大模型与传统 AI 的区别:从特征工程到端到端学习
文章摘要: 本文对比了传统AI与大模型的核心范式差异。传统AI依赖特征工程和多阶段手工处理,需领域专家设计特征且迁移困难;大模型则通过预训练实现端到端学习,利用海量数据自动提取特征并具备跨任务泛化能力。传统方法受限于特征表达瓶颈和标注数据需求,而大模型通过统一架构支持多任务处理,实现零样本学习和提示工程。这种范式转变使AI开发从专业密集型转向数据驱动型,大幅提升了模型的通用性和应用效率。(149字
·
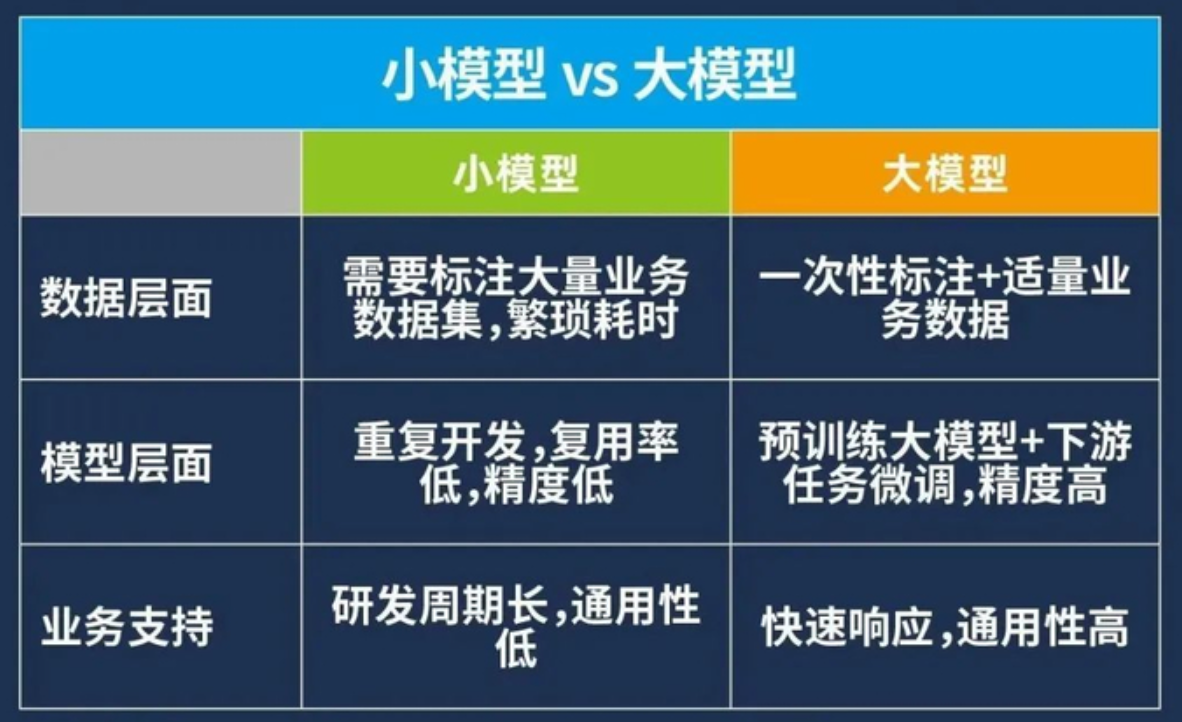
一、核心范式转变
1.1 两种AI范式的对比
根本性区别:
| 维度 | 传统AI | 大模型 |
|---|---|---|
| 核心方法 | 特征工程 + 专用模型 | 预训练 + 提示/微调 |
| 数据依赖 | 高质量标注数据 | 海量无标注数据 |
| 领域迁移 | 需要重新设计 | 零样本/少样本迁移 |
| 开发流程 | 多阶段流水线 | 端到端学习 |
二、传统AI的特征工程时代
2.1 特征工程的本质
传统机器学习流程:
# 传统文本分类的特征工程示例
class TraditionalTextClassifier:
def feature_engineering(self, raw_text):
features = {}
# 1. 文本统计特征
features['text_length'] = len(raw_text)
features['word_count'] = len(raw_text.split())
features['avg_word_length'] = np.mean([len(word) for word in raw_text.split()])
# 2. 词袋模型特征
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=1000)
tfidf_features = vectorizer.fit_transform([raw_text])
# 3. 句法特征
features['contains_question'] = '?' in raw_text
features['exclamation_count'] = raw_text.count('!')
# 4. 领域特定特征(需要专家知识)
features['contains_medical_terms'] = self.detect_medical_terms(raw_text)
features['sentiment_score'] = self.calculate_sentiment(raw_text)
return features
def detect_medical_terms(self, text):
# 需要医学专家定义的关键词列表
medical_terms = ['fever', 'headache', 'prescription', 'symptom']
return any(term in text.lower() for term in medical_terms)
2.2 传统AI的技术栈
完整的传统AI流水线:
class TraditionalMLPipeline:
def __init__(self):
self.steps = [
"数据收集与清洗",
"特征工程与选择",
"模型选择与训练",
"超参数调优",
"模型部署与监控"
]
def run_pipeline(self, raw_data):
results = {}
# 阶段1: 数据预处理
cleaned_data = self.data_cleaning(raw_data)
# 阶段2: 特征工程(最耗时)
features = self.comprehensive_feature_engineering(cleaned_data)
# 阶段3: 特征选择
selected_features = self.feature_selection(features)
# 阶段4: 模型训练
model = self.train_model(selected_features)
# 阶段5: 评估优化
performance = self.evaluate_model(model)
return model, performance
def feature_engineering(self, data):
"""需要大量领域知识和试错"""
features = {
'statistical': self.statistical_features(data),
'linguistic': self.linguistic_features(data),
'domain_specific': self.domain_expert_features(data),
'temporal': self.temporal_features(data)
}
return features
2.3 传统AI的局限性
主要挑战:
class TraditionalAILimitations:
def __init__(self):
self.challenges = {
"特征工程瓶颈": {
"问题": "依赖专家知识,难以自动化",
"影响": "开发周期长,成本高",
"示例": "需要语言学专家设计文本特征"
},
"领域迁移困难": {
"问题": "每个任务需要重新设计特征",
"影响": "无法跨领域泛化",
"示例": "情感分析特征不能用于文本分类"
},
"数据要求严格": {
"问题": "需要大量标注数据",
"影响": "标注成本高昂",
"示例": "需要人工标注数千个样本"
},
"性能天花板": {
"问题": "手工特征表达能力有限",
"影响": "性能提升遇到瓶颈",
"示例": "准确率难以突破90%"
}
}
三、大模型的端到端革命
3.1 端到端学习原理
大模型的核心思想:
class LargeLanguageModel:
def __init__(self):
self.paradigm_shift = {
"从": "手工特征 + 专用模型",
"到": "预训练表示 + 提示工程",
"关键创新": "统一架构解决多任务"
}
def pretraining_phase(self):
"""预训练:学习通用表示"""
return """
自监督学习目标:
输入: 海量无标注文本数据
任务: 下一个词预测
输出: 通用的语言理解能力
"""
def adaptation_phase(self):
"""适配:应用到具体任务"""
adaptation_methods = {
"提示工程": "通过自然语言指令激发能力",
"微调": "少量标注数据继续训练",
"上下文学习": "在提示中提供示例"
}
return adaptation_methods
3.2 统一架构解决多任务
# 大模型的统一处理方式
class UnifiedModelApproach:
def handle_different_tasks(self, task_description, input_text):
"""
使用同一个模型处理多种任务
无需为每个任务设计特定架构
"""
tasks = {
"文本分类": f"分类以下文本的情感:{input_text}",
"翻译": f"将以下文本翻译成英文:{input_text}",
"摘要": f"为以下文本生成摘要:{input_text}",
"问答": f"基于以下文本回答问题:{input_text}",
"代码生成": f"根据以下描述生成代码:{input_text}"
}
prompt = tasks.get(task_description, input_text)
return self.model.generate(prompt)
def zero_shot_learning(self, task, input_data):
"""零样本学习:无需任务特定训练数据"""
# 模型在预训练时已经学习了相关模式
prompt = f"执行{task}任务:{input_data}"
return self.model.generate(prompt)
四、技术架构对比
4.1 架构演进路径
4.2 具体技术对比
自然语言处理任务对比:
class NLPTaskComparison:
def sentiment_analysis_compare(self):
traditional_approach = {
"步骤": [
"1. 收集标注的情感数据",
"2. 设计情感词典和规则",
"3. 提取TF-IDF、n-gram特征",
"4. 训练SVM/随机森林模型",
"5. 评估和调优"
],
"所需专业知识": ["语言学", "特征工程", "机器学习"],
"开发时间": "数周至数月",
"准确率": "85-90%"
}
llm_approach = {
"步骤": [
"1. 编写提示词:'分析以下文本的情感:{text}'",
"2. 直接调用大模型API",
"3. 解析返回结果"
],
"所需专业知识": ["提示工程"],
"开发时间": "数小时至数天",
"准确率": "90-95%"
}
return traditional_approach, llm_approach
def machine_translation_compare(self):
traditional = {
"架构": "编码器-解码器 + 注意力",
"训练数据": "需要平行语料库",
"语言对": "每个语言对需要单独训练",
"维护成本": "高(每个模型独立维护)"
}
llm = {
"架构": "统一的大语言模型",
"训练数据": "多语言混合数据",
"语言对": "支持任意语言对零样本翻译",
"维护成本": "低(单一模型)"
}
return traditional, llm
五、开发流程变革
5.1 传统AI开发流程
class TraditionalDevelopmentWorkflow:
def __init__(self):
self.phases = [
{
"阶段": "需求分析",
"持续时间": "1-2周",
"主要活动": "领域分析、数据评估、可行性研究",
"关键角色": "领域专家、数据科学家"
},
{
"阶段": "数据准备",
"持续时间": "2-4周",
"主要活动": "数据收集、清洗、标注",
"关键角色": "数据工程师、标注团队"
},
{
"阶段": "特征工程",
"持续时间": "3-6周",
"主要活动": "特征设计、选择、优化",
"关键角色": "机器学习工程师、领域专家"
},
{
"阶段": "模型开发",
"持续时间": "2-4周",
"主要活动": "算法选择、训练、验证",
"关键角色": "机器学习工程师"
},
{
"阶段": "部署运维",
"持续时间": "2-3周",
"主要活动": "模型部署、监控、更新",
"关键角色": "MLOps工程师"
}
]
def total_timeline(self):
return "总计:10-19周(2.5-5个月)"
def key_bottlenecks(self):
return [
"特征工程依赖专家知识",
"数据标注成本高",
"模型调优周期长",
"跨领域迁移困难"
]
5.2 大模型开发流程
class LLMDevelopmentWorkflow:
def __init__(self):
self.phases = [
{
"阶段": "任务定义",
"持续时间": "几天",
"主要活动": "明确需求、设计提示词",
"关键角色": "产品经理、提示工程师"
},
{
"阶段": "提示工程",
"持续时间": "1-2周",
"主要活动": "设计优化提示、few-shot示例",
"关键角色": "提示工程师"
},
{
"阶段": "评估迭代",
"持续时间": "1周",
"主要活动": "测试效果、调整策略",
"关键角色": "测试工程师"
},
{
"阶段": "部署集成",
"持续时间": "1周",
"主要活动": "API集成、应用开发",
"关键角色": "软件工程师"
}
]
def total_timeline(self):
return "总计:3-5周"
def efficiency_improvements(self):
return {
"时间节省": "75-80%",
"人力节省": "减少对领域专家的依赖",
"成本降低": "避免复杂的数据标注",
"灵活性": "快速迭代和调整"
}
六、能力范围对比
6.1 任务泛化能力
传统AI的任务专用性:
class TraditionalAICapabilities:
def __init__(self):
self.specialized_models = {
"情感分析模型": "只能做情感分析",
"命名实体识别模型": "只能做NER",
"文本分类模型": "只能做文本分类",
"机器翻译模型": "特定语言对翻译"
}
def add_new_task(self, new_task):
"""新增任务需要从头开发"""
return f"需要为{new_task}重新收集数据、设计特征、训练模型"
def knowledge_transfer(self):
return "有限,主要依赖特征工程的通用性"
大模型的任务通用性:
class LLMCapabilities:
def __init__(self):
self.unified_abilities = {
"理解能力": ["语义理解", "逻辑推理", "知识问答"],
"生成能力": ["文本创作", "代码生成", "对话生成"],
"分析能力": ["情感分析", "文本分类", "信息提取"],
"转换能力": ["翻译", "摘要", "格式转换"]
}
def handle_new_task(self, task_description):
"""通过自然语言描述处理新任务"""
return f"模型通过提示词理解并执行:{task_description}"
def emergent_abilities(self):
return [
"零样本学习",
"少样本学习",
"思维链推理",
"指令跟随"
]
6.2 性能表现对比
class PerformanceComparison:
def benchmark_comparison(self):
tasks = {
"文本分类": {
"传统AI": {"准确率": "89%", "开发成本": "高"},
"大模型": {"准确率": "93%", "开发成本": "低"}
},
"命名实体识别": {
"传统AI": {"F1分数": "0.87", "开发成本": "高"},
"大模型": {"F1分数": "0.91", "开发成本": "中"}
},
"情感分析": {
"传统AI": {"准确率": "86%", "开发成本": "中"},
"大模型": {"准确率": "92%", "开发成本": "低"}
},
"创意写作": {
"传统AI": {"质量": "有限", "开发成本": "很高"},
"大模型": {"质量": "优秀", "开发成本": "很低"}
}
}
return tasks
def cost_effectiveness(self):
"""成本效益分析"""
analysis = {
"传统AI": {
"初始开发成本": "$50,000 - $200,000",
"维护成本": "高(每个模型独立维护)",
"扩展成本": "高(新任务需要重新开发)",
"投资回报周期": "长(6-12个月)"
},
"大模型": {
"初始开发成本": "$5,000 - $20,000",
"维护成本": "低(单一模型)",
"扩展成本": "低(通过提示工程)",
"投资回报周期": "短(1-3个月)"
}
}
return analysis
七、实际应用案例
7.1 客户服务系统对比
传统方法:
class TraditionalCustomerService:
def __init__(self):
self.components = {
"意图识别模型": "基于规则和分类器",
"情感分析模型": "专用情感分类器",
"问答系统": "基于知识库检索",
"路由系统": "规则引擎"
}
def process_query(self, user_query):
steps = [
"1. 意图分类 → 确定用户目的",
"2. 情感分析 → 判断用户情绪",
"3. 实体提取 → 识别关键信息",
"4. 知识检索 → 查找相关答案",
"5. 回答生成 → 模板填充"
]
return " → ".join(steps)
def limitations(self):
return [
"意图分类准确率有限",
"无法处理复杂多轮对话",
"知识库更新维护复杂",
"扩展新功能需要重新训练模型"
]
大模型方法:
class LLMCustomerService:
def __init__(self):
self.unified_approach = "单一模型处理所有任务"
def process_query(self, user_query, conversation_history):
prompt = f"""
作为客户服务助手,请回答用户问题。
历史对话:
{conversation_history}
当前问题:
{user_query}
请提供专业、友好的回答。
"""
return self.llm.generate(prompt)
def advantages(self):
return [
"自然的多轮对话能力",
"理解复杂和模糊的查询",
"统一的知识理解和应用",
"快速适应新的问题类型"
]
7.2 内容生成对比
传统内容生成:
class TraditionalContentGeneration:
def generate_article(self, topic):
methods = {
"模板填充": "预定义文章结构 + 关键词填充",
"摘要提取": "从现有内容中提取重组",
"规则生成": "基于语法规则生成句子"
}
return "生硬、模式化、创造性有限"
def limitations(self):
return {
"创造性": "有限,基于模式和规则",
"连贯性": "段落间衔接不自然",
"适应性": "难以适应不同风格要求",
"质量": "明显的人工生成痕迹"
}
大模型内容生成:
class LLMContentGeneration:
def generate_article(self, topic, style="professional", length=1000):
prompt = f"""
以{style}风格写一篇关于{topic}的文章,字数约{length}字。
要求内容专业、结构清晰、语言流畅。
"""
return self.llm.generate(prompt)
def advantages(self):
return {
"创造性": "高,能生成新颖内容",
"连贯性": "文章逻辑连贯自然",
"适应性": "轻松适应不同风格主题",
"质量": "接近人类写作水平"
}
八、总结
8.1 核心区别总结
范式转变的本质:
class ParadigmShiftSummary:
def key_differences(self):
return {
"方法论": {
"传统AI": "分而治之,专用模型",
"大模型": "统一架构,通用智能"
},
"数据使用": {
"传统AI": "标注数据驱动",
"大模型": "预训练 + 提示"
},
"开发流程": {
"传统AI": "线性多阶段",
"大模型": "迭代快速开发"
},
"能力范围": {
"传统AI": "狭窄但稳定",
"大模型": "广泛但需要控制"
}
}
def selection_guidance(self):
return """
选择传统AI当:
- 任务明确且稳定
- 对可解释性要求高
- 计算资源有限
- 有丰富的领域知识
选择大模型当:
- 任务复杂多变
- 需要创造性和泛化能力
- 开发时间紧迫
- 处理自然语言任务
"""
8.2 未来展望
大模型不是完全取代传统AI,而是开启了AI应用的新范式。未来的AI系统很可能是混合架构,结合大模型的通用能力和传统AI的专用优化,在各目的应用场景中发挥最大价值。
理解这两种范式的区别,有助于我们在合适的场景选择合适的技术,更好地规划和建设AI系统。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 9
9 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)