无需GPU!三步实现DeepSeek开源模型本地化部署。
deepseek和chatGpt最大的区别就在于,它是开源的模型,并且训练成本更低,这使得我们普通人也能够在自己的电脑部署大语言模型,训练自己的AI智能体。我们需要谨记的就是,AI是工具,是为了提高我们的效率,它能够给我们提供更精确,更具逻辑的回答,你再根据自身的需求进行修改和采用。最近Deepseek访问量剧增,导致App时常访问不了,但是不用担心,官方给我们提供了本地部署大模型的方案。
deepseek和chatGpt最大的区别就在于,它是开源的模型,并且训练成本更低,这使得我们普通人也能够在自己的电脑部署大语言模型,训练自己的AI智能体。我们需要谨记的就是,AI是工具,是为了提高我们的效率,它能够给我们提供更精确,更具逻辑的回答,你再根据自身的需求进行修改和采用。
最近Deepseek访问量剧增,导致App时常访问不了,但是不用担心,官方给我们提供了本地部署大模型的方案。
一、本地部署 vs APP/网页端访问
最近Deepseek访问量剧增,导致App时常访问不了,但是不用担心,官方给我们提供了本地部署大模型的方案。 这里做一下简单的说明,本地部署Deepseek r1大模型和使用App/网页访问的区别。
本地部署:使用个人电脑,部署大模型,需要一定技术背景
-
优点:隐私保护性强,更安全,可以训练专属智能体。
-
缺点:性能差,跟官方的服务器差距很大,成本更高,对电脑显卡有要求。【相当于单机模式,本地运行】
App/网页使用:开箱即用,使用简单跟微信聊天一样,无需技术背景,性能更高,因为官方的服务器后面是成百上千张卡进行
本地部署和通过App访问DeepSeek大模型是两种完全不同的使用方式,在技术实现、资源要求和使用场景上存在显著差异。以下是两者的核心区别对比:
1、 技术架构差异

2、资源与技术门槛

3、 隐私与安全性
-
本地部署
▶️ 数据隐私性高:所有用户数据仅在本地处理,无第三方接触风险
▶️ 合规优势:满足金融/医疗等敏感行业的监管要求 -
App访问
▶️ 潜在数据风险:输入内容需通过服务商服务器(存在日志留存可能)
▶️ 依赖服务商信任:需接受隐私政策条款
4、 功能与灵活性
| 本地部署优势 | App访问限制 |
|---|---|
| ▶️ 支持模型微调(定制行业专属模型) | ▶️ 功能固定(无法修改模型参数) |
| ▶️ 可集成到私有系统(OA/CRM等) | ▶️ 仅限官方提供的交互界面 |
| ▶️ 支持量化/剪枝优化(降低资源消耗) | ▶️ 受限于服务商API调用频次/响应速度 |
5、成本对比
-
本地部署
▶️ 前期成本高:硬件采购/电费支出(如RTX 4090约¥1.5万+月均电费¥300)
▶️ 长期成本低:一次投入后可无限次使用 -
App访问
▶️ 短期成本低:免费版/按需付费(如API调用按token计费)
▶️ 长期成本不可控:大规模使用时费用可能指数级增长
典型应用场景建议
-
选择本地部署
✔️ 处理敏感数据(法律文件/患者病历)
✔️ 需要7×24小时高频调用
✔️ 企业私有化知识库构建 -
选择App访问
✔️ 个人临时性需求(论文润色/日常问答)
✔️ 算力资源有限的开发者测试
✔️ 快速验证模型基础能力
技术趋势补充
当前企业级部署常采用混合架构:核心敏感业务本地部署(如金融风控模型),非敏感需求通过API调用云端服务(如客服聊天),既保障安全又降低成本。对于个人开发者,使用Colab免费GPU+模型量化技术也能低成本实现准本地化部署。
二.如何本地部署DeepSeek大模型。
1、第一步:下载 Ollama服务工具
说明: Ollama 是一个开源的大型语言模型(LLM)服务工具,主要用于在本地机器上便捷地部署和运行大型语言模型。以下是其主要特点和功能:
-
本地模型管理:支持从官方模型库或自定义模型库拉取预训练模型,并在本地保存和加载。
-
高效推理:通过 GPU/CPU 的加速,Ollama 提供高效的模型推理,适合本地化应用或需要控制数据隐私的场景。
-
多种接口访问:支持命令行(CLI)、HTTP 接口访问推理服务,并通过 OpenAI 客户端实现更广泛的集成。
-
环境变量配置:通过灵活的环境变量,用户可以自定义推理设备(GPU/CPU)、缓存路径、并发数、日志级别等。
一句话总结:Ollama是一个能让你用简单的命令在本地电脑上轻松运行DeepSeek,Llama,Mistral等大语言模型的"一键启动器",像安装手机App一样方便地玩转AI大模型。
官方网站:https://ollama.com/
我这里选择的是windows版本,然后进行下载安装。安装的时候直接一键安装就行。
2、第二步:下载对应的大模型DeepSeek-r1
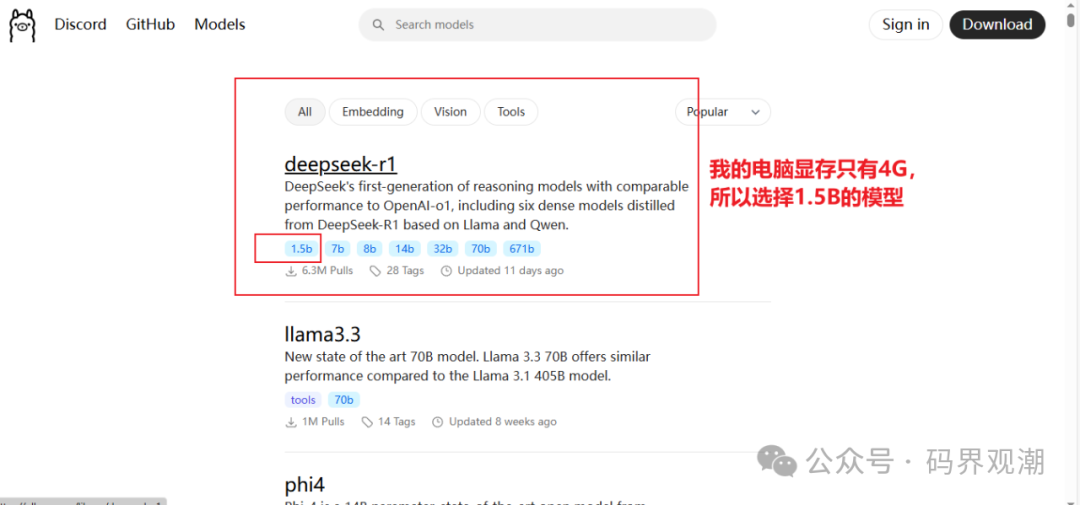
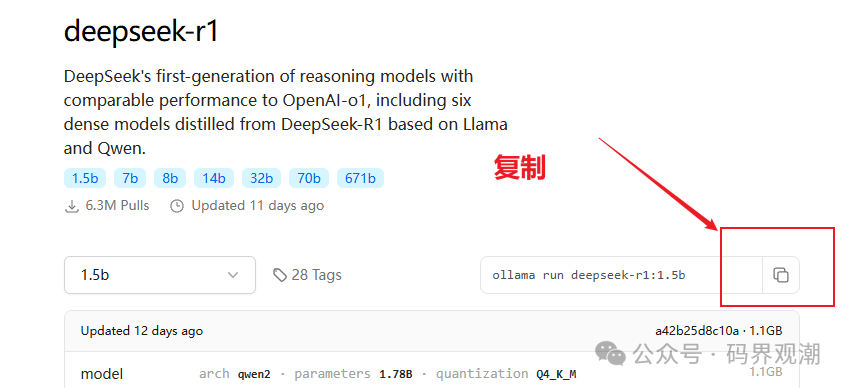
在Ollama网页上点击Models,跳转到大模型页面,选择DeepSeek-r1模型。这里根据你的电脑显存大小进行对应的模型选择。我这里以最小的1.5B模型进行示范。复制下载模型的命令。
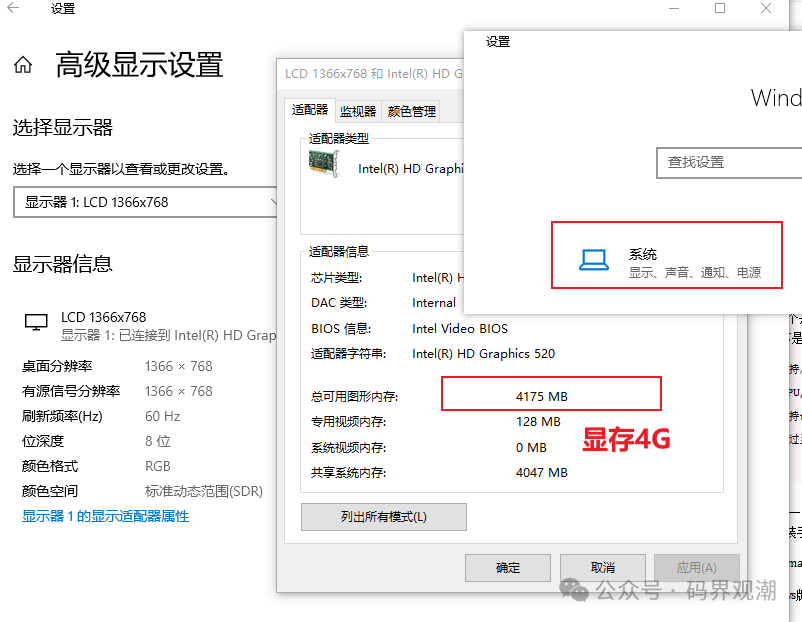
windows查看笔记本显存:
3、第三步:Windows命令行安装deepseek-r1:1.5B模型
windows电脑打开命令行,mac则打开终端。
说明:windows如何打开命令行: Win+R,然后输入cmd.


选择好对应的模型后,在命令行执行以下命令:
ollama run deepseek-r1:1.5b

4、第四步:下载完成后,开始提问。
先问一个数学问题,从1+2+3+…100等于多少?

再问一个语文问题,中国的四大名著是什么?

最后需要注意的是:AI大模型回答的准确性取决于训练数据的质量,模型的参数量级,注意力机制的优化等等。
所以像DeepSeek这样的大语言模型,它仍然是个在学习的"孩子",会犯错,会出现AI幻觉,我们不能指望AI通用模型帮我们一步到位解决问题,它提供的答案还是需要我们人为去校对和修正的,但是它确实能够极大地提高我们的工作效率。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)