内存碎片:内部碎片&外部碎片
内部碎片是指已分配给某个任务的内存块中,未被实际使用但也不能被其他任务使用的部分。过度预分配(over-provisioning)特征:内存属于某个请求,但没有被用上结果:造成严重浪费 —— 论文中指出,实际有效利用率只有📌 类比操作系统:就像操作系统给进程分配一页内存(比如 4KB),但程序只用了 1KB,剩下 3KB 就是内部碎片。外部碎片是指系统中总的可用内存足够,但由于这些空闲内存不连续
在你提供的这篇关于 vLLM(一种高效的大型语言模型服务系统)的论文中,作者指出了现有 LLM 推理系统在管理 KV Cache(Key-Value 缓存)时存在严重的内存效率问题,并特别提到了两个关键概念:
- Internal Memory Fragmentation(内部内存碎片)
- External Memory Fragmentation(外部内存碎片)
下面我们来详细解释这两个术语的含义、它们在 LLM 服务中的具体表现以及为什么会造成资源浪费。
🌟 背景知识:KV Cache 是什么?
在自回归生成(如 GPT 生成文本)过程中,模型每生成一个新 token,都需要访问之前所有 token 的 注意力 Key 和 Value 向量,这些信息被缓存起来,称为 KV Cache。
由于序列长度可变且逐步增长,KV Cache 需要动态扩展。它的生命周期和大小在请求开始时是未知的(not known a priori),这给内存管理带来了挑战。
为了兼容深度学习框架(如 PyTorch)对连续内存的要求,传统系统会为每个请求预先分配一块连续的内存空间用于存放整个 KV Cache。
这就引出了我们今天要讲的核心问题:内存碎片化。
一、Internal Memory Fragmentation(内部内存碎片)
✅ 定义:
内部碎片是指已分配给某个任务的内存块中,未被实际使用但也不能被其他任务使用的部分。
🔍 在 vLLM 论文中的体现:
假设一个用户请求的最大可能序列长度是 2048 tokens,系统就会提前为其分配足够存储 2048 个 token 的 KV Cache 的连续内存空间。
但是,这个请求最终可能只生成了 300 个 token。
👉 那么剩下的 2048 - 300 = 1748 个 token 所对应的内存空间虽然从未被使用,但仍被该请求“独占”,不能分配给别的请求。
这部分空闲却无法利用的空间就是 内部碎片。
🎯 关键点总结:
- 原因:过度预分配(over-provisioning)
- 特征:内存属于某个请求,但没有被用上
- 结果:造成严重浪费 —— 论文中指出,实际有效利用率只有 20.4% ~ 38.2%
📌 类比操作系统:就像操作系统给进程分配一页内存(比如 4KB),但程序只用了 1KB,剩下 3KB 就是内部碎片。
二、External Memory Fragmentation(外部内存碎片)
✅ 定义:
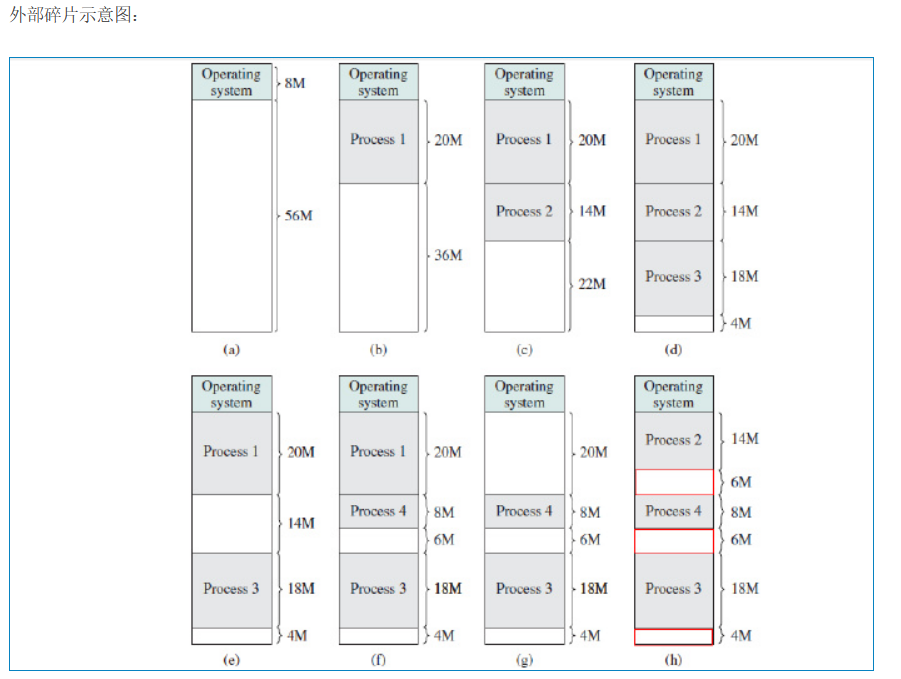
外部碎片是指系统中总的可用内存足够,但由于这些空闲内存不连续,导致无法满足一个需要大块连续内存的请求。
🔍 在 vLLM 论文中的体现:
想象一下,GPU 上有很多小块的空闲内存(比如多个 512-token 大小的空隙),但现在来了一个新的请求,需要一块能容纳 1024 个 token 的连续内存空间。
尽管总共有超过 1024 个 token 的空闲内存,但如果这些内存是分散的、不连续的,系统仍然无法分配,只能报错或拒绝服务。
这就是 外部碎片。
此外,不同请求预分配的大小不同(有的 512,有的 1024,有的 2048),释放后留下各种尺寸的小块内存,加剧了这种碎片问题。
🎯 关键点总结:
- 原因:频繁地分配/释放不同大小的连续内存块
- 特征:总量够,但不连续 → 分配失败
- 影响:降低内存利用率,限制并发请求数量
📌 类比操作系统:就像硬盘上有许多零散的空闲扇区,无法存入一个大文件,即使总空间足够。
💡 总结对比表
| 项目 | 内部碎片 (Internal Fragmentation) | 外部碎片 (External Fragmentation) |
|---|---|---|
| 定义 | 已分配内存中未使用的部分 | 空闲内存总量足够但不连续 |
| 发生位置 | 在已分配的内存块内部 | 在全局内存池中 |
| 主要原因 | 预分配最大长度,实际用得少 | 不同大小的连续块分配与释放 |
| 是否“属于”某个请求 | 是,被某个请求独占 | 否,是自由内存池的一部分 |
| 典型例子 | 分配了 2048 token 空间,只用了 300 | 总共剩 1500 token 空间,但最大小块只有 512 |
| 论文数据支持 | 图2显示仅 20.4%-38.2% 内存被有效使用 | 同样反映在图2的整体低效中 |
🛠️ vLLM 如何解决这些问题?——PagedAttention
论文提出的解决方案叫 PagedAttention,灵感来自操作系统的虚拟内存分页机制。
核心思想:
将 KV Cache 按固定大小划分为多个 block(块),每个 block 可以存储 N 个 token 的 KV 数据(例如 N=16)。
这些 block 不需要在物理内存中连续存放,通过一个“页表”记录逻辑顺序到物理 block 的映射。
就像操作系统把进程的地址空间分成页,映射到物理内存页一样。
这样做的好处:
- 消除内部碎片:按需分配 block,不会为一个短请求预留过多空间。
- 避免外部碎片:只需要找到任意空闲 block 即可分配,不要求大块连续内存。
- 支持内存共享:多个解码路径(如 Beam Search 中的不同 beam)可以共享公共前缀的 block,进一步节省内存。
✅ 总结一句话:
传统方法因强制使用连续内存而导致严重的 内部碎片(浪费已分配空间)和 外部碎片(无法利用零散空间);而 vLLM 的 PagedAttention 借鉴操作系统分页思想,将 KV Cache 分块管理,显著提升了内存利用率和系统吞吐量。
如果你还想了解 PagedAttention 的具体实现细节或性能提升数据,也可以继续问我!
外部碎片示意图:
转自:

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)