中间件的日志管理与分析:ELK Stack实战
本文介绍了利用ELK Stack(Elasticsearch、Logstash、Kibana)进行中间件日志管理与分析的实践方法。ELK Stack通过Logstash收集处理日志数据,Elasticsearch存储索引数据,Kibana提供可视化分析。文章详细讲解了ELK架构原理、日志收集配置示例(包括文件输入、错误日志过滤等)、安装配置步骤,以及常见问题解决方法(如日志收集不全、分析不准确等)
在中间件的监控和运维工作中,日志管理与分析起着至关重要的作用。通过对中间件日志的有效管理和分析,我们可以及时发现系统中的潜在问题,了解系统的运行状态。而ELK Stack就是一款强大的用于日志收集、存储和分析的工具集。接下来,我们就一起走进ELK Stack的实战世界,去掌握如何利用它对中间件日志进行有效管理和分析。
目录
ELK Stack的架构
ELK Stack由三个主要组件组成:Elasticsearch、Logstash和Kibana,我们先来了解一下它们各自的作用和整个架构的工作原理。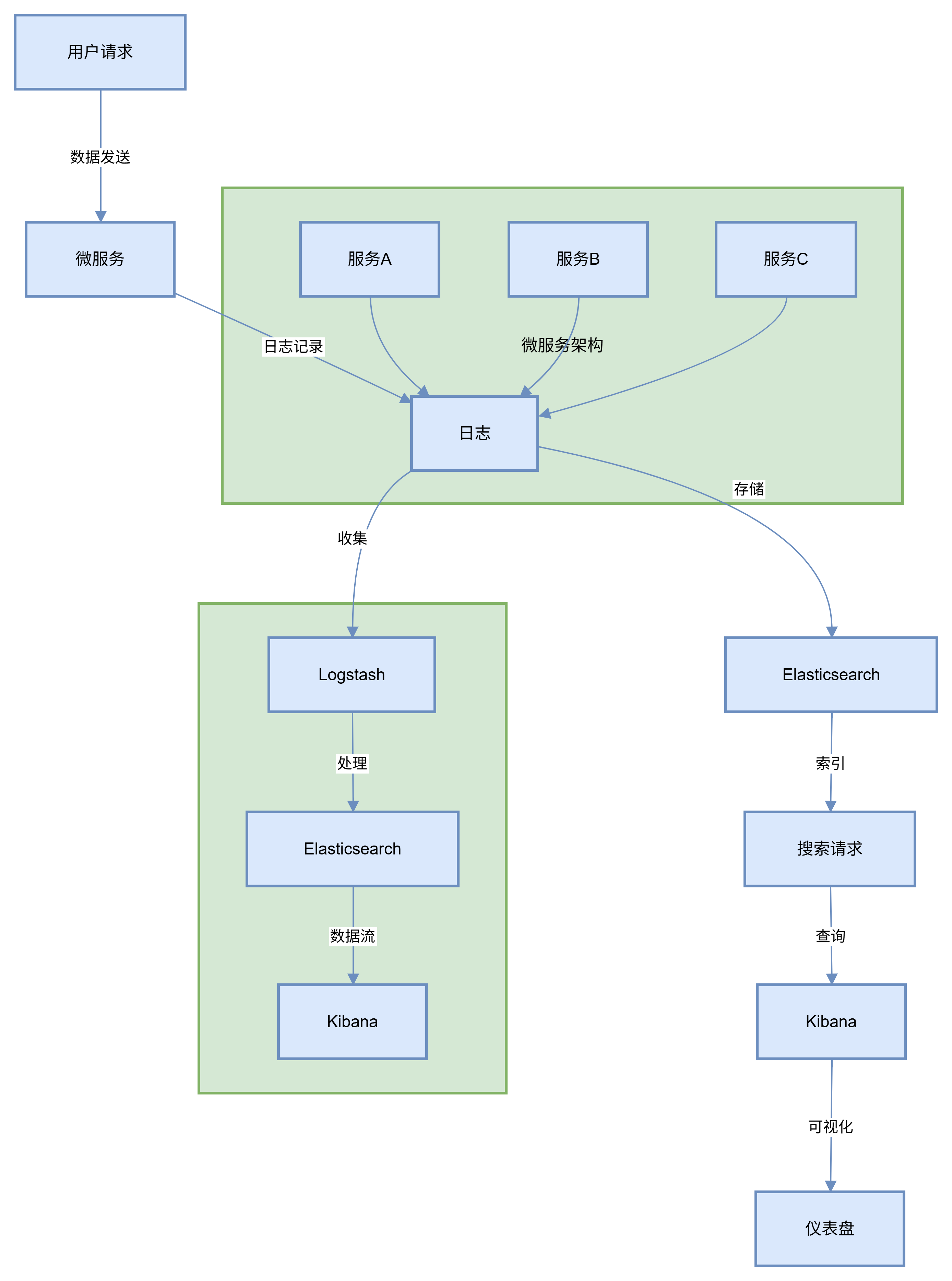
Elasticsearch
Elasticsearch是一个分布式的搜索和分析引擎。用大白话来说,它就像是一个超级大的“图书馆”,可以把我们收集到的日志数据按照一定的规则进行分类存放,并且能够快速地找到我们想要的信息。它基于Lucene构建,提供了强大的全文搜索和分析功能。例如,在一个大型电商系统中,我们可以使用Elasticsearch快速查找某个时间段内所有用户的登录日志,分析用户的登录行为。
Logstash
Logstash是一个数据收集和处理的管道。它就像一个“快递员”,负责从各个数据源(如中间件的日志文件、系统日志等)收集日志数据,然后对这些数据进行过滤、转换等处理,最后将处理好的数据发送到Elasticsearch中进行存储。比如,我们可以配置Logstash只收集中间件中错误级别的日志,忽略其他级别的日志,这样可以减少存储和分析的工作量。
Kibana
Kibana是一个可视化工具。它就像是一个“展示厅”,可以将Elasticsearch中存储的日志数据以各种图表、报表的形式展示出来,让我们更直观地了解日志数据背后的信息。例如,我们可以使用Kibana生成一个柱状图,展示每天中间件的错误日志数量的变化趋势。
整个ELK Stack的架构就是这样,Logstash负责收集和处理日志数据,Elasticsearch负责存储和搜索日志数据,Kibana负责可视化展示日志数据。
日志收集和分析流程
日志收集
日志收集是整个流程的第一步。我们需要配置Logstash从中间件的日志文件中收集数据。以下是一个简单的Logstash配置示例:
input {
file {
path => "/var/log/middleware.log"
start_position => "beginning"
}
}
filter {
# 这里可以添加过滤规则,例如只收集错误级别的日志
if [message] =~ /ERROR/ {
mutate {
add_tag => ["error_log"]
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "middleware_logs"
}
}
在这个配置中,input部分指定了日志文件的路径,filter部分可以对日志数据进行过滤,output部分指定了将处理好的数据发送到Elasticsearch的地址和索引名称。
日志存储
当Logstash将处理好的日志数据发送到Elasticsearch后,Elasticsearch会将这些数据存储在指定的索引中。索引就像是数据库中的表,每个索引可以包含多个文档(即日志记录)。Elasticsearch会自动对这些文档进行索引,以便快速搜索。
日志分析
在Kibana中,我们可以使用各种查询和可视化工具对Elasticsearch中存储的日志数据进行分析。例如,我们可以使用Kibana的查询功能查找某个时间段内所有包含特定关键词的日志记录,然后使用可视化工具生成图表展示这些日志的分布情况。
实操模块:分步骤实现中间件日志的收集和分析
步骤一:安装和配置ELK Stack
首先,我们需要分别安装Elasticsearch、Logstash和Kibana。安装过程可以参考官方文档。安装完成后,我们需要对它们进行配置。
- Elasticsearch配置:打开
elasticsearch.yml文件,配置集群名称、节点名称等信息。例如:
cluster.name: my_elk_cluster
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
- Logstash配置:创建一个Logstash配置文件,如上面的示例所示,配置输入、过滤和输出部分。
- Kibana配置:打开
kibana.yml文件,配置Elasticsearch的地址。例如:
elasticsearch.hosts: ["http://localhost:9200"]
步骤二:启动ELK Stack
分别启动Elasticsearch、Logstash和Kibana服务。可以使用以下命令:
- 启动Elasticsearch:
./bin/elasticsearch - 启动Logstash:
./bin/logstash -f /path/to/logstash.conf - 启动Kibana:
./bin/kibana
步骤三:验证日志收集
打开Kibana的Web界面,访问http://localhost:5601。在Kibana中创建一个索引模式,指向我们在Logstash配置中指定的索引名称(如middleware_logs)。然后,使用Kibana的查询功能验证日志是否已经成功收集到Elasticsearch中。
步骤四:日志分析和可视化
在Kibana中,我们可以使用各种可视化工具对日志数据进行分析和展示。例如,创建一个柱状图展示每天的错误日志数量,创建一个饼图展示不同类型错误日志的占比等。
解决ELK Stack日志收集不全、分析不准确等问题
日志收集不全
- 检查日志文件权限:确保Logstash有足够的权限访问中间件的日志文件。可以使用
chmod命令修改文件权限。 - 检查Logstash配置:检查
input部分的路径是否正确,是否有遗漏的日志文件。 - 检查网络连接:确保Logstash和Elasticsearch之间的网络连接正常。
分析不准确
- 检查过滤规则:检查Logstash的
filter部分是否正确配置,是否过滤掉了有用的日志数据。 - 检查索引映射:确保Elasticsearch的索引映射正确,能够正确解析日志数据的字段类型。
通过以上步骤,我们可以解决ELK Stack日志收集不全、分析不准确等问题,确保日志管理和分析的有效性。
掌握了ELK Stack的使用,我们就能够对中间件日志进行有效管理和分析,及时发现系统中的潜在问题,保障中间件的稳定运行。掌握了ELK Stack的使用后,下一节我们将深入学习中间件的性能监控方法,进一步完善对本章中间件的监控与运维主题的认知。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)