【ICLR26匿名投稿】MIGA:让无限帧视频生成重回技术巅峰通过免训练技术
目前主流的「训练自由」(train-free)延长方案,如 FreeNoise、FreeLong、FreePCA,通过重排噪声或融合频域信息,成功突破了基础模型的帧数限制。MIGA 通过“噪声分布对齐 + 时序一致性建模”,在不训练的前提下,让基础模型实现高一致性的无限帧长视频生成,推动长视频生成迈向实用化。FIFO-Diffusion 虽提出了基于噪声队列的自回归生成机制,实现了理论上的无限帧,
文章: MIGA: Make Train-Free Infinite Frame Generation Great Again for Consistent Long Vide os
代码:暂无
单位与作者:匿名
📌 问题背景:Train-Free 长视频生成的瓶颈
近年来,基础视频生成模型(如 Wan、VideoCrafter2)在短视频合成上取得了突破性进展。但要满足电影制作、游戏引擎、数字孪生等场景需求,仅仅“生成几秒视频”远远不够。长时长、可控、内容一致 才是落地应用的刚需。
目前主流的「训练自由」(train-free)延长方案,如 FreeNoise、FreeLong、FreePCA,通过重排噪声或融合频域信息,成功突破了基础模型的帧数限制。然而,它们仍面临两大核心技术挑战:
-
训练-推理噪声分布不一致模型训练时仅见过统一噪声水平的短片段,而推理时却要同时处理多帧、多噪声水平,导致内容漂移与失真积累。
-
长期一致性建模缺失主体在长视频中可能出现位置漂移、形态抖动、背景闪烁等现象,而现有方法多只处理局部一致性。
FIFO-Diffusion 虽提出了基于噪声队列的自回归生成机制,实现了理论上的无限帧,但上述问题依然未被根治。

🧠 方法创新:MIGA 框架
MIGA(Make Train-Free Infinite Frame Generation Great Again)在保持 train-free 特性的前提下,针对上述两大痛点提出了两项核心技术改进:
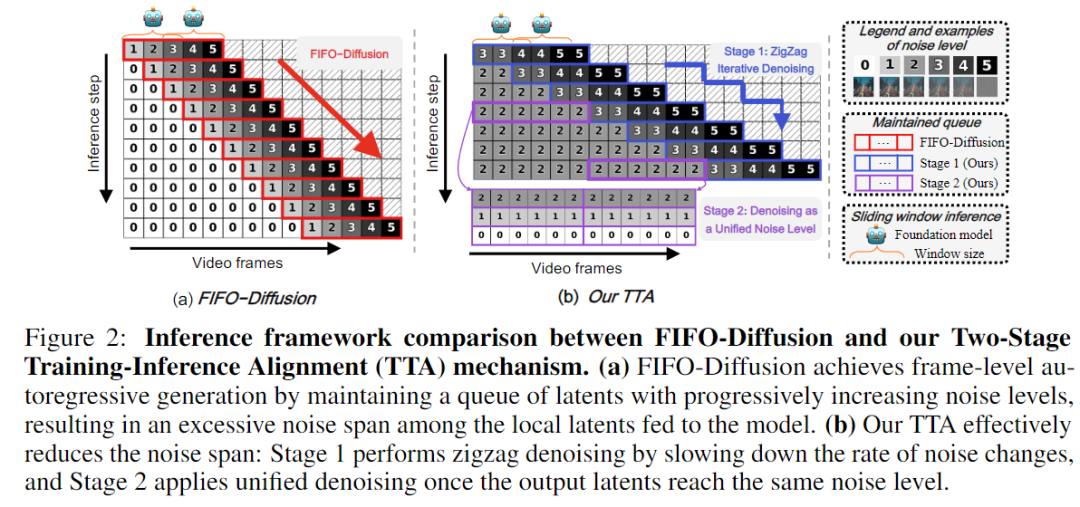
1. 🌀 两阶段训练-推理对齐机制(TTA)
核心思想:推理时控制噪声分布,使其更接近训练阶段。
-
Stage 1:Zigzag Iterative Denoising推理时对噪声变化进行“缓冲”,通过 Zigzag 结构让噪声跨度更小,从而减轻模型处理多噪声输入时的不稳定性。
-
Stage 2:Unified Noise Level Denoising所有帧被逐步推到统一噪声级别,接近训练分布,进一步缩小 training–inference gap。
TTA 本质上是在「推理时」构造一个更接近训练时分布的输入,从而让基础模型的潜力得到更充分释放。
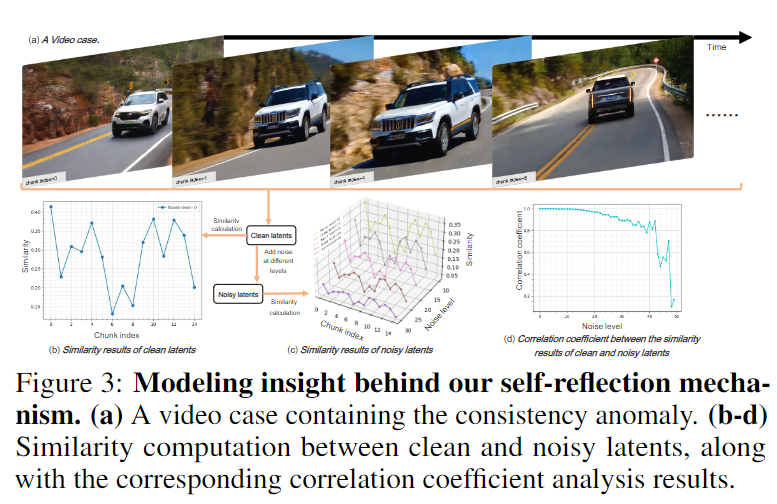
2. 🔁 双一致性增强机制(DCE)
核心思想:通过“自反射 + 长程引导”显式强化视频时序一致性。
-
Self-Reflection借鉴 LLM 中 Test-Time Scaling(TTS)思路,在早期高噪声阶段动态检测一致性异常位置,触发局部搜索和替换,低成本实现自我纠错。
-
Long-Range Frame Guidance引入序列中较早、已低噪声的帧作为引导信息,增强远程依赖的建模能力,让前后帧在结构与语义上保持稳定。
该机制避免了依赖外部评估器或额外训练,完全在 latent 层完成一致性建模。
📊 实验结果:SOTA 性能验证
MIGA 在 VBench 与 NarrLV 两个主流长视频评测基准上均取得了显著提升:
|
方法 |
无限帧 |
主体一致性 |
背景一致性 |
平均得分 |
|---|---|---|---|---|
|
FIFO-Diffusion |
✅ |
92.92 |
95.01 |
95.02 |
|
ScalingNoise |
✅ |
94.29 |
95.52 |
95.95 |
| MIGA (Ours) |
✅ |
97.66 | 96.99 | 97.82 |
NarrLV 的多叙事测试同样证明,MIGA 能更好地支持复杂语义和长时间的叙事内容生成,尤其是在 TNA=4 情况下领先幅度最大。
此外,消融实验进一步验证了两大机制的独立有效性:
-
单独加入 TTA 或 DCE 都能带来显著增益;
-
组合使用时整体一致性表现达到峰值。
🌟 优势与局限
✅ 技术优势
-
完全 Train-Free:无需额外训练成本即可解锁长视频能力;
-
分布对齐 + 自反射机制,有效缓解 drift 与噪声积累;
-
一致性建模内化到推理过程中,无需额外模型;
-
可无缝嵌入现有基础视频生成框架(如 Wan、VideoCrafter2)。
⚠️ 局限与挑战
-
自反射机制引入的搜索在长视频推理中增加计算成本;
-
对极高复杂度、多主体场景的鲁棒性仍有限;
-
泛化到多样化场景和真实拍摄风格仍需更多实证。
📝 一句话总结
MIGA 通过“噪声分布对齐 + 时序一致性建模”,在不训练的前提下,让基础模型实现高一致性的无限帧长视频生成,推动长视频生成迈向实用化。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)