【收藏必学】Prophet+Transformer超强组合:200个算法模型助你精通时序预测
文章详细介绍了将Prophet与Transformer结合用于时序预测的三种方法:残差建模、特征增强和端到端可微联合训练。Prophet擅长捕捉长期趋势、周期和节假日效应,而Transformer处理复杂短期波动和长程依赖。通过案例展示了残差建模的具体实现,包括数据准备、Prophet拟合、残差计算和Transformer训练,最后提供了算法优化和调参建议,帮助提升预测精度。
前言
在时间序列的社群里,大家提到了Transformer结合Prophet时序预测,无论是在实际的使用中,或者论文中,也有同学进行了调整进而使用。
简单的来说,把 Prophet 当成“可解释的基线”去抓长期趋势、周期和节假日效应。
把 Transformer 当成“强大的非线性残差/上下文学习器”去补足 Prophet 没能拟合的复杂短期、交互和长程依赖。
常见做法有三种:
第一种,残差建模(两阶段)
第二种,特征增强(把 Prophet 的分量当输入)
第三种,端到端可微联合训练
核心原理
1) Prophet
Prophet 用可解释的组件把时间序列拆开,长期趋势 + 周期(如年/周/日)+ 节假日效应 + 随机噪声。
优点是大家容易解释、对缺失/不规则采样/节假日友好、对趋势突变(changepoints)有专门处理。
数学上,Prophet 的基本分解:
-
:趋势(常用 piecewise linear 或 logistic growth),Piecewise linear(有 changepoints )写成:
其中 是基础斜率/截距, 是第 个 changepoint 对斜率的调整。
-
:季节项,常用傅里叶展开(周期 ):
-
:节假日等指示回归项( 为 indicator)。
Prophet 还能给出拟合不确定性(MCMC 或近似)。
Transformer
Transformer 用自注意力机制(self-attention)来“让每个时刻看向历史上所有时刻”,擅长捕捉复杂的非线性关系、长程依赖和多个信号间的交互。
通常用 encoder(把历史编码)+ decoder(逐步/并行预测未来)。
缩放点积注意力(Scaled dot-product attention):
多头注意力(MultiHead):
一个 Transformer 层(带残差与 LayerNorm):
在时间序列预测里,Transformer 的输出可以是未来 步的直接预测(非自回归)或自回归式解码。
核心点来了,为什么把两者合起来
首先,Prophet 擅长把序列的“可解释、可预测的低频/周期/节假日”拆出来,减少模型要学的负担。
其次,Transformer 擅长“非线性短期波动、多周期交互、异常模式、异构回归变量的复杂关系”。
合起来可以:让 Transformer 专注学Prophet 无法充分捕捉的剩余信息(残差),既提高精度又保留可解释性。
三种主流结合方案
第一种,残差建模
先用 Prophet 求出基线 ,然后只用 Transformer 学 残差 ,预测未来残差,最后把两者加回去。
步骤:
-
用 Prophet 拟合训练数据,得到对未来 的基线预测 (包括趋势、季节、节假日)。
-
计算训练期残差:
-
构造 Transformer 的训练样本。给定历史窗口长度 ,目标预测长度 。样本 的输入与目标可以是:
可选分量
- 输入:历史残差 、历史原始观测 、外生变量 、以及 Prophet 给出的未来分量(可选)。
- 输出:未来残差 。 表示为函数形式:
- 损失(最常见 MSE):
- 最终预测:
优点是简单、保留 Prophet 可解释性、容易调试(把问题拆成两块)。
但是大家要注意,要保证 Prophet 的周期/趋势成分不被 Transformer 重复学习(避免“重复拟合”)。一般先把 Prophet 的分量从训练输入中移除(或者明确让 Transformer 只学残差)。
第二种,特征增强
把 Prophet 的分量当 Transformer 的输入特征。
不单独学残差,而是把 Prophet 输出的各个分量()作为额外的特征,连同原始历史一起输入 Transformer,由 Transformer 直接预测 。
- 对每个时间步 ,构造输入向量
- 用 Transformer 学映射:
- 损失可以是 MSE 或分位数损失等:
Transformer 可以直接决定是否、如何利用 Prophet 的分量,灵活;可用于端到端学习。
但是有可能会把 Prophet 的成分“重复学习”导致冗余;可解释性比残差方案弱(但仍可通过注意力/特征重要性分析部分恢复解释性)。
第三种,端到端可微联合训练
把 Prophet 的分解模块用可微的参数化函数实现(例如把 changepoints、斜率参数设为可学习参数而非黑盒 MCMC),然后把它与 Transformer 放在同一个计算图里一起训练,损失反向传播到两端。
模型定义:
-
定义可微趋势模块 (参数包括 base slope/intercept 与每个 changepoint 的),傅里叶季节模块(参数为傅里叶系数),节假日系数(参数)。
-
Transformer 预测残差或直接预测最终输出 。
-
总输出:
-
联合训练损失:
其中 可为 MSE 或对数似然, 是正则化(例如鼓励 稀疏以保留少量 changepoints,便于解释)。
理论上是“最灵活”的方式,可以同时利用 Prophet 的可解释形式与 Transformer 的表示能力,且训练是端到端的(参数互相适配)。
但是训练复杂、需要 careful 初始化(例如先用 Prophet 估计初值),可能丧失 Prophet 原本的贝叶斯不确定性估计机制;也更容易过拟合。
完整案例
我们在这里模拟一个 销量类时间序列,方便大家学习:
- 趋势:逐渐上升
- 季节性:周周期(周期 = 7)+ 年周期(周期 = 365)
- 节假日效应:某些特殊日销量飙升
- 随机噪声
这样 Prophet 能捕捉趋势+周期,Transformer 补充短期波动。
方法设计方面,使用残差建模方案
-
用 Prophet 拟合数据,得到 。
-
计算残差:
-
用 Transformer 预测未来残差:
外生变量
-
最终预测:
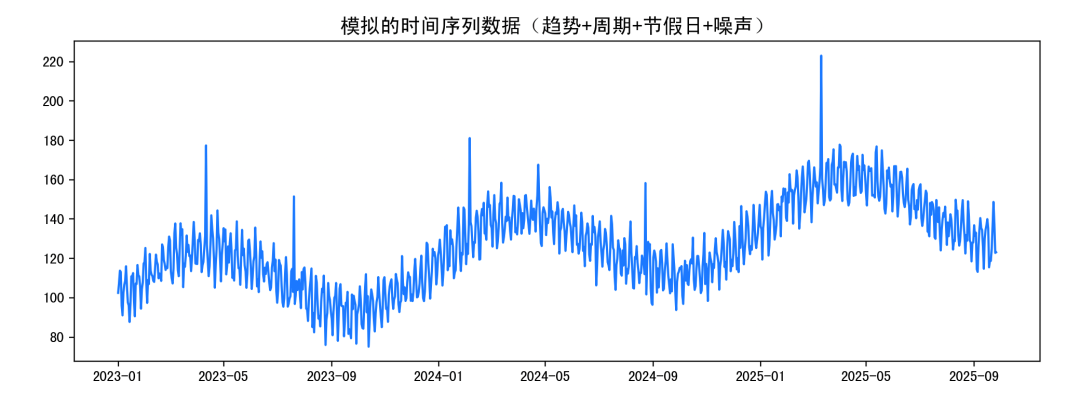
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport torchimport torch.nn as nnfrom torch.utils.data import DataLoader, Datasetfrom sklearn.preprocessing import StandardScalerfrom prophet import Prophet# 1. 构造虚拟数据np.random.seed(42)days = 1000time = np.arange(days)trend = 0.05 * time # 上升趋势seasonal_week = 10 * np.sin(2 * np.pi * time / 7) # 周期seasonal_year = 20 * np.sin(2 * np.pi * time / 365) # 年周期holiday_effect = np.zeros(days)holiday_days = [100, 200, 400, 600, 800]holiday_effect[holiday_days] = 50 # 节假日爆发noise = np.random.normal(0, 5, days)y = 100 + trend + seasonal_week + seasonal_year + holiday_effect + noisedf = pd.DataFrame({"ds": pd.date_range("2023-01-01", periods=days), "y": y})# 可视化原始序列plt.figure(figsize=(12,4))plt.plot(df["ds"], df["y"], color="dodgerblue")plt.title("模拟的时间序列数据(趋势+周期+节假日+噪声)", fontsize=14)plt.show()
Prophet 拟合与预测:
# 2. Prophet 拟合m = Prophet(yearly_seasonality=True, weekly_seasonality=True, daily_seasonality=False)m.add_country_holidays(country_name='US')m.fit(df)future = m.make_future_dataframe(periods=100)forecast = m.predict(future)# 可视化 Prophet 预测fig1 = m.plot(forecast)plt.title("Prophet 基线预测", fontsize=14)plt.show()fig2 = m.plot_components(forecast)plt.show()
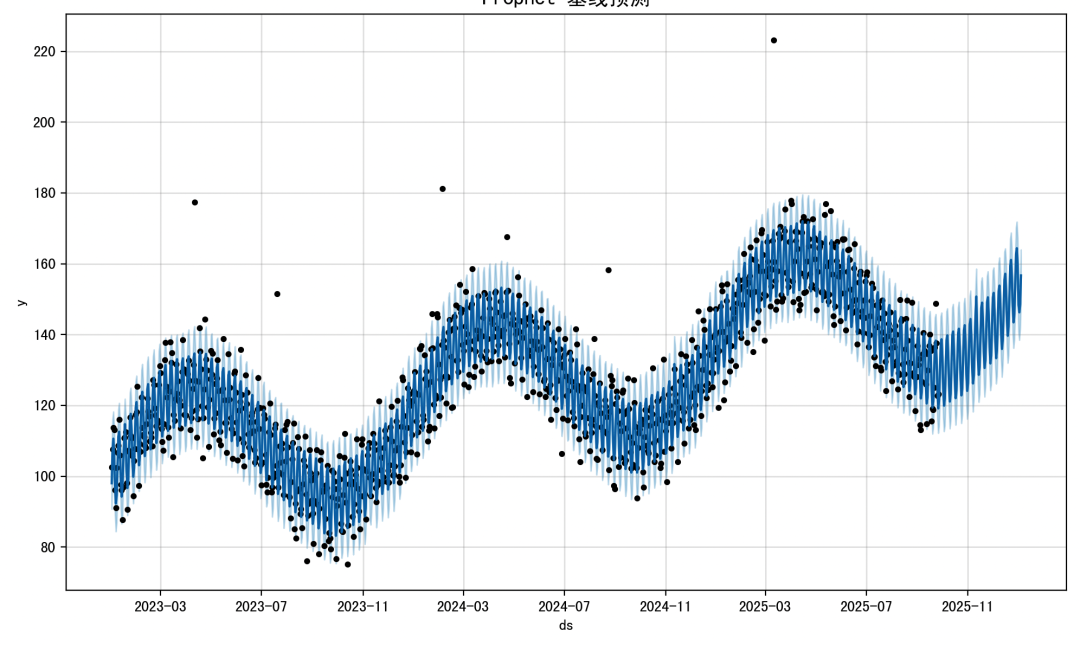
图1:显示 Prophet 的整体预测效果。
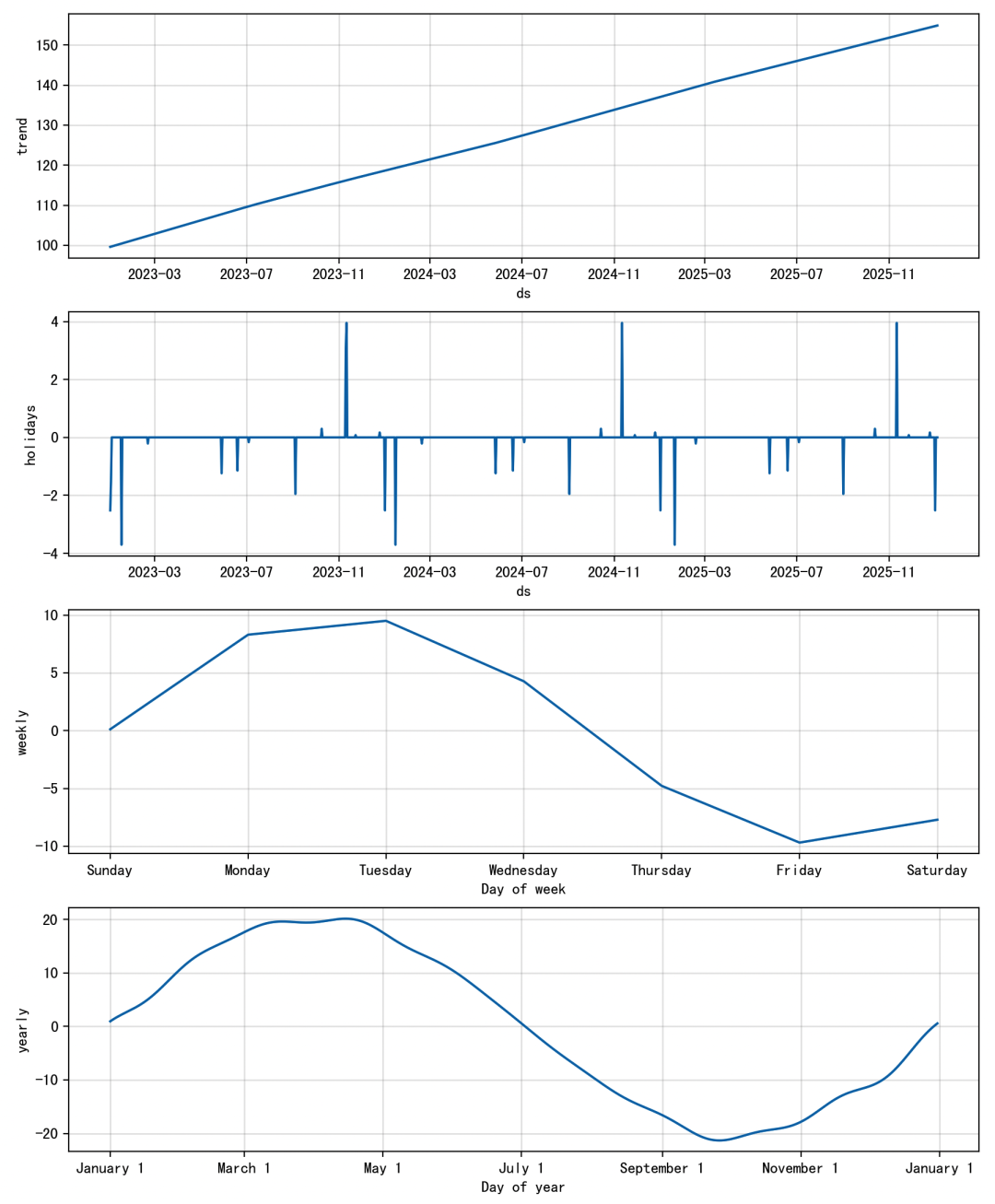
图2:分解图,展示趋势、周周期、年周期、节假日效应。
残差计算与分析:
# 3. 计算残差df["yhat"] = forecast.loc[:len(df)-1, "yhat"].valuesdf["residual"] = df["y"] - df["yhat"]plt.figure(figsize=(12,4))plt.plot(df["ds"], df["residual"], color="crimson")plt.title("Prophet 残差序列", fontsize=14)plt.show()
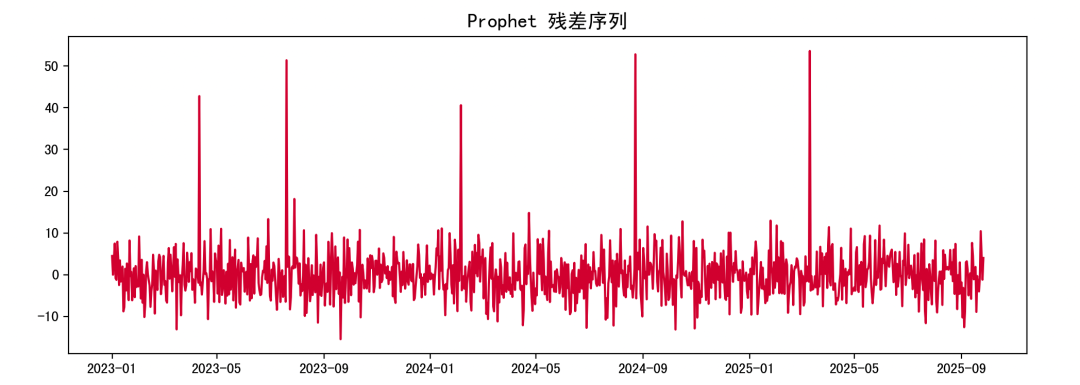
残差显示 Prophet 未能拟合的复杂波动部分。
构建 PyTorch Transformer:
# 数据集类class ResidualDataset(Dataset): def __init__(self, data, seq_len=30, pred_len=7): self.data = data self.seq_len = seq_len self.pred_len = pred_len def __len__(self): return len(self.data) - self.seq_len - self.pred_len def __getitem__(self, idx): x = self.data[idx:idx+self.seq_len] y = self.data[idx+self.seq_len:idx+self.seq_len+self.pred_len] return torch.tensor(x, dtype=torch.float32), torch.tensor(y, dtype=torch.float32)# 标准化残差scaler = StandardScaler()residuals = scaler.fit_transform(df["residual"].values.reshape(-1,1)).flatten()seq_len, pred_len = 30, 7dataset = ResidualDataset(residuals, seq_len, pred_len)dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 定义 Transformer 模型class ResidualTransformer(nn.Module): def __init__(self, d_model=64, nhead=4, num_layers=2, pred_len=7): super().__init__() self.embedding = nn.Linear(1, d_model) encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=128) self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers) self.fc_out = nn.Linear(d_model, pred_len) def forward(self, x): # x: (batch, seq_len) x = x.unsqueeze(-1) # (batch, seq_len, 1) x = self.embedding(x) # (batch, seq_len, d_model) x = x.permute(1,0,2) # (seq_len, batch, d_model) encoded = self.encoder(x) # (seq_len, batch, d_model) out = self.fc_out(encoded[-1]) # 取最后一步 return outmodel = ResidualTransformer()criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
模型训练:
epochs = 20for epoch in range(epochs): model.train() total_loss = 0 for x,y in dataloader: optimizer.zero_grad() yhat = model(x) loss = criterion(yhat, y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{epochs}, Loss={total_loss/len(dataloader):.4f}")
最终预测结果融合:
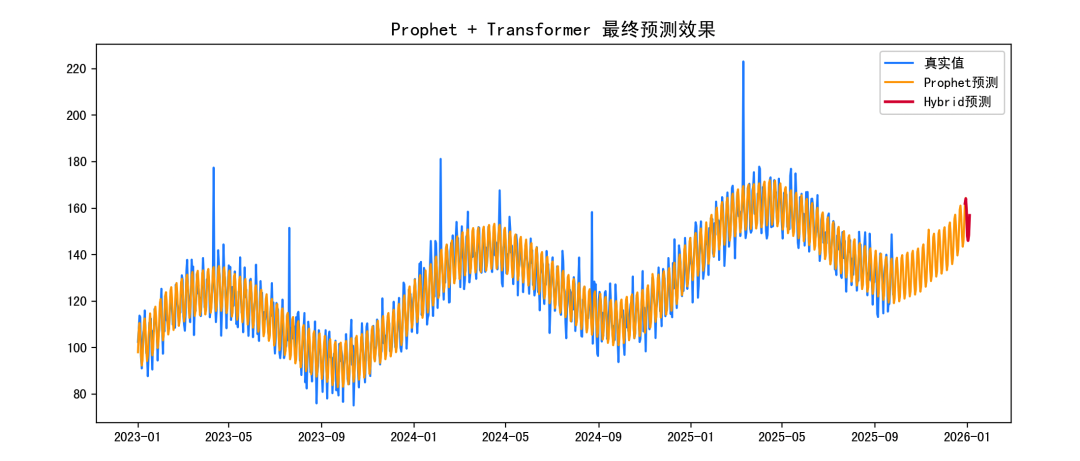
# 预测最后 seq_len+pred_lenlast_seq = residuals[-seq_len:]last_seq = torch.tensor(last_seq, dtype=torch.float32).unsqueeze(0)model.eval()with torch.no_grad(): pred_residual = model(last_seq).numpy().flatten()# 反归一化pred_residual = scaler.inverse_transform(pred_residual.reshape(-1,1)).flatten()# Prophet 基线预测prophet_future = forecast["yhat"].values[-pred_len:]# 融合预测final_pred = prophet_future + pred_residual# 可视化最终预测plt.figure(figsize=(12,5))plt.plot(df["ds"], df["y"], label="真实值", color="dodgerblue")plt.plot(future["ds"], forecast["yhat"], label="Prophet预测", color="orange")plt.plot(future["ds"].values[-pred_len:], final_pred, label="Hybrid预测", color="crimson", linewidth=2)plt.title("Prophet + Transformer 最终预测效果", fontsize=14)plt.legend()plt.show()
算法优化方面,给大家爱整理了4个方面:
- 残差建模 → 可以增加外生变量(如天气、促销)。
- Transformer 优化:
- 用 Informer/Autoformer(稀疏注意力、季节趋势分解)
- 使用位置编码改进(时间特征 embedding)
- 概率预测 → 输出均值+方差,结合 Prophet 不确定性。
- 集成学习 → 多模型融合(LSTM、XGBoost)
调参流程:
- 窗口长度 L:通常选择 4-8 倍预测步长。
- Transformer 参数:
- d_model: 64–256
- nhead: 保证 d_model % nhead == 0
- num_layers: 2–4
- 学习率:1e-3 起步,带 Cosine Annealing/LR Scheduler
- batch_size:32–128,数据量大时可增大
- 正则化:dropout=0.1–0.3
整个过程,大家要注意Prophet 预测时只能用训练集窗口(不能用未来真实值)。
而Transformer 输入残差时,注意不要泄露未来信息(严格滑动窗口)。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献416条内容
已为社区贡献416条内容

所有评论(0)