生成式深度学习全面解析:从RNN到VAE、GAN的原理与实战
本文系统性地介绍了生成式深度学习的三大核心模型:RNN、VAE和GAN,从理论基础到代码实战提供了完整的知识体系。
生成式深度学习
1. 什么是生成式深度学习?
- 目标:不仅能“识别”,还能“创造”新的数据。
一、核心概念:从“判别”到“生成”
要理解生成式深度学习,首先要将其与我们所熟知的判别式模型进行对比。
- 判别式模型
- 核心问题: “这是什么?” 或 “它属于哪一类?”
- 任务: 学习类别之间的决策边界。它分析输入数据,然后输出一个标签或一个概率(例如,这是一只猫的概率是90%)。
- 目标: 区分不同的数据。
- 例子: 图像分类(识别猫狗)、垃圾邮件检测、预测房价。
- 比喻: 一个艺术鉴定师,他能判断一幅画是真是假,但自己画不出一幅逼真的名画。
- 生成式模型
- 核心问题: “数据是如何生成的?” 或 “像这样的数据是如何分布的?”
- 任务: 学习训练数据的概率分布。它理解了数据的内在结构和模式,然后可以从这个学到的分布中采样,创造出全新的、但与训练数据相似的数据样本。
- 目标: 创造新的数据。
- 例子: 生成不存在的人脸、创作音乐、编写一段连贯的文本。
- 比喻: 一个画家,他研究了大量梵高的画作后,能够自己创作出一幅具有梵高风格的全新画作。
简单总结:判别式模型是“分析师”,而生成式模型是“创造者”。
2. 文本生成(基于循环神经网络 RNN)
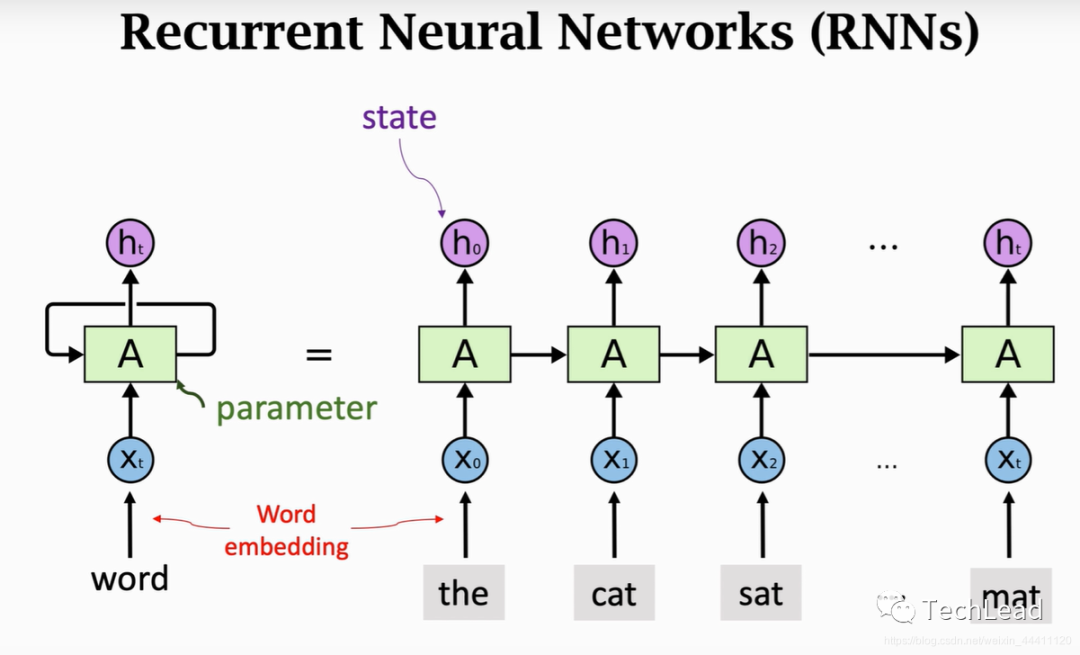
一、核心思想:序列建模
文本生成本质上是一个序列到序列 的问题。其核心思想是:
给定前面所有的词(或字符),预测下一个最可能出现的词(或字符)。
通过不断地将预测出的新词作为输入的一部分,再预测下一个词,就可以像滚雪球一样生成任意长度的文本序列。
1.1 建模方式:语言模型
文本生成任务可以形式化为一个语言模型问题。语言模型的目标是为一个序列分配一个概率:P(w₁, w₂, w₃, ..., w_T)
其中 w_i 表示序列中的第 i 个词。通过链式法则,这个联合概率可以分解为一系列条件概率的乘积:
P(w₁, w₂, ..., w_T) = P(w₁) * P(w₂|w₁) * P(w₃|w₁, w₂) * ... * P(w_T|w₁, w₂, ..., w_{T-1})
文本生成,就是基于这个条件概率,在每一步选择下一个词的过程。
3. 图像生成:自编码器 & VAE
一、自编码器
1.1 核心思想与目标
自编码器的核心思想是学习数据的压缩表示。它是一种无监督模型,通过一个特殊的任务来学习:尝试重建其输入。
其根本目标不是生成新数据,而是通过重建过程,学习到数据中最重要的特征和内在结构。
1.2 基本架构:编码与解码
自编码器由两个对称的部分组成:
- 编码器:
- 功能:将高维的输入数据(如图像)映射到一个低维的潜在空间。
- 过程:通过一系列神经网络层(如全连接层或卷积层)逐步压缩数据,丢弃冗余信息(如噪声、不重要的细节),最终提取出数据的本质特征。这个过程的输出被称为潜在编码或瓶颈层。
- 解码器:
- 功能:将低维的潜在编码重新映射回原始的高维数据空间。
- 过程:试图利用编码器学到的“精髓”,恢复出与原始输入尽可能相似的数据。这是一个从特征到具体数据的“翻译”过程。
信息瓶颈:潜在空间的维度远小于输入空间,这一约束迫使模型不能简单地记忆输入,而必须学会识别和保留数据中最具信息量的模式。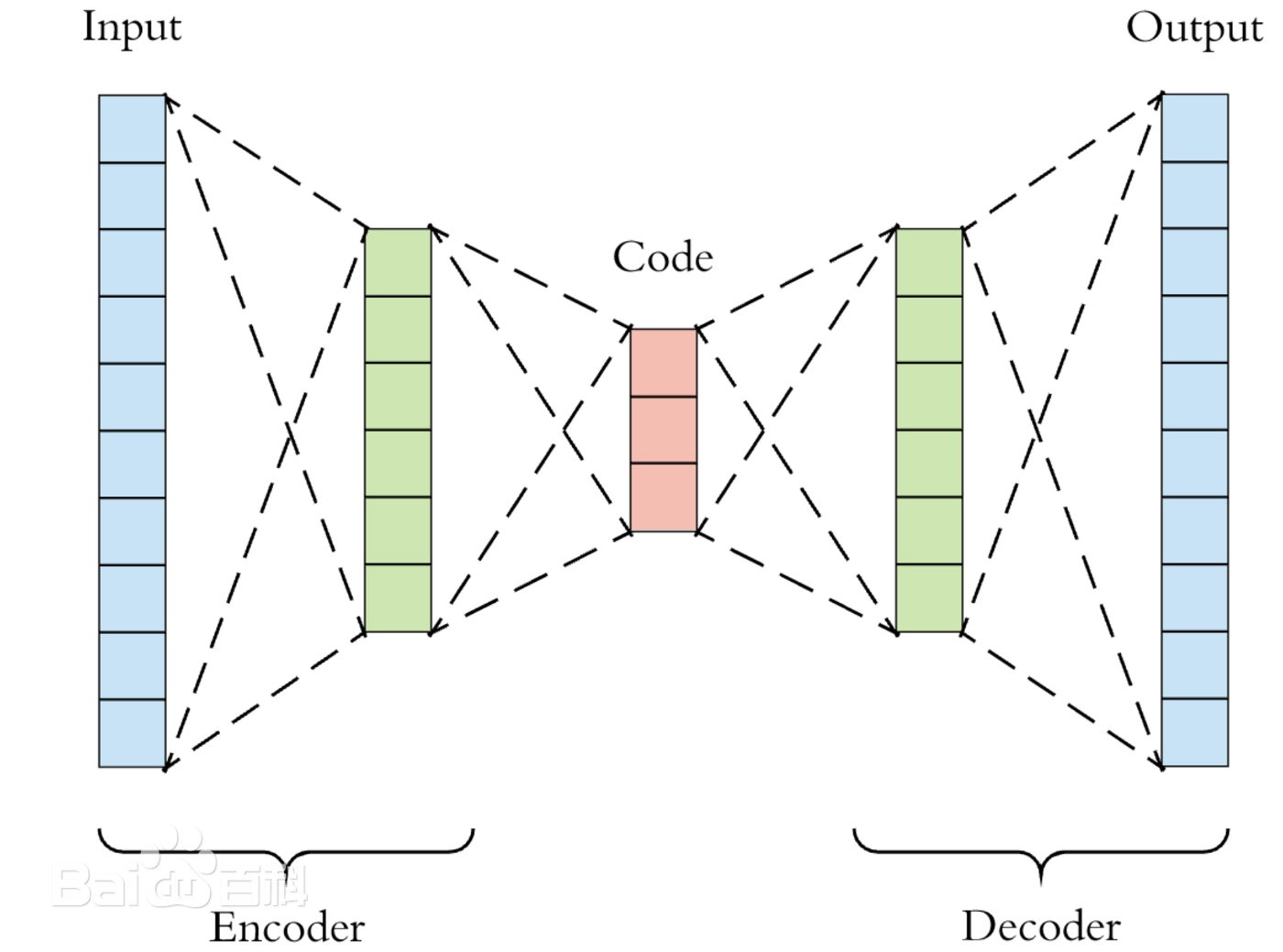
1.3 损失函数
自编码器通过最小化重建损失 来训练。该损失衡量了原始输入与解码器输出之间的差异。常用的重建损失包括:
- 均方误差:适用于一般的实值数据。
- 二元交叉熵:当输入数据被归一化到[0,1]区间时(如图像像素),效果良好。
1.4 局限性:为何不是理想的生成模型?
尽管自编码器能学习到有用的特征,但它本质上不是一个合格的生成模型,原因如下:
- 潜在空间缺乏结构:自编码器只关心编码-解码的效率,不关心潜在空间本身的形态。潜在空间可能是不连续和不规则的。
- 无法进行有效采样:由于潜在空间的结构未知,如果我们从一个随机点(如标准正态分布中采样)进行解码,很可能会生成毫无意义的、混乱的输出,因为这个点可能位于模型从未学习过的区域。
- 功能定位:其主要优势在于降维和特征学习,而非创造新样本。
二、变分自编码器
VAE是为了解决标准自编码器的生成缺陷而被提出的。它从根本上改变了编码器的输出和模型的目标,将概率论引入到框架中。
2.1 核心哲学:概率生成框架
VAE的核心思想是:我们假设所有的数据点都是由某个潜在的、看不见的随机变量生成的。模型的目标是学习这个生成过程。
具体来说,VAE不再将输入图像映射为一个固定的点,而是映射为潜在空间中的一个概率分布。
2.2 关键创新与架构
a) 编码器输出概率分布
在VAE中,编码器不再输出一个单一的潜在编码,而是输出一个概率分布的参数。通常,这个分布被假设为高斯分布,因此编码器输出两个向量:
- 均值向量:表示该数据点在潜在空间中最可能的位置。
- 对数方差向量:表示该数据点在潜在空间中的不确定性或分布范围。
b) 重参数化技巧
这是一个至关重要的技术,使得梯度能够通过随机采样节点反向传播。过程如下:
- 编码器输出均值
μ和对数方差log(σ²)。 - 从标准正态分布中采样一个随机噪声
ε ~ N(0, I)。 - 通过公式
z = μ + σ ⊙ ε计算最终的潜在向量z。- 这里
σ = exp(0.5 * log(σ²))。 - 这个技巧将随机性分离出来,使得
μ和σ仍然是可训练的参数,梯度可以正常回传。
- 这里
c) 解码器作为生成器
解码器的功能保持不变,但它现在被解释为一个生成模型:P(X|Z)。即,给定一个从潜在分布中采样的点 z,解码器需要生成一个看起来像真实数据的数据点 x。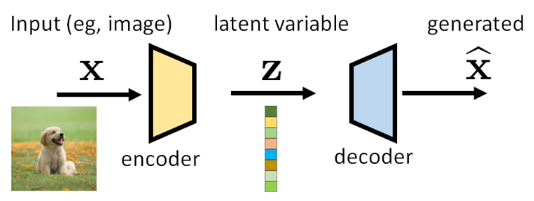
2.3 VAE的损失函数
VAE的损失函数由两部分组成,反映了模型的双重目标:
总损失 = 重建损失 + KL散度损失
a) 重建损失
- 作用:与标准自编码器相同,确保解码器能够从潜在编码中有效地重建输入数据。它衡量了生成质量。
- 常用形式:均方误差或二元交叉熵。
b) KL散度损失
- 作用:正则化项。它强制让编码器输出的分布
q(z|x)接近标准正态分布p(z) = N(0, I)。 - 意义:
- 结构化潜在空间:通过让所有数据的后验分布都向同一个中心(标准正态分布)靠拢,确保了潜在空间是连续且平滑的。
- 实现生成能力:因为潜在空间被规整为标准正态分布,在生成新样本时,我们可以自信地从
N(0, I)中随机采样一个点z,并输入解码器,期望得到一个有意义的输出。潜在空间中相邻的点会对应着语义上相似的图像,实现了有意义的插值。
三、VAE vs 自编码器:核心区别
| 特征 | 自编码器 | 变分自编码器 |
|---|---|---|
| 编码器输出 | 确定性的潜在向量(一个点) | 概率分布的参数(均值μ和方差σ²) |
| 潜在空间 | 不规则、不连续、无结构 | 连续、平滑、结构化(近似标准正态分布) |
| 采样方式 | 直接使用编码输出 | 从分布中采样:Z = μ + σ⊙ε |
| 核心目标 | 数据压缩与特征提取 | 学习数据的生成过程 |
| 损失函数 | 仅有重建损失 | 重建损失 + KL散度(正则化项) |
| 生成能力 | 弱,无法保证随机采样的有效性 | 强,可以从潜在分布中采样生成新样本 |
| 本质 | 一种识别模型 | 一种生成模型 |
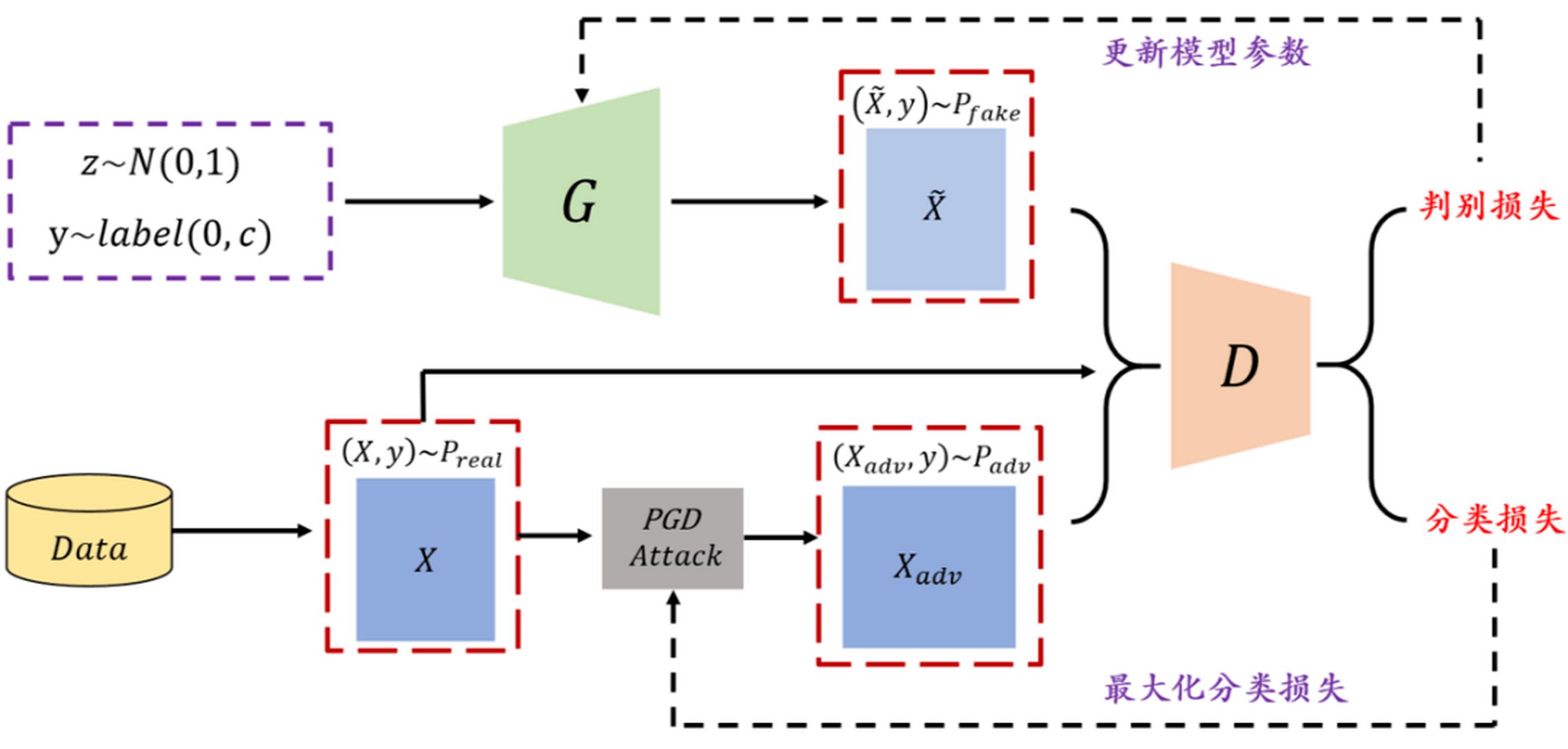
4. 生成对抗网络(GAN)
一、核心思想:博弈论的巧妙应用
GAN的核心灵感来源于博弈论中的零和博弈。它摒弃了直接学习数据分布的传统思路,转而引入一个对抗性过程,让两个神经网络模型通过相互竞争、相互欺骗来共同进化。
二、GAN的基本架构
GAN由两个独立的神经网络构成:
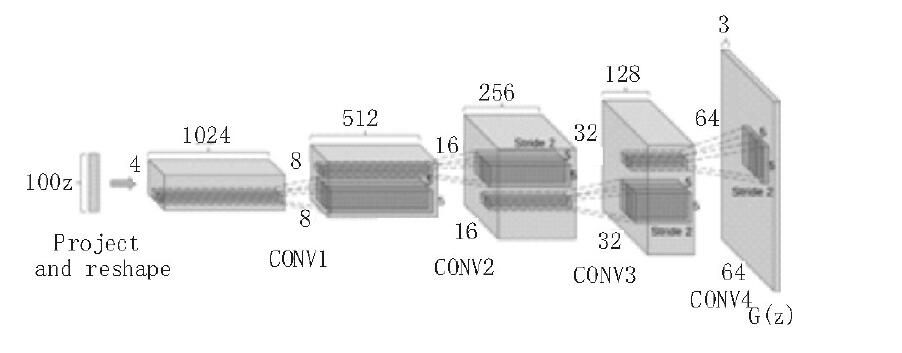
2.1 生成器
- 目标:捕获真实数据的分布,将随机噪声映射到数据空间,生成足以“以假乱真”的样本。
- 输入:一个从简单先验分布(如标准正态分布、均匀分布)中随机采样的噪声向量z。这个噪声为生成过程提供了随机性和多样性。
- 输出:一个假样本G(z),其维度与真实数据相同(例如,一张28x28的假图像)。
- 策略:学习如何变换随机噪声,使得生成的样本能够欺骗判别器,让其误判为“真”。
2.2 判别器
- 目标:估计一个样本来自真实数据分布而非生成器的概率。本质上,它是一个二分类器。
- 输入:一个数据样本,可以是真实样本x(来自训练集),也可以是生成样本G(z)。
- 输出:一个标量概率值D(·),表示输入样本是真实的置信度(例如,接近1表示“真”,接近0表示“假”)。
- 策略:学习准确区分真实数据与生成器制造的数据。
三、对抗训练过程与目标函数
3.1 目标函数
GAN的训练目标可以用以下极小极大博弈公式来概括:
min_G max_D V(D, G) = E_x~p_data(x)[log D(x)] + E_z~p_z(z)[log(1 - D(G(z)))]
这个公式可以分解理解:
- 判别器的目标(max_D):
E[log D(x)]:对于真实数据,判别器希望输出D(x)接近1,使这项最大化。E[log(1 - D(G(z)))]:对于生成数据,判别器希望输出D(G(z))接近0,使这项最大化。- 综上,判别器希望最大化整个目标函数V。
- 生成器的目标(min_G):
- 生成器只能影响公式的第二项。它希望判别器对它的作品判断失误,即希望
D(G(z))接近1,从而使log(1 - D(G(z)))变得非常小(一个很大的负数)。 - 因此,生成器希望最小化整个目标函数V,特别是最小化第二项。
- 生成器只能影响公式的第二项。它希望判别器对它的作品判断失误,即希望
3.2 训练算法
训练是一个迭代过程,通常交替优化判别器和生成器:
- 固定生成器G,训练判别器D(k步):
- 从真实数据中采样一个批次
{x₁, x₂, ..., x_m}。 - 从噪声先验中采样一个批次
{z₁, z₂, ..., z_m}。 - 通过生成器得到假数据批次
{G(z₁), G(z₂), ..., G(z_m)}。 - 通过梯度上升更新判别器参数,以最大化
(1/m) Σ [log D(xᵢ) + log(1 - D(G(zᵢ)))]。
- 从真实数据中采样一个批次
- 固定判别器D,训练生成器G(1步):
- 从噪声先验中采样一个批次
{z₁, z₂, ..., z_m}。 - 通过梯度下降更新生成器参数,以最小化
(1/m) Σ log(1 - D(G(zᵢ)))。在实践中,为了提供更强的梯度,通常改为最大化(1/m) Σ log(D(G(zᵢ)))。
- 从噪声先验中采样一个批次
这个“一步生成器,k步判别器”的过程不断重复,直到达到某种平衡(纳什均衡)。
四、GAN的优势
- 生成质量高:GAN生成的样本在清晰度和逼真度上往往优于同时期的VAE和自回归模型。它避免了VAE可能产生的模糊问题。
- 无需明确的概率分布:GAN不需要对数据分布
p_data(x)进行任何显式假设,而是通过对抗过程直接学习从简单分布到复杂分布的映射。 - 训练灵活性:只要可以定义梯度,就可以与任何类型的生成器和判别器架构结合,非常灵活。
- 隐式特征学习:判别器在训练过程中会学习到数据的高级、有区分度的特征。
附代码实现
以下是 RNN、VAE、GAN 分别实现的完整代码示例:
1. RNN 文本生成实现
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class CharRNN(nn.Module):
def __init__(self, vocab_size, hidden_size, num_layers=2):
super(CharRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.rnn = nn.LSTM(hidden_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x, hidden=None):
# x shape: (batch_size, seq_len)
x = self.embedding(x) # (batch_size, seq_len, hidden_size)
if hidden is None:
hidden = self.init_hidden(x.size(0))
out, hidden = self.rnn(x, hidden) # out: (batch_size, seq_len, hidden_size)
out = self.fc(out) # (batch_size, seq_len, vocab_size)
return out, hidden
def init_hidden(self, batch_size):
return (torch.zeros(self.num_layers, batch_size, self.hidden_size),
torch.zeros(self.num_layers, batch_size, self.hidden_size))
# 训练示例
def train_rnn():
# 假设我们有文本数据
text = "hello world " * 100
chars = sorted(list(set(text)))
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
vocab_size = len(chars)
seq_length = 25
# 准备训练数据
inputs = []
targets = []
for i in range(0, len(text) - seq_length):
inputs.append([char_to_idx[ch] for ch in text[i:i+seq_length]])
targets.append([char_to_idx[ch] for ch in text[i+1:i+seq_length+1]])
inputs = torch.tensor(inputs)
targets = torch.tensor(targets)
# 模型训练
model = CharRNN(vocab_size, 128, 2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(1000):
hidden = model.init_hidden(inputs.size(0))
optimizer.zero_grad()
output, hidden = model(inputs, hidden)
loss = criterion(output.view(-1, vocab_size), targets.view(-1))
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
return model, char_to_idx, idx_to_char
# 文本生成
def generate_text(model, start_string, char_to_idx, idx_to_char, length=100):
model.eval()
chars = [ch for ch in start_string]
hidden = model.init_hidden(1)
for _ in range(length):
input_tensor = torch.tensor([[char_to_idx[ch] for ch in chars[-10:]]])
output, hidden = model(input_tensor, hidden)
# 采样下一个字符
probs = torch.softmax(output[0, -1], dim=0).detach().numpy()
next_char = np.random.choice(list(idx_to_char.keys()), p=probs)
chars.append(idx_to_char[next_char])
return ''.join(chars)
2. VAE 图像生成实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(image_size, h_dim),
nn.LeakyReLU(0.2),
nn.Linear(h_dim, h_dim),
nn.LeakyReLU(0.2)
)
self.fc_mu = nn.Linear(h_dim, z_dim)
self.fc_logvar = nn.Linear(h_dim, z_dim)
self.decoder = nn.Sequential(
nn.Linear(z_dim, h_dim),
nn.LeakyReLU(0.2),
nn.Linear(h_dim, h_dim),
nn.LeakyReLU(0.2),
nn.Linear(h_dim, image_size),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
def vae_loss(recon_x, x, mu, logvar):
# 重建损失
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
# KL散度
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
def train_vae():
# 数据加载
transform = transforms.Compose([transforms.ToTensor()])
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True, transform=transform),
batch_size=128, shuffle=True)
# 模型初始化
model = VAE()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练循环
for epoch in range(50):
model.train()
train_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = vae_loss(recon_batch, data, mu, logvar)
loss.backward()
train_loss += loss.item()
optimizer.step()
print(f'Epoch {epoch}, Loss: {train_loss/len(train_loader.dataset):.4f}')
return model
# 生成新样本
def generate_vae_samples(model, num_samples=64):
model.eval()
with torch.no_grad():
z = torch.randn(num_samples, 20)
samples = model.decode(z)
return samples.view(-1, 1, 28, 28)
# 可视化生成结果
def plot_vae_samples(samples):
fig, axes = plt.subplots(8, 8, figsize=(10, 10))
for i, ax in enumerate(axes.flat):
ax.imshow(samples[i].squeeze(), cmap='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
3. GAN 图像生成实现
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
class Generator(nn.Module):
def __init__(self, latent_dim=100, img_shape=(1, 28, 28)):
super(Generator, self).__init__()
self.img_shape = img_shape
self.latent_dim = latent_dim
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *self.img_shape)
return img
class Discriminator(nn.Module):
def __init__(self, img_shape=(1, 28, 28)):
super(Discriminator, self).__init__()
self.img_shape = img_shape
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
def train_gan():
# 超参数
latent_dim = 100
lr = 0.0002
b1 = 0.5
b2 = 0.999
n_epochs = 50
# 数据加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True, transform=transform),
batch_size=64, shuffle=True)
# 初始化模型
generator = Generator(latent_dim)
discriminator = Discriminator()
# 损失函数和优化器
adversarial_loss = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
# 训练循环
for epoch in range(n_epochs):
for i, (imgs, _) in enumerate(dataloader):
batch_size = imgs.shape[0]
# 真实和假标签
real = torch.ones(batch_size, 1)
fake = torch.zeros(batch_size, 1)
# ---------------------
# 训练判别器
# ---------------------
optimizer_D.zero_grad()
# 真实图像的损失
real_loss = adversarial_loss(discriminator(imgs), real)
# 假图像的损失
z = torch.randn(batch_size, latent_dim)
gen_imgs = generator(z)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# ---------------------
# 训练生成器
# ---------------------
optimizer_G.zero_grad()
# 生成器希望假图像被判断为真
g_loss = adversarial_loss(discriminator(gen_imgs), real)
g_loss.backward()
optimizer_G.step()
print(f"[Epoch {epoch}/{n_epochs}] [D loss: {d_loss.item():.4f}] [G loss: {g_loss.item():.4f}]")
# 每10个epoch保存生成样本
if epoch % 10 == 0:
save_image(gen_imgs.data[:25], f"gan_samples_{epoch}.png", nrow=5, normalize=True)
return generator, discriminator
# 生成新样本
def generate_gan_samples(generator, num_samples=64):
generator.eval()
with torch.no_grad():
z = torch.randn(num_samples, 100)
samples = generator(z)
return samples
# 可视化工具
def save_image(tensor, filename, nrow=8, padding=2, normalize=False):
from torchvision.utils import save_image as torch_save_image
torch_save_image(tensor, filename, nrow=nrow, padding=padding, normalize=normalize)
# 使用示例
if __name__ == "__main__":
# 训练RNN
print("训练RNN...")
rnn_model, char_to_idx, idx_to_char = train_rnn()
generated_text = generate_text(rnn_model, "hello", char_to_idx, idx_to_char)
print(f"生成的文本: {generated_text}")
# 训练VAE
print("训练VAE...")
vae_model = train_vae()
vae_samples = generate_vae_samples(vae_model)
plot_vae_samples(vae_samples)
# 训练GAN
print("训练GAN...")
gan_generator, gan_discriminator = train_gan()
gan_samples = generate_gan_samples(gan_generator)
plot_vae_samples(gan_samples) # 复用VAE的可视化函数
各模型特点总结:
RNN:
- 应用:序列数据生成(文本、时间序列)
- 特点:有记忆能力,适合处理时序数据
- 输出:生成的文本序列
VAE:
- 应用:图像生成、数据压缩
- 特点:训练稳定,有明确的概率解释
- 输出:生成的图像样本(可能稍模糊)
GAN:
- 应用:高质量图像生成
- 特点:生成质量高,但训练不稳定
- 输出:清晰的生成图像
每个模型都有其独特的优势和应用场景,可以根据具体任务需求选择合适的模型。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)