opencv学习笔记10:残差网络
本文详细介绍了残差网络(ResNet)的核心原理与实现。主要内容包括: 残差网络通过shortcut连接解决深层网络的退化问题,其核心公式H(x)=F(x)+x让网络学习残差而非完整映射 详细解析了残差块的前向传播(传递图像特征)和反向传播(传递梯度)机制 提供了残差块的具体计算实例,说明其增量学习特性 实现了ResNet-18在MNIST数据集上的完整代码,包括: 残差块定义(ResBlock)
目录
残差网络论文地址:https://arxiv.org/abs/1512.03385
<1>. 第 1 层网络计算(x → 第 1 层输出 a1)
<2>. 第 1 层 ReLU 激活(a1 → a1_relu)
<4>. 第 2 层 ReLU 激活(a2 → F (x))
(1)super(ResNet18, self).__init__()
(1)print中的train_loss/(batch_idx+1)
(2) 倒数第四条代码:_, predicted = outputs.max(1)
(4)倒数第二条代码:correct += predicted.eq(targets).sum().item()
残差网络论文地址:https://arxiv.org/abs/1512.03385
一.残差网络感性认识
残差网络( Residual Network ),简称ResNet,
对于resnet残差连接可以用“传话筒”游戏来通俗理解:类似于《王牌》中的传话筒,腾哥在看到了“狗中赤兔”这个词后,形象地演给花花看,花花又演给晓彤看,最后晓彤演给玲姐看,结果玲姐看完一脸懵~。可以看出,“狗中赤兔”在传递过程中信息是不断减少的,腾哥获得了最多的信息,而玲姐获得的最少,这就类似于浅层网络获得的信息多,而深层少,最终深层网络无法理解传来的信息,也就是玲姐猜不出来题。(这一现象称之为“梯度消失”,就是指信息一层层不断减少直至消失)那怎么办呢?为了解决这个问题,腾哥就跳过花花晓彤,单独给玲姐演了一遍,结果玲姐顿悟—“狗中赤兔”!这相当于浅层网络绕开中间网络,把信息直接传给了深层网络,深层网络秒懂。残差连接就是将信息直接传给深层网络,避免了浅层网络对信息的削减。(还有一种“梯度爆炸”现象,是指每一层网络传递的信息越来越多,导致深层网络直接“死机”了)
二.相关专业术语介绍
1.网络退化
网络退化(Network Degradation):当神经网络的层数增加到一定程度后,模型的性能(如分类准确率、回归误差)不仅不再提升,反而出现明显下降(训练误差和测试误差同时增大),深层网络性能反而不如浅层网络的现象。
研究者发现:当网络层数增加到一定程度后,模型性能会不升反降(训练误差和测试误差同时变大)。这种现象不是 “过拟合”(过拟合是训练误差小、测试误差大;就相当于一个学生模拟考试成绩好,但一高考就失利),而是 “网络退化”—— 深层网络的学习能力居然不如浅层网络。
举个例子:假设一个 56 层的网络,理论上它可以包含 20 层网络的所有表达能力(只需让后 36 层学习 “恒等映射”,即输入等于输出)。但实际训练中,56 层网络的性能却不如 20 层,说明网络难以学习到 “恒等映射”。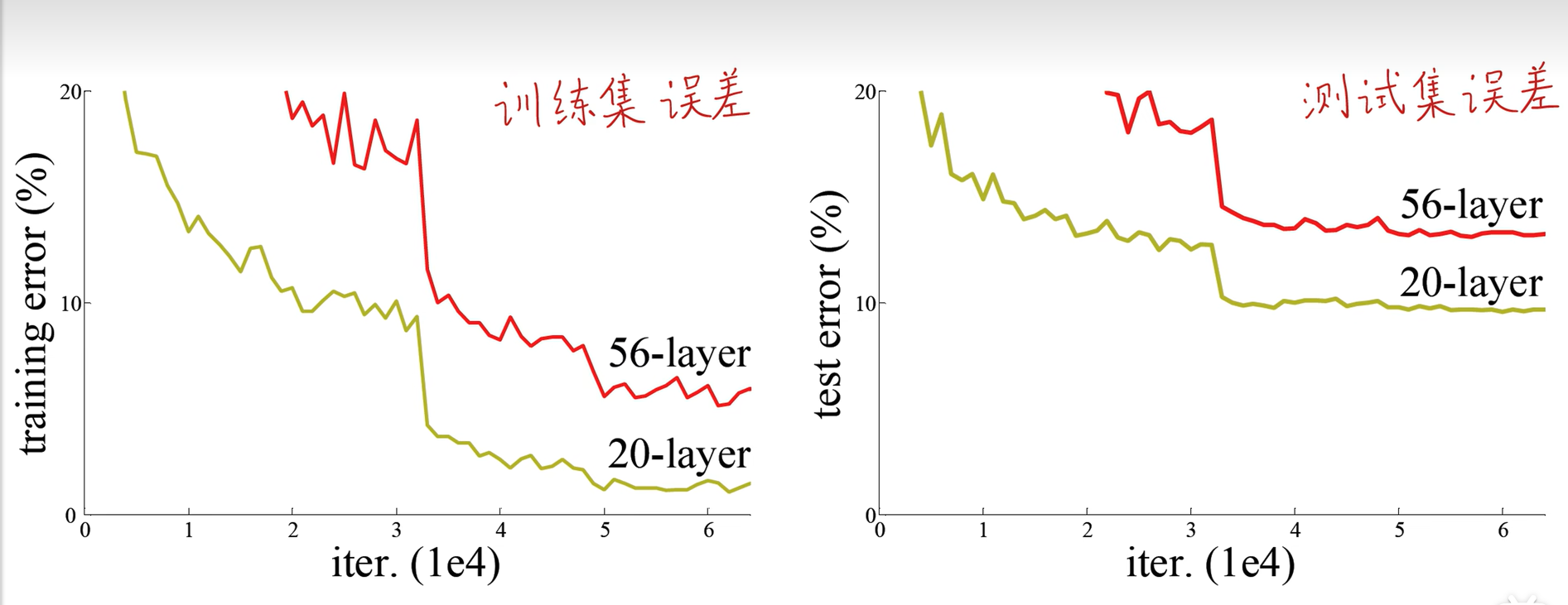
由上图可以看出,56层的神经网络比22层的神经网络在训练集和测试集的准确率都要差得多,也就是所说的退化现象,也就是说如果只是简单的增加网络的深度,可能会导致神经网络模型退化,进而丢失网络前面获取的特征。可以这样想,假如当层数为40层的时候已经达到了最佳的模型,然后继续增加网络的层数,因为激活函数以及卷积等效果,只会增加整体(网络)的非线性,所以效果会变得更差。
2.梯度消失与梯度爆炸
- 梯度消失(Gradient Vanishing):在深层神经网络反向传播训练时,梯度(指导参数更新的 “修正信号”)从输出层向输入层传递过程中,因不断乘以小于 1 的权重(如激活函数导数、卷积核参数),导致数值逐渐趋近于 0 的现象。
- 传统深层网络中,梯度要从最后一层(输出层)反向传播到第一层(输入层)。每经过一层,梯度都会乘以一个小于 1 的权重(比如激活函数的导数)。经过几十、上百层后,梯度会变成一个极小的数(比如 0.9^100≈2.65e-5),几乎等于 0。
- 梯度爆炸与梯度消失相对,它是在反向传播时,梯度从输出层向输入层传递过程中,数值急剧增大的现象。激活函数导数大于 1(如未做归一化的 ReLU),或权重初始化过大,多层叠加后梯度 “失控”。
残差网络主要解决了深层神经网络的退化问题、以及梯度消失与梯度爆炸。
3.残差和误差
在统计学中,残差和误差是非常容易混淆的两个概念。误差是衡量观测值和真实值之间的差距,残差是指预测值和观测值之间的差距。
4.残差块
一个残差块的数学模型如下图所示,残差网络和之前的网络最大的不同之处就是多了一条自身的捷径分支shortcut(捷径连接 / 短路连接),正是因为这一个分支的存在,使得网络在反向传播的时候,损失可以通过这条捷径将梯度直接传向更前的网络,从而减缓网络退化问题,我们前边了解到梯度之间具有相关性的。我们在有个梯度相关性这个指标之后,作者分析了许多的结构和激活函数,发现了正是我们这个网络在保持梯度相关性上是很强的,除了这一点之外,残差网络并没有增加新的参数,只是多了一步加法,计算量相对而言也没有增加。
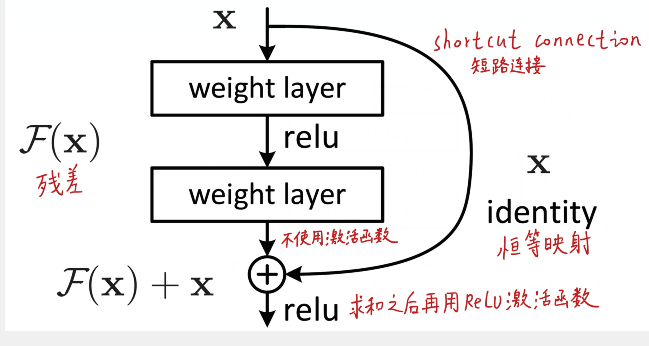
(1)残差网络核心公式
H(x)=F(x)+x
- x:残差块的输入特征
- F(x):残差函数(由残差块内的卷积、BN、激活等层组成的变换)
- H(x):残差块的输出特征
- 公式含义:残差块的输出 = 残差变换结果 + 原始输入(shortcut 连接)
从学习目标角度,公式可改写为:F(x)=H(x)−x
这表明残差网络不直接学习完整的映射 H(x),而是学习输入与输出的残差F(x),大幅降低了学习难度,同时通过 shortcut 让梯度直接回传,解决深层网络的梯度消失问题。
(2)残差块传的到底是梯度还是图像特征啊?
残差块同时传递图像特征(前向传播)和梯度(反向传播),两者在不同的传播方向中承担不同角色,总结就是:
- 前向传特征(加工并增强输入信息);
- 反向传梯度(保障深层参数的有效更新)。这种双向设计是残差网络解决深层退化问题的核心。
<1> 前向传播:传递图像特征
在模型从输入到输出的前向计算中,残差块传递的是图像的特征表示(可以理解为经过抽象的 “像素信息”,而非原始像素):
- 输入 x 是某一层的特征图(如卷积后的纹理、形状特征);
- 经过 “weight layer → ReLU → weight layer” 后,得到残差特征 F(x)(对输入特征的增量优化);
- 最终输出 F(x)+x 是 “原始特征 + 优化特征” 的组合,用于后续层的特征提取或分类。
<2> 反向传播:传递梯度
在计算损失并更新参数的反向传播中,残差块传递的是梯度(用于调整网络参数的 “修正信号”):
- 损失函数的梯度会从输出层向输入层回传;
- shortcut 连接让梯度可以直接跨层传递,避免了传统网络因多层叠加导致的梯度消失 / 爆炸;
- 残差结构的梯度计算更高效,让深层网络的参数也能有效更新。
(3)shortcut的“低成本保留” 优势
- 传统网络(如 VGG、AlexNet)是 **“层叠式加工”** 逻辑:输入 x 经过第一层卷积→ReLU→第二层卷积→ReLU→…→输出 H(x)。它要保存原始输入信息,必须让每一层的变换 “恰好不破坏关键信息”—— 这需要网络通过海量参数学习 “如何在复杂变换中保留有效特征”,但深层网络中这种学习难度极高,很容易因 “过度加工” 丢失原始信息,最终导致退化。
- 而shortcut 连接是显式地、无代价地把原始输入 x 加到深层输出中,网络不需要 “费力学习如何保留信息”,只需专注于学习 “增量残差F(x)”。这种设计的核心是把 “保留信息” 从 “需要学习的任务” 变成了 “直接赋予的条件”——直接让增量x设置为0,即使深层网络学不到有效特征,至少能通过 shortcut 把浅层的有效信息 “搬” 到深层,避免信息断层。
5.残差块计算实例
(1)先明确实例设定
- 任务:简化的图像特征处理(输入 x 是 1 个像素点的特征值,实际是矩阵,这里用单个数值简化)
- 残差块结构:2 层简单全连接层(对应 weight layer)+ ReLU 激活(简化为 “小于 0 则取 0,大于 0 则不变”)
- 已知参数(训练好的权重 / 偏置,实际是训练学习的,这里直接给固定值方便计算):
- 第 1 层权重 W1=0.2,偏置 b1=1
- 第 2 层权重 W2=0.5,偏置 b2=0.5
- 输入 x:5(对应一张图像某个位置的像素特征值)
(2)F (x) 的完整计算过程(一步都不跳)
F (x) 是残差块内部 2 层网络的输出,计算流程:x → 第1层网络 → ReLU → 第2层网络 → ReLU → 输出F(x)
<1>. 第 1 层网络计算(x → 第 1 层输出 a1)
公式:a1 = x × W1 + b1(全连接层基本计算:输入 × 权重 + 偏置)代入数值:a1 = 5 × 0.2 + 1 = 1 + 1 = 2
<2>. 第 1 层 ReLU 激活(a1 → a1_relu)
ReLU 规则:如果数值 > 0,保持不变;≤0 则取 0计算:a1=2>0 → a1_relu = 2
<3>. 第 2 层网络计算(a1_relu → a2)
公式:a2 = a1_relu × W2 + b2代入数值:a2 = 2 × 0.5 + 0.5 = 1 + 0.5 = 1.5
<4>. 第 2 层 ReLU 激活(a2 → F (x))
ReLU 规则同上:a2=1.5>0 → 最终 F (x) = 1.5
(3)最终输出(F (x)+x)
残差块的最终输出是 “残差 F (x) + 原始输入 x”:输出 = F (x) + x = 1.5 + 5 = 6.5
(4)关键说明(对应你的核心疑问)
- F (x) 确实是 “跑一遍网络层” 得到的:从 x=5 开始,依次经过 2 层权重层 + ReLU,最终算出 F (x)=1.5,和你理解的 “跑一遍” 完全一致。
- F (x) 的本质的是 “增量变化”:这里目标映射 H (x) 其实就是残差块的最终输出 6.5(H (x)=6.5),而 F (x)=H (x)-x=6.5-5=1.5—— 刚好是网络学到的 “增量”,这就是 “残差” 的由来!
- 和传统网络的区别(核心!):
- 传统网络:这 2 层要直接学 “x=5→H (x)=6.5” 的映射,相当于硬记 “5 变 6.5”;
- 残差网络:这 2 层只学 “x=5→F (x)=1.5” 的增量,再通过 shortcut 加回 x,难度大幅降低(学 “加 1.5” 比学 “5→6.5” 简单多了)。
(5)再补一个 “极端简单情况”(更直观)
如果网络需要学 “恒等映射”(即 H (x)=x,输出 = 输入):
- 理想 F (x)=H (x)-x=0
- 此时网络只需把权重调小(比如 W1=0,W2=0),计算过程:a1=5×0+1=1 → ReLU=1;a2=1×0+0.5=0.5 → ReLU=0.5(接近 0)
- 就算没完全到 0,也比传统网络 “硬学 5→5” 容易太多,不会出现退化。
三.代码详解
1.数据集切片
由于ResNet-18参数众多,计算量是简单 CNN 的几十倍,那我这里就跑一轮训练吧,然后我还要把MNIST数据集切片,让样本数量减少,加快时间,这样跑一轮都得5分钟
MNIST 数据集对象不支持直接切片(如[:10000])train_dataset=full_train_dataset[:10000]❌️、test_dataset=full_test_dataset[:2000]❌️,torchvision的数据集类需要用专门的工具subset来进行子集采样。
先:from torch.utils.data import Subset
再train_dataset = Subset(full_train_dataset, range(10000)) # 前10000个样本
test_dataset = Subset(full_test_dataset, range(2000)) # 前2000个样本
from torch.utils.data import Subset
full_train_dataset = datasets.MNIST(root='./data/mnist', train=True, download=False, transform=transform)
full_test_dataset = datasets.MNIST(root='./data/mnist', train=False, download=False, transform=transform)
# 创建子集(使用Subset工具)
train_dataset = Subset(full_train_dataset, range(10000)) # 前10000个样本
test_dataset = Subset(full_test_dataset, range(2000)) # 前2000个样本2.定义残差块
(1)super(ResNet18, self).__init__()
super() 可以调用 nn.Module 类的 __init__ 方法,从而完成父类的初始化操作,确保 ResNet18 类能正确继承 nn.Module 的所有基础功能。
ResNet18:表示当前类(即要调用父类方法的子类)。self:表示当前类的实例(即当前ResNet18类的对象)。
# 1. 定义残差块
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1): #构造函数
super(ResBlock, self).__init__() #调用父类nn.Module的构造函数初始化
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
#定义第一个卷积层。padding填充一圈0像素;
#bias=False:不使用偏置(后续有批归一化,偏置会被 BN 层抵消,无需额外设置)。
self.bn1 = nn.BatchNorm2d(out_channels) #归一化,让特征分布更稳定、更合理
self.relu = nn.ReLU(inplace=True)
#激活,inplace=True:原地激活(直接修改输入张量,不创建新张量,节省内存)。
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False) #第二个卷积层
self.bn2 = nn.BatchNorm2d(out_channels) #归一化
self.shortcut = nn.Sequential() #初始化捷径连接(残差连接),默认是空的Sequential容器(无任何操作)。
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
#当stride=1且in_channels=out_channels:shortcut 是空 Sequential(直接返回 x,真正的恒等映射)。
#当尺寸 / 通道不匹配:用 1×1 卷积调整通道数和尺寸,保证形状匹配后相加。
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) #残差网络公式就是H(x)=F(x)+x
out = self.relu(out)
return out(2)为什么 先归一化、再激活
conv → bn → relu 是现代 CNN 的标准顺序(称为pre-activation变体),相比传统的conv → relu → bn,这种顺序能让梯度传播更顺畅,缓解梯度消失。
先 ReLU 再 BN可以吗?:不建议。如果先 ReLU,输出值都非负,会破坏 BN 需要的对称分布,降低归一化效果。别管了,你就先记住顺序吧:conv1 → bn → relu → conv2 → bn2 → +shortcut
(3)残差块为什么没有池化 / 全连接?
- 不建议将池化 / 全连接放进残差块,池化层:残差块中已有
stride>1的卷积实现下采样(替代池化),若再加入池化会导致特征图尺寸过度缩小,信息丢失严重。 - 全连接层:全连接层会将特征展平为一维,破坏残差块的空间特征结构,且无法与 shortcut 的二维特征相加(形状不匹配)。
- 后果:模型会失去残差连接的优势,梯度传播受阻,性能大幅下降。
- 残差块专注于特征提取,池化由步长 > 1 的卷积实现(stride=2 时特征图尺寸减半),全连接层放在整个网络的最后(ResNet18 的
self.fc)。
3.定义resnet-18
- 为什么单独定义一个第一层卷积层?为什么不直接make_layer?
- 第一层卷积是stem 层,负责将输入(MNIST 的 1 通道)映射到 64 通道,是网络的起始层。
_make_layer用于创建残差块组成的 layer,不适合做初始层(初始层无残差连接)。
- 第一层卷积是stem 层,负责将输入(MNIST 的 1 通道)映射到 64 通道,是网络的起始层。
- ResNet-18名字由来:ResNet-18 的层数是 18 层可训练层:
- 1 层初始卷积 + 4 个 layer(每个 layer 含 2 个残差块,每个残差块含 2 层卷积) + 1 层全连接 → 1 + 4×2×2 + 1 = 18 层。
- 4 个残差层:是 ResNet 的标准设计,每层通道数翻倍(64→128→256→512),尺寸减半(通过 stride=2),逐步提取更高维的特征。
- 前向传播顺序:遵循
初始卷积 → 残差层1 → 残差层2 → 残差层3 → 残差层4 → 全局池化 → 全连接的经典 CNN 特征提取流程。
4.训练中的注意点
def train(epoch): #定义训练函数,执行一轮 epoch 的训练
model.train() #将模型设为训练模式
train_loss = 0 #初始化训练损失累加变量,用于计算本轮 epoch 的平均损失。
correct = 0 #初始化正确预测数累加变量,用于计算本轮 epoch 的准确率。
total = 0 #初始化总样本数累加变量,用于计算准确率分母。
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device) #将输入和标签张量移到指定设备(GPU/CPU),与模型参数设备一致。
#把输入数据和标签从 CPU 转移到指定的计算设备(比如 GPU)上,具体解释如下:
#inputs.to(device):将inputs(模型的输入数据,比如图片张量)移动到device对应的硬件(如果device是 GPU,就从 CPU 转存到 GPU 显存)。
#targets.to(device):同理,将targets(输入对应的标签,比如分类任务的类别)也移动到同一个device。
#赋值给原变量inputs, targets:覆盖原来在 CPU 上的数据,后续模型计算都用 GPU 上的张量。
optimizer.zero_grad() #清空优化器的梯度(PyTorch 梯度默认累积,若不清空会导致梯度叠加)。
outputs = model(inputs) #前向传播,将输入传入模型,得到输出(类别得分)
loss = criterion(outputs, targets) #计算损失(交叉熵损失)。
loss.backward() #反向传播,计算模型参数的梯度(从损失函数向输入方向求导)。
optimizer.step() #更新模型参数(根据计算出的梯度和优化器规则)。
train_loss += loss.item() #累加损失值(loss.item()获取张量的 Python 数值,避免计算图累积)
_, predicted = outputs.max(1) #获取预测类别(取类别得分最大的索引)。作用同CNN里的argmax
total += targets.size(0) #累加总样本数(targets.size(0)是当前批次的样本数,如 128)
correct += predicted.eq(targets).sum().item() #累加正确预测数。
print(f'Epoch: {epoch}, Loss: {train_loss/(batch_idx+1):.3f}, Acc: {100.*correct/total:.3f}%')
(1)print中的train_loss/(batch_idx+1)
train_loss是累加了所有批次的损失值总和。loss本来就是每个批次中所有图片的损失的平均值,则所有批次的损失相加再除批次数就是所有批次的平均损失值。batch_idx是从 0 开始计数的批次索引,batch_idx+1就是实际的总批次数。- 平均损失公式:
总损失值 / 批次数 = 平均损失。
例如:
- 批次 1 损失:2.0
- 批次 2 损失:1.5
- 批次 3 损失:1.0
总损失 = 2.0 + 1.5 + 1.0 = 4.5批次数 = 3平均损失 = 4.5 / 3 = 1.5
这个 1.5 就是每个批次的平均损失,它反映了训练过程中模型在整体数据上的平均表现。
(2) 倒数第四条代码:_, predicted = outputs.max(1)
_,丢弃变量,表明:我只关心第二个返回值,第一个值我不需要,用下划线_来接收并忽略它。outputs.max(1)返回两个张量:- 最大值张量:形状
(1000,),每个元素是对应样本的最大概率值(原始得分),返回原始得分,没用的东西,我们用_,忽略它。 - 索引张量:形状
(1000,),和 argmax 结果完全相同
- 最大值张量:形状
- argmax(1):
- 返回形状:
(1000,) - 每个元素是对应样本预测概率最大的类别索引(0-9 之间的整数)
- 例如:
[3, 7, 1, ...]
- 返回形状:
- 这里的
max(1)是在维度 1(即类别维度)上找最大值,返回的索引就对应预测的类别,效果等同于argmax(1)。 - 区别:
max()返回值 + 索引,argmax()只返回索引。在分类任务中,两者在获取预测类别时效果一致。
(3)total += targets.size(0)
累加总样本数(targets.size(0)是当前批次的样本数,如 128)
用于后面print中的correct/total:.3f算正确率,
残差网络(ResNet)用于 MNIST 分类,整个数据集是跑不动的,因为ResNet-18参数众多,计算量是简单 CNN 的几十倍,我需要对它缩减样本,并且只训练一轮,真正跑时候range(20)改成range(1)
(4)倒数第二条代码:correct += predicted.eq(targets).sum().item()
predicted:模型预测的类别索引(形状如[batch_size]的张量).eq(targets):是 PyTorch 张量的方法,全称是 "equal",用于逐元素比较两个张量是否相等,这里比较predicted和targets这两个张量的逐元素值是否相等,形状都是[128]- sum():对布尔张量中的
True值进行求和(True会被当作 1,False当作 0) item():将标量张量转换为 Python 原生的数值类型(如 int 或 float)
(5)batch_idx 作用域问题
batch_idx 虽然是 for 循环里的局部变量,看似print不在作用域无法使用batch_idx,但Python 中,循环变量在循环结束后并不会立即销毁,而是会保留最后一次迭代的值,因此 print 语句可以正常使用。
代码历程
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.data import Subset
# 1. 定义残差块
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1): #构造函数
super(ResBlock, self).__init__() #调用父类nn.Module的构造函数初始化
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
#定义第一个卷积层。padding填充一圈0像素;
#bias=False:不使用偏置(后续有批归一化,偏置会被 BN 层抵消,无需额外设置)。
self.bn1 = nn.BatchNorm2d(out_channels) #归一化,让特征分布更稳定、更合理
self.relu = nn.ReLU(inplace=True)
#激活,inplace=True:原地激活(直接修改输入张量,不创建新张量,节省内存)。
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False) #第二个卷积层
self.bn2 = nn.BatchNorm2d(out_channels) #归一化
self.shortcut = nn.Sequential() #初始化捷径连接(残差连接),默认是空的Sequential容器(无任何操作)。
#空 Sequential 调用shortcut(x) 时会直接返回输入(x),相当于恒等映射
if stride != 1 or in_channels != out_channels:
#这两个条件用于判断是否需要用 1×1 卷积调整 shortcut 的形状,确保能与主路径输出相加。
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
#当stride=1且in_channels=out_channels:shortcut 是空 Sequential(直接返回 x,真正的恒等映射)。
#当尺寸 / 通道不匹配:用 1×1 卷积调整通道数和尺寸,保证形状匹配后相加。
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) #残差网络公式就是H(x)=F(x)+x
out = self.relu(out)
return out
# 2. 定义ResNet-18(适配MNIST)
class ResNet18(nn.Module):
def __init__(self, num_classes=10): #num_classes=10:分类任务的类别数
super(ResNet18, self).__init__()
#in_channels当前输入到残差层的通道数(初始为 64,与初始卷积层的输出通道一致)
self.in_channels = 64
self.conv1 = nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(64, 2, stride=1)
self.layer2 = self._make_layer(128, 2, stride=2)
self.layer3 = self._make_layer(256, 2, stride=2)
self.layer4 = self._make_layer(512, 2, stride=1)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
#自适应平均池化,不管输入尺寸是多少,输出固定为 1×1(每个通道只保留一个值)。
#例如输入是 7×7,会计算整个 7×7 区域的平均值得到 1×1 输出;如果是 14×14,也计算全局平均。
#比固定池化核更灵活,适配不同输入尺寸。
self.fc = nn.Linear(512, num_classes)
#构建残差层,批量创建残差块并堆叠:
def _make_layer(self, out_channels, num_blocks, stride):
#num_blocks:表示当前 layer 包含的残差块数量。ResNet-18 的每个 layer 有 2 个残差块,所以num_blocks=2。
strides = [stride] + [1] * (num_blocks - 1)
#第一个残差块用指定的 stride(可能 = 2,用于下采样)。下面是列表拼接
#后续残差块用 stride=1(保持尺寸不变)。
#例如num_blocks=2, stride=2 → strides=[2] + [1]=[2,1]
layers = [] #初始化空列表layers,用于存储残差块实例。
for stride in strides: #strides是一个列表,stride是循环变量名,依次取列表中的每个元素。
layers.append(ResBlock(self.in_channels, out_channels, stride))
#self是隐藏的,无需显式传入
#更新全局输入通道数为当前残差块的输出通道数
#即更新下一个残差块的输入通道数让它等于当前残差块的输出通道数。
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
# 3. 数据加载与预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
full_train_dataset = datasets.MNIST(root='./data/mnist', train=True, download=False, transform=transform)
full_test_dataset = datasets.MNIST(root='./data/mnist', train=False, download=False, transform=transform)
# 创建子集(使用Subset工具)
train_dataset = Subset(full_train_dataset, range(10000)) # 前10000个样本
test_dataset = Subset(full_test_dataset, range(2000)) # 前2000个样本
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False)
# 4. 模型初始化与训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet18().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), weight_decay=5e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
#StepLR 是一种等间隔调整学习率的策略,
#optimizer:指定要调整学习率的优化器对象。
#step_size:设置学习率衰减的周期(每隔多少个 epoch,这里隔10个echo学习率就会按照 gamma 指定的比例进行调整更新一次)。
#gamma:设置学习率衰减的比例因子,当达到 step_size 指定的周期时,当前的学习率会乘以 gamma。
def train(epoch): #定义训练函数,执行一轮 epoch 的训练
model.train() #将模型设为训练模式
train_loss = 0 #初始化训练损失累加变量,用于计算本轮 epoch 的平均损失。
correct = 0 #初始化正确预测数累加变量,用于计算本轮 epoch 的准确率。
total = 0 #初始化总样本数累加变量,用于计算准确率分母。
for batch_idx, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device) #将输入和标签张量移到指定设备(GPU/CPU),与模型参数设备一致。
#把输入数据和标签从 CPU 转移到指定的计算设备(比如 GPU)上,具体解释如下:
#inputs.to(device):将inputs(模型的输入数据,比如图片张量)移动到device对应的硬件(如果device是 GPU,就从 CPU 转存到 GPU 显存)。
#targets.to(device):同理,将targets(输入对应的标签,比如分类任务的类别)也移动到同一个device。
#赋值给原变量inputs, targets:覆盖原来在 CPU 上的数据,后续模型计算都用 GPU 上的张量。
optimizer.zero_grad() #清空优化器的梯度(PyTorch 梯度默认累积,若不清空会导致梯度叠加)。
outputs = model(inputs) #前向传播,将输入传入模型,得到输出(类别得分)
loss = criterion(outputs, targets) #计算损失(交叉熵损失)。
loss.backward() #反向传播,计算模型参数的梯度(从损失函数向输入方向求导)。
optimizer.step() #更新模型参数(根据计算出的梯度和优化器规则)。
train_loss += loss.item() #累加损失值(loss.item()获取张量的 Python 数值,避免计算图累积)
_, predicted = outputs.max(1) #获取预测类别(取类别得分最大的索引)。同CNN里的argmax
total += targets.size(0) #(targets.size(0)是当前批次的样本数,如 128)累加总样本数
correct += predicted.eq(targets).sum().item() #累加正确预测数。
print(f'Epoch: {epoch}, Loss: {train_loss/(batch_idx+1):.3f}, Acc: {100.*correct/total:.3f}%')
def test():
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(test_loader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(f'Test Loss: {test_loss/(batch_idx+1):.3f}, Test Acc: {100.*correct/total:.3f}%')
# 训练
for epoch in range(1):
train(epoch)
test()
scheduler.step()四.简介完整代码
下面的代码是可以正常运行的,上面的只是历程,有些小问题没改。注:要卸载 CPU 版 PyTorch,重新安装支持 CUDA 的pytorch版本,大概2.8G,要不然跑不动
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import Subset
from torch.utils.data import DataLoader
import time
start_time = time.perf_counter()
#0.计时器,打印运行时间
def over_timer(start_time):
over = time.perf_counter() - start_time
print(f"已运行:{over:.2f}秒", end="\n")
# 1.定义残差块
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = self.relu(out)
return out
# 2.定义ResNet-18
over_timer(start_time)
class ResNet18(nn.Module):
def __init__(self, num_classes=10):
super(ResNet18, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(1,64,kernel_size=3,stride=1,padding=1,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(64, 2, stride=1)
self.layer2 = self._make_layer(128, 2, stride=2)
self.layer3 = self._make_layer(256, 2, stride=2)
self.layer4 = self._make_layer(512, 2, stride=1)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(ResBlock(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
over_timer(start_time)
# 3.数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
full_train_dataset = datasets.MNIST(root='./data/mnist', train=True, download=False, transform=transform)
full_test_dataset = datasets.MNIST(root='./data/mnist', train=False, download=False, transform=transform)
train_dataset = Subset(full_train_dataset, range(10000))
test_dataset = Subset(full_test_dataset, range(2000))
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False)
# 4.模型初始化与训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet18().to(device) # 构建神经网络
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999)) # 优化器,用于更新权重等
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
over_timer(start_time)
def train(epoch):
model.train()
train_loss = 0
total = 0
correct = 0
count = 0
for batch_idx, (inputs, targets) in enumerate(train_loader):
count += 1
print("train", count)
over_timer(start_time)
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(f'Epoch:{epoch},Loss:{train_loss / (batch_idx + 1):.3f},Acc:{100. * correct / total:.3f}%')
def test():
model.eval()
test_loss = 0
total = 0
correct = 0
count = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(test_loader):
count += 1
print("test", count)
over_timer(start_time)
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(f'Test Loss:{(test_loss / (batch_idx + 1)):.3f},Test Acc:{100. * correct / total:.3f}%')
for epoch in range(1):
train(epoch)
test()
scheduler.step()
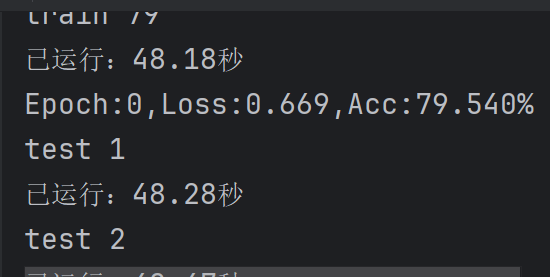
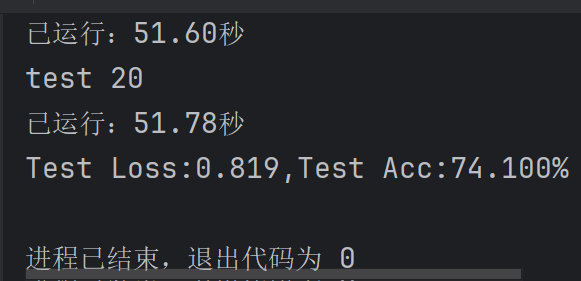
输出打印结果:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)