通过LLM中的因果干预实现可控和可解释的文本生成
二进制掩码,是实现干预的参数。作者提出了一种结构因果模型,在以往的大模型结构中,大模型的输入输出往往体现出一定的相关性,而非因果逻辑性。这篇论文只是提出了一种因果机制在大模型具体位置干预大模型输出的理论方法,但是在具体的实现中,人工干预的方法效率不高。新的内生变量: C = {c₁, c₂, ..., cₖ}, 其中每个 cₖ 代表一个要控制的属性(如 c₁=风格, c₂=情感)。属性投影函数,这
Towards Controllable and Explainable Text Generation via Causal Intervention in LLMs
通过LLM中的因果干预实现可控和可解释的文本生成
发布于 MDPI 2025.8.18
论文链接:Towards Controllable and Explainable Text Generation via Causal Intervention in LLMs
暂无代码链接
- 简介
大语言模型在文本生成上虽展现出强大能力,但其“黑盒”特性导致了三大核心挑战:控制不精准、决策过程不透明、以及容易产生事实性幻觉。传统方法如提示工程或解码策略,往往效果不稳定且缺乏理论保证。
为此,本研究提出了一种创新的结构因果干预框架,将因果推理直接嵌入大语言模型的生成过程中。
这属于对大模型输出的优化。
- 方法
本论文的核心是提出一个结构因果干预框架,旨在从模型内部对文本生成过程进行根本性的控制与解释。
该方法主要包含三个关键组成部分:1) 结构因果模型构建、2) 因果干预模块、3) 反事实训练与优化。
- 结构因果模型构建(SCM)
SCM由有向无环图G=(V,E)定义,其中每个节点V对应生成流程中的变量,边E则表示直接因果依赖关系。
一个SCM有三个部分组成:V内生变量、U外生变量(代表外部随机噪声的变量集合)、F结构方程(描述变量间因果关系的函数集合)
内生变量V={X,H,Y}
X:输入序列;Y:输出序列;H:隐藏状态表示
外生变量U={U_H,U_Y}
U_H:影响隐藏状态生成的不可观测随机噪声;
U_Y:影响最终输出生成的不可观测随机噪声。
结构方程F:X → H → Y
· 引入控制属性:为了实现对文本生成属性(如风格、情感)的控制,论文对基础SCM进行了关键性的扩展——引入了属性节点C。
新的内生变量: C = {c₁, c₂, ..., cₖ}, 其中每个 cₖ 代表一个要控制的属性(如 c₁=风格, c₂=情感)。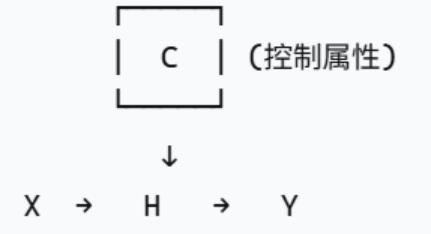
通过将整个生成过程构建为具有明确定义干预措施的SCM系统,我们的模型确保每个
可控属性对输出结果都具有可解释且可验证的影响。基于这一理论基础,我们接下来引入
因果干预模块,该模块在隐藏状态层面将这些路径具体化。
2、因果干预模块
在结构因果模型中,我们定义了 do(cₖ) 这一操作,表示我们强行设置某个属性 cₖ 的值,并观察其如何因果地影响输出。因果干预模块的目标就是在神经网络的隐藏状态上物理地实现这个 do-operator。
公式如下: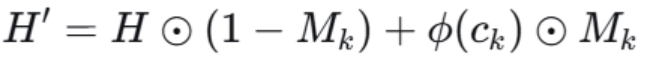
H:原始隐藏状态
Mk:
二进制掩码,是实现干预的参数。它是一个与隐藏状态 H 维度相同的二值向量(0或1),M_k 中的每一个元素对应 H 中的一个隐藏维度。值为 1 的位置表示“这个维度与属性Ck高度相关,需要进行干预”;值为 0 的位置表示“这个维度与 cₖ 无关,必须保持原样”。
研究人员用一个带有标签的小数据集(比如,一些标记了正式/非正式的句子)输入模型。他们通过技术手段(如计算梯度或互信息)来观察,当属性(如风格)变化时,H 中哪些神经元的激活值变化最大。他们选择变化最明显的前10%的神经元,在 Mₖ 中把这些位置初始化为 1。这就给了模型一个很好的起点。
ϕ(Ck):
属性投影函数,这是一个待训练函数(如一个小型神经网络),负责将离散或连续的属性值 cₖ映射到一个与H同维度的属性嵌入向量中。
前半部分:![]()
后半部分:![]()
3、反事实训练和优化
· 目的:
传统模型只学会了关联,没有学会真正的因果。
反事实训练的核心思想是不仅要让模型知道"是什么",更要让模型理解"如果某个属性改变了,输出应该相应地如何变化"。
这通过让模型同时接触事实和反事实样本来实现。
· 反事实样本构造
对于一个给定的输入X和其真实属性配置C(事实),我们通过人为修改一个或多个属性值来创建一个新的属性配置C'(反事实)。
· 复合复合损失函数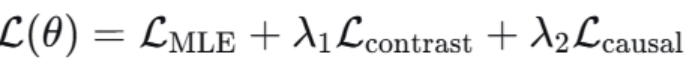
最大似然损失:LMLE
对比损失:Lcontrast
因果一致性损失:Lcausal
- 实验
- 实验目的:
严格评估框架。论文设计了涵盖可控性、可解释性、效率与泛化性的多维度实验。
2、实验设置
· 数据集:
风格控制:GYAFC
情感控制:YelpReviewFull
事实摘要:XSum + FRANK
· 基线方法:
DATG (2024) & Ctrl-G (2024)、RSA-Control (2024)、Magicdec (2024) & JAM (2025)。
· 评估指标:
内容质量:BLEU, ROUGE-L, 困惑度
可控性:属性一致性(%),多属性冲突率(%)
可解释性:因果归因分数(CAS) + 人工评估
3、实验内容
我们在三个任务上评估了可控性表现:风格控制、情感控制、事实摘要。
4、实验结果
评估内容包括以下内容:
- 有效性:在三个任务中,可控性指标全面领先。
2、因果逻辑性:通过自动和人工评估,证实其能提供更可信、更直观的因果解释。
3、低成本性:训练和推理开销显著低于同类因果方法。
4、泛化性:在未知属性、低资源、跨领域组合等挑战性场景下,表现出卓越的鲁棒性。
5、整体性:消融实验证实了SCM、反事实训练、稀疏掩码三个核心组件的不可或缺。
- 思考与启示
在这篇论文中,主要学习的是大模型输出的可控性。
作者提出了一种结构因果模型,在以往的大模型结构中,大模型的输入输出往往体现出一定的相关性,而非因果逻辑性。为了实现大模型输出的可控性,作者构建了因果机制,这使我们可以在模型的具体定位进行干预。
在未来的研究中,我们可以探索以下方向:
这篇论文只是提出了一种因果机制在大模型具体位置干预大模型输出的理论方法,但是在具体的实现中,人工干预的方法效率不高。我们可以探索让大模型自动干预,实现动态因果机制。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)