【论文阅读14】-推进多模态诊断:将工业文本数据与领域知识和大语言模型相结合
本文提出了一种创新方法,将大型语言模型(LLM)与工业领域知识相结合,用于多模态故障诊断。研究团队通过三阶段框架:1)使用工业文本微调LLM成为领域专家;2)将检查笔记转化为语义向量;3)采用注意力机制加权融合文本和传感器数据,显著提升了水力发电机退化水平预测的准确性(MAE降至4.2)。该方法突破了传统自然语言处理技术难以处理工业专业术语的局限,首次有效利用了长期被忽视的非结构化维修文本数据。研
😊文章背景
题目:Advancing multimodal diagnostics: Integrating industrial textual data and domain knowledge with large language models
期刊:Expert Systems with Applications
检索情况:SCI基础版 工程技术2区(IF 7.5)计算机科学TOP SWJTU A++ EI检索 SWUFE B
SCI升级版 计算机科学1区
作者:Sagar Jose a,∗, Khanh T.P Nguyen a, Kamal Medjaher a, Ryad Zemouri b, Mélanie Lévesque b, Antoine Tahan c
单位:法国塔布奥克西塔尼-比利牛斯技术大学
发表年份:2024.12
关键词:故障检测与诊断;大型语言模型;专家知识;技术语言处理;多模态数据
摘要:大型语言模型(LLM)在各个领域的快速发展和应用,促使人们研究其在预测与健康管理(PHM)领域的潜力,特别是增强数据驱动模型的能力。本研究探讨了利用LLM将非结构化文本数据(如技术文档和维护日志)中积累的领域知识整合到诊断模型中。该研究展示了利用传统上因其复杂性和领域特定术语而未被充分利用的数据的新可能性。通过利用LLM进行上下文理解和从此类文本中提取信息,本研究提出了一种新颖的方法,该方法将文本数据与现有的状态监测系统相结合,以提高诊断模型的准确性。一个关于水力发电机的案例研究说明了将LLM集成到PHM系统中的可行性和价值。研究结果表明,LLM的加入可以带来更明智、更准确的诊断,最终提高工业环境中的运营效率和安全性。
DOI:10.1016/j.eswa.2024.124603
网址:https://www.sciencedirect.com/science/article/pii/S0957417424014702
❓ 研究问题
工业PHM高度依赖传感器数据(振动、温度等),由技术人员产生的大量非结构化文本数据(维修记录、检查笔记)是宝贵的“暗知识”。当前诊断模型面临着两大核心挑战:
-
传统自然语言处理 (NLP) 技术难以有效处理工业文本中的专业术语、缩写和语言噪声。
-
技术人员产生的大量非结构化文本数据长期被排除在数据驱动模型之外,造成信息浪费。
📌 研究目标
利用LLM将非结构化文本数据(如技术文档和维护日志)中积累的领域知识整合到诊断模型中,带来更明智、更准确的诊断。
🧠 所用方法
整体框架
核心思想: 提出一个三阶段框架,让文本信息扮演“专家顾问”角色,而非简单数据源:
-
领域知识微调LLM: 用维修手册等专业文本训练LLM,使其成为领域专家。
-
文本嵌入: 将检查笔记输入微调后的LLM,转化为语义向量。
-
智能加权与预测: 将多模态检测数据特征作为Query查询,将文本向量作为Key和Value,指导模型关注重要的传感器特征,最终预测退化水平。
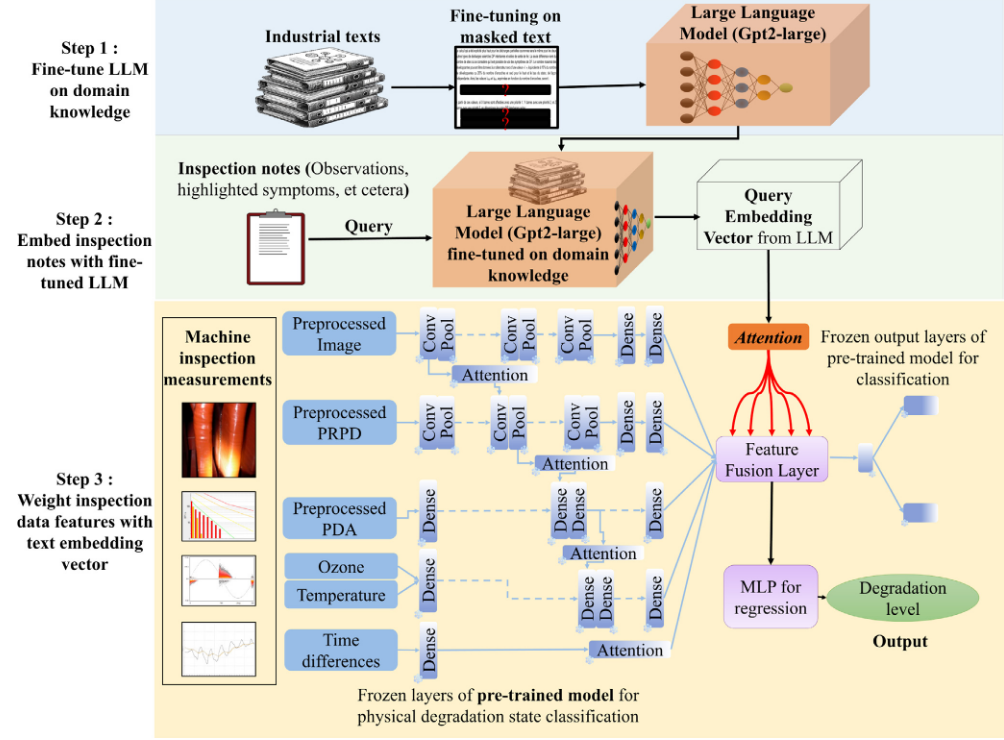
- 领域知识微调LLM:将工业文本(如手册、标准)输入给大模型,通过掩码语言建模对通用LLM进行微调,采用掩码文本微调(掩盖住文本中的部分内容,让LLM对被掩盖住的内容进行预测,从而学习领域知识)的方法对大模型进行微调,使其转化为能深度理解领域语言和知识的专家LLM模型。
- 将技术人员的检查笔记嵌入到微调后的LLM:将检查笔记输入微调后的LLM,LLM将其转化为富含语义信息的文本查询嵌入向量。
- 基于注意力的特征加权与回归预测:使用CNN等神经网络提取多模态检测数据(图像、PRPD、PDA数据等)的特征。关键创新在于,将多模态检测数据特征作为Query查询,将文本向量作为Key和Value。 模型利用检测数据主动'检索'文本中相关的领域知识,利用文本信息对检测特征进行增强和加权,最终输入MLP进行回归预测。
一、领域知识驱动的LLM微调——培养“领域专家”
-
目标:将一个通用的大型语言模型(LLM)转化为精通特定工业领域的“专家”。
-
操作:
-
模型选择:基于计算资源与性能的平衡,本研究选择了
Gpt2-large作为基础模型。 -
微调技术:采用掩码语言建模 进行微调。这种方法通过随机遮盖文档中的部分词汇,让LLM预测被遮盖的内容,从而使其深入学习领域特有的术语、表达逻辑和知识结构。预训练核心技术:掩码语言建模(MLM)与因果语言建模(CLM)-CSDN博客
-
-
创新点:此步骤的创新在于将LLM的通用语言能力与深厚的领域知识相结合。这不同于传统方法使用静态词向量(如Word2Vec),经过微调的LLM能够理解技术文本中复杂的上下文关系,为后续高质量的文字嵌入打下坚实基础。
二、上下文感知的文本嵌入——解读“专家笔记”
-
目标:将技术人员简短、非结构化、可能包含行话和错误的检查笔记,转化为富含语义信息的向量。##工业文本数据的两种主要类型:(1)结构化的知识文档(如指南、标准);(2)非结构化的、充满噪声的检查记录。##
-
操作:微调好的LLM 会将检查笔记转换成一个高维的 “查询嵌入向量”,这个向量捕捉了该段文本在特定工业语境下的深层含义。
-
创新点:此步骤的关键在于利用微调后LLM的上下文理解能力。例如,对于笔记中的“脏”,通用模型可能只理解表面意思,而领域专家LLM能将其关联到“影响散热”、“可能导致过热”等具体故障后果,从而生成更精准的嵌入表示。
三、基于注意力的特征加权——实施“专家决策”
-
目标:将文本嵌入向量与检测数据特征进行智能融合,模拟专家权衡不同证据的过程。
-
操作:这是整个方法最具创新性的环节。论文提出并对比了两种融合策略:
-
直接拼接:将文本嵌入向量与其他传感器数据的特征向量简单拼接在一起,作为模型的输入。
-
注意力加权(论文核心创新):视觉特征作为Q,文本特征作为K和V,计算视觉特征(Q)和文本特征(K)之间的相关性生成注意力分数(权重)。 然后用这些权重对文本特征(V)进行加权,最终将融合后的特征输入到多层感知机(MLP)中进行回归分析。LLM注意力Attention,Q、K、V矩阵通俗理解_qkv矩阵-CSDN博客【论文阅读13】-多模态大型语言模型综述-CSDN博客
##本文采用的是一种高效的“引导式”特征加权融合,与论文13中提到特征级别融合有异同点: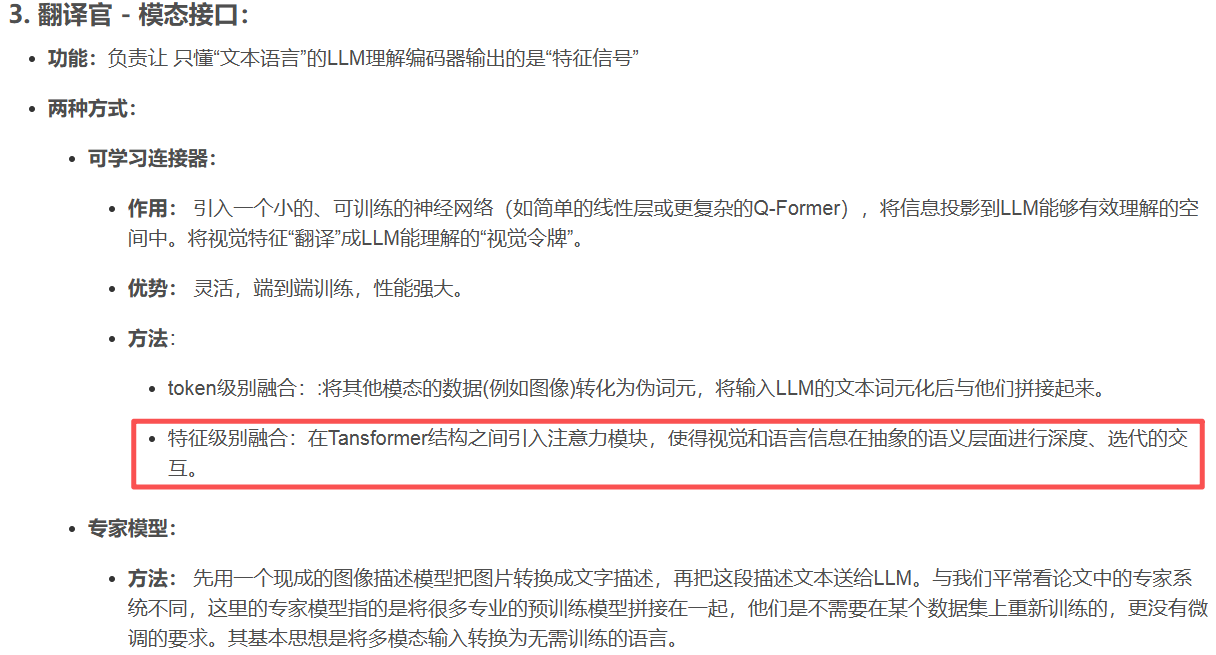
特性
本文的注意力机制
经典的多模态Transformer(如ViLBERT)
融合类型
特征级融合
特征级融合
交互方式
非对称、单向引导
对称、双向深度交互
核心过程
文本作为查询,视觉特征作为键和值。
文本和视觉模态分别通过Transformer层,并通过跨模态注意力层进行双向、多次的信息交换。
计算复杂度
相对较低
非常高
物理隐喻
专家(文本)审阅体检报告(传感器数据)
专家和工程师围绕一张图纸进行多轮深入讨论
-
MLP回归预测:经过加权后的融合特征被送入多层感知机。MLP作为非线性回归器,学习从加权的融合特征到最终退化水平数值之间的复杂映射函数,输出一个具体的、连续的健康指数值,直接反映了专家评估的机器退化程度。什么是MLP?-CSDN博客
-
-
创新点:
-
范式转变:“注意力加权”策略代表了一种范式转变。与直接拼接不同,利用传感器捕捉到的物理现象(Q),去检索和激活文本中对应的专家知识(K/V),从而让模型“注意到”那些能解释当前故障的文字描述计算视觉特征。
-
物理意义对齐:这种方法使模型的内部运作与物理世界的因果关系更加对齐。例如,文本提到“异常振动”,模型就会自动关注振动传感器信号中的异常模式。
-
-
模型改进
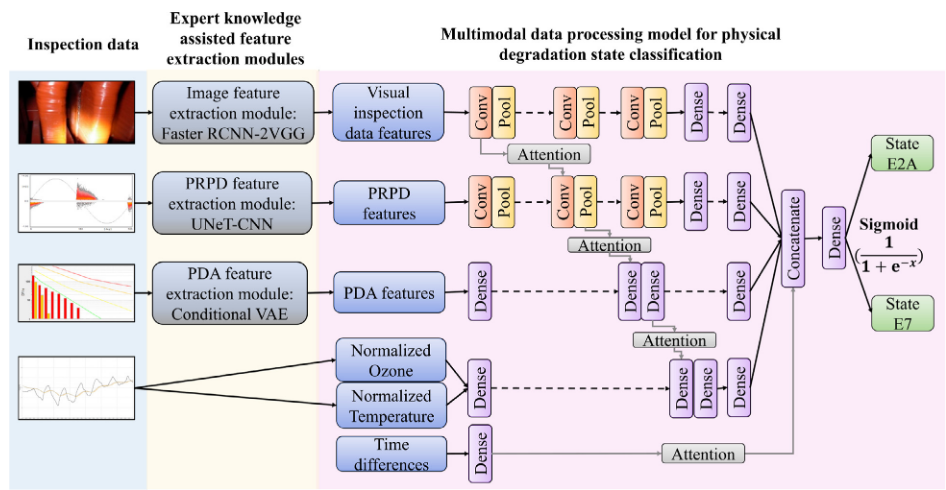
Jose等人(2023)提出的先前用于物理退化状态分类的模型示意图,本文在此模型基础上进行改进。
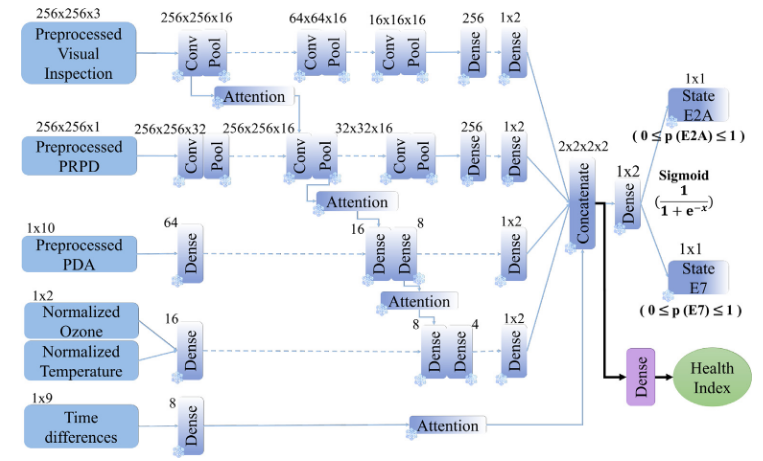
输出从分类改为回归:所有来自先前训练的分类模型的层都被冻结,从融合层添加新的输出(回归)层,以预测一个0-100的健康指数,直接对应专家评估的退化水平。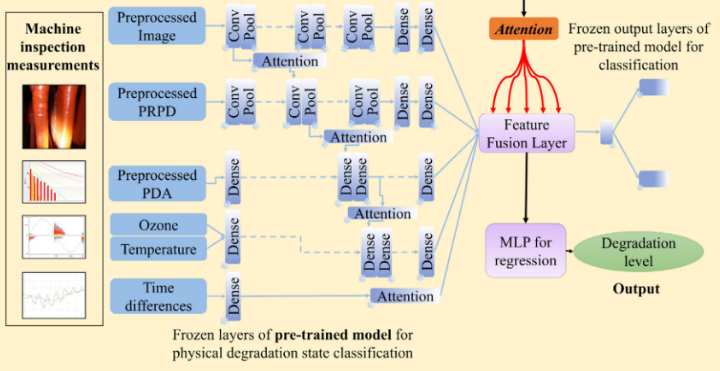
🧪 实验设计与结果
一、数据准备:如何处理复杂、非结构化的工业文本数据
- 目标:将原始、杂乱的工业文本转化为适合大语言模型(LLM)微调和嵌入的干净、规整的数据格式。
- 挑战:
-
来源复杂:来自计算机化维修管理系统的简短记录、技术手册、行业标准等。
-
格式不统一:包含大量特殊字符、拼写错误、领域特定缩写、技术行话以及非标准标点。
-
语言特殊性:案例研究中的数据主要为法语,存在英语-centric模型处理不佳、工具支持有限等问题。
-
- 步骤1:文本清洗与格式化:去除噪声,规范文本
- 特殊字符:谨慎处理法语中的重音符号(如é, è, ê),避免信息丢失。
- 编码管理:解决来自旧版计算机化维护管理系统 (CMMS) 使用非UTF编码导致的乱码问题

- 步骤2:语言特定处理:攻克非英语工业文本的难题
-
定制化分词器:使用能正确处理法语特殊字符的分词工具。
-
字符集归一化:统一文本编码,确保字符一致表示。
-
双语嵌入:采用能够映射法语义到英语语义空间的嵌入技术,以利用强大的英语-centric模型。
-
无用信息剔除:使用命名实体识别(NER)模型移除技术人员姓名等个人身份信息,并过滤掉CMMS系统自动生成的元数据标记。
-
-
步骤3:文档准备与文本提取:为微调准备领域知识文档
-
文本提取:从PDF、Word等格式的原始文档(如标准、指南)中提取纯文本。
-
内容清理:移除无关的格式元素,如页码、页眉页脚、项目符号等,保留核心语义内容。
-
-
步骤4:分块与分词:将长文本处理为适配模型输入的格式
-
分块:根据LLM的上下文长度限制,将长文档分割成大小合适的文本块。分割时需在自然断句处(如句号、段落结尾)进行,以保持语义完整性。
-
分词:使用诸如字节对编码(BPE) 等先进算法,将文本转换为模型能够理解的离散单元(令牌)。
-
二、实验设计
-
案例背景: 真实的水力发电机退化水平预测。
-
数据: 多模态数据(图像、PRPD、PDA、温度等) + 法语检查笔记。
-
评估指标: 平均绝对误差 (MAE)。值越小,预测越准确。
-
消融实验设计: 通过控制变量,系统对比不同因素组合的影响:SCI论文写作系列:一文读懂消融实验!什么是消融实验,消融实验有啥用,写论文怎么用,该不该加,啥时候加.......,仅此一文,通俗讲解!全面掌握!-CSDN博客
-
文本模型类型: 小模型 (FrWac2Vec) vs. 大语言模型 (Gpt2-large)
-
是否微调: 通用模型 vs. 领域知识微调后的模型
-
融合方式: 直接拼接 vs. 注意力加权
-
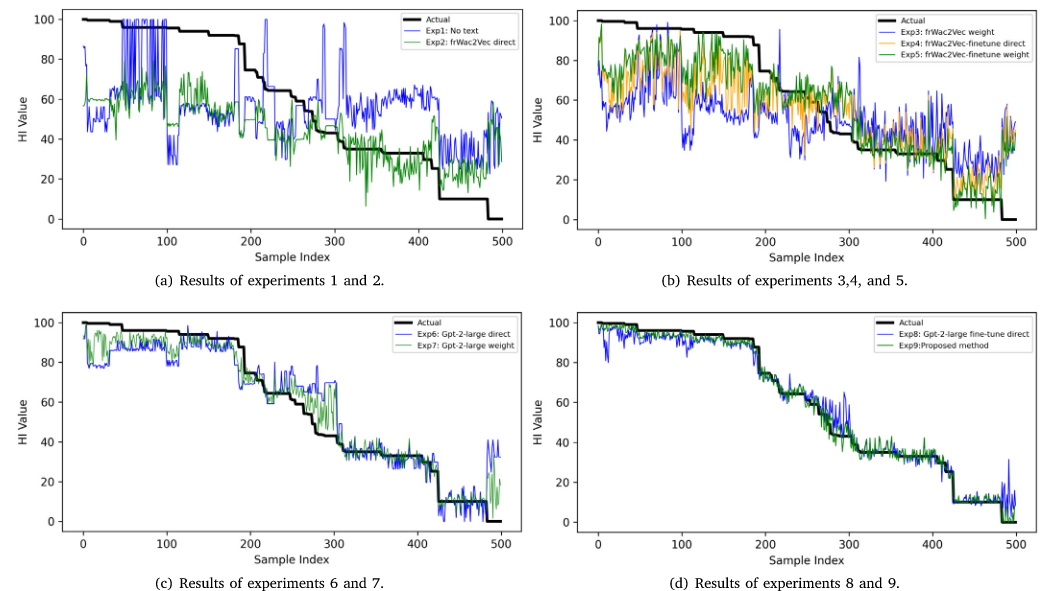
三、实验结果
-
实验1(基线):不使用任何文本数据,误差较大(MAE=44.2)。
-
实验2-5:使用小模型处理文本。结果表明,微调和注意力加权能带来改进,但小模型能力有限。
-
实验6-9:使用大语言模型处理文本。结果显示出巨大提升。
-
实验9(提出的方法):结合了 LLM + 领域知识微调 + 注意力加权,取得了最佳效果,将误差大幅降低至 MAE=4.2。
九个实验模型在 500 个测试样本上的性能表现:
所有实验中MAE平均绝对误差的比较:

✅ 研究结论
-
本研究成功证明了利用大语言模型整合工业文本数据和领域知识,可以极大提升多模态故障诊断模型的性能。
📈 研究意义
-
所提出的“注意力加权”融合范式,为处理多模态工业数据提供了一种新颖且有效的思路。
-
该方法使模型能够模拟人类专家的决策过程,为实现更智能、更可靠的工业 prognostics and health management 系统迈出了重要一步。
🔮 未来研究方向
-
技术深化: 探索参数效率更高的微调技术,以及引入多模态大模型直接理解文本和图像。
-
应用拓展: 将本方法应用于航空航天、智能制造等其他工业领域。
-
实时性研究: 研究该方法在实时或近实时监控场景下的应用与优化。
📕专业名词
1. 核心领域与概念类术语
-
PHM - prognostics and health management( prognostics and health management)
-
外行定义:可以理解为机器的“健康管理与疾病预测系统”。就像我们通过定期体检和健康指标来预测和预防疾病一样,PHM 通过分析机器的数据来评估其当前健康状况并预测它什么时候可能会出故障,从而提前安排维修。
-
-
Fault detection and diagnostics(故障检测与诊断)
-
外行定义:这是 PHM 的核心任务之一。“检测”是发现机器“生病了”(出现了异常),“诊断”是确定它得了什么“病”(故障的类型、位置和严重程度)。
-
-
Multimodal data(多模态数据)
-
外行定义:指来自不同来源、不同形式的多种数据。在这篇论文里,就像医生诊断时不仅要看体温计读数(数值数据),还要看X光片(图像数据)和听病人描述病情(文本数据)。论文中的多模态数据包括振动信号、温度、图像以及维修人员的文字记录等。
-
-
Domain knowledge / Expert knowledge(领域知识/专家知识)
-
外行定义:指在特定行业或领域(如发电机维修)中,专家们所掌握的专业知识、经验和规则。这些知识通常写在技术文档、维修手册、行业标准 等文件中。
-
-
Condition monitoring(状态监测)
-
外行定义:持续地“监听”机器的运行状态,就像用听诊器听心跳一样。通常通过安装传感器来收集数据,以便实时了解机器的健康情况。
-
-
Degradation level(退化水平)
-
外行定义:机器“衰老”或“磨损”的严重程度。通常用一个数值(如健康指数,HI)来表示,0 表示非常健康,100 可能表示即将彻底损坏。
-
-
Health Index - HI(健康指数)
-
外行定义:给机器健康状况打的一个分数(例如0到100分),分数越高代表越不健康。这有助于量化机器的“退化水平”。
-
2. 技术与模型类术语
-
LLM - Large Language Model(大语言模型)
-
外行定义:一种非常强大的“文本理解与生成人工智能”。它通过阅读海量互联网文本进行训练,能够理解语言的复杂含义,并完成回答问题、写作等任务。ChatGPT 就是基于 LLM 的典型应用。本文用它来理解专业的维修文本。
-
-
Fine-tuning(微调)
-
外行定义:对已经训练好的大模型(如LLM)进行“再培训”的过程。用特定领域的资料(如本论文中的维修手册)去教它,让它从一个“通才”变成某个领域的“专家”,从而能更好地理解专业术语和上下文。
-
-
Embedding(嵌入)
-
外行定义:将文字、词语或句子转换成一串数字(即向量)的过程。这串数字在电脑里代表该文字的“含义”。含义相近的词,其对应的数字串在数学空间里的距离也更近。这是让电脑“理解”文字的关键一步。
-
-
Attention mechanism(注意力机制)
-
外行定义:让模型在处理信息时,能够“聚焦”于最重要的部分。就像你在阅读一长段文字时,会不自觉地把注意力放在关键词上一样。在本文中,模型利用从文本中提取的信息,来“关注”传感器数据中更重要的部分。
-
-
MLP - multilayer perceptron(多层感知机)
-
外行定义:一种经典且结构简单的人工神经网络,可以理解为一堆相互连接的“计算单元”叠在一起。它常被用作最终的决策模型,负责根据输入的特征(如处理后的传感器和文本数据)进行计算,输出结果(如健康指数)。
-
-
Transformer architecture(Transformer 架构)
-
外行定义:当前绝大多数先进大语言模型(如GPT系列)所采用的核心技术框架。它的核心就是注意力机制,使其能够非常有效地处理和理解文本等序列数据。
-
3. 数据与文本处理类术语
-
NLP - Natural Language Processing(自然语言处理)
-
外行定义:计算机科学的一个分支,旨在让电脑能够理解、解释和生成人类语言。本文中使用 LLM 就是 NLP 的一种高级应用。
-
-
Unstructured text data(非结构化文本数据)
-
外行定义:指那些没有固定格式、杂乱无章的文本,比如维修人员随手写的笔记、报告中的段落。相对于数据库里整齐排列的表格数据,这种数据更难被电脑自动处理。
-
-
TLP - Technical Language Processing(技术语言处理)
-
外行定义:NLP 的一个特殊分支,专门处理工业、技术领域中的文本,这些文本通常包含大量行话、缩写和特定术语。
-
-
Tokenization(分词/令牌化)
-
外行定义:将一段完整的文本切割成更小单元(如单词、子词或字符)的过程。这是文本处理的第一步,就像把一句话拆分成一个个独立的词。
-
-
RAG - Retrieval-Augmented Generation(检索增强生成)
-
外行定义:一种让大语言模型更准确的方法。当模型需要回答问题时,它会先从外部知识库(如维修手册数据库)中查找相关信息,然后基于找到的信息来生成答案,从而减少“胡说八道”(幻觉)。
-
4. 其他缩写
-
CMMS - Computerized Maintenance Management System(计算机化维修管理系统)
-
外行定义:工厂或企业用来管理和记录设备维护工作的软件系统。维修工单、历史记录、零件库存等信息都存储在里面。
-
-
API - Application Programming Interface(应用程序编程接口)
-
外行定义:一套让不同软件能够相互“对话”和交换数据的规则和工具。本文提到其他研究曾通过 API 调用 GPT 模型。
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)