音乐生成模型介绍:指标、Suno、Mureka
概述、指标、Suno、Udio、Mureka、MusiCoT、Hailuo、YuE、架构、DiffRhythm、InspireMusic、SongGeneration、实战、参考、
概述
玩AI一年,听过Suno等平台很多次,但一直没有简单梳理、了解、使用、实战过。
本文梳理一下常见的商业/闭源创作平台、开源歌曲生成大模型。
| 模型名称 | 发布方/机构 | 开源状态 | 核心特点/简介 |
|---|---|---|---|
| ACE-Step(音跃) | 阶跃星辰&ACEStudio | 开源 | 支持19种语言,快速生成(15-32秒),可控性强 |
| DiffRhythm(谛韵) | 西北工业大学&香港中文大学 | 开源 | 全Diffusion架构,极快(10秒生成4分45秒歌曲),显存要求低 |
| SongGeneration | 腾讯AILab | 开源 | 专注提升音质、音乐性与生成速度平衡,支持多维度人类偏好对齐 |
| InspireMusic | 阿里巴巴/FunAudioLLM | 开源 | 结合超分辨率和LLM,可生成长达8分钟的高保真音乐 |
| Mureka(V7) | 昆仑万维 | 闭源 | 采用MusiCoT思维链技术,注重音乐整体结构规划,商业平台 |
指标
音乐生成大模型的评测是一个超级复杂的多维度问题,大致可以划分为以下几类:
flowchart TD
A[音乐生成大模型评测体系]-->B1[感知与主观评测]
A --> B2[客观与技术指标]
A --> B3[音乐学与专业指标]
A --> B4[应用与实用指标]
B1 --> C1[全局音乐性<br>(Musicality/Coherence)]
B1 --> C2[艺术表现力<br>(Expressiveness/Artistry)]
B1 --> C3[情感传达<br>(Emotional Impact)]
B1 --> C4[人声自然度<br>(Vocal Naturalness)]
B2 --> C5[音频质量<br>(信噪比/过零率等)]
B2 --> C6[声学特征<br>(频谱/梅尔谱等)]
B2 --> C7[结构特征<br>(节奏/音高稳定性)]
B2 --> C8[生成效率<br>(内存占用/FLOPs)]
B3 --> C9[和声与调性<br>(和弦进行/调性稳定性)]
B3 --> C10[节奏与节拍<br>(节奏复杂性/节拍精度)]
B3 --> C11[旋律分析<br>(音程分布/轮廓)]
B3 --> C12[结构模仿度<br>(与目标风格的相似度)]
B4 --> C13[任务完成度<br>(对提示词的遵循度)]
B4 --> C14[创作可控性<br>(参数/风格/情感调节)]
B4 --> C15[系统可用性<br>(接口易用性/延迟)]
B4 --> C16[公平与偏见<br>(风格/文化代表性)]
CSDN自带的markdown编辑器渲染有问题,附图
对各类别下的具体指标进行详细说明:
- 感知与主观评测(Perceptual & Subjective Metrics)
主要通过人工评分(如Mean Opinion Score,MOS)来衡量人类的主观听感:
- 全局音乐性/连贯性(Overall Musicality/Coherence):评估整体是否像一首“完整好听”的音乐,各段落是否连贯;
- 艺术表现力/创意(Artistic Expressiveness/Creativity):评估生成内容是否具有艺术感、新颖性和创意,而非机械重复;
- 情感传达(Emotional Impact):音乐能否成功传达或引发预期的情感(如欢快、悲伤、紧张);
- 人声自然度与表现力(Vocal Naturalness & Expressiveness):对于带人声的模型,评估音色、颤音、气息等是否接近真人演唱,情感表达是否到位。
- 客观与技术指标(Objective & Technical Metrics)
通过算法计算,具有可重复性:
- 音频质量(Audio Quality):
- 信噪比(Signal-to-Noise Ratio,SNR) / 过零率(Zero-Crossing Rate):衡量音频底噪和纯净度;
- 频谱分析(Spectral Analysis):如频谱质心(Spectral Centroid)、频谱衰减(Spectral Roll-off),分析音色亮度和能量分布。
- 声学特征分布(Acoustic Feature Distribution):比较生成音频与真实音频在梅尔频谱(Mel-spectrogram)、梅尔倒谱系数(MFCCs)等特征上的分布差异,常用Frèchet Audio Distance(FAD)和Inception Score(IS)来衡量。
- 音乐结构的客观测量(Objective Measures of Structure):
- 节奏/速度一致性(Tempo Consistency):整首曲子速度是否稳定;
- 音高稳定性(Pitch Stability):音高是否准确、无异常抖动。
- 生成效率(Generation Efficiency):
- 内存占用(Memory Footprint):推理时占用的显存;
- 浮点运算量(FLOPs):生成所需计算量。
- 音乐学与专业指标(Musicological & Professional Metrics)
从音乐理论角度进行专业分析,常借助专门工具(如librosa、music21)或专家评审。
- 和声与调性(Harmony & Tonality):
- 和弦进行的合理性(Chord Progression Rationality):和弦连接是否合乎逻辑。
- 调性清晰度与稳定性(Tonal Clarity & Stability):是否有明确的调性中心,是否频繁出现不协和、跑调的音符。
- 节奏与节拍(Rhythm & Beat):
- 节奏模式的多样性/复杂性(Rhythmic Pattern Diversity/Complexity)。
- 节拍对齐精度(Beat Alignment Accuracy):生成的强拍是否与标准节拍点对齐。
- 旋律分析(Melodic Analysis):
- 音程分布(Interval Distribution):旋律中音程(如大二度、纯五度)的使用是否符合常见规律。
- 旋律轮廓(Melodic Contour):旋律线的起伏是否自然、有表现力。
- 结构模仿度(Structural Fidelity):当给定特定风格(如“12小节蓝调”、“AABA爵士结构”)时,模型生成的作品在结构上与该风格的符合程度。
- 应用与实用指标(Application & Practical Metrics)
评估模型在实际应用场景中的能力。
- 任务完成度/遵循度(Task Fulfillment/Adherence):对于条件生成(如根据文本、旋律片段生成),评估输出与输入条件的匹配程度(如文本-音乐相关性得分)。
- 可控性与交互性(Controllability & Interactivity):
- 支持多大程度的细粒度控制(如分轨控制、情绪、乐器、段落过渡)。
- 是否支持交互式编辑(如“让这里更激昂”)。
- 系统与可用性(System & Usability):
- API延迟与吞吐量(API Latency & Throughput):对于商业应用至关重要。
- 易用性(Ease of Use):提示词是否易于理解,是否需要专业音乐知识。
- 公平性与偏见(Fairness & Bias):模型在不同音乐文化(如西方、印度、中国传统音乐)、风格和语言上的生成能力是否均衡,是否存在固有偏见。
在实际应用中,通常采用多种指标的组合:
- 学术研究:侧重于FAD、IS、KL散度等客观指标,并结合MOS主观评分;
- 产品开发:更关注生成速度、可控性、任务完成度和用户满意度;
- 音乐专业性评测:会深入使用和声、节奏分析等专业指标,甚至邀请音乐家进行盲听评审。
主观人工评测:
- 旋律(MEL):评估旋律的动听程度、情感表达能力以及音乐线条感,是否与整体风格或预期相一致;
- 伴奏(HAM):伴奏的色彩丰富度、配器的多样性与协调性,以及与主旋律之间的融合程度;
- 结构(SSC):乐句起止与过渡是否自然清晰、段落结构的可识别性、相似段落的合理重复,以及节奏的稳定性;
- 音质(AQ):音频是否饱满、清晰,是否存在杂音或底噪,同时考察人声与各类乐器的辨识度及其音色还原程度;
- 歌词准确度(LYC):歌词与演唱内容的匹配度,包括是否存在多字、少字、歌词错配等问题,以及音乐段落中是否出现不自然的重复或机械循环;
- 整体表现(OVL):综合感知旋律、伴奏、音乐结构、音质表现与歌词准确度等多个要素后,对音乐作品产生的总体喜爱程度。
其他指标:
- 时长:能否生成3分钟以上音乐
- CE:内容欣赏度,涉及音频的情感冲击力、艺术技巧、艺术表现力以及听众体验等方面;
- CU:内容实用性,评估该音频作为内容创作素材的可用性或使用可能性;
- PQ:制作质量,侧重于音频的技术质量,而非主观感受。评估要素包括清晰度与保真度、动态范围、频率分布以及空间化表现等;
- PC:制作复杂度,关注音频场景的复杂性,通常通过音频成分的数量来衡量;
- Vocal Range:音域表现力
- KL:
- CLaMP3:
Suno
官网,
官网提供类似ChatGPT的交互窗口,左下角按钮用于上传音频文件(支持录音),右下角有个骰子用于随机生成Prompt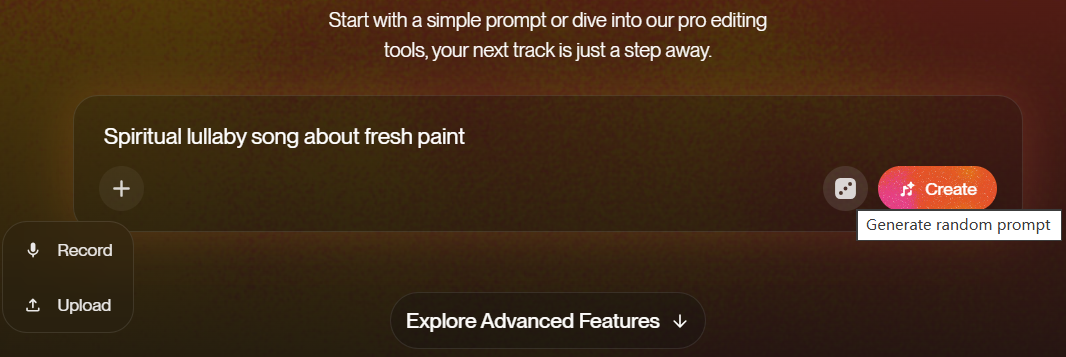
登录成功后,界面如下: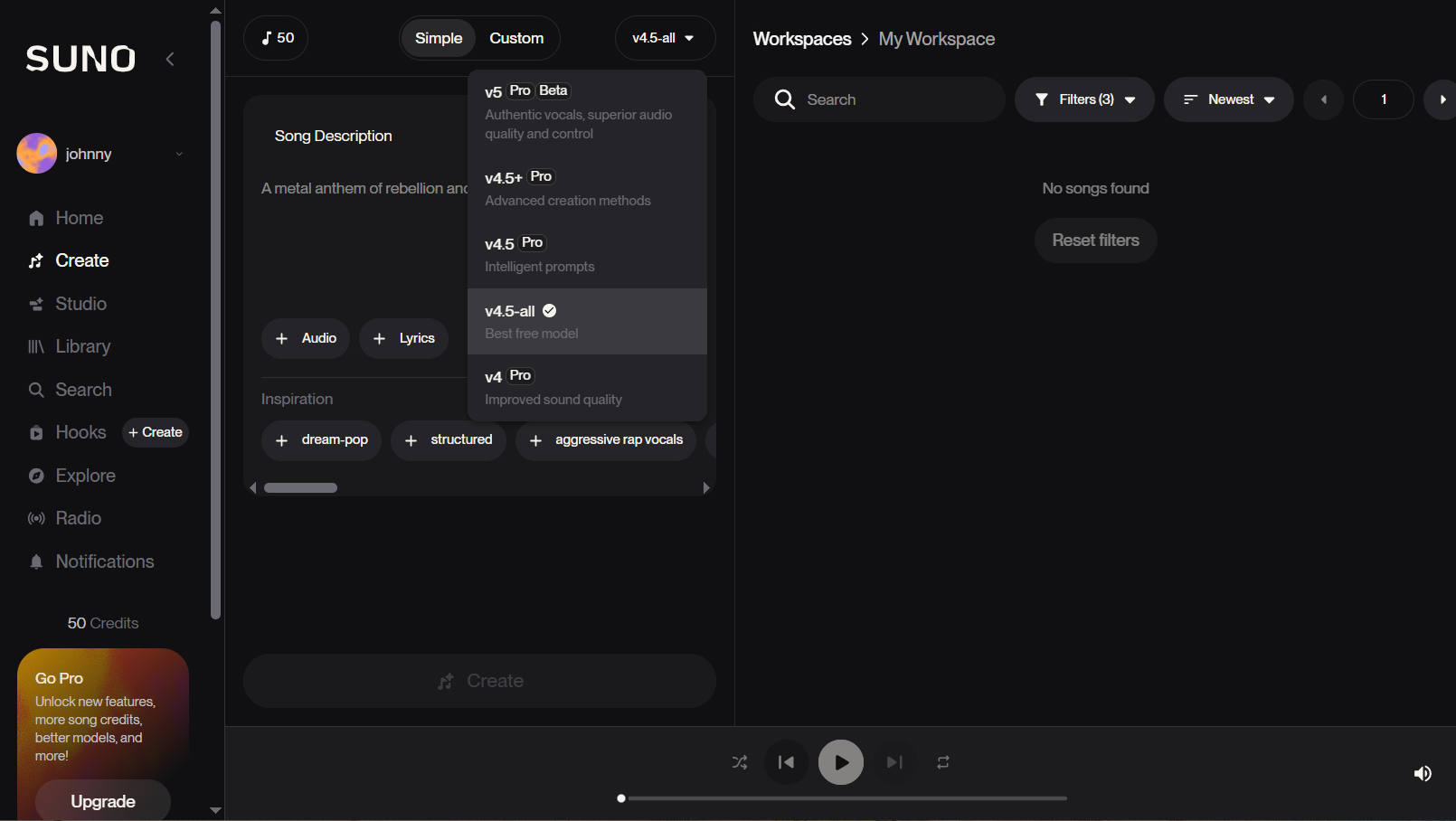
简单解读:
- 有简单(Simple)和自定义(Custom)两种使用模式,后者需要有一定熟练度;
- 除Audio上传音频外,Lyrics按钮用于上传歌词;
- 有个Instrumental开关选项;
- Inspiration包括:feeling of running等等;
- 提供5种模型,包括v4、v4.5-all、v4.5 Pro、v4.5+ Pro、v5 Pro(Beta),标记为Pro的需付费升级账号才能使用;
- 免费账户有50点;
左侧菜单栏,其中工作室(Studio)需要升级为Pro账户才能使用,其他菜单提供更多玩法,库(library)包含各种概念: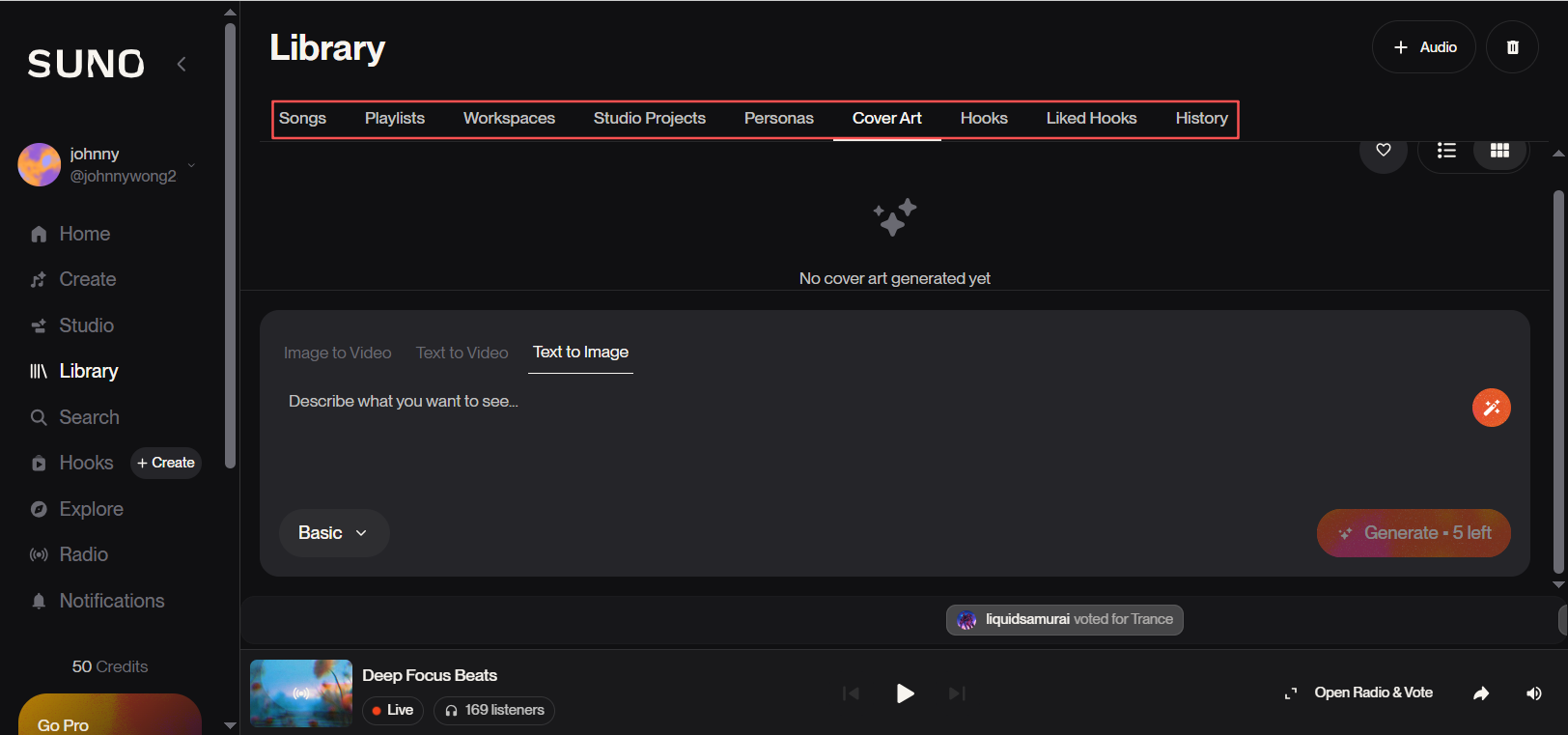
Udio
官网,
Mureka
国际官网,中文站点,Mureka是Music+Eureka的组合,昆仑万维推出对标Suno的AI音乐商用创作平台,基于自研SkyMusic 2.0音乐大模型,该模型采用DiT架构并实现特定风格歌曲的持续稳定生成。
官方MV里,音乐由Mureka生成,视频由SkyReels技术支持生成
特点:
- 全球化:支持亚美欧10种语言的音乐生成;
- 审美在线:界面清爽,功能简洁,有一种时尚的舒适感;
- 兼顾小白与专业用户:提供简单和高级模式,基础与进阶兼顾;
- 二次编辑:音轨分离下载,人声、伴奏多轨输出,支持分段修改,非常方便二次创作。
评测:
- 听感评测,Mureka O1超过Suno V4。其中乐器演奏法多样性和配器设计方面明显超越Suno V4,在音质、人声质感及BGM质感上有显著提升;
- 客观评测,Mureka O1在WhisperX、All-In-One Music、CLAP、Meta Audiobox Aesthetics等主流系统上表现卓越。在发音清晰度、生成歌曲的唱词准确率、乐段的精准度、与输入文本的相关性和制作质量上处于行业领先地位。
歌曲创作界面和Suno几乎完全一模一样,不熟悉英文的可使用中文站点: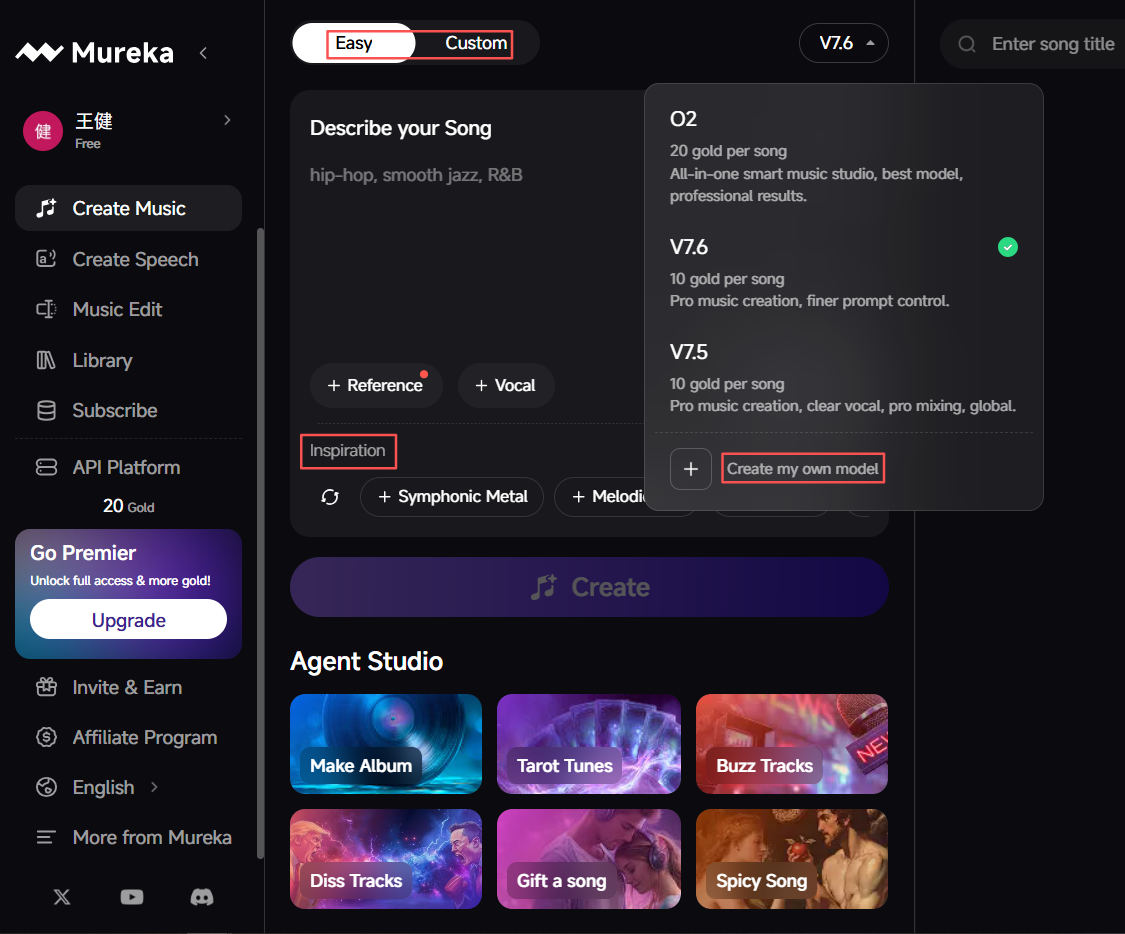
点击参考(Reference),可引用他人创作好的30秒时长音频文件,支持选择想要的Genre和Mood: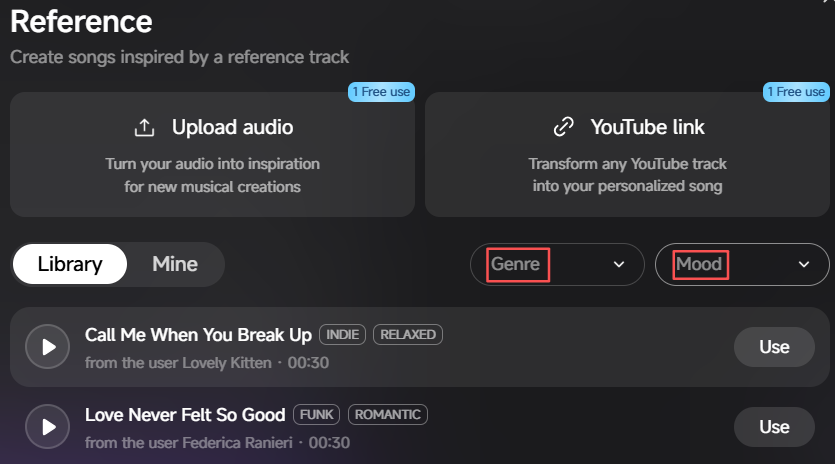
点击口音(Vocal),可选择: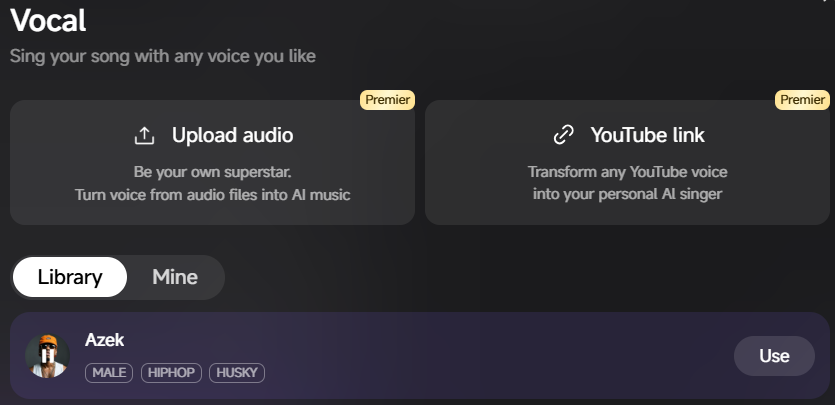
系列模型:
- Mureka V6基座模型:引入自研ICL技术,使得声场更加开阔,人声质感和混音设计进一步强化。相比5.5版本,歌曲品质进一步增强;适用于日常的音乐创作。全球首个开放API服务和模型微调的音乐模型。API平台
- Mureka O1:基于Mureka V6的推理优化版,在音乐生成过程中加入CoT,大幅提升音乐品质。更擅长专业级的音乐制作,能克隆人声,每个人都能用自己的声音创作歌曲。
MusiCoT
利用CoT思维链方法,不同于传统自回归模型逐步生成音频,MusiCoT首次在细粒度音频token预测前预生成整体音乐结构,大幅提升生成音乐的结构连贯性与乐器编排精准度。MusiCoT为高保真AI音乐生成开辟全新路径,推动音乐AI创作迈入结构化时代。
Hailuo
亮点在于左下角的设置,比较适合新手小白:
YuE
论文,港科大团队的研究成果YuE,首个开源(GitHub,5.8K Star,679 Fork)的歌词到歌曲生成大模型,最长能生成5分钟的完整音乐。不同于学术界常见的30秒片段,YuE能在保持歌词对齐和旋律连贯的同时,展现多样化的音乐风格与声线表现力,在部分维度上追平甚至超越Suno、Udio等商业系统。体验地址。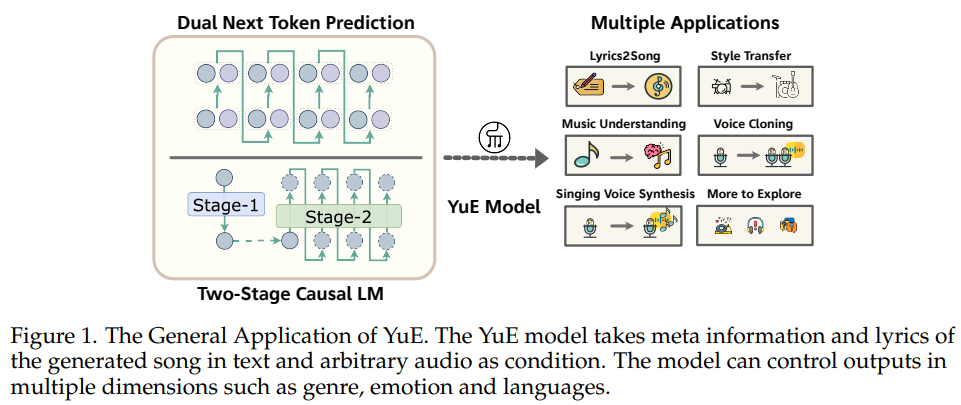
音乐生成是AI在艺术与技术交汇处的重要前沿问题,尤其是歌词到完整歌曲(Lyrics-to-Song)生成,当前现状:
- 传统研究大多停留在短音频片段(<30秒),难以生成完整歌曲。
- 商业产品已有不错效果,但闭源限制复现与科研创新。
- 学术界缺少开放可扩展的长音频生成模型,且面临多重挑战:
- 长时依赖(分钟级音乐结构)
- 多声部信号复杂度(人声+伴奏)
- 歌词与旋律对齐困难
- 高质量配对数据稀缺
架构
基于LLaMA2架构,核心创新点包括:
- Track-Decoupled Next-Token Prediction:Dual-NTP,将每个时间步拆分为人声Token与伴奏Token,减少混合信号干扰,提升歌词清晰度。
- Structural Progressive Conditioning:CoT思想,借鉴歌曲天然分段(前奏、主歌、副歌等),逐段建模,避免长上下文衰减问题。
- Music In-Context Learning:上下文学习重设计,支持风格迁移(如将日式City Pop转为英文Rap),并能在参考音频基础上做双向创作。
- 两阶段生成框架
- Stage-1:负责语义级别建模(歌词与旋律对齐)
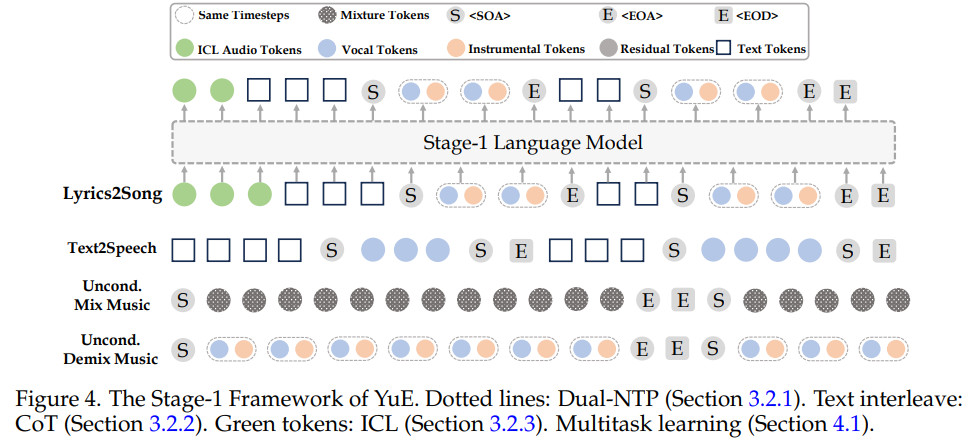
- Stage-2:负责残差细节建模,提升音质与表现力。
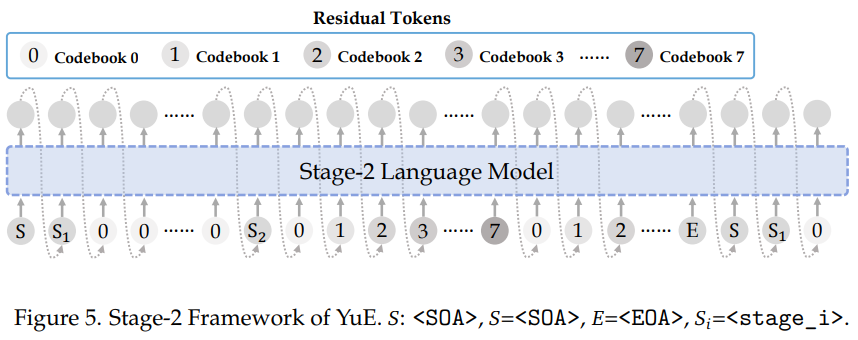
- Stage-1:负责语义级别建模(歌词与旋律对齐)
- 多任务+多阶段预训练:结合TTS、无条件音乐生成、歌词-歌曲配对数据,逐步扩展语境长度并引入控制信号。
DiffRhythm
论文,开源(GitHub,2.1K Star,248 Fork)。
官网:
- https://diffrhythm.com
- https://diffrhythm.org
- https://diffrhythm.app
在线体验:
- https://aisinging.ai
- https://diffrhythm.org/create.php
- https://diffrhythm.app/#generator
InspireMusic
由阿里巴巴通义实验室开发并开源(GitHub,1.3K Star,129 Fork)的生成式AI音乐创作工具包,旨在提供一个统一的平台用于音乐、歌曲和音频生成。
基于自回归变换器和条件流匹配模型,支持多种任务如文本到音乐生成、音乐续写、音乐重建和超分辨率音频生成。核心技术包括音频分词器(将音频转换为离散标记)、基于Qwen模型初始化的Transformer架构,以及扩散模型用于声学细节优化,从而实现高质量音频输出。
亮点:
- 统一音频生成框架:基于强大的音频大模型技术,轻松驾驭各种音频格式,满足多样化的创作需求;
- 灵活可控的生成:通过简单的文字描述或音频提示,就能精准控制音乐风格、结构和情感表达。让AI真正理解你的创作意图;
- 简单易用:提供便捷的模型微调和推理工具,简化模型调整和部署流程;
- 推理模式灵活:包括快速生成模型(fast模型)和高音质模型(支持24kHz或48kHz输出),满足不同用户需求,如快速生成或高品质输出,支持创作5分钟以上的长音频作品;
- 支持混合精度训练(FP16、BF16、FP32),提高训练效率
https://huggingface.co/spaces/FunAudioLLM/InspireMusic
https://modelscope.cn/studios/iic/InspireMusic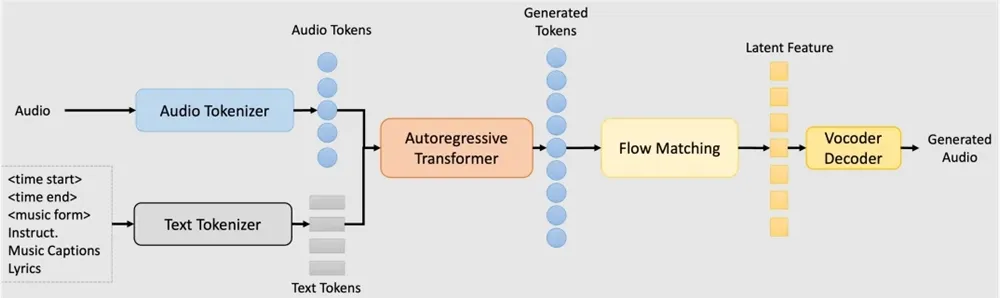
SongGeneration
论文,腾讯AI Lab开源(GitHub,1K Star,118 Fork)音乐生成大模型,专注解决AIGC音乐中音质、音乐性与生成速度这三大难题,基于LLM-DiT的融合架构,在保持生成速度的同时,显著提升音质表现,生成歌曲准确度相较部分商业闭源模型表现出相当甚至更优的质量,同时在整体表现、旋律、伴奏、音质与结构等维度也优于现有多数开源模型。
功能概览:
- 文本控制:用户仅需输入关键词文本(如
开心 流行、激烈 摇滚)即可实现风格与情绪控制,基于输入文本生成高质量的完整音乐作品; - 风格跟随:用户可自行上传10秒以上的参考音频,会自动生成风格一致的全长新曲,覆盖流行、摇滚、中国风、神曲等多种流派。生成歌曲在保持风格一致性的同时,拥有较好的音乐性表现;
- 多轨生成:能够自动生成分离的人声与伴奏轨道,同时保证旋律、结构、节奏与配器的高度匹配;
- 音色跟随:支持基于参考音频的音色跟随功能,生成歌曲具备音色克隆级别的人声表现,听感自然、音质出众的同时,兼具卓越的情感表现力。
实战
项目主页试听效果,托管在Hugging Face空间,也可在线体验。
使用指南
- 歌词有结构组成,一首歌可以包含多个结构
- 一个段落代表一个结构,结构的第一行必须是结构标签,最后一行必须是空行
- 结构标签有以下种类
[verse]:主歌
[chorus]:副歌
[bridge]:过渡
[intro-short]:短前奏
[intro-medium]:中前奏
[outro-short]:短尾奏
[outro-medium]:中尾奏
[inst-short]:短间奏
[inst-medium]:中间奏 - 主歌、副歌、过渡下必须包含歌词:[verse], [chorus], [bridge]
- 其他节奏部分不能包含歌词:
[intro-short], [intro-medium],
[inst-short], [inst-medium],
[outro-short], [outro-medium] - 结构内一行代表一句歌词,行内不建议带上标点符号
参考

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)