DetectGPT 的轻量升级:贝叶斯代理让检测更高效
如何在几乎不多问大模型的情况下,依然靠谱地分辨一段文字是不是 LLM 写的?过去的零样本检测方法,要么像传统的 log-prob 检测器那样效果一般,要么像 DetectGPT 那样效果不错但查询次数离谱——检测一段文本要几百次调用源模型。在商用 LLM 按 token 收费的大背景下,这个成本几乎不可接受。在 DetectGPT 的框架里塞进了一个“贝叶斯代理人”
1. 论文基本信息
- 标题:Efficient Detection of LLM-generated Texts with a Bayesian Surrogate Model
- 作者:Yibo Miao, Hongcheng Gao, Hao Zhang, Zhijie Deng
- 年份:2024(arXiv v3, 2024-06-04 更新)
- 领域关键词:LLM-generated text detection,zero-shot detection,DetectGPT,Bayesian surrogate model,Gaussian Process,BertScore kernel,query efficiency
- 论文链接:arXiv:2305.16617
2. 前言
这篇文章解决的核心问题,其实用一句话就能说清楚:如何在几乎不多问大模型的情况下,依然靠谱地分辨一段文字是不是 LLM 写的?
过去的零样本检测方法,要么像传统的 log-prob 检测器那样效果一般,要么像 DetectGPT 那样效果不错但查询次数离谱——检测一段文本要几百次调用源模型。在商用 LLM 按 token 收费的大背景下,这个成本几乎不可接受。
作者做的事,可以理解为:在 DetectGPT 的框架里塞进了一个“贝叶斯代理人”,只挑少量“关键扰动样本”去问一次源模型,然后用高斯过程(Gaussian Process, GP)把这些分数“插值外推”到其他扰动上,最后还是用 DetectGPT 那套曲率统计量来做判别。
从结果上看,这个想法非常粗暴但好用:
- 在检测 LLaMA2 家族文本时,只用 2–3 次查询,他们的方法就能干翻 DetectGPT 用 200 次查询的表现。
- 即便是经典的 GPT-2 场景,在相同性能下,他们也能做到 查询次数减少一半左右,甚至在极低查询数(2 次)下就能超过 DetectGPT。
- 更关键的是,方法还能推广到黑盒大模型(例如 ChatGPT),只要有一个还不错的代理模型就行。
3. 历史背景与前置技术
要看懂这篇文章,得先把 LLM 文本检测这一条技术线捋一下。
最早的一批工作,更像传统机器学习:收集大量人类写的文本和机器写的文本,训练一个监督分类器。从简单的特征工程,到后来的 DNN / Transformer 检测器,思路都是“看数据学一个判别器”。问题很明显:
- 数据很难覆盖所有领域,一旦分布变化就容易直接失效;
- 模型越复杂,就越面临对抗攻击、后门攻击等安全问题。
后来,社区开始转向零样本检测:既然 LLM 自己非常懂自己,那不如用生成模型的输出概率来判别它写没写这段话。典型做法是:
- 统计候选文本的平均 per-token log probability,logprob 越高,越有可能是模型自己的产物;
- GLTR 这类工作会检查每个 token 的 rank 分布,分析“这个词对模型来说是不是太容易预测了”。
在这条线的基础上,DetectGPT 往前迈了一大步。它的观点是:
- 模型自己写的文本,更像是 log 概率函数的局部峰值;
- 于是它不只看 log pθ(x),还会在 x 周围做一堆语义相近的扰动,看看“在这片邻域里,原句是不是明显更高一点”。
这就引出了 DetectGPT 的核心统计量: - 生成很多重写版本 x i x_i xi,计算它们的平均 log 概率;
- 用原句的 log 概率减去这个平均值,得到一项类似“局部曲率”的指标。
问题也很直观:要估出这块“局部形状”,就得采很多点。DetectGPT 通常需要上百个扰动样本,每个都要跑一次源 LLM 的 logprob,这对 LLaMA、ChatGPT、GPT-4 这种大模型来说,成本可太高了。
另一方面,在主动学习和贝叶斯优化领域,人们早就知道:
- 如果你有一个带不确定性估计的代理模型(比如高斯过程),就可以只在“最不确定”的点上做真实查询,再用代理模型对剩余点做插值;
- 这样可以在很少的真实标签(这里对应“问一次 LLM 的 logprob”)下,尽可能恢复函数的大致形状。
这篇论文做的事情,就是把这条“贝叶斯代理 + 不确定性采样”的老路,嫁接到 DetectGPT 的曲率检测框架里,从而在不牺牲性能的前提下,极大地压缩查询次数。
4. 论文核心贡献
我自己的理解,这篇文章的贡献可以概括成一句话:在 DetectGPT 这条路线不动核心思想的前提下,换掉了最烧钱的部分——把“全靠源模型算分”变成了“少量源模型 + 贝叶斯代理插值”。
更细一点看:
- 作者把 DetectGPT 里面那堆“随机扰动样本”视作一片高维语义邻域,认为它们之间高度冗余,没必要对每个样本都问一次源模型。
- 他们用一个 高斯过程回归器 来近似 log pθ(·) 在这片局部区域的形状。因为 GP 天然带有预测方差,就可以用这个不确定性来顺序挑选“最有价值”的样本去真正查询 LLM。
- 在只查询少量 “典型扰动样本” 后,GP 代理模型就被用来给剩下的大量扰动样本打分,再带回 DetectGPT 那个曲率统计量框架中。
- 这套方法在 GPT-2、LLaMA2、Vicuna、甚至 ChatGPT(通过代理模型)上,都取得了非常稳定的性能优势,尤其是在低查询预算场景下差距巨大。
我比较喜欢的一点是:作者并没有试图重新发明一个新的检测统计量,而是承认 DetectGPT 的思路是对的,然后老老实实地优化它最痛的“查询效率”瓶颈。这种“工程 + 贝叶斯小技巧”的结合,在现在这个大模型成本敏感的时代,其实非常实用。
5. 方法详解
(这是整篇论文最“干货”的部分,我会按 DetectGPT 回顾 → 代理模型设计 → 典型样本选择 → 完整流程 这个顺序来拆。)
5.1 从 DetectGPT 说起:曲率统计量到底在算什么?
零样本 LLM 文本检测可以被视作一个二分类问题:给你一段文本 x x x,判断它是人写的还是某个 LLM p θ p_{\theta} pθ 写的。零样本的含义是:不事先训练额外的分类器,只允许访问源 LLM 的打分能力。
DetectGPT 的核心统计量可以写成:
l o g p θ ( x ) − 1 N ∑ i = 1 N l o g p θ ( x i ) log p_{\theta}(x) - \frac{1}{N}\sum_{i=1}^{N} log p_{\theta}(x_i) logpθ(x)−N1∑i=1Nlogpθ(xi)
这里:
- x x x 是待检测文本;
- x i x_i xi 是从一个扰动分布 q ( ⋅ ∣ x ) q(\cdot | x) q(⋅∣x) 中采样得到的“重写版”,语义上与 x x x 相近;
- l o g p θ ( ⋅ ) log p_{\theta}(\cdot) logpθ(⋅) 是源 LLM 给出的 log 概率。
直觉非常简单:如果 x x x 正好是模型喜欢的那种“峰值点”,那它在局部邻域里的 log 概率应该显著高于周围的扰动版本,于是上式就会比较大;反过来,如果 x x x 是人写的,往往不会恰好卡在模型的局部最优,平均一下反而差不多。
整个 DetectGPT 的消耗主要来自两点:
- 需要大量扰动样本 x i x_i xi(比如 N=200),才能稳定估计这片局部形状;
- 每个 x i x_i xi 都要跑一次 LLM 的 logprob,这就是几十到几百次查询。
这篇论文的目标就是:在不改变这个统计量定义的情况下,大幅减少需要真正求 logprob 的样本数量。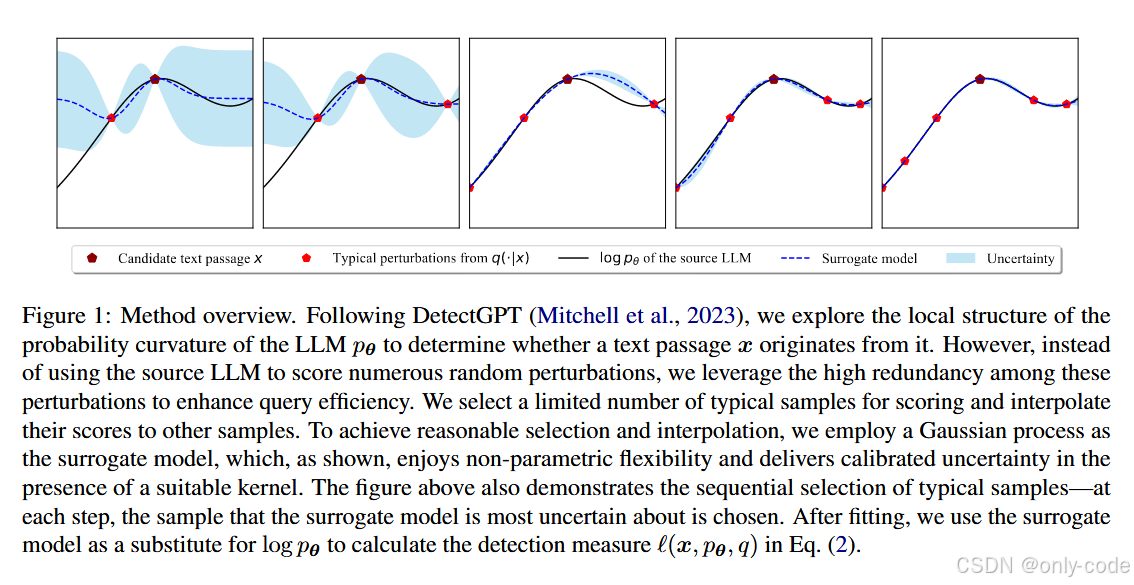
【插图:论文 Fig.1 方法整体框架示意(候选文本、扰动样本、GP 代理、典型样本选择)】
5.2 思路翻译:从“全量评分”到“典型样本 + 插值”
作者的关键观察是:
- 由于扰动模型 q ( ⋅ ∣ x ) q(\cdot|x) q(⋅∣x) 通常是通过 T5 这类 mask-filling 模型做近义改写,所有扰动样本之间高度相似;
- 在这样一个局部语义邻域里, l o g p θ ( ⋅ ) log p_{\theta}(\cdot) logpθ(⋅) 其实是一条相对平滑的函数,只要在少数点上知道真值,就可以靠一个函数逼近器去插值。
于是他们提出:
- 先从所有扰动样本里,选出一小撮“典型样本”组成集合 X t X_t Xt;
- 只在这些样本上调用 LLM,得到真分数 y t = l o g p θ ( X t ) y_t = log p_{\theta}(X_t) yt=logpθ(Xt);
- 训练一个代理模型 f f f,在局部拟合 l o g p θ log p_{\theta} logpθ;
- 用 f f f 来给剩余的大量扰动样本打分,再计算 DetectGPT 的统计量。
关键问题就变成两个:
- 代理模型 f f f 用什么?
- 怎样高效、可靠地选择这些“典型样本”?
5.3 代理模型选择:为什么是高斯过程(GP)?
作者给代理模型开出的“需求清单”大概是这样:
- 在数据点很少的局部场景下,不能太容易过拟合;
- 要能够表达出足够复杂的局部曲率;
- 最好自带一个“对自己有多不确定”的量,方便做样本选择;
- 计算量要可控,不能为了省 LLM 查询又引入更大的计算炸弹。
在这个条件下,他们选了一个很经典的贝叶斯工具:高斯过程回归。思路是:
- 在函数空间里假设一个先验 f ( x ) ∼ G P ( 0 , k ( x , x ′ ) ) f(x) \sim GP(0, k(x, x')) f(x)∼GP(0,k(x,x′));
- 观测到有限样本 ( X t , y t ) (X_t, y_t) (Xt,yt) 之后,通过贝叶斯推断得到在新点 X ∗ X^* X∗ 上的后验预测分布。
在 GP 框架下,新的点集 X ∗ X^* X∗ 上的预测满足:
f X ∗ ∼ N ( f ˉ ∗ , Σ ∗ ) f_{X^*} \sim \mathcal{N}(\bar f_*, \Sigma_*) fX∗∼N(fˉ∗,Σ∗)
其中预测均值大致形如:
f ˉ ∗ = k X ∗ , X t ( k X t , X t + σ 2 I ) − 1 y t \bar f_* = k_{X^*, X_t} (k_{X_t, X_t} + \sigma^2 I)^{-1} y_t fˉ∗=kX∗,Xt(kXt,Xt+σ2I)−1yt
预测协方差:
Σ ∗ = k X ∗ , X ∗ − k X ∗ , X t ( k X t , X t + σ 2 I ) − 1 k X t , X ∗ \Sigma_* = k_{X^*, X^*} - k_{X^*, X_t} (k_{X_t, X_t} + \sigma^2 I)^{-1} k_{X_t, X^*} Σ∗=kX∗,X∗−kX∗,Xt(kXt,Xt+σ2I)−1kXt,X∗
直觉上:
- f ˉ ∗ \bar f_* fˉ∗ 给出了“我们认为这几个扰动样本的 log 概率大概是多少”;
- Σ ∗ \Sigma_* Σ∗ 的对角线就是每个点的不确定性——离已知数据很远、不被 kernel 覆盖到的点,不确定性就大。
这正好满足我们“按不确定性挑典型样本”的需要。
5.4 文本世界里的 kernel:基于 BertScore 的相似度
问题是:GP 需要一个定义在文本上的 kernel。传统的 RBF、poly 这些都默认输入是向量,而这里的输入是整段文本。
作者借用了一个在文本评测中非常常见的工具:BertScore。它大致是用预训练 BERT 对文本进行编码,然后通过 token-level 匹配来衡量两段文本的相似性。
在此基础上,他们直接定义 kernel:
k ( x , x ′ ) = α ⋅ BertScore ( x , x ′ ) + β k(x, x') = \alpha \cdot \text{BertScore}(x, x') + \beta k(x,x′)=α⋅BertScore(x,x′)+β
其中:
- BertScore 本身就落在一个相对有限的区间,反映语义相似度;
- α > 0 \alpha > 0 α>0、 β \beta β 是两个可学习的超参数,用来调节缩放和平移,使 kernel 更“好用”。
这个设计非常工程:不追求理论优雅,核心目标是——使文本越相似,GP 眼里这两个点就越“近”。
5.5 超参数通过边际似然自适应学习
GP 里还有三个重要超参数: α \alpha α、 β \beta β 和噪声项方差 σ 2 \sigma^2 σ2。作者没有手调,而是用标准的最大化对数边际似然来学习:
l o g p ( y t ∣ X t , α , β , σ 2 ) ∝ − [ y t ⊤ ( k X t , X t + σ 2 I ) − 1 y t + log ∣ k X t , X t + σ 2 I ∣ ] log p(y_t | X_t, \alpha, \beta, \sigma^2) \propto -\big[y_t^\top (k_{X_t, X_t} + \sigma^2 I)^{-1} y_t + \log |k_{X_t, X_t} + \sigma^2 I|\big] logp(yt∣Xt,α,β,σ2)∝−[yt⊤(kXt,Xt+σ2I)−1yt+log∣kXt,Xt+σ2I∣]
这里的意思是:
- 第一项希望模型在当前样本上拟合得好;
- 第二项通过 log-determinant 惩罚过度复杂的核矩阵,起到一种“自动正则”的作用。
鉴于 X t X_t Xt 通常很小(几十个以内),矩阵求逆和 log-determinant 的开销完全可以接受。作者用 Adam 优化器,学习率 0.01,跑约 50 步就行。
5.6 如何选“典型样本”:基于贝叶斯不确定性的顺序采样
有了 GP 之后,接下来就是这篇论文最“萌”的部分:典型样本是怎么被挑出来的?
整体流程可以概括为一个交替迭代:
- 初始化:
- 从全部扰动样本集合 X = x i X = {x_i} X=xi 中,随机选出一小部分作为初始典型集 X t X_t Xt,并要求一定包含原文本 x x x 本身;
- 对这些样本调用一次源 LLM,得到 y t = l o g p θ ( X t ) y_t = log p_{\theta}(X_t) yt=logpθ(Xt); - 给定当前的 ( X t , y t ) (X_t, y_t) (Xt,yt),优化 GP 超参数,得到一个“当前代理”;
- 在候选集合 X ∗ X^* X∗(可以是 X ∖ X t X \setminus X_t X∖Xt 或者额外采样的扰动)上,计算 GP 的预测协方差 Σ ∗ \Sigma_* Σ∗;
- 找出不确定性最大的那个样本(也就是 Σ ∗ \Sigma_* Σ∗ 对角线最大的点),把它加入 X t X_t Xt,并向 LLM 查询它的 logprob;
- 回到步骤 2,直到达到查询上限 T 或者整体不确定性降到某个阈值。

【插图:论文 Algorithm 1 贝叶斯代理检测算法伪代码】
这种做法本质上就是一种贝叶斯主动学习 / 贝叶斯优化的 acquisition 策略,只不过 acquisition 函数非常简单:谁最不确定就问谁。
论文里还做了一个很有趣的可视化实验:
- 从一句话“Joe Biden recently made a move to the White House.”出发,用 ChatGPT 重写 50 个版本;
- 模拟这一套典型样本选择流程,观察前 11 个被选中的样本。
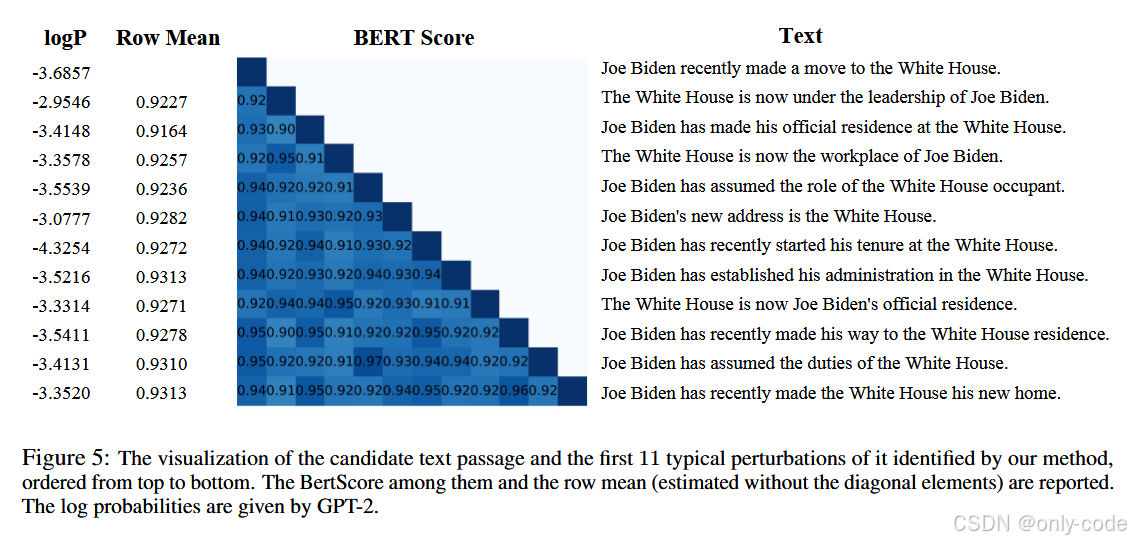
【插图:论文 Figure 5 典型扰动样本及相似度可视化】
结果显示:在典型样本列表中,越靠前的句子越“独特”,而后面逐渐被选中的句子和前面的样本相似度越来越高,这说明 GP 确实在一开始优先选择了那些在语义空间里更“边角”的位置,之后才慢慢填补局部空白。
5.7 最后一步:用代理模型回到 DetectGPT 统计量
经过若干轮典型样本选择之后,我们得到了:
- 一小撮被真正查询过 logprob 的样本 X t X_t Xt 和 y t y_t yt;
- 一个在局部区域拟合好的 GP 代理 f f f。
接下来,作者做了一个看似“反常识”但非常重要的决定:
- 用于估计 DetectGPT 统计量时,他们仍然会在局部采大量扰动样本(比如 N=200);
- 区别在于:这些样本不再直接问源 LLM,而是喂进 GP 代理,用预测均值 f ˉ ∗ \bar f_* fˉ∗ 来近似 l o g p θ ( x i ) log p_{\theta}(x_i) logpθ(xi)。
这样一来,DetectGPT 的统计量就变成:
l o g p θ ( x ) − 1 N ∑ i = 1 N f ˉ ( x i ) log p_{\theta}(x) - \frac{1}{N}\sum_{i=1}^{N} \bar f(x_i) logpθ(x)−N1∑i=1Nfˉ(xi)
其中 l o g p θ ( x ) log p_{\theta}(x) logpθ(x) 这项仍然是真实查询(毕竟只查一次不心疼),而后半部分则全部由 GP 代理提供。
在针对大模型(LLaMA 等)的实验中,作者还使用了一个归一化版本:
l o g p θ ( x ) − E ∗ x ~ ∼ q ( ⋅ ∣ x ) [ l o g p ∗ θ ( x ~ ) ] σ \frac{log p_{\theta}(x) - \mathbb{E}*{\tilde x \sim q(\cdot | x)}[log p*{\theta}(\tilde x)]}{\sigma} σlogpθ(x)−E∗x~∼q(⋅∣x)[logp∗θ(x~)]
这里 σ \sigma σ 是扰动样本 log 概率的标准差,用来缓解“局部尺度差异太大”的问题,让不同文本之间的分数更可比较。
6. 实验结果
论文的实验覆盖面非常广,基本把“常见 LLM 检测场景”都过了一遍:包括白盒检测 GPT-2 / LLaMA2 / Vicuna,黑盒检测 ChatGPT,以及不同扰动模型的影响、跨源模型/代理模型组合等等。
6.1 实验设置简述
数据集方面,沿用 DetectGPT 的设定:
- XSum:新闻摘要语料,用来模拟“识别伪新闻”的场景;
- SQuAD contexts:Wikipedia 段落,类似学术/说明文写作;
- WritingPrompts:Reddit 写作题材,侧重创意写作。
生成方式是:取真实文本的前 30 个 token,让 LLM 继续生成后续内容,形成“机器写的版本”。检测任务就是区分这些机器扩写与原始人类文本。
模型方面:
- 源 LLM:GPT-2、LLaMA2-7B/13B、Vicuna-7B/13B;
- 扰动模型:T5-large(主设置)和更强的 T5-3B;
- 代理模型:本文提出的 GP。
评价指标用 AUROC 为主,并额外关注在低 FPR(比如 1%、5%)时的 TPR。
6.2 LLaMA2 / Vicuna:2 次查询打败 200 次查询
在检测 LLaMA2 / Vicuna 生成文本的实验里,结果可以用“夸张”来形容。以 LLaMA2-7B 为例:
- 在 WritingPrompts 上,DetectGPT 在 2、3、4 次查询时的 AUROC 大约在 0.42–0.51 附近徘徊;
- 本文方法在 2 次查询时 AUROC 就已经达到约 0.60,3 次时直接飙到 0.89,4 次则进一步稳定。
而即便给 DetectGPT 开足火力,让它用到 200 次查询,AUROC 也只有 0.46 左右。
类似的现象在 XSum、SQuAD,和 Vicuna-7B/13B 上也都存在:
- 在同样甚至更少的查询预算下,Bayesian 代理方法几乎全面领先;
- 给 DetectGPT 继续增加查询数,收益非常有限,而 GP 代理版在 3–4 次查询时基本就“封顶”了。
从检测任务的角度看,这说明:
- 对于这些强力聊天模型,在局部语义邻域里,log 概率结构的有效信息极其集中;
- 典型样本 + GP 插值足以捕捉这种结构,而盲目地对 200 个随机扰动样本用同一个 LLM 计算 logprob,并没有带来等比例的信息增益。
6.3 GPT-2:更传统场景下的性能与查询效率
在 GPT-2 上,论文画出了比较完整的“查询次数 vs AUROC 曲线”。总体趋势是:
- GP 版方法几乎在所有查询预算下都压着 DetectGPT 一头;
- 在 XSum / SQuAD / WritingPrompts 三个数据集上,10 次查询的 GP 版 ≈ 20 次查询的 DetectGPT;
- 使用更强的扰动模型 T5-3B 后,两者的绝对性能都提高了,但 GP 版的相对优势依然明显。
作者还做了一个有意思的观察:
- 在 WritingPrompts 上,DetectGPT 的性能在查询数增加到 16、20、30 之后几乎不再提升;
- 而 GP 版的曲线比较平滑,随着查询数增加还会有稳定的收益。
这从侧面说明,随机扰动采样的边际收益极快衰减,而不确定性驱动的典型样本选择更有效地“花掉”每一次查询。
6.4 黑盒检测:跨源模型/代理模型与 ChatGPT
现实场景中,我们往往不知道文本是从哪个模型生成的,甚至源模型完全是个黑盒(比如商用 ChatGPT)。论文在这方面做了两层实验。
第一层是源模型 / 代理模型交叉评估:
- 在源模型 {GPT-2, GPT-Neo-2.7, GPT-J} 和代理模型三者之间做 3×3 的组合;
- 观察用哪个模型来当“打分器”更合适。
结果表明:
- 同模型生成 + 同模型打分 当然是最好的;
- 但即便源模型和代理模型不同,比如用 GPT-Neo-2.7 作为代理模型,检测 GPT-2 或 GPT-J 生成文本,性能依旧不错;
- 在所有组合里,GP 版方法相对于 DetectGPT,AUROC 能稳定提升,最高可达到 +3% 左右。
第二层是大家最关心的:ChatGPT 的检测。
- 这里源模型是 ChatGPT(完全黑盒),
- 代理模型分别用 LLaMA2-13B 和 Vicuna-13B 来估计 logprob。
在 XSum / SQuAD / WritingPrompts 三个数据集上: - LLaMA2 代理下,XSum 上 DetectGPT 的 AUROC 仅约 0.40,而 GP 版达到了 0.63;
- 在 WritingPrompts 上,DetectGPT 大约 0.64,GP 版约 0.74;
- 类似地,Vicuna 代理也呈现出类似的明显优势。
这说明在黑盒大模型场景下,只要你有一个足够像源模型的代理 LLM,这套 GP 插值方案依然能够发挥作用。
6.5 更细节的统计结果:ROC 与低 FPR 表现
论文还比较细致地给出了 ROC 曲线和在低 FPR(1%、5%)下的 TPR。结论大致是:
- 在 GPT-2 / Vicuna 等场景下,在 FPR=5% 时 GP 版的 TPR 通常能比 DetectGPT 高出一个明显台阶;
- 比如在 Vicuna-7B + XSum 的组合上,FPR=5% 时 DetectGPT 的 TPR 约 0.80,而 GP 版约 0.88;
- 在 WritingPrompts 这种“创意文本”场景,GP 版在低 FPR 区间的优势就更明显了。
从应用角度看,低 FPR 往往比整体 AUROC 更关键——没人希望把大量人写的文章错判成机器写的。在这点上,Bayesian 代理方法确实更稳一些。
7. 创新点与不足
如果只用一句话记住这篇论文的创新,那就是:用一个带不确定性的贝叶斯代理,把 DetectGPT“烧钱”的那部分换成了少量精挑细选的真实查询 + 插值。
具体来说,我觉得值得记住的亮点有:
- 思路务实:没有推翻 DetectGPT,而是承认其“局部曲率”假设的价值,专注在最痛的查询效率上做优化;
- 方法简洁但有效:高斯过程 + BertScore kernel + 最大不确定性采样,本身都是成熟工具,但组合在一起恰好很契合问题结构;
- 跨模型可推广:不仅能在 GPT-2 / LLaMA2 / Vicuna 上工作,还能通过代理模型扩展到 ChatGPT 这种黑盒大模型;
- 有解释性:典型样本的可视化、交叉评估矩阵,让人大致能直观理解这套方法在“看”什么。
当然,作者也坦诚写出了局限,而且读完后我会再补充一点:
- 典型样本选择是顺序的:每次选择都依赖于前一轮的 GP 不确定性,这让方法很难并行;在大规模部署里,可能会成为另一个性能瓶颈;
- 计算 BertScore 也不便宜:虽然省了 LLM 查询,但在大规模检测时,频繁算 BertScore + GP 矩阵运算也有一定开销,只是相比查询大模型要小得多;
- GP 的局部假设有时会失效:在局部概率曲率非常复杂或“奇怪”的文本周围,少量典型样本可能不足以拟合真实形状,这在他们的行为分析里也表现为某些人类文本被赋予过高或过低的统计量;
- 对强 paraphrase 攻击的鲁棒性尚未系统评估:作者自己也提到,他们目前主要目标是优化 DetectGPT 的查询效率,尚未研究在更强对抗场景下的稳健性。
8. 总结
读完这篇论文,我的整体感觉是:这是在现有检测框架之上,做了一次很“工程感”的贝叶斯升级。问题仍然是 DetectGPT 那个问题——通过局部概率曲率来区分人类文本和 LLM 文本;解决策略则是把原本“人力密集型”(大量 LLM 查询)的部分交给一个带不确定性估计的高斯过程来代劳。
从实验结果看,这样做的收益非常可观:在 LLaMA2 / Vicuna 这类现代 LLM 上,只要 2–4 次查询就能达到甚至超越原始 DetectGPT 用 200 次查询的效果;在 GPT-2 和黑盒 ChatGPT 场景里,方法也保持了稳定的优势。对于现在越来越关注成本和延迟的大模型应用来说,这种**“少问几句,多靠代理”的检测策略**非常具有现实意义。
如果要用几句压缩这篇解读:
- 它没有试图重新定义“什么是机器文本”,而是站在 DetectGPT 肩膀上,承认局部曲率这条路是值得走的;
- 它引入了一个贝叶斯代理模型,用 GP + BertScore 来重建这片局部概率景观;
- 在只问少量“关键点”的前提下,依然能恢复足够的曲率信息,从而在代价极低的情况下给出可靠的检测分数。
如果你之后在实践中还想继续沿着“概率曲率检测”这条路往前走,这篇文章给出了一条很清晰的方向:先想办法把真 LLM 查询压到能接受的水平,再考虑在这个基础上叠加更复杂的检测统计量或鲁棒性改进。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)