【南京理工大学-ICCV25】Controllable-LPMoE:大模型微调也要“可控”与“高效”!
📌 在 COD、SOD、PS、SLS、SD、GD 全面表现领先 📌 IoU、Dice、Fwm 等指标均大幅提升 📌 训练资源大幅缩减。但问题来了👇 ✔ 参数巨大(100M+) ✔ 显存占用高 ✔ 训练速度慢 ✔ 下游任务适应性有限。它不是“微调大模型”,而是“让大模型主动理解任务”——低成本,高表现,适配未来多任务分割时代。动态先验引导的微调范式(Dynamic Priors-based
文章:Controllable-LPMoE: Adapting to Challenging Object Segmentation via Dynamic Local Priors from Mixture-of-Experts
代码:https://github.com/CSYSI/Controllable-LPMoE
单位:南京理工大学
🔍 一、问题背景
在二值目标分割(Binary Object Segmentation)任务中,如伪装目标检测、显著性目标检测、息肉分割、皮肤病变分割等,近年的主流方法是采用Vision Transformer(ViT)类大模型全参数微调。
但问题来了👇 ✔ 参数巨大(100M+) ✔ 显存占用高 ✔ 训练速度慢 ✔ 下游任务适应性有限
于是 Prompt-based 方法开始流行,但缺乏语义先验 & 无法精细感知目标细节 ➜ 分割性能依然不够理想。
📌 核心痛点:
如何在保持大模型强表征能力的前提下,高效、低成本地适配下游分割任务?
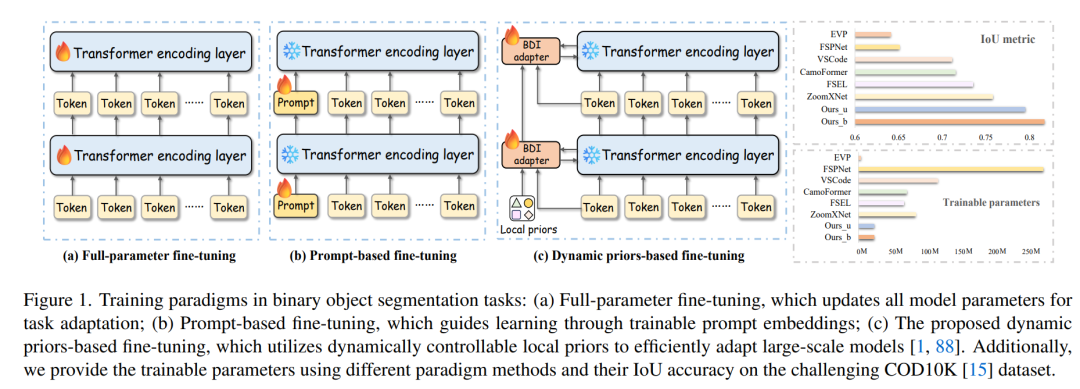
💡 二、方法创新:Controllable-LPMoE
论文提出 动态先验引导的微调范式(Dynamic Priors-based Fine-tuning) ——Controllable-LPMoE:
通过 动态可控的局部先验 + 双向交互适配器,仅用少量可训练参数即可高效调动大模型能力!
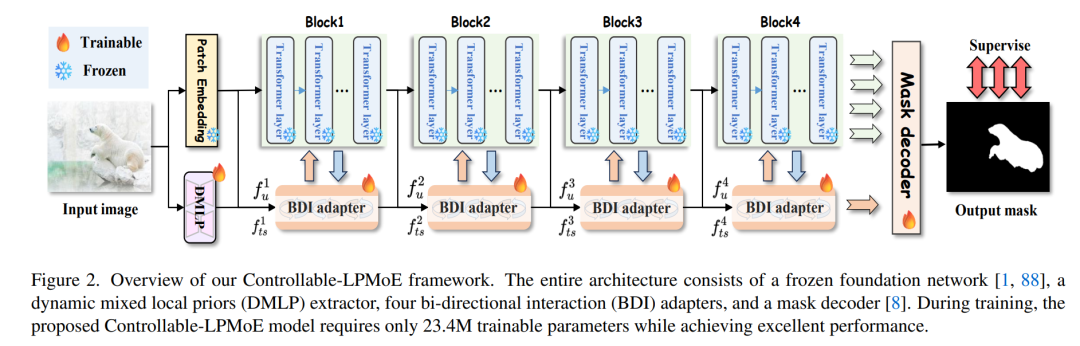
🧠 核心结构:
|
模块 |
功能 |
|---|---|
|
DMLP:Dynamic Mixed Local Priors |
从图像中提取多类型局部先验(异构卷积 + MoE策略) |
|
BDI Adapter |
冻结特征 ↔ 可训练特征之间双向交互,增强语义融合 |
|
Mask Decoder |
输出二值分割结果 |
|
Frozen Encoder |
BEiT-L / UniPerceiver-L,不更新参数 |
📌 框架图显示结构:
-
左边为输入图像
-
中间DMLP提取4类局部prior
-
BDI四次交互
-
Decoder输出mask
仅 23.4M 可训练参数!对比传统方法常超 200M 🚀
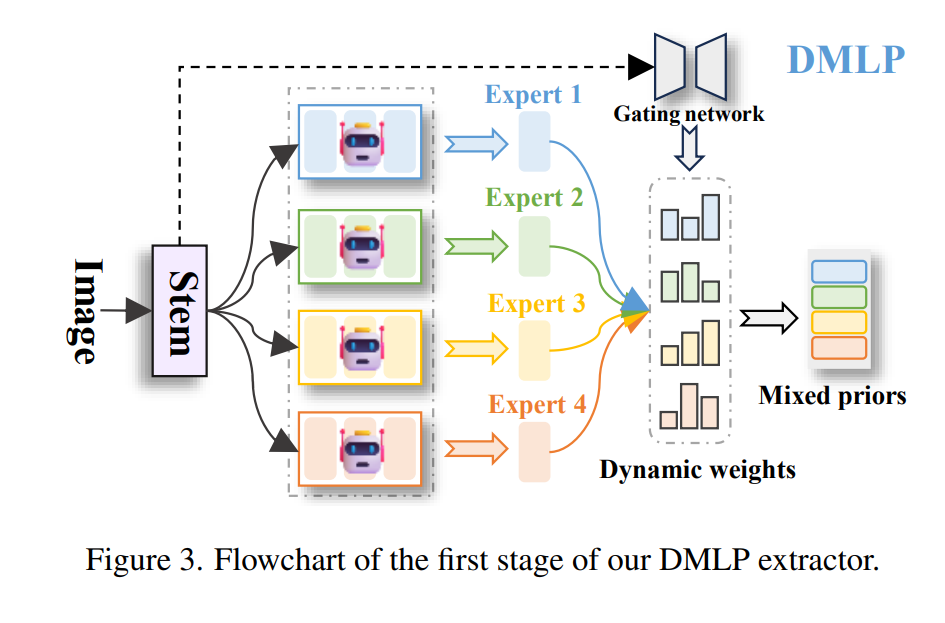
📊 三、实验结果亮点
📌 覆盖 6 大任务,18 个数据集,31 个SOTA对比📌 在 COD、SOD、PS、SLS、SD、GD 全面表现领先 📌 IoU、Dice、Fwm 等指标均大幅提升 📌 训练资源大幅缩减
|
方法 |
训练参数 |
IoU (COD10K) |
|---|---|---|
|
Full FT |
273M+ |
0.858 |
|
Prompt-based |
60M左右 |
0.820 |
| Controllable-LPMoE | 23.4M | 0.876 ↑ |
⚡ 训练效率对比(Page 8 表9):
-
参数仅为1/14
-
显存降低35%~55%
-
训练速度提升10%+
-
性能几乎不降!
🌟 四、优势与局限
👍 优势
✔ 仅 23M 参数即可适配大模型
✔ MoE + 卷积提取更丰富局部信息
✔ 双向交互机制增强特征融合
✔ 适配多种下游任务(稳健泛化)
⚠️ 局限
⚠ 框架仍依赖较大的Frozen Transformer
⚠ 交互次数增加后性能提升有限
⚠ 真实长尾类别场景未深入讨论
🧠 五、一句话总结
它不是“微调大模型”,而是“让大模型主动理解任务”——低成本,高表现,适配未来多任务分割时代。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)