python与streamlit构建的外卖评论分析
摘要:本文介绍了一个基于Streamlit的外卖评论分析系统,采用模块化架构设计,包含前端应用和分析引擎两部分。系统支持情感分析、关键词提取和智能摘要生成功能,采用双模型策略(深度学习+规则模型)提高分析准确性。技术栈包括Streamlit、Transformers、jieba等,支持多种数据格式输入和大文件流式处理。系统提供三层可视化展示(概览仪表板、详细分析和原始数据),并包含个性化建议引擎,
·
外卖评论分析
1. 概览
1.1 整体架构
这个系统是一个基于Streamlit的完整数据分析和可视化应用,采用模块化设计,包含两个主要部分:
外卖评论分析系统
├── 前端应用 (app.py)
│ ├── 用户界面层 (Streamlit)
│ ├── 业务逻辑层
│ └── 数据展示层
└── 分析引擎 (评论分析工具模块.py)
├── NLP处理层
├── 机器学习模型层
└── 数据分析层1.2 技术栈
-
前端框架: Streamlit (交互式Web应用)
-
数据处理: Pandas, NumPy
-
可视化: Plotly Express/Graph Objects
-
NLP: Transformers, jieba, Sentence-BERT
-
机器学习: Hugging Face Transformers
2. 前端应用
2.1 状态管理
# 使用session_state进行状态管理
if 'data' not in st.session_state:
st.session_state.data = None
# 这种设计避免页面刷新时数据丢失关键特点:
-
支持页面刷新后数据持久化
-
分离数据处理和展示逻辑
-
支持异步模型加载
2.2 UI/UX设计亮点
2.2.1 渐进式信息展示
# 三层信息架构
1. 概览仪表板 (总体指标)
2. 详细分析 (情感分布、关键词)
3. 原始数据 (可下载结果)2.2.2 响应式布局
# 使用columns创建自适应布局
col1, col2, col3 = st.columns(3) # 三等分布局2.3 数据处理流程
输入 → 预处理 → 分析 → 可视化 → 导出
↓ ↓ ↓ ↓ ↓
文件/文本 → 清洗 → 情感/关键词 → 图表 → CSV3. 分析引擎
3.1 情感分析模块
3.1.1 模型选择策略
# 双模型策略
1. 深度学习模型: uer/roberta-base-finetuned-dianping-chinese
- 优点: 准确性高
- 缺点: 计算资源要求高
2. 规则回退模型
- 优点: 轻量、快速
- 缺点: 准确性有限3.1.2 情感分析算法
def analyze_sentiment(text: str) -> Dict[str, Any]:
# 三层处理逻辑
1. 文本清洗 (remove HTML, URLs, 特殊字符)
2. 深度学习预测 (transformers pipeline)
3. 规则匹配 (positive/negative词汇统计)
4. 标签映射 (LABEL_0 → 消极, LABEL_1 → 积极)置信度计算:
-
深度学习模型: 使用模型输出的概率分数
-
规则模型: 基于情感词比例计算相对分数
3.2 关键词提取模块
3.2.1 多策略提取
# 三层关键词提取
1. jieba.analyse (基于TF-IDF)
2. 词性过滤 (只保留n, vn, v, a)
3. 停用词过滤3.2.2 领域特定优化
# 添加外卖领域词典
food_delivery_words = [
'配送', '骑手', '外卖', '打包', '包装',
'洒漏', '超时', '口感', '分量', '性价比'
]3.3 摘要生成模块
3.3.1 多维度分析
summary_data = {
'sentiment_stats': {}, # 情感统计
'keyword_clusters': {}, # 关键词聚类
'risk_analysis': {}, # 风险检测
'profile_insights': {} # 用户画像洞察
}3.3.2 个性化建议引擎
# 基于用户画像的智能建议
advice_map = {
"健身人士": "关注低卡、高蛋白餐品",
"上班族": "关注配送速度和包装完整性",
"学生党": "关注性价比和分量"
}4. 数据流程优化
4.1 流式处理
# 支持大文件处理
for i, text in enumerate(texts):
analyze_sentiment(text) # 逐条处理
extract_keywords(text) # 实时提取
update_progress(i/len(texts)) # 进度反馈4.2 缓存机制
# 模型缓存避免重复加载
_model_cache = {
'sentiment_model': None,
'keyword_model': None
}5. 可视化
5.1 多层图表架构
# 1. 概览层
metrics_display = [
("总评论数", "📊"),
("积极比例", "😊"),
("消极比例", "😞"),
("风险评论", "⚠️")
]
# 2. 分析层
charts = [
("情感分布饼图", px.pie),
("关键词频率柱状图", px.bar),
("情感-关键词关联图", make_subplots)
]
# 3. 明细层
detailed_data = pd.DataFrame({
'评论内容': [],
'情感': [],
'置信度': [],
'关键词': []
})5.2 交互式功能
# 支持的功能
1. 数据预览 (expandable dataframe)
2. 图表交互 (hover, zoom, download)
3. 结果导出 (CSV format)
4. 示例数据下载6. 错误处理
6.1 多级异常处理
try:
# 1. 模块加载检查
from 评论分析工具模块 import ...
except ImportError:
CUSTOM_MODULE_AVAILABLE = False
# 2. 模型加载回退
if not TRANSFORMERS_AVAILABLE:
use_rule_based_sentiment()
# 3. 文件格式兼容
supported_formats = ['txt', 'csv', 'xlsx', 'xls']6.2 用户友好提示
# 分级提示系统
1. 成功: st.success("✅ 加载成功!")
2. 警告: st.warning("⚠️ 使用简化模式")
3. 错误: st.error("❌ 加载失败")
4. 进度: st.spinner("正在处理...")7. 性能优化
7.1 懒加载模式
# 按需加载模型
if not st.session_state.models_loaded:
load_models() # 首次使用时加载7.2 批量处理优化
# 批量处理策略
1. 短文本: 逐条处理
2. 长文本: 截断到510字符 (模型限制)
3. 大文件: 分块处理 + 进度显示8. 扩展性和可维护性
8.1 模块化设计
# 清晰的接口定义
def load_models(analysis_mode: str) -> dict:
"""加载指定分析模式的模型"""
def analyze_sentiment(text: str) -> Dict[str, Any]:
"""分析单条文本情感"""8.2 配置分离
# 可配置参数集中管理
STOPWORDS = get_stopwords() # 停用词
DOMAIN_WORDS = food_delivery_words # 领域词
MODEL_CONFIGS = { # 模型配置
"快速分析": "uer/roberta-base-...",
"深度分析": "更复杂的模型"
}9. 洞察
9.1 核心洞察输出
1. 用户满意度量化
- 积极/消极比例
- 情感趋势
2. 问题定位
- 高频关键词聚类
- 风险评论识别
3. 改进方向
- 个性化建议
- 优先级排序9.2 目标用户价值
1. 餐饮商家
- 服务质量监控
- 菜品改进依据
2. 平台运营
- 商家评级参考
- 用户画像分析
3. 市场研究
- 竞品分析
- 需求挖掘10. 代码
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import io
import time
import base64
from datetime import datetime
# 导入自定义分析模块
try:
from 评论分析工具模块 import (
load_models, process_uploaded_file, analyze_sentiment,
extract_keywords, generate_summary, calculate_metrics
)
CUSTOM_MODULE_AVAILABLE = True
except ImportError as e:
print(f"警告: 无法导入评论分析工具模块: {e}")
CUSTOM_MODULE_AVAILABLE = False
# 页面配置
st.set_page_config(
page_title="外卖评论分析",
page_icon="🍜",
layout="wide",
initial_sidebar_state="expanded"
)
# 移除了自定义CSS样式,使用Streamlit默认样式
# 初始化session state
if 'data' not in st.session_state:
st.session_state.data = None
if 'analysis_results' not in st.session_state:
st.session_state.analysis_results = None
if 'summary' not in st.session_state:
st.session_state.summary = None
if 'metrics' not in st.session_state:
st.session_state.metrics = None
if 'models_loaded' not in st.session_state:
st.session_state.models_loaded = False
# 加载模型
def load_analysis_models():
"""加载分析模型"""
if not st.session_state.models_loaded and CUSTOM_MODULE_AVAILABLE:
with st.spinner("正在加载分析模块,首次加载可能需要一些时间..."):
try:
load_models("快速分析")
st.session_state.models_loaded = True
st.success("✅ 模型加载成功!")
except Exception as e:
st.error(f"❌ 模型加载失败: {str(e)}")
st.warning("⚠️ 将使用简化模式进行分析,功能可能受限")
# 侧边栏
def render_sidebar():
"""渲染侧边栏"""
st.sidebar.title("🍜 外卖评论分析")
# 关于应用
with st.sidebar.expander("关于应用", expanded=False):
st.info("""
支持多种数据格式:TXT、CSV、Excel
""")
# 分析设置
st.sidebar.subheader("🔧 分析设置")
analysis_mode = st.sidebar.selectbox(
"选择分析模式",
["快速分析", "深度分析"],
index=0,
help="快速分析适合大量数据,深度分析更精确但耗时"
)
# 用户画像选择
st.sidebar.subheader("👥 用户画像")
user_profiles = st.sidebar.multiselect(
"选择目标用户群体",
["健身人士", "宝妈/宝爸", "学生党", "上班族",
"美食爱好者", "价格敏感型"],
default=["上班族"],
help="选择后系统会提供针对性建议"
)
return analysis_mode, user_profiles
# 主页
def render_home(analysis_mode, user_profiles):
"""渲染主页"""
st.title("🍜 外卖评论分析")
st.success("""
**欢迎使用外卖评论分析**<br>
挖掘用户需求,提升服务质量。
""")
# 功能介绍
col1, col2, col3 = st.columns(3)
with col1:
st.info("""
🔍 **情感分析**<br>
自动识别评论中的积极、消极和中性情感,量化用户满意度
""")
with col2:
st.info("""
🔑 **关键词提取**<br>
智能提取评论中的核心关键词,发现用户关注的焦点问题
""")
with col3:
st.info("""
📊 **智能摘要**<br>
生成结构化摘要报告,提供数据洞察和改进建议
""")
# 数据上传区
st.header("📤 数据上传")
# 示例数据下载
def get_example_data():
"""创建示例数据"""
example_data = [
"配送速度超快,食物还很热,包装也很好,满分!",
"等了快两个小时才送到,电话也打不通,体验很差",
"味道不错,但是分量有点少,性价比一般",
"吃出异物了,太恶心了,不会再点了",
"商家服务态度很好,包装很用心,会回购",
"菜品口感很好,就是有点咸,希望可以改进",
"第一次点这家,味道很惊艳,会推荐给朋友",
"配送员态度很好,但包装有点漏汤,需要改进",
"价格有点贵,但食材很新鲜,物有所值",
"辣度刚刚好,很下饭,会继续支持"
]
return "\n".join(example_data)
# 提供示例数据下载
example_data = get_example_data()
b64 = base64.b64encode(example_data.encode()).decode()
href = f'<a href="data:file/txt;base64,{b64}" download="示例评论数据.txt">下载示例数据</a>'
st.markdown(f"没有数据?{href}试试我们的示例数据", unsafe_allow_html=True)
# 文件上传
uploaded_file = st.file_uploader(
"上传评论数据文件",
type=['txt', 'csv', 'xlsx', 'xls'],
help="支持TXT(每行一条评论)、CSV和Excel格式"
)
# 文本输入框
st.subheader("📝 或直接输入评论")
text_input = st.text_area(
"每行输入一条评论",
placeholder="配送很快,食物也很热!\n味道不错,分量有点少...",
height=150
)
# 分析按钮
if st.button("🚀 开始分析", type="primary"):
if not CUSTOM_MODULE_AVAILABLE:
st.error("❌ 分析模块未加载,请检查依赖是否正确安装")
return
# 确保模型已加载
load_analysis_models()
# 处理上传的文件
if uploaded_file is not None:
with st.spinner(f"正在处理文件 {uploaded_file.name}..."):
try:
data, file_type = process_uploaded_file(uploaded_file)
if data is not None:
if file_type == 'txt':
# 文本文件,每行一条评论
texts = data
elif isinstance(data, pd.DataFrame):
# CSV或Excel文件
if '评论' in data.columns:
texts = data['评论'].dropna().astype(str).tolist()
elif 'comment' in data.columns:
texts = data['comment'].dropna().astype(str).tolist()
else:
# 假设第一列是评论
texts = data.iloc[:, 0].dropna().astype(str).tolist()
else:
st.error("❌ 无法识别的数据格式")
return
st.session_state.data = texts
st.success(f"✅ 成功加载 {len(texts)} 条评论!")
# 显示前几条评论预览
with st.expander("📋 评论数据预览", expanded=True):
preview_df = pd.DataFrame({'评论': texts[:10]})
st.dataframe(preview_df)
else:
st.error("❌ 文件处理失败")
return
except Exception as e:
st.error(f"❌ 处理文件时出错: {str(e)}")
return
# 处理直接输入的文本
elif text_input.strip():
texts = [line.strip() for line in text_input.split('\n') if line.strip()]
st.session_state.data = texts
st.success(f"✅ 成功加载 {len(texts)} 条评论!")
else:
st.warning("⚠️ 请上传文件或输入评论内容")
return
# 如果有数据,进行分析
if st.session_state.data and len(st.session_state.data) > 0:
analyze_reviews(st.session_state.data, analysis_mode, user_profiles)
# 分析评论
def analyze_reviews(texts, analysis_mode, user_profiles):
"""分析评论数据"""
with st.spinner("🤖 正在分析评论,请稍候..."):
analysis_results = []
# 批量处理评论
for i, text in enumerate(texts):
try:
# 情感分析
sentiment = analyze_sentiment(text)
# 关键词提取
keywords = extract_keywords(text)
# 保存结果
analysis_results.append({
'index': i+1,
'text': text,
'sentiment': sentiment,
'keywords': keywords
})
# 更新进度条
progress = (i + 1) / len(texts)
st.progress(progress, text=f"分析进度: {i+1}/{len(texts)}")
except Exception as e:
st.error(f"处理第 {i+1} 条评论时出错: {str(e)}")
continue
# 生成摘要
summary = generate_summary(analysis_results, user_profiles)
# 计算指标
metrics = calculate_metrics(analysis_results)
# 保存到session state
st.session_state.analysis_results = analysis_results
st.session_state.summary = summary
st.session_state.metrics = metrics
st.success(f"✅ 分析完成!共处理 {len(analysis_results)} 条评论")
# 显示分析结果
def show_results():
"""显示分析结果"""
if not st.session_state.analysis_results:
st.warning("⚠️ 暂无分析结果,请先上传数据进行分析")
return
st.header("📊 分析结果")
# 直接显示所有内容,不使用标签页
# 1. 总体概览
st.markdown("---")
show_overview()
# 2. 情感分析
st.markdown("---")
show_sentiment_analysis()
# 3. 关键词分析
st.markdown("---")
show_keyword_analysis()
# 4. 详细数据
st.markdown("---")
show_detailed_data()
# 显示总体概览
def show_overview():
"""显示总体概览"""
summary = st.session_state.summary
metrics = st.session_state.metrics
# 关键指标
col1, col2, col3, col4 = st.columns(4)
with col1:
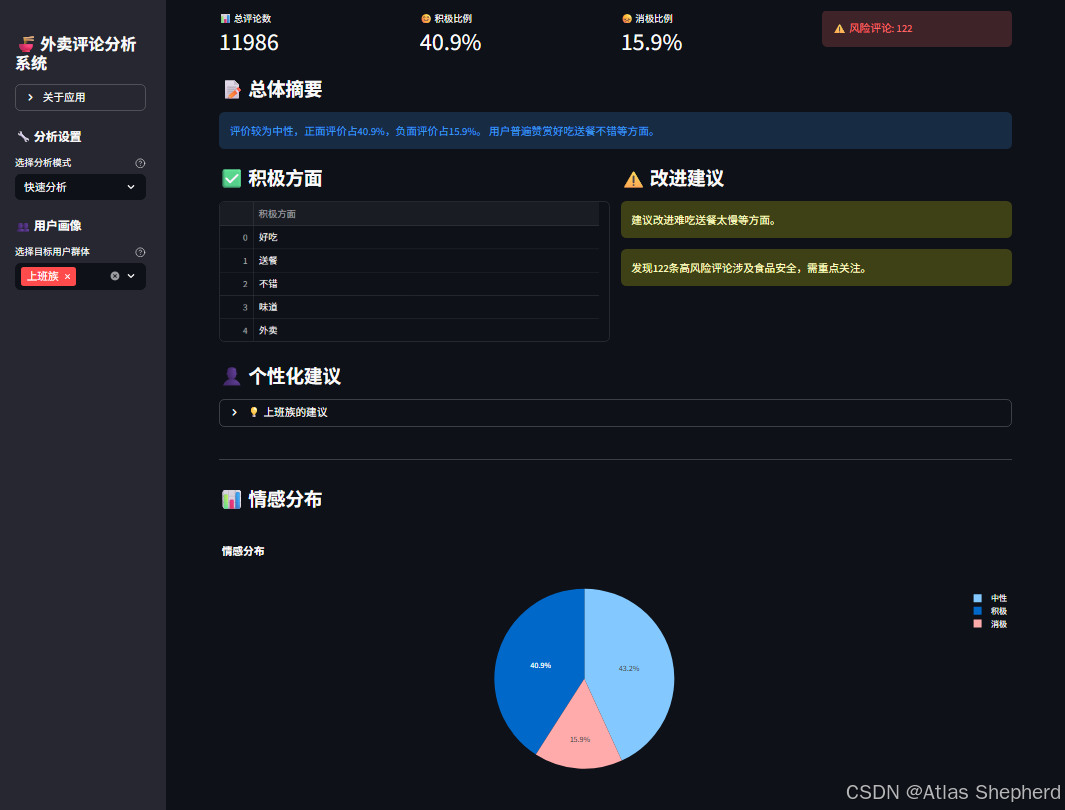
st.metric("📊 总评论数", metrics['total_reviews'])
with col2:
st.metric("😊 积极比例", f"{metrics['positive_ratio']:.1f}%")
with col3:
st.metric("😞 消极比例", f"{metrics['negative_ratio']:.1f}%")
with col4:
risk_count = metrics['risk_count']
if risk_count > 0:
st.error(f"⚠️ 风险评论: {risk_count}")
else:
st.success(f"⚠️ 风险评论: {risk_count}")
# 总体摘要
st.subheader("📝 总体摘要")
st.info(summary['overall_summary'])
# 积极与消极方面
col1, col2 = st.columns(2)
with col1:
st.subheader("✅ 积极方面")
if summary['positive_aspects']:
positive_df = pd.DataFrame({'积极方面': summary['positive_aspects'][:10]})
st.dataframe(positive_df, use_container_width=True)
else:
st.info("暂无显著积极方面")
with col2:
st.subheader("⚠️ 改进建议")
if summary['suggestions']:
for suggestion in summary['suggestions']:
st.warning(suggestion)
else:
st.info("暂无明显改进建议")
# 个性化建议
if summary['personalized_advice']:
st.subheader("👤 个性化建议")
for profile, advice in summary['personalized_advice'].items():
with st.expander(f"💡 {profile}的建议", expanded=False):
st.info(advice)
# 显示情感分析
def show_sentiment_analysis():
"""显示情感分析结果"""
metrics = st.session_state.metrics
# 情感分布饼图
st.subheader("📊 情感分布")
sentiment_dist = metrics['sentiment_distribution']
fig = px.pie(
values=list(sentiment_dist.values()),
names=list(sentiment_dist.keys()),
title="情感分布",
color_discrete_map={
'积极': '#28a745',
'消极': '#dc3545',
'中性': '#ffc107'
}
)
st.plotly_chart(fig, use_container_width=True)
# 显示各情感下的典型评论
st.subheader("💬 典型评论")
tab1, tab2, tab3 = st.tabs(["😊 积极评论", "😞 消极评论", "😐 中性评论"])
positive_reviews = [r for r in st.session_state.analysis_results
if r['sentiment']['label'] == '积极']
negative_reviews = [r for r in st.session_state.analysis_results
if r['sentiment']['label'] == '消极']
neutral_reviews = [r for r in st.session_state.analysis_results
if r['sentiment']['label'] == '中性']
with tab1:
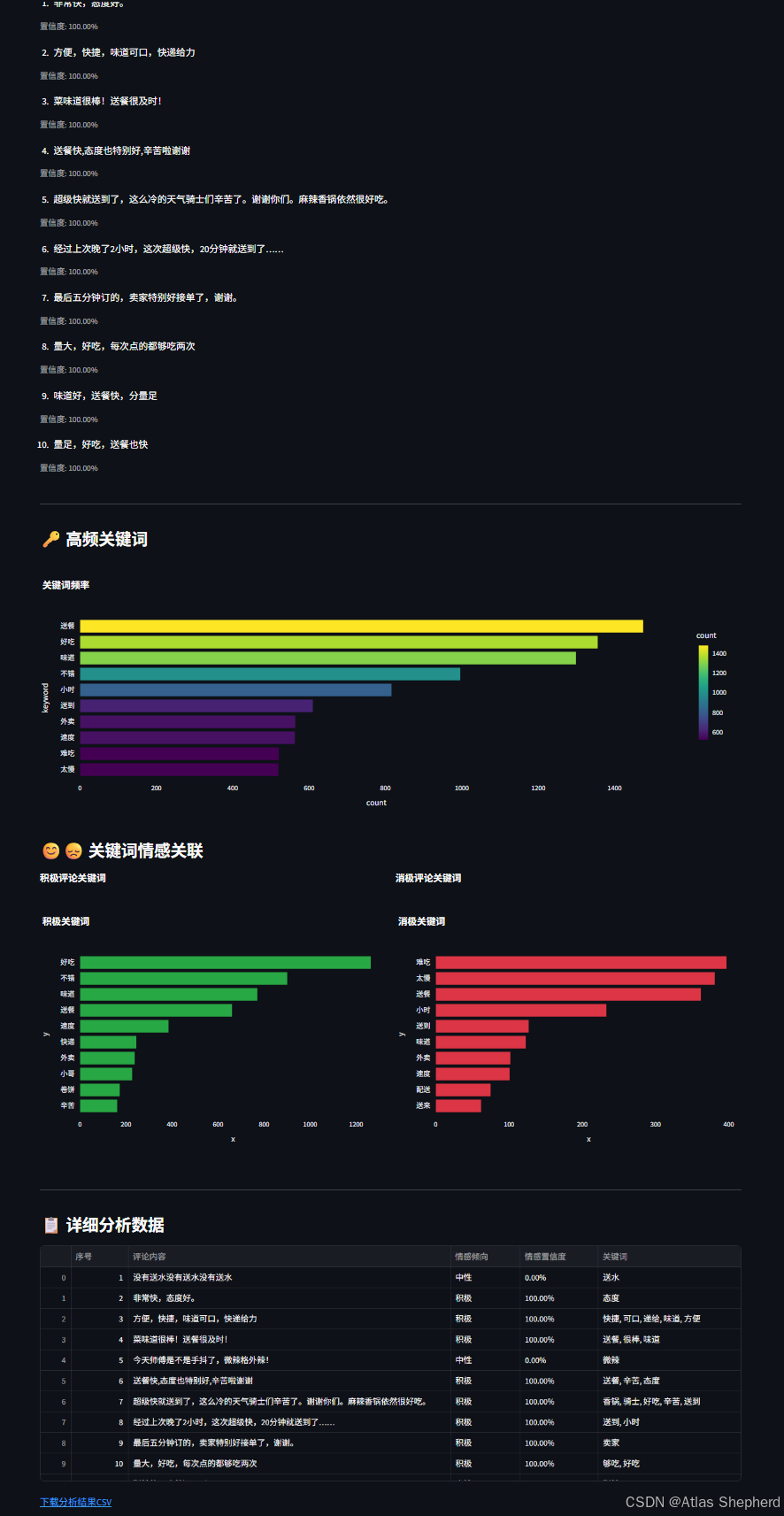
if positive_reviews:
# 按置信度排序
positive_reviews.sort(key=lambda x: x['sentiment']['confidence'], reverse=True)
for i, review in enumerate(positive_reviews[:10]):
st.write(f"{i+1}. {review['text']}")
st.caption(f"置信度: {review['sentiment']['confidence']:.2%}")
else:
st.info("暂无积极评论")
with tab2:
if negative_reviews:
# 按置信度排序
negative_reviews.sort(key=lambda x: x['sentiment']['confidence'], reverse=True)
for i, review in enumerate(negative_reviews[:10]):
st.write(f"{i+1}. {review['text']}")
st.caption(f"置信度: {review['sentiment']['confidence']:.2%}")
else:
st.info("暂无消极评论")
with tab3:
if neutral_reviews:
# 按置信度排序
neutral_reviews.sort(key=lambda x: x['sentiment']['confidence'], reverse=True)
for i, review in enumerate(neutral_reviews[:10]):
st.write(f"{i+1}. {review['text']}")
st.caption(f"置信度: {review['sentiment']['confidence']:.2%}")
else:
st.info("暂无中性评论")
# 显示关键词分析
def show_keyword_analysis():
"""显示关键词分析结果"""
metrics = st.session_state.metrics
# 关键词频率条形图
top_keywords = metrics['top_keywords']
st.subheader("🔑 高频关键词")
if top_keywords:
keywords_df = pd.DataFrame(top_keywords[:20])
fig = px.bar(
keywords_df,
x='count',
y='keyword',
orientation='h',
title="关键词频率",
color='count',
color_continuous_scale='viridis'
)
fig.update_layout(yaxis={'categoryorder': 'total ascending'})
st.plotly_chart(fig, use_container_width=True)
else:
st.info("暂无关键词数据")
# 关键词与情感关联分析
st.subheader("😊😞 关键词情感关联")
# 分析不同情感下的关键词
positive_keywords = []
negative_keywords = []
for result in st.session_state.analysis_results:
if result['sentiment']['label'] == '积极':
positive_keywords.extend(result['keywords'])
elif result['sentiment']['label'] == '消极':
negative_keywords.extend(result['keywords'])
positive_freq = pd.Series(positive_keywords).value_counts().head(10)
negative_freq = pd.Series(negative_keywords).value_counts().head(10)
col1, col2 = st.columns(2)
with col1:
st.write("**积极评论关键词**")
if not positive_freq.empty:
fig = px.bar(
x=positive_freq.values,
y=positive_freq.index,
orientation='h',
title="积极关键词",
color_discrete_sequence=['#28a745']
)
fig.update_layout(yaxis={'categoryorder': 'total ascending'})
st.plotly_chart(fig, use_container_width=True)
else:
st.info("暂无积极关键词")
with col2:
st.write("**消极评论关键词**")
if not negative_freq.empty:
fig = px.bar(
x=negative_freq.values,
y=negative_freq.index,
orientation='h',
title="消极关键词",
color_discrete_sequence=['#dc3545']
)
fig.update_layout(yaxis={'categoryorder': 'total ascending'})
st.plotly_chart(fig, use_container_width=True)
else:
st.info("暂无消极关键词")
# 显示详细数据
def show_detailed_data():
"""显示详细数据表格"""
if not st.session_state.analysis_results:
return
st.subheader("📋 详细分析数据")
# 准备数据
detailed_data = []
for result in st.session_state.analysis_results:
detailed_data.append({
'序号': result['index'],
'评论内容': result['text'],
'情感倾向': result['sentiment']['label'],
'情感置信度': f"{result['sentiment']['confidence']:.2%}",
'关键词': ', '.join(result['keywords'])
})
df = pd.DataFrame(detailed_data)
# 显示数据表格
st.dataframe(df, use_container_width=True)
# 下载结果
csv = df.to_csv(index=False, encoding='utf-8-sig')
b64 = base64.b64encode(csv.encode()).decode()
href = f'<a href="data:file/csv;base64,{b64}" download="评论分析结果.csv">下载分析结果CSV</a>'
st.markdown(href, unsafe_allow_html=True)
# 主函数
def main():
"""主函数"""
# 渲染侧边栏
analysis_mode, user_profiles = render_sidebar()
# 主内容区
if st.session_state.analysis_results is None:
render_home(analysis_mode, user_profiles)
else:
# 显示导航
st.markdown("---")
col1, col2, col3 = st.columns([1, 2, 1])
with col2:
if st.button("🔙 返回首页", use_container_width=True):
# 重置session state
st.session_state.data = None
st.session_state.analysis_results = None
st.session_state.summary = None
st.session_state.metrics = None
st.rerun()
# 显示结果
show_results()
# 运行应用
if __name__ == "__main__":
main()import pandas as pd
import numpy as np
from typing import List, Dict, Any, Tuple, Optional
import re
from collections import Counter
import jieba
import jieba.analyse
import hashlib
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
# 尝试导入可选依赖
try:
import torch
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
TRANSFORMERS_AVAILABLE = True
except ImportError:
TRANSFORMERS_AVAILABLE = False
print("警告: transformers库未安装,部分功能将受限")
try:
from sentence_transformers import SentenceTransformer
SENTENCE_TRANSFORMERS_AVAILABLE = True
except ImportError:
SENTENCE_TRANSFORMERS_AVAILABLE = False
print("警告: sentence-transformers库未安装,部分功能将受限")
# 缓存字典
_model_cache = {}
def load_models(analysis_mode: str = "快速分析"):
"""
加载AI模型到缓存中
Args:
analysis_mode: 分析模式,"快速分析"或"深度分析"
"""
if 'sentiment_model' in _model_cache and 'keyword_model' in _model_cache:
return _model_cache
print(f"正在加载{analysis_mode}模型...")
# 情感分析模型
if TRANSFORMERS_AVAILABLE:
try:
if analysis_mode == "快速分析":
# 使用轻量级模型
sentiment_model = pipeline(
"sentiment-analysis",
model="uer/roberta-base-finetuned-dianping-chinese",
device=-1 # CPU
)
else:
# 使用更精确的模型
sentiment_model = pipeline(
"sentiment-analysis",
model="uer/roberta-base-finetuned-dianping-chinese", # 使用相同的模型以确保兼容性
device=-1
)
_model_cache['sentiment_model'] = sentiment_model
print("情感分析模型加载完成")
except Exception as e:
print(f"情感分析模型加载失败: {e}")
_model_cache['sentiment_model'] = None
else:
_model_cache['sentiment_model'] = None
# 关键词提取模型
if SENTENCE_TRANSFORMERS_AVAILABLE:
try:
# 使用较小的模型以减少内存使用
keyword_model = SentenceTransformer('all-MiniLM-L6-v2')
_model_cache['keyword_model'] = keyword_model
print("关键词模型加载完成")
except Exception as e:
print(f"关键词模型加载失败: {e}")
_model_cache['keyword_model'] = None
else:
_model_cache['keyword_model'] = None
# 加载jieba分词词典
jieba.initialize()
# 添加外卖领域自定义词典
food_delivery_words = [
'配送', '骑手', '外卖', '打包', '包装', '洒漏', '超时',
'口感', '分量', '性价比', '辣度', '咸淡', '新鲜度',
'客服', '退款', '售后', '优惠券', '满减'
]
for word in food_delivery_words:
jieba.add_word(word)
return _model_cache
def process_uploaded_file(uploaded_file) -> Tuple[Optional[Any], str]:
"""
处理上传的文件,返回数据和处理类型
Args:
uploaded_file: Streamlit上传的文件对象
Returns:
Tuple[数据, 文件类型]
"""
file_type = uploaded_file.name.split('.')[-1].lower()
try:
if file_type == 'txt':
# 读取文本文件,每行一条评论
content = uploaded_file.getvalue().decode('utf-8')
texts = [line.strip() for line in content.split('\n') if line.strip()]
return texts, 'txt'
elif file_type == 'csv':
# 读取CSV文件
df = pd.read_csv(uploaded_file)
return df, 'csv'
elif file_type in ['xlsx', 'xls']:
# 读取Excel文件
df = pd.read_excel(uploaded_file)
return df, 'excel'
else:
print(f"不支持的文件类型: {file_type}")
return None, file_type
except Exception as e:
print(f"文件处理失败: {e}")
return None, file_type
def analyze_sentiment(text: str) -> Dict[str, Any]:
"""
分析文本情感
Args:
text: 评论文本
Returns:
情感分析结果字典
"""
if not text or not isinstance(text, str) or len(text.strip()) == 0:
return {'label': '中性', 'score': 0.5, 'confidence': 0.5}
# 清理文本
text = clean_text(text)
# 如果模型未加载,使用规则匹配
if 'sentiment_model' not in _model_cache or _model_cache['sentiment_model'] is None:
return rule_based_sentiment(text)
try:
# 使用模型分析情感
result = _model_cache['sentiment_model'](text[:510]) # 截断到模型最大长度
if isinstance(result, list):
result = result[0]
# 映射标签
label_map = {
'LABEL_0': '消极',
'LABEL_1': '积极',
'negative': '消极',
'positive': '积极',
'NEGATIVE': '消极',
'POSITIVE': '积极'
}
label = result.get('label', '中性')
score = result.get('score', 0.5)
# 转换标签
for key, value in label_map.items():
if key in str(label).upper():
label = value
break
# 如果模型返回的是0/1,转换为中文标签
if label in ['0', 0]:
label = '消极'
elif label in ['1', 1]:
label = '积极'
return {
'label': label,
'score': float(score),
'confidence': float(score)
}
except Exception as e:
print(f"情感分析失败: {e}")
return rule_based_sentiment(text)
def rule_based_sentiment(text: str) -> Dict[str, Any]:
"""
基于规则的情感分析(备用方案)
Args:
text: 评论文本
Returns:
情感分析结果
"""
# 定义积极和消极词汇
positive_words = ['好', '不错', '满意', '喜欢', '棒', '赞', '快', '热情', '新鲜', '好吃', '美味', '划算']
negative_words = ['差', '不好', '不满意', '讨厌', '慢', '冷淡', '不新鲜', '难吃', '贵', '贵', '贵']
# 检查文本中的情感词
text_lower = text.lower()
positive_count = sum(1 for word in positive_words if word in text_lower)
negative_count = sum(1 for word in negative_words if word in text_lower)
# 计算情感分数
total_words = positive_count + negative_count
if total_words > 0:
score = positive_count / total_words
else:
score = 0.5
# 确定标签
if score > 0.6:
label = '积极'
elif score < 0.4:
label = '消极'
else:
label = '中性'
return {
'label': label,
'score': score,
'confidence': min(abs(score - 0.5) * 2, 1.0) # 置信度基于距离0.5的偏移
}
def extract_keywords(text: str, top_k: int = 5) -> List[str]:
"""
提取文本关键词
Args:
text: 评论文本
top_k: 返回关键词数量
Returns:
关键词列表
"""
if not text or not isinstance(text, str):
return []
text = clean_text(text)
try:
# 使用jieba提取关键词
keywords = jieba.analyse.extract_tags(
text,
topK=top_k,
withWeight=False,
allowPOS=('n', 'vn', 'v', 'a') # 名词、动名词、动词、形容词
)
# 过滤停用词
stopwords = get_stopwords()
keywords = [kw for kw in keywords if kw not in stopwords and len(kw) > 1]
return keywords[:top_k]
except Exception as e:
print(f"关键词提取失败: {e}")
# 回退到简单方法:按词频提取
words = jieba.lcut(text)
words = [w for w in words if len(w) > 1 and w not in get_stopwords()]
word_freq = Counter(words)
return [word for word, _ in word_freq.most_common(top_k)]
def generate_summary(analysis_results: List[Dict], user_profile: List[str]) -> Dict[str, Any]:
"""
生成评论摘要
Args:
analysis_results: 分析结果列表
user_profile: 用户画像列表
Returns:
摘要字典
"""
if not analysis_results:
return {
'overall_summary': '暂无评论数据',
'positive_aspects': [],
'negative_aspects': [],
'suggestions': [],
'personalized_advice': {}
}
# 统计基本信息
total_reviews = len(analysis_results)
sentiments = [r['sentiment']['label'] for r in analysis_results]
positive_count = sentiments.count('积极')
negative_count = sentiments.count('消极')
neutral_count = sentiments.count('中性')
positive_ratio = positive_count / total_reviews * 100
negative_ratio = negative_count / total_reviews * 100
# 提取所有关键词
all_keywords = []
for result in analysis_results:
all_keywords.extend(result.get('keywords', []))
keyword_freq = Counter(all_keywords)
top_keywords = keyword_freq.most_common(10)
# 提取评论文本
texts = [r['text'] for r in analysis_results]
# 分析积极方面
positive_texts = [r['text'] for r in analysis_results if r['sentiment']['label'] == '积极']
positive_keywords = extract_keywords_from_texts(positive_texts, top_k=5)
# 分析消极方面
negative_texts = [r['text'] for r in analysis_results if r['sentiment']['label'] == '消极']
negative_keywords = extract_keywords_from_texts(negative_texts, top_k=5)
# 检测风险评论
risk_keywords = ['头发', '虫子', '异物', '苍蝇', '蟑螂', '拉肚子', '腹泻', '变质', '发霉']
risk_comments = []
for result in analysis_results:
text = result['text']
if any(risk_word in text for risk_word in risk_keywords):
risk_comments.append(text[:50] + '...')
# 生成摘要
summary_parts = []
# 总体评价
if positive_ratio >= 70:
overall = f"总体评价非常积极,{positive_ratio:.1f}%的用户给出正面评价。"
elif positive_ratio >= 50:
overall = f"总体评价较为积极,{positive_ratio:.1f}%的用户给出正面评价。"
elif negative_ratio >= 50:
overall = f"需要关注负面评价,{negative_ratio:.1f}%的用户给出负面评价。"
else:
overall = f"评价较为中性,正面评价占{positive_ratio:.1f}%,负面评价占{negative_ratio:.1f}%。"
summary_parts.append(overall)
# 积极方面
if positive_keywords:
summary_parts.append(f"用户普遍赞赏{''.join(positive_keywords[:3])}等方面。")
# 改进建议
suggestions = []
if negative_keywords:
suggestions.append(f"建议改进{''.join(negative_keywords[:3])}等方面。")
if risk_comments:
suggestions.append(f"发现{len(risk_comments)}条高风险评论涉及食品安全,需重点关注。")
# 个性化建议
personalized_advice = {}
for profile in user_profile:
if profile == "健身人士":
advice = "建议关注低卡、高蛋白餐品的评价,注意用户对食材新鲜度的反馈。"
elif profile == "宝妈/宝爸":
advice = "建议关注儿童餐的评价,注意食品安全和营养均衡的反馈。"
elif profile == "学生党":
advice = "建议关注性价比和分量的评价,学生群体对价格敏感度高。"
elif profile == "上班族":
advice = "建议关注配送速度和包装完整性的评价,上班族对时间要求高。"
elif profile == "美食爱好者":
advice = "建议关注口味和食材质量的评价,美食爱好者对味道要求严格。"
elif profile == "价格敏感型":
advice = "建议关注性价比和优惠活动的评价,价格是主要决策因素。"
else:
advice = "建议综合多方面评价做出选择。"
personalized_advice[profile] = advice
return {
'overall_summary': ' '.join(summary_parts),
'positive_aspects': positive_keywords,
'negative_aspects': negative_keywords,
'suggestions': suggestions,
'personalized_advice': personalized_advice,
'statistics': {
'total_reviews': total_reviews,
'positive_ratio': positive_ratio,
'negative_ratio': negative_ratio,
'risk_count': len(risk_comments),
'top_keywords': [kw for kw, _ in top_keywords[:5]]
}
}
def extract_keywords_from_texts(texts: List[str], top_k: int = 5) -> List[str]:
"""
从文本列表中提取关键词
Args:
texts: 文本列表
top_k: 返回关键词数量
Returns:
关键词列表
"""
all_text = ' '.join(texts)
return extract_keywords(all_text, top_k)
def clean_text(text: str) -> str:
"""
清理文本,移除特殊字符和多余空格
Args:
text: 原始文本
Returns:
清理后的文本
"""
if not isinstance(text, str):
return ""
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除URL
text = re.sub(r'http[s]?://\S+', '', text)
# 移除特殊字符,保留中文、英文、数字和常用标点
text = re.sub(r'[^\w\u4e00-\u9fff\s.,!?;:,。!?;:、]', '', text)
# 移除多余空白字符
text = re.sub(r'\s+', ' ', text).strip()
return text
def get_stopwords() -> set:
"""
获取中文停用词表
Returns:
停用词集合
"""
# 基础停用词
stopwords = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要',
'去', '你', '会', '着', '没有', '看', '好', '自己', '这', '但', '我们', '谁', '什么', '看', '吃', '点', '个',
'啊', '哦', '嗯', '呀', '嘛', '呃', '吧', '啦', '吗', '么', '呢', '哇', '喂', '嘿', '唉', '哈', '哼', '嗯',
'这', '那', '哪', '这个', '那个', '这些', '那些', '这样', '那样', '这里', '那里', '这么', '那么', '怎样',
'为', '为了', '因为', '所以', '但是', '而且', '如果', '虽然', '然后', '或者', '还是', '虽然', '即使',
'很', '非常', '太', '真', '真的', '确实', '实在', '特别', '极其', '相当', '比较', '稍微', '有点',
'已经', '曾经', '正在', '将要', '马上', '立刻', '刚刚', '刚才', '以前', '以后', '现在', '今天', '明天',
'昨天', '前天', '后天', '上午', '下午', '晚上', '中午', '早晨', '傍晚', '深夜',
'可以', '可能', '能够', '会', '要', '想', '愿意', '应该', '必须', '得', '肯', '敢',
'我', '你', '他', '她', '它', '我们', '你们', '他们', '她们', '它们', '自己', '大家', '别人', '人家',
'这', '那', '哪', '这个', '那个', '这些', '那些', '这样', '那样', '这里', '那里', '这么', '那么', '怎样',
'谁', '什么', '哪', '怎么', '为什么', '多少', '几', '何', '怎', '岂', '难道', '莫非', '究竟', '到底',
'啊', '呀', '呢', '吧', '吗', '啦', '哇', '嘛', '噢', '哦', '嗯', '哼', '唉', '咳', '呸', '嘿', '喂',
'的', '地', '得', '了', '着', '过', '啊', '呀', '呢', '吧', '吗', '啦', '哇', '嘛', '噢', '哦', '嗯',
'和', '与', '跟', '同', '及', '以及', '或', '或者', '还是', '并且', '而且', '甚至', '不仅', '不但',
'虽然', '但是', '然而', '可是', '不过', '而', '却', '如果', '假如', '要是', '只要', '只有', '除非',
'因为', '所以', '因此', '因而', '于是', '然后', '接着', '之后', '之前', '当', '每当', '在', '于',
'从', '自', '自从', '由', '往', '向', '到', '在', '于', '以', '与', '和', '跟', '同', '及', '以及',
'对', '对于', '关于', '至于', '至于', '至于', '至于', '至于', '至于'
}
return stopwords
def calculate_metrics(analysis_results: List[Dict]) -> Dict[str, Any]:
"""
计算分析指标
Args:
analysis_results: 分析结果列表
Returns:
指标字典
"""
if not analysis_results:
return {}
total = len(analysis_results)
# 情感统计
sentiment_labels = [r['sentiment']['label'] for r in analysis_results]
sentiment_counts = {
'积极': sentiment_labels.count('积极'),
'消极': sentiment_labels.count('消极'),
'中性': sentiment_labels.count('中性')
}
# 平均情感分数(积极评论)
positive_scores = [r['sentiment']['score'] for r in analysis_results
if r['sentiment']['label'] == '积极']
avg_positive_score = np.mean(positive_scores) if positive_scores else 0
# 关键词统计
all_keywords = []
for result in analysis_results:
all_keywords.extend(result.get('keywords', []))
keyword_freq = Counter(all_keywords)
top_keywords = keyword_freq.most_common(10)
# 风险检测
risk_keywords = ['头发', '虫子', '异物', '苍蝇', '蟑螂', '拉肚子', '腹泻', '变质', '发霉']
risk_count = 0
for result in analysis_results:
text = result['text']
if any(risk_word in text for risk_word in risk_keywords):
risk_count += 1
return {
'total_reviews': total,
'sentiment_distribution': sentiment_counts,
'positive_ratio': sentiment_counts['积极'] / total * 100,
'negative_ratio': sentiment_counts['消极'] / total * 100,
'avg_positive_score': float(avg_positive_score),
'top_keywords': [{'keyword': kw, 'count': count} for kw, count in top_keywords],
'risk_count': risk_count,
'risk_ratio': risk_count / total * 100 if total > 0 else 0
}
# 测试函数
def test_analyzer():
"""测试分析器功能"""
print("正在测试评论分析器...")
# 测试数据
test_reviews = [
"配送很快,食物也很热,包装完好无损!",
"等了快一个小时才送到,饭菜都凉了",
"味道不错,就是分量有点少,性价比一般",
"吃出头发,太恶心了,再也不会点了",
"商家态度很好,包装很用心,还会再点"
]
# 加载模型
load_models("快速分析")
# 测试情感分析
print("\n=== 情感分析测试 ===")
for review in test_reviews:
sentiment = analyze_sentiment(review)
print(f"评论: {review[:30]}...")
print(f"情感: {sentiment['label']}, 置信度: {sentiment['score']:.2%}")
# 测试关键词提取
print("\n=== 关键词提取测试 ===")
for review in test_reviews[:3]:
keywords = extract_keywords(review)
print(f"评论: {review[:30]}...")
print(f"关键词: {keywords}")
# 测试摘要生成
print("\n=== 摘要生成测试 ===")
results = []
for review in test_reviews:
results.append({
'text': review,
'sentiment': analyze_sentiment(review),
'keywords': extract_keywords(review)
})
summary = generate_summary(results, ["上班族"])
print(f"总体摘要: {summary['overall_summary']}")
print(f"积极方面: {summary['positive_aspects'][:3]}")
print(f"改进建议: {summary['suggestions'][:3]}")
# 测试指标计算
print("\n=== 指标计算测试 ===")
metrics = calculate_metrics(results)
print(f"总评论数: {metrics['total_reviews']}")
print(f"积极比例: {metrics['positive_ratio']:.1f}%")
print(f"风险评论数: {metrics['risk_count']}")
print("\n✅ 测试完成!")
if __name__ == "__main__":
# 运行测试
test_analyzer()

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)