调用阿里接口实现图片编辑
目前阿里支持的图像编辑场景很多,比如可以结合多张图片生成一张融合图,也可以基于单张图片和提示词进行图片编辑,还可以修改图片里面的文字内容或样式,只需要一句话就可以完成ps高级功能,大家赶快来尝试一下吧。下面我就演示一下如何实现将图片变成一张帅气的证件照。执行测试:python edit.py。创建测试文件edit.py。
·
目前阿里支持的图像编辑场景很多,比如可以结合多张图片生成一张融合图,也可以基于单张图片和提示词进行图片编辑,还可以修改图片里面的文字内容或样式,只需要一句话就可以完成ps高级功能,大家赶快来尝试一下吧。


下面我就演示一下如何实现将图片变成一张帅气的证件照。
创建测试文件edit.py
import json
import os
from dashscope import MultiModalConversation
import dashscope
# 以下为中国(北京)地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1
dashscope.base_http_api_url = 'https://dashscope.aliyuncs.com/api/v1'
# 模型支持输入1-3张图片
messages = [
{
"role": "user",
"content": [
{"image": "https://assets.fonts.adobe.com/f9f8293c-74a0-4f41-9cbe-1fe10aa986be"},
{"text": "修改为蓝底证件照,人物穿上白色衬衫,黑色西装,打着条纹领带"}
]
}
]
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# 若没有配置环境变量,请用百炼 API Key 将下行替换为:api_key="sk-xxx"
api_key = "sk-xxx"
# 模型仅支持单轮对话,复用了多轮对话的接口
# qwen-image-edit-plus支持输出1-6张图片,此处以2张为例
response = MultiModalConversation.call(
api_key=api_key,
model="qwen-image-edit-plus",
messages=messages,
stream=False,
n=2,
watermark=False,
negative_prompt=" ",
prompt_extend=True,
# 仅当输出图像数量n=1时支持设置size参数,否则会报错
# size="1024*2048",
)
if response.status_code == 200:
# 如需查看完整响应,请取消下行注释
# print(json.dumps(response, ensure_ascii=False))
for i, content in enumerate(response.output.choices[0].message.content):
print(f"输出图像{i+1}的URL:{content['image']}")
else:
print(f"HTTP返回码:{response.status_code}")
print(f"错误码:{response.code}")
print(f"错误信息:{response.message}")
print("请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code")执行测试:python edit.py
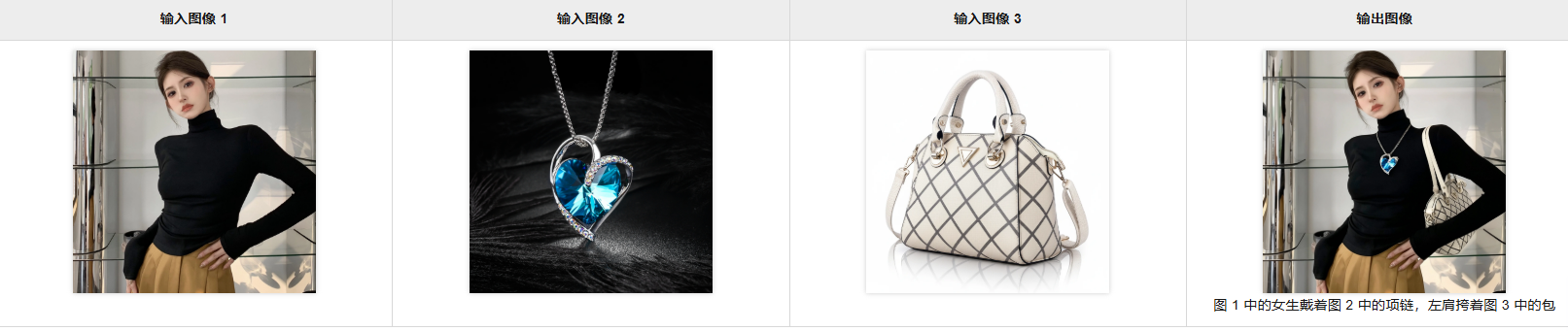
原图为:

生成图为:


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)