图文一致指标(论文工作)
上一篇我们简单介绍了图文一致指标的发展脉络和一篇综述文章,下面我们来具体的看一些论文。
上一篇图文一致性指标我们简单介绍了图文一致指标的发展脉络和一篇综述文章,下面我们来具体的看一些论文。
早期阶段工作
在上一篇文章中我们提到,早期阶段模型能力有限(如AttnGAN, DM-GAN),评估方法相对基础粗糙,侧重于判断图像是否“大致相关”,而非精细的一致性。在这里我们介绍一些相关的工作。
-
Inception Score (IS) (2016)
-
提出论文: "Improved Techniques for Training GANs" (Salimans et al., NIPS 2016)
-
核心思想: 评估生成图像的清晰度和多样性。使用预训练的Inception v3模型计算图像的条件概率分布
P(y|x)和边缘分布P(y)。 -
与图文一致性关联: 弱关联。主要评估图像质量和类别多样性,并未直接关联文本。常被不恰当地用于早期文生图评估(模型只需生成清晰且类别多样的图即可得高分),不能有效检测图文一致性。
-
公式:
IS = exp(E_x[KL(p(y|x) || p(y))])
-
-
R-precision / Recall (2018)
-
提出/广泛应用论文: "AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks" (Xu et al., CVPR 2018)
-
核心思想: 基于检索的评估。
-
方法: 对于一个给定生成图像,用其嵌入向量在包含
R个候选文本(其中1个是原始描述,R-1个是随机选的其他描述)的数据集中进行文本检索。 -
R-precision: 原始描述排在检索结果前
R名的概率。常用R=1或R=10。 -
Recall@K: 原始描述在检索结果中出现且排在 Top K 的概率(当
R很大时)。
-
-
与图文一致性关联: 较强关联。评估模型是否能依据图像准确“召回”其对应的原始文本描述,反映了图像与文本在语义空间中的粗粒度对齐程度。是早期衡量图文一致性的重要指标。缺点: 仅衡量整体语义相似度,不检查细节;候选文本的选择影响结果;依赖于文本编码器和图像编码器的质量。
-
-
基于目标检测/分割的指标 (FID Variants) (2018-2019)
-
代表工作: "Obj-GAN: On Evaluating Object Hallucination in Large-Scale Text-to-Image Generation" (Gu et al., arXiv preprint 2019)
-
核心思想: 利用预训练的目标检测器(如Faster R-CNN)或分割模型(如Mask R-CNN)提取图像中的物体信息(类别、数量、位置、边界框精度等),并将其与文本描述中提到的物体进行比较。
-
常见计算方式:
-
Object Occurrence: 计算文本中提到的物体在图像中被检测出的百分比。
-
Precision/Recall/F1 (Object-wise): 将每个提到的物体视为一个“类别标签”,计算生成图像中预测出的物体标签相对于文本描述的精确率、召回率、F1值。可以扩展到属性(颜色等)。
-
-
与图文一致性关联: 直接检测物体级别的存在性。非常适合于评估模型是否能正确生成文本描述中明确提到的物体及其基本属性(如类别)。缺点: 依赖检测/分割模型的精度(容易漏检/错检);无法评估关系、属性组合、抽象概念、场景描述、复杂动词等细粒度语义;需要人工标注边界框或依赖模型输出(引入额外噪声)。
-
第二阶段:CLIP的出现
CLIP
论文题目:Learning Transferable Visual Models From Natural Language Supervision(2021)
论文地址:https://proceedings.mlr.press/v139/radford21a/radford21a.pdf
概述:
CLIP(Contrastive Language-Image Pre-training)原始论文,主要思想是利用对比学习获得文本与图像的对齐关系,先将图像和文本分别编码为特征向量,再将两个特征向量映射到同一个特征空间,通过比较特征向量之间的相似性来学习图像和文本之间的匹配关系。
主要内容:
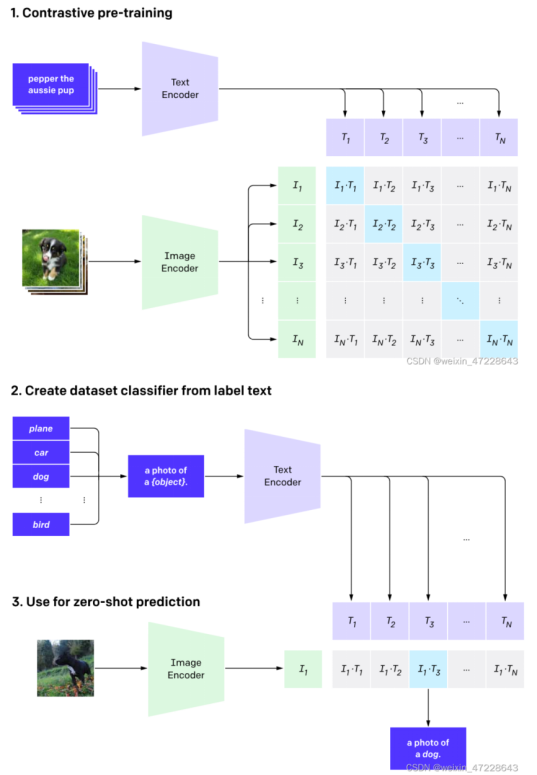
1.编码器与结构
图像编码器:在方法介绍部分,使用的图像编码器为Vision Transformer(ViT),ViT模型引入了多头注意机制,投影n次,dk=dv=dmodel/h,每个投影上并行计算,提高了计算效率。
对比实验部分,使用了使用ResNet50 作为基础架构,并在此基础上根据ResNetD的改进和抗锯齿rect-2模糊池对原始版本进行了修改。同时,还将全局平均池化层替换为注意力池化机制。注意力池化机制通过一个单层的“transformer式”多头QKV注意力,其中查询query是基于图像的全局平均池表示。
文本编码器:文本编辑器是Transformer架构,文本序列用**[SOS]和[EOS]**令牌括起来,[EOS]令牌上transformer最高层的激活函数(层归一化)被用作文本的特征表示,然后线性投影到多模态嵌入空间中。在文本编码器中使用了隐藏的自注意,以保留添加语言模型作为辅助目标的能力。
2.方法
数据集:现有工作主要使用MS-COCO 、Visual Genome 和YFCC100M三个数据集。虽然MS-COCO和Visual Genome是高质量的人群标记数据集,但按照现代标准,它们的规模很小,每个数据集大约有10万张训练照片。相比之下,其他计算机视觉系统在多达35亿张照片上进行了训练。
文章构建了一个新的数据集,其中包含4亿对(图像、文本),这些数据集来自互联网上各种公开可用的资源。为了尝试覆盖尽可能广泛的视觉概念集,文中将搜索(图像,文本)对作为构建过程的一部分,其文本包含500,000个查询集中的一个。
训练方法:
文章主要解决的任务是通过自监督训练,实现0样本的图像分类任务。在当时的图像分类任务需要依赖下游任务目标对模型进行训练(预测几个类别就需要又几个类别的数据对模型进行训练,对于新个体无法给出正确的预测)。CLIP通过获取图像和文本的特征并投影至相同的特征空间后设置正负样本对比学习,将CLIP转换为0样本的分类器。
文章从头开始训练CLIP,而不是用预训练的权重初始化。去掉了表示和对比嵌入空间之间的非线性投影,只使用一个线性投影从每个编码器的表示映射到多模态嵌入空间。
文章还删除了文本转换函数tu,该函数从文本中均匀采样单个句子,因为CLIP的预训练数据集中的许多(图像,文本)对只是单个句子;还简化了图像变换函数tv,从调整大小的图像中随机裁剪是训练期间使用的唯一数据增强。
最后,控制softmax中对数范围的温度参数τ在训练过程中被直接优化为对数参数化的乘法标量,以避免变成超参数。
3.讨论
由于在预训练过程中,图文对的文字是一段描述,而不是单个的文本标签,所以在后续进行图像分类时,标签会被处理为“A photo of 标签”,变成了图像描述与图像的匹配度评分。因此在后续的研究中,CLIP逐渐被引入到探索图文一致的一个重要指标。
BLIP
论文题目:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation(2022)
概述:(BLIP)Bootstrapping Language-Image Pre-training。文章中涉及两个贡献。一提出了BLIP的模型架构,引入多模态架构,实现了更好的图像文本对齐以及生成更好的文本描述。二是利用该架构可以构建Captioner来优化网络收集的图文对中的文本描述。
BLIP的一些架构借鉴了之前ALBEF和VLMO的结构

1.动机
一个是从模型角度出发,当前使用的模型大多基于编码器和编码器-解码器,只使用编码器的模型不能很好的运用到文本生成(如字幕生成),而编码器-解码器则不适用于图像文本检索任务。从数据角度出发,目前的方法如CLIP等使用的数据集是从网上获取的,具有噪声,不是最优解。因此提出了Captioner(Cap)生成更好的描述性文本
2.BLIP模型结构
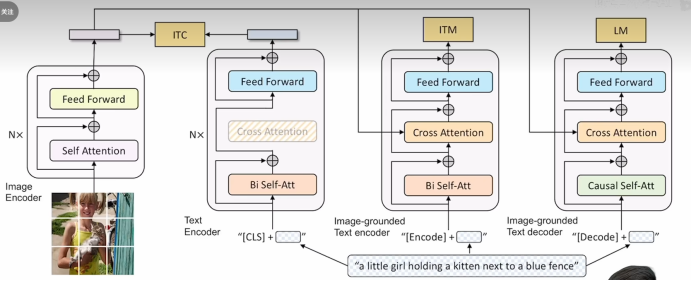
相同颜色共享参数。可以任意两个模型结合使用不同的loss函数训练,完成不同的任务。
3.CapFilter Model
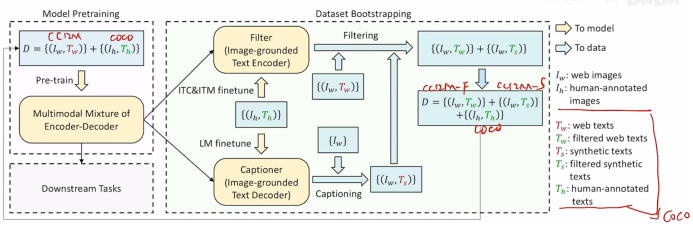
清理数据集,使用BLIP模型将图像模型和文本模型(ITC和ITM)拿出来构成Filter模块,在干净数据集coco上进行微调,使得Filter可以进行图像文本相似度计算,实现对网络数据集的过滤。同时对文本生成模型(LM)也在干净数据集上进行微调,使其能够生成更好的描述构成新的图文数据对,再进行过滤。将原始数据集和生成数据集经过滤后得到新的,质量更优的数据集。
SSD
论文题目:SSD: Towards Better Text-Image Consistency Metric in Text-to-Image Generation(2022)
论文地址:[2210.15235] SSD: Towards Better Text-Image Consistency Metric in Text-to-Image Generation
概述:
本篇论文聚焦于文本到图像生成(Text-to-Image Generation, T2I)任务,提出了一种新的评估指标——语义相似性距离(Semantic Similarity Distance, SSD),用以衡量生成图像与文本描述之间的一致性。基于SSD指标,论文还设计了一种名为并行深度融合生成对抗网络(Parallel Deep Fusion Generative Adversarial Networks, PDF-GAN)的框架,旨在提高生成图像的文本-图像一致性。PDF-GAN引入了两个创新组件:硬负样本句子构造器(Hard-Negative Sentence Constructor, HNSC)和语义投影(Semantic Projection, SProj),以缓解语义不一致的问题并缩小文本-图像语义差距。实验表明,PDF-GAN在CUB和COCO数据集上的表现优于当前最先进的方法,能够显著提高文本-图像一致性,同时保持图像质量。
主要内容:
1.Semantic Similarity Distance (SSD) 指标
理论基础:SSD从分布的角度出发,结合两个项来衡量文本-图像一致性:第一项(SS)直接衡量文本-图像语义相似性,反映生成图像与文本之间的语义偏差;第二项(dSV)评估生成图像与真实图像在文本条件下的语义变化差异,确保生成图像的语义多样性与真实图像一致。
与现有指标的关系:SSD在理论上与CLIPScore(CS)和条件弗雷歇 inception 距离(CFID)存在关联,但通过实验验证,SSD在衡量语义一致性方面展现出更理想的特性。
SSD的具体思路:
在CLIP模型的基础上,将图像和文本映射到一个联合语言-视觉嵌入空间,通过计算生成图像和文本的嵌入分布之间的差异来衡量文本-图像一致性。
SSD的计算公式结合了第一矩(文本-图像语义相似性)和第二矩(文本条件下生成图像与真实图像的语义变化差异),从而更全面地评估文本-图像一致性。
2.PDF-GAN框架
并行融合模块(PFM):该模块用于融合不同粒度的文本信息(全局特征和局部特征),通过深融合(Deep Fusion)技术,有效地捕捉文本中的语义信息,从而提高文本-图像一致性。
硬负样本句子构造器(HNSC):HNSC通过根据词性替换文本描述中的词汇来构建硬负样本句子,为判别器提供更稳定和可控的负样本,帮助模型学习更精确的语义。
语义投影(SProj):SProj通过约束语义损失的优化方向,将语义损失的优化方向投影到与对抗损失不冲突的方向,从而克服语义差距问题,平衡文本-图像一致性和图像质量之间的优化。
PDF-GAN的实现过程:
生成器和判别器的结构:生成器G利用PFM融合全局和局部文本信息,通过多层处理生成图像;判别器D采用全局和局部两个判别器,分别对全局特征和局部特征进行判别。
训练目标:PDF-GAN的训练目标包括对抗损失、语义感知损失和对比损失。对抗损失用于训练生成器和判别器的对抗过程;语义感知损失通过全局和局部语义感知损失来增强生成图像的语义信息;对比损失用于进一步排斥不匹配的样本。
HNSC的实现:在给定描述中,根据词性(名词、动词和形容词)随机替换词汇,生成硬负样本句子,为判别器提供更具挑战性的负样本。
SProj的实现:在训练过程中,当计算对抗损失和语义损失的梯度后,通过投影操作将语义损失的优化方向调整到与对抗损失不冲突的方向,从而平衡模型在语义一致性和图像质量之间的优化。
结论与不足:
主要结论:论文提出的SSD指标能够更准确地反映文本-图像一致性,并且可以通过SSD指导文本到图像模型的设计。PDF-GAN框架通过融合不同层次的语义信息,并利用HNSC和SProj组件,有效地提高了生成图像的文本-图像一致性,同时保持了图像质量。
不足之处:
HNSC的负样本构建策略:尽管HNSC通过词性替换生成硬负样本句子,但这种方法可能无法完全覆盖文本语义的多样性,存在改进空间,例如可以探索更复杂的负样本构建策略。
SProj的优化方向约束机制:SProj通过投影操作约束语义损失的优化方向,但在某些情况下,投影后的优化方向可能仍然无法完全避免与对抗损失的冲突,需要进一步研究更有效的优化方向约束方法。
模型的泛化能力:虽然PDF-GAN在CUB和COCO数据集上表现出色,但其在其他数据集或跨领域任务中的泛化能力尚未得到充分验证,需要进一步的实验来验证其广泛适用性。
ImageReward
论文题目:ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation(2023)
论文地址:ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
概述:将NLP领域的基于人类偏好的想法引入至文生图模型,建立了一个通用的基于人类偏好的奖励模型ImageReward。根据新建立的ImageReward模型提出了ReFL算法对扩散模型直接生图。
主要内容:
1.ImageReward的构建
数据收集:从 DiffusionDB 中选择多样化的真实用户提示词,并采集相应的图像,形成候选对。
人类标注:标注流程分为三个阶段,首先是提示词标注,包括对提示词进行分类和识别问题;接着是对每个文本 - 图像对进行评分,从文本 - 图像对齐、保真度和总体满意度等维度进行七级评分,并检查图像是否存在重复生成、身体问题等七类问题;最后是图像排名,标注者根据评分标准对同一提示词生成的图像进行排序。
模型训练:基于标注数据,将偏好标注转化为排名问题,采用 BLIP 作为骨干网络提取图像和文本特征,结合交叉注意力机制,通过 MLP 生成用于偏好比较的标量值。训练过程中,冻结部分骨干网络层参数以防止过拟合,并通过网格搜索确定最优训练超参数。
2.ReFL算法的构建
训练设置:以 Stable Diffusion v1.4 作为基线生成模型,在 8 个 40GB NVIDIA A100 GPU 上进行半精度微调。预训练数据集来自 LAION-5B 的一个 625k 子集,提示词集从 DiffusionDB 中采样。设定相关超参数,如学习率、批量大小等。
算法细节:在 ReFL 算法中,随机选取一个去噪步骤 t(范围在 [T₁, T₂] 之间),从高斯分布中采样噪声作为潜在变量,从 t 步开始进行去噪过程,预测原始潜在变量,并根据 ImageReward 的分数计算损失,将损失反向传播更新模型参数。同时,为了防止过拟合和稳定微调过程,对 ReFL 损失进行重加权,并结合预训练损失进行优化。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)