【论文阅读】Reward Fine-Tuning Two-Step Diffusion Models via Learning Differentiable Latent-Space
这篇论文提出了一种新的框架LaSRO,用于在潜在空间中学习可微分的替代奖励,从而有效解决了两步扩散模型的微调问题。:通过广泛的消融研究和实验,验证了LaSRO在不同奖励目标下的有效性和稳定性,优于流行的强化学习方法(如DDPO和Diffusion-DPO)。:未来的研究可以进一步探索LaSRO在其他类型的两步扩散模型中的应用,并优化其设计以提高在不同任务和奖励信号下的性能。:LaSRO的TD
通过学习可微分的潜在空间代理奖励来微调两步扩散模型。
Reward Fine-Tuning Two-Step Diffusion Models via Learning Differentiable Latent-Space Surrogate Reward
背景
-
研究问题:解决的问题是如何在超快速(≤2步)图像生成中,通过学习可微分的替代奖励来微调扩散模型(DMs)。现有的强化学习方法(如PPO或DPO)在应用于步骤蒸馏的DMs时存在局限性。
-
研究难点:两步扩散采样器的确定性映射导致非平滑性,使得策略梯度估计变得困难;现有的RL方法在处理非光滑映射时效果不佳,导致训练不稳定和效率低下。
-
相关工作:扩散模型在连续数据生成中的显著应用;步骤蒸馏扩散模型的研究进展;以及使用RL方法微调DMs以对齐模型输出的研究。
-
基础:Latent Consistency Models,是 teacher DMs(比如 SDXL) 的快速蒸馏版本。LCM 在 潜空间(latent space) 工作。通过 Consistency Distillation 学习一个映射:
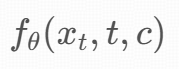 这个映射可以直接从任意噪声层 xt 把数据“跳”到最终生成结果 x0,相当于压缩了原本多步的去噪过程。
这个映射可以直接从任意噪声层 xt 把数据“跳”到最终生成结果 x0,相当于压缩了原本多步的去噪过程。
为什么现有 RL 方法在 ≤ 2 步 DM 上失效?
-
采样过程高度确定性
- 在二步蒸馏 DM 中,第一步是从噪声到中间状态,第二步几乎是确定性映射到最终图像。
- 很多 RL 依赖于模型的随机性进行探索,但这里几乎没有随机性。
-
映射非平滑
- 从噪声 → 图像的映射不连续,reward 对输入噪声的梯度无法平稳传播,导致策略梯度(policy gradient)估计不准确。
-
探索困难
- PPO / DPO 等基于策略梯度的方法需要广泛探索,但在二步生成中几乎探索不到新的结果。
-
特定 RL 方法失效
- Diffusion-DPO、DDPO 等依赖扩散损失(denoising loss)的方法,在二步 DM 中反而生成模糊图像,因为奖励信号无法有效反映至采样分布。
方法
这篇论文提出了LaSRO(Latent-space Surrogate Reward Optimization)框架,用于解决两步扩散模型的微调问题。
与其直接对不可微分的 reward 做策略梯度,不如:
- 学习一个可微分的奖励代理(Surrogate Reward)。在模型的 latent space(如 SDXL 的潜空间)上进行学习,使这个代理奖励函数模拟真实奖励。
- 用可微分的奖励直接指导扩散模型微调,绕过策略梯度的难题。具体实现上,利用预训练的潜在扩散模型作为替代模型的骨干,并在其上添加一个简单的CNN预测头。
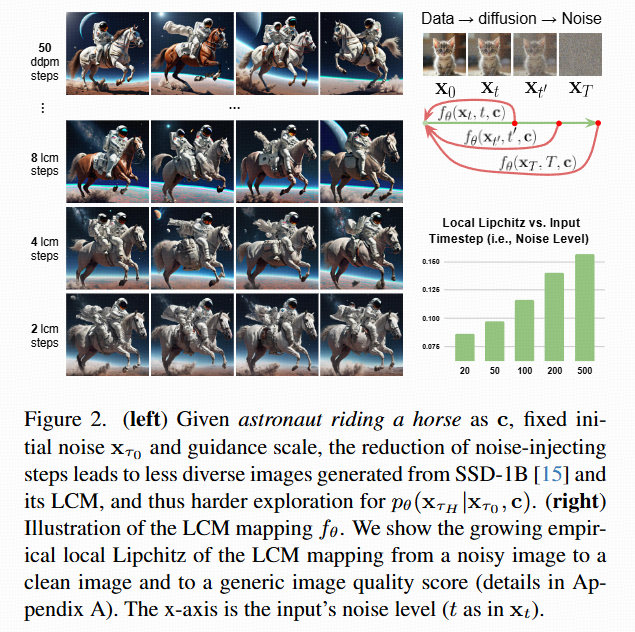
两步扩散模型的微调:提出了一个两阶段的微调框架:预训练阶段和奖励优化阶段。预训练阶段学习替代奖励,奖励优化阶段交替进行DM的微调和替代奖励的在线适应。
实验设计
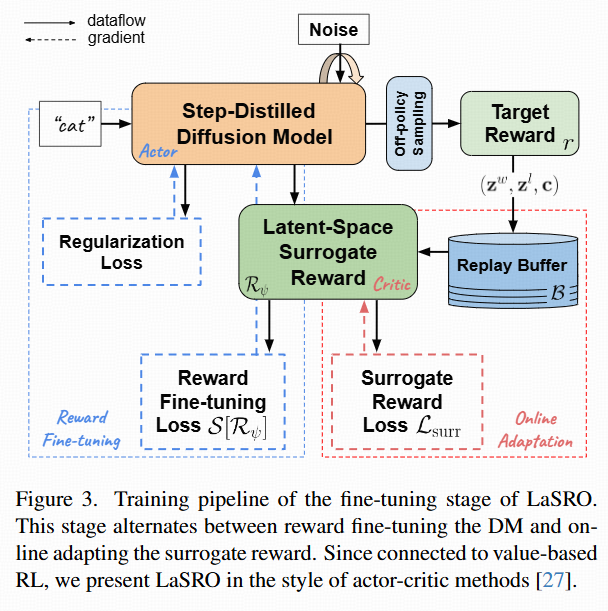
LaSRO,一个包含两个阶段的强化学习训练框架:(1)预训练潜在空间替代奖励(算法1)。(2)对两步DM进行奖励微调(算法2)。图3中可视化了后期阶段的流程。
训练方法
- 来自 teacher DM(记作 ϕ)的两条轨迹(teacher 生成的 x^t−1ϕ 和 student model 生成的 fθ(xt))之间进行一致性约束:d(⋅,⋅) 是距离度量(比如 L2 距离);第二个 fθ 不反传梯度(stop gradient)。
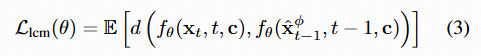
采样方法
- LCM 一步就能生成图像(1-step)。
- 如果想多步采样,可以在每一步中把部分噪声重新注入:
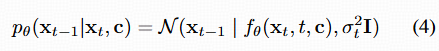
奖励函数:对 LCM,由于中间就能生成图像,可以在所有步都计算奖励:![]()
What are the RL Obstacles
研究背景。总结了三大难题,这也是 LaSRO 设计的出发点。
Hard Exploration for Two-Step Image DMs
- 在普通多步扩散模型中,每一步采样都会注入高斯噪声,形成较大的 采样多样性,方便 RL 的探索。
- 两步(甚至一步)蒸馏模型 噪声注入次数大幅减少:
- 一步 LCM 完全确定性,没有随机性。
- 两步 LCM 只在第二步前注入一次噪声:这里的 Z 是唯一的随机性来源。
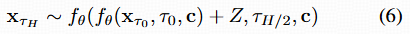
Degenerated RL Objectives for Two-Step DMs
在 RL 中(例如 DDPO),目标通常是:![]()
梯度:
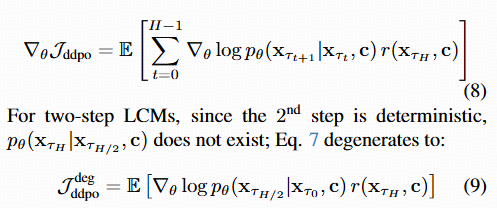
在两步 LCM 中,第二步是确定性的:没法对 pθ(xτH∣xτH/2,c) 取梯度,因为它不是概率分布而是确定性映射。目标退化成(9),只优化了生成链的前半段,后半段无法直接优化 → 效果差。
Non-Smooth Mappings of Two-Step DMs
- 两步 DM 的去噪映射高度非平滑(高 Lipschitz 常数):
- 输入 latent 有轻微变化 → 输出图像差异巨大(尤其是第一步输入噪声很大)。
- 第二步要从非常嘈杂的输入 xτH/2 生成清晰图像,需要强大非线性拟合 → 非平滑性更高。
- 结果:
- 策略梯度方法(PPO等):
- 高非平滑性使梯度估计方差极高 → 训练不稳定。
- Reward-Weighted Regression(RWR, DPO等):
- 虽然回避了梯度高方差,但直接用扩散损失微调会破坏蒸馏过程映射 → 生成图像变模糊。
- 策略梯度方法(PPO等):
- 结论:
两步 DM 的非平滑性是 RL 的大敌,既破坏梯度估计,又让 RWR 类方法失效。
Clearing the RL Obstacles with LaSRO
核心设计思想
- 不用直接从不可微分 reward 求策略梯度 → 改为训练一个 可微分的奖励代理(Surrogate Reward Rψ)。
- Rψ 在 latent space 中预测 reward 分值,可平滑地反传到生成模型。
- 这样:
- 第二步的确定性映射也能获得 reward 梯度(因为 Rψ 可直接对 latent 求梯度)。
- 探索不依赖噪声注入,可以通过 reward 梯度在 latent 空间中移动。
- 避免高方差策略梯度,避免 RWR 模糊化。
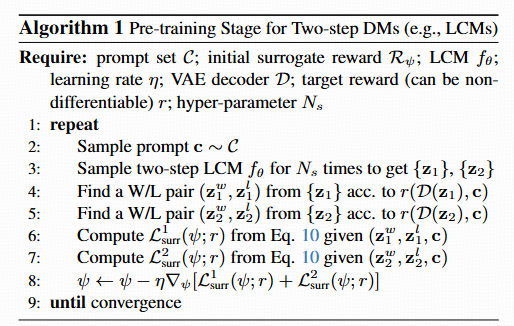

阶段 1:Surrogate Reward 学习
-
把真实奖励函数(可能不可微分)作为标签。使用预训练的 latent diffusion 作为 backbone 来训练一个 可微分奖励网络。输入是 latent representation,输出是奖励值。相当于拟合奖励函数的一个「平滑近似」。
阶段 2:Reward Optimization
- 用 surrogate reward 对扩散模型进行微调。由于 surrogate 可微分,可以直接反传梯度至扩散模型。用 off-policy 样本(已有生成结果)来高效探索,避免在线 RL 的低效。
Surrogate Reward Learning 预训练阶段
- 选择 backbone:
- 测试过 CLIP / BLIP / SDXL Unet encoder → SDXL latent encoder 最好(效率高 & 特征一致)。
- 预测头:
- 简单 CNN,用来输出可微 reward Rψ(z,c)。
- 训练目标:
- 使用 Bradley-Terry 模型做成对 ranking loss:
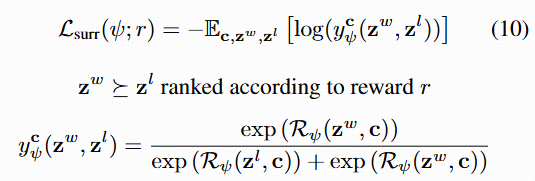
- 使用 Bradley-Terry 模型做成对 ranking loss:
数据生成:
- 从 prompt 集随机取一个 c。
- 用 LCM 生成 z1=fθ(zτ0,τ0,c)(第一步结果),采样 Ns 个不同初始噪声。
- 为每个 z1 注入噪声 Z 生成 z2=fθ(z1+Z,τH/2,c)(第二步)。
- 用真实 reward r(D(z),c) 找出胜/负样本对并训练 Rψ。
📌 关键优势:
- 在 latent 空间训练(效率更高,保留更多结构信息)。
- 可直接用于后续两步精调。
Reward Fine-tuning Two-Step DMs 微调阶段
交替进行:
- Reward Fine-tuning:
- 采样两步 latent(z1, z2),用 Rψ 计算 reward 分值,经过归一化 & 截断函数 S 提高稳定性。
- 总损失:第一项是原 LCM 蒸馏损失(保持生成质量),后两项是 reward 引导(分别针对第一步 & 第二步 latent)。
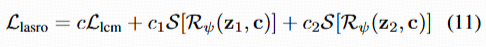
- Online Adaptation:
- 从 replay buffer B 中取样(存放生成的胜/负样本对),继续微调 Rψ,适应分布变化。
LaSRO ≈ Value-Based RL 理论解释
- 对于 horizon H=2 的 MDP,TD-learning 的 Q(st, at) 近似等价于 Rψ(z, c)。
- LaSRO 类似 actor-critic:
- actor = LCM 生成器 fθ
- critic = surrogate reward Rψ
- 差别:
- 完全 off-policy(采样初始噪声 N 次形成多样性)
- 短时任务中,value-based 方法比 policy gradient 稳定很多。
- 这解释了 LaSRO 为什么在两步模型中优于 DDPO / DPO。
总结 RL 障碍:
|
障碍 |
原因 |
LaSRO 解决方式 |
|---|---|---|
|
探索不足 |
噪声注入次数太少 |
latent 空间梯度引导探索 + 多初始噪声 off-policy |
|
目标退化 |
第二步不可导 |
surrogate reward 可直接对第二步 latent 提供梯度 |
|
非平滑映射 |
策略梯度方差高 / RWR 模糊化 |
避免直接 policy gradient / RWR,改为平滑 surrogate |
-
数据集:选择LCM(Latent Consistency Model)作为主要测试平台,从SSD-1B蒸馏得到。训练数据集为T2I-prompt-873K,包含873k个独特的文本提示。评估数据集包括MJHQ-30K,涵盖10个常见的文本到图像类别。
-
实验设置:在预训练阶段,使用随机抽取的文本提示和初始噪声,训练替代奖励模型。在奖励优化阶段,交替进行DM的微调和替代奖励的在线适应。使用归一化和剪辑的微调损失函数,并通过跟踪替代奖励的移动平均值和最大值来提高训练稳定性。
结果与分析
-
一般图像质量提升:通过优化Image Reward,LaSRO显著提高了两步扩散模型生成的图像质量。与其他RL方法相比,LaSRO在训练稳定性和生成图像质量方面表现优异。
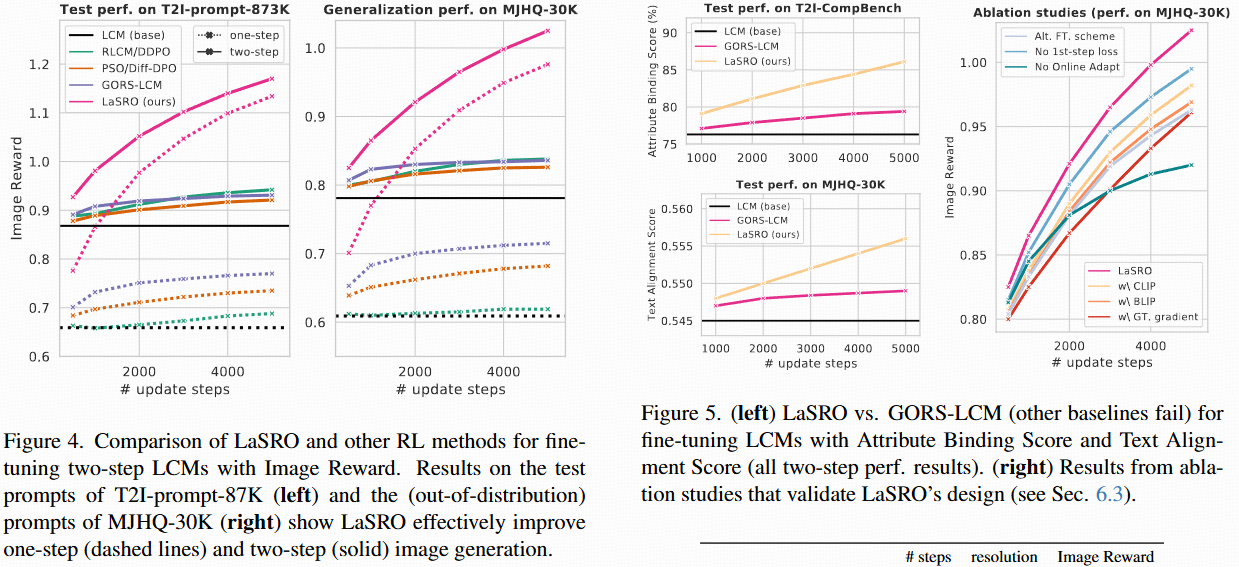
-
属性绑定:通过优化Attribute Binding Score,LaSRO显著提高了输入提示与生成图像中对应元素之间的属性绑定能力。
-
文本对齐:通过优化Text Alignment Score,LaSRO显著提高了生成图像的文本对齐能力。
总体结论
这篇论文提出了一种新的框架LaSRO,用于在潜在空间中学习可微分的替代奖励,从而有效解决了两步扩散模型的微调问题。LaSRO在优化不同奖励目标方面表现出色,优于现有的流行RL方法。通过理论分析和实验验证,展示了LaSRO的设计优势,并为大规模RL微调和定制模型对齐提供了新的思路。
优点与创新
-
解决了现有强化学习方法在超快速图像生成(≤2步)中的局限性:论文分析了基于策略的强化学习方法(如PPO和DPO)在应用现有方法时面临的挑战,并提出了新的解决方案。
-
提出了LaSRO框架:通过在潜在空间中学习可微分的替代奖励模型,LaSRO能够将任意奖励信号转换为可微分信号,从而有效地进行奖励梯度指导。
-
利用预训练的潜在扩散模型:LaSRO使用预训练的潜在扩散模型作为替代模型的骨干,展示了其在内存和速度效率以及泛化能力方面的优越性。
-
高效的离线探索:LaSRO通过离策略样本实现了对两步图像扩散模型的高效探索。
-
理论洞察:论文进一步展示了LaSRO与基于价值的强化学习之间的联系,提供了理论上的见解。
-
实验验证:通过广泛的消融研究和实验,验证了LaSRO在不同奖励目标下的有效性和稳定性,优于流行的强化学习方法(如DDPO和Diffusion-DPO)。
不足与反思
-
局限性:论文提到,尽管LaSRO在超快速图像生成方面表现出色,但其设计主要针对特定的应用场景(如文本到图像生成),可能需要进一步的调整和优化以适应其他数据模态或任务。
-
下一步工作:未来的研究可以进一步探索LaSRO在其他类型的两步扩散模型中的应用,并优化其设计以提高在不同任务和奖励信号下的性能。
关键问题及回答
问题1:LaSRO框架如何在潜在空间中学习可微分的替代奖励模型?
LaSRO框架通过在潜在空间中学习一个可微分的替代奖励模型来解决两步扩散模型的微调问题。具体实现上,LaSRO利用预训练的潜在扩散模型作为替代模型的骨干,并在其上添加一个简单的CNN预测头。替代奖励模型的目标是将任意奖励信号转换为可微分的奖励信号,从而避免策略梯度估计问题。在预训练阶段,LaSRO使用随机抽取的文本提示和初始噪声,训练替代奖励模型。通过这种方式,LaSRO能够提供准确的奖励梯度指导,从而显著提高两步扩散模型生成的图像质量。
问题2:LaSRO框架的两阶段微调过程是如何设计的?
LaSRO框架的两阶段微调过程包括预训练阶段和奖励优化阶段。在预训练阶段,LaSRO学习替代奖励模型,具体步骤如下:
-
使用随机抽取的文本提示和初始噪声,训练替代奖励模型。
-
通过对比不同样本的得分,找到胜者和败者对,并计算损失函数。
在奖励优化阶段,LaSRO交替进行DM的微调和替代奖励的在线适应,具体步骤如下:
-
使用微调损失函数和替代奖励模型进行DM的微调。
-
在线适应替代奖励模型,以应对微调过程中输出分布的变化。
通过这种两阶段的设计,LaSRO能够在保持训练稳定性的同时,显著提高两步扩散模型的生成图像质量。
问题3:LaSRO框架如何与基于价值的RL方法建立联系,并从中获得理论支持?
LaSRO框架与基于价值的RL方法建立了联系,主要体现在以下几个方面:
-
目标函数的等价性:LaSRO的TD损失(时间差分损失)在H=2的情况下,可以等价于替代奖励损失,其中替代奖励模型相当于价值函数Q。
-
探索策略:LaSRO通过采样初始噪声进行探索,而不是仅限于基于当前策略的分布,这与基于价值的RL方法中的完全离线探索策略相似。
-
减少梯度噪声:基于价值的RL方法通过学习动作价值函数,能够减少梯度噪声,从而提高方法的鲁棒性和效率。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)