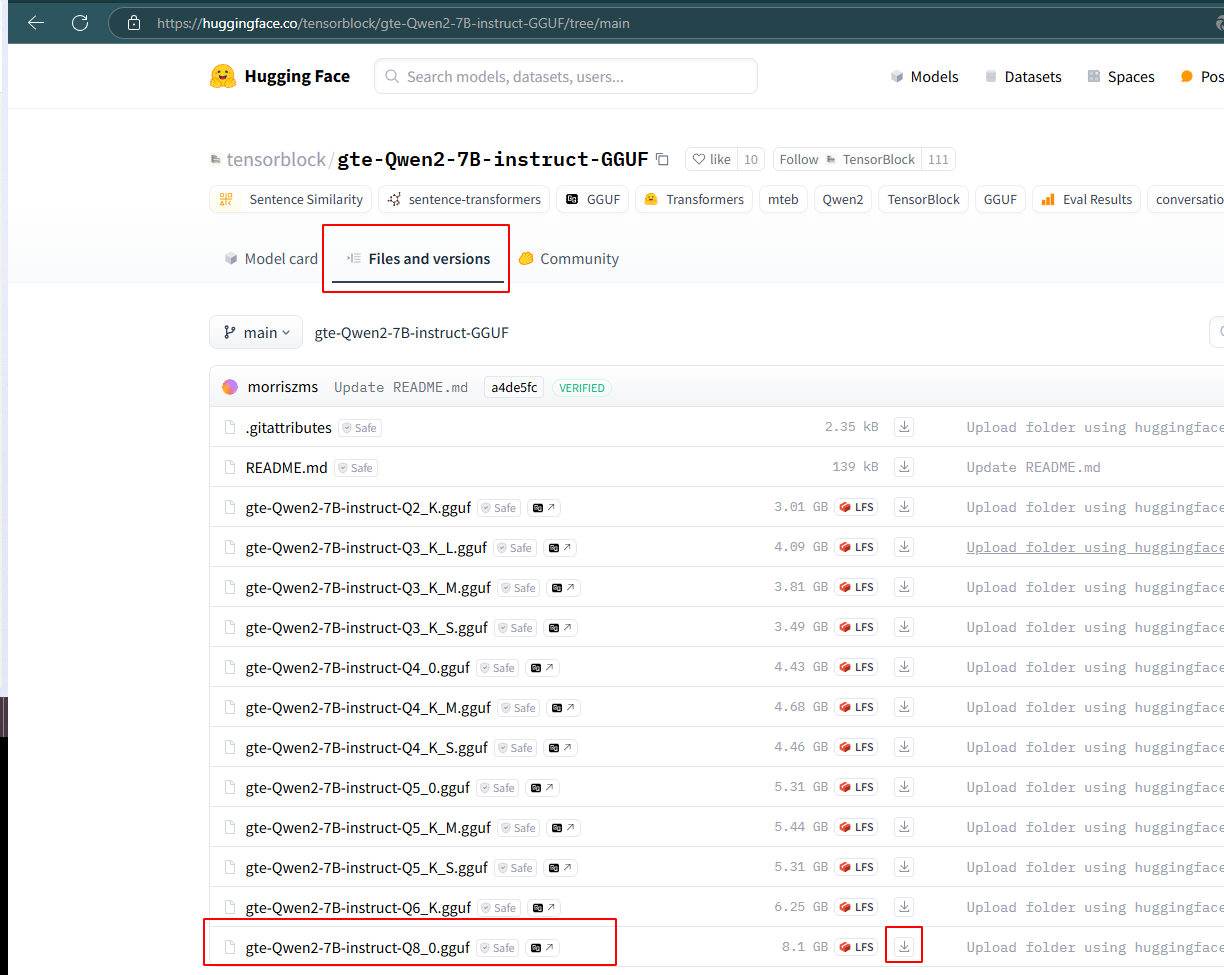
-
编写对应的模型配置文件Modelfile.gte-Qwen2-7B-instruct
FROM ./gte-Qwen2-7B-instruct-Q8_0.gguf
TEMPLATE """{{ .Prompt }}"""
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
- 将下载的模型文件以及配置文件放在同一个目录上传到服务器中
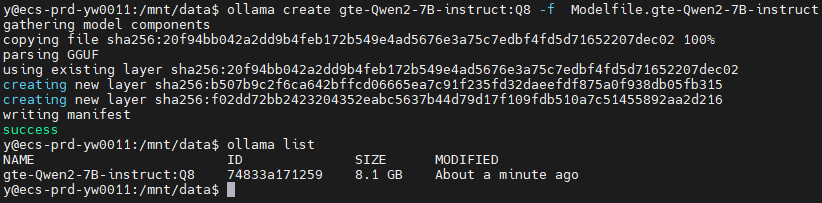
- 注册模型到ollama。在服务器中运行如下命令
ollama create gte-Qwen2-7B-instruct:Q8 -f Modelfile.gte-Qwen2-7B-instruct
3.1.3 测试模型
curl -s 127.0.0.1:11434/api/embeddings \
-X POST \
-d '{"model": "gte-Qwen2-7B-instruct:Q8", "prompt": "hello"}' \
-H 'Content-Type: application/json' | head -c 100 ; echo


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)