基于Python的新闻舆情监测与智能分析系统毕设
在社会应用层面,本系统的意义更为直接和深远。通过对文本进行精准的分词、去噪、实体识别等预处理,并利用先进的文本表示模型(如Word2Vec、BERT)进行特征提取,进而构建高精度的情感分类模型(如LSTM、CNN或Transformer),以自动判别新闻所蕴含的情感极性(正面、负面、中性)及其强度,并实现关键主题的自动聚类与演化追踪。当前共识是,基于大模型的微调是达到最佳性能的实用路径,而如何实现
研究内容
-
数据收集:利用Scrapy、Requests等Python库构建分布式网络爬虫,抓取新闻网站的新闻标题、正文、发布时间、来源、评论等数据。
-
数据预处理:
-
分词处理:使用Jieba、HanLP等中文分词工具进行精准分词,并去除停用词。
-
文本清洗:去除HTML标签、特殊字符、无关广告文本等。
-
特征提取:采用TF-IDF、Word2Vec或BERT等模型将文本转化为数值向量。
-
-
模型训练:
-
情感分析模型:基于预处理后的数据,训练LSTM、CNN或微调BERT分类模型,实现正面、负面、中性三分类。
-
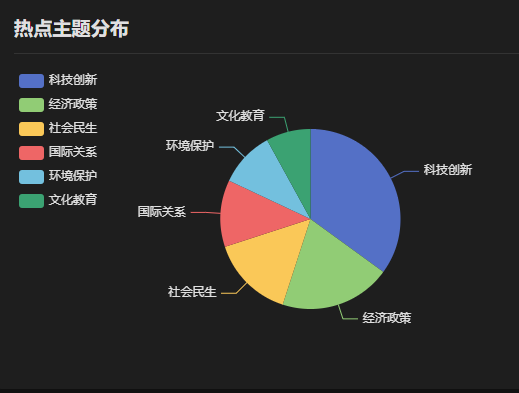
主题聚类模型:利用LDA、TextRank或聚类算法(如K-Means)自动发现新闻中的热点主题。
-
-
系统开发:采用Flask构建RESTful API后端,Vue构建前后端分离的前端界面,并使用ECharts.js进行数据可视化。
需求分析
-
用户需求:
-
政府/企业宣传部门:需要实时掌握与自身相关的舆论动态,了解公众情绪,及时发现负面舆情以进行预警和应对。
-
市场/品牌分析师:需要追踪竞品动态、行业趋势和品牌声誉,生成分析报告以支持决策。
-
社会研究人员:需要长期、宏观地观察社会舆论的变迁规律和热点分布。
-
系统管理员:需要管理用户权限、监控爬虫运行状态、管理数据源和系统配置。
-
-
功能需求:
-
多源新闻采集:支持配置化添加新闻源,实现7x24小时自动化采集与更新。
-
数据存储与管理:对采集的原始新闻和预处理后的数据进行结构化存储和管理。
-
智能舆情分析:自动执行情感分析、主题聚类、关键词提取等核心分析任务。
-
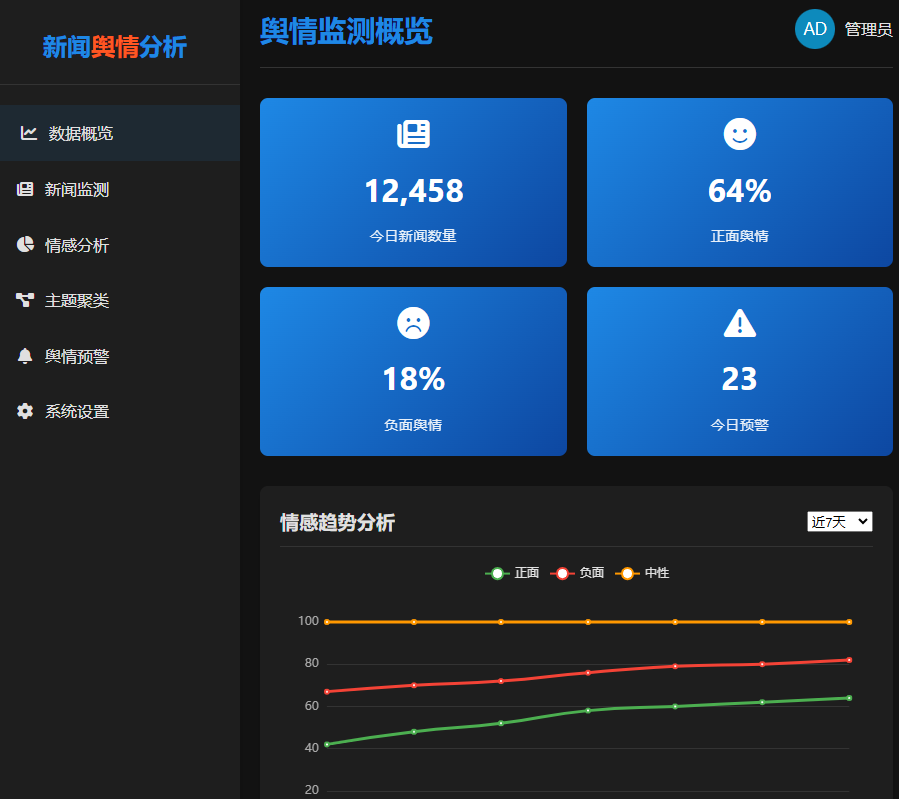
多维数据可视化:通过仪表盘、趋势图、词云、地理信息图等形式直观展示分析结果。
-
舆情预警与报告:设定预警规则(如负面情感阈值),自动触发警报,并支持一键生成舆情日报、周报。
-
用户与系统管理:实现用户角色权限管理、系统日志记录、数据备份等功能。
-
可行性分析
-
经济可行性:本项目主要采用开源技术和工具(Python、Flask、Vue、MySQL等),开发成本极低。硬件方面,初期可使用中等配置的服务器进行部署,投入可控。系统建成后,能极大节省人工监测舆情的成本,并为决策提供支持,潜在经济收益高,具备良好的经济可行性。
-
社会可行性:该系统响应了国家关于加强网络社会治理、提升舆情引导能力的号召。它为政府和企业提供了科学的管理工具,有助于维护社会稳定和品牌形象,具有积极的社会效益。在数据使用上,只要严格遵守相关法律法规,尊重数据版权,其社会接受度和合法性是有保障的。
-
技术可行性:Python在数据爬取、处理和机器学习领域拥有成熟的生态(Scrapy, Pandas, Scikit-learn, Transformers)。Flask和Vue是轻量级且高效的前后端开发框架。ECharts是强大的可视化库。整个技术栈经过大量项目验证,社区活跃,资料丰富,从技术层面实现该系统是完全可行的。
功能分析
根据需求,系统主要分为以下功能模块:
-
数据采集模块:爬虫调度、新闻源管理、数据去重、增量抓取。
-
数据处理模块:文本清洗、中文分词、情感分析、主题聚类、实体识别。
-
数据可视化模块:
-
舆情概览仪表盘(情感分布、热点新闻、数据总量)。
-
情感趋势分析(按时间线展示情感变化)。
-
主题演化分析(展示不同时间段的热点主题)。
-
关键词词云与排行榜。
-
新闻列表与详情查看。
-
-
预警报告模块:预警规则设置、预警信息推送、分析报告生成与导出。
-
系统管理模块:用户管理、角色权限、操作日志、系统配置。
数据库设计
数据库表结构
1. 新闻源表 (news_source)
| 字段名 (英语) | 说明 (中文) | 大小 | 类型 | 主外键 | 备注 |
|---|---|---|---|---|---|
| source_id | 源ID | INT | 主键 | 自增 | |
| source_name | 源名称 | 100 | VARCHAR(100) | 如:人民网 | |
| source_url | 源网址 | 255 | VARCHAR(255) | 主页URL | |
| crawler_config | 爬虫配置 | JSON/TEXT | 存放选择器、请求头等配置 | ||
| is_active | 是否启用 | BOOLEAN | 默认TRUE | ||
| created_at | 创建时间 | DATETIME | 默认当前时间 |
2. 新闻数据表 (news_article)
| 字段名 (英语) | 说明 (中文) | 大小 | 类型 | 主外键 | 备注 |
|---|---|---|---|---|---|
| article_id | 文章ID | BIGINT | 主键 | 自增 | |
| source_id | 新闻源ID | INT | 外键 | 关联 news_source.source_id | |
| title | 新闻标题 | 500 | VARCHAR(500) | ||
| content | 新闻正文 | LONGTEXT | |||
| publish_time | 发布时间 | DATETIME | |||
| url | 原文链接 | 500 | VARCHAR(500) | 唯一索引 | |
| author | 作者 | 100 | VARCHAR(100) | ||
| keywords | 系统提取关键词 | JSON/TEXT | 存储分析得到的关键词列表 | ||
| created_at | 入库时间 | DATETIME | 默认当前时间,建立索引 |
3. 情感分析结果表 (sentiment_analysis)
| 字段名 (英语) | 说明 (中文) | 大小 | 类型 | 主外键 | 备注 |
|---|---|---|---|---|---|
| analysis_id | 分析ID | BIGINT | 主键 | 自增 | |
| article_id | 文章ID | BIGINT | 外键 | 关联 news_article.article_id,唯一索引 | |
| sentiment_label | 情感标签 | 10 | VARCHAR(10) | 'positive', 'negative', 'neutral' | |
| sentiment_score | 情感得分 | FLOAT | 例如,0.95 (非常正面), -0.8 (非常负面) | ||
| analyzed_at | 分析时间 | DATETIME | 默认当前时间 |
4. 主题聚类结果表 (topic_cluster)
| 字段名 (英语) | 说明 (中文) | 大小 | 类型 | 主外键 | 备注 |
|---|---|---|---|---|---|
| topic_id | 主题ID | INT | 主键 | 自增 | |
| topic_name | 主题名称 | 200 | VARCHAR(200) | 由系统生成或人工标注 | |
| top_keywords | 主题关键词 | JSON/TEXT | 存储该主题下权重最高的关键词 | ||
| start_time | 起始时间 | DATETIME | 该主题开始出现的时间 | ||
| end_time | 结束时间 | DATETIME | 该主题热度消退的时间 |
5. 文章-主题关联表 (article_topic)
| 字段名 (英语) | 说明 (中文) | 大小 | 类型 | 主外键 | 备注 |
|---|---|---|---|---|---|
| id | 关联ID | BIGINT | 主键 | 自增 | |
| article_id | 文章ID | BIGINT | 外键 (联合主键之一) | 关联 news_article.article_id | |
| topic_id | 主题ID | INT | 外键 (联合主键之一) | 关联 topic_cluster.topic_id | |
| weight | 关联权重 | FLOAT | 表示该文章属于该主题的概率或强度,0-1之间 |

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)