大语言模型幻觉问题全面解析与解决方案指南
文章详细介绍了大语言模型的六种幻觉类型:事实性、时间性、上下文、语言、外部和内部幻觉,及其对模型可靠性的影响。针对每种幻觉,提出了相应解决方案:RAG技术、时间感知提示、Lookback Lens、语义一致性过滤、矛盾检测和指针/拷贝机制。这些实用技术能有效提升大语言模型的输出准确性,是开发者解决模型幻觉问题的完整参考指南。
文章详细介绍了大语言模型的六种幻觉类型:事实性、时间性、上下文、语言、外部和内部幻觉,及其对模型可靠性的影响。针对每种幻觉,提出了相应解决方案:RAG技术、时间感知提示、Lookback Lens、语义一致性过滤、矛盾检测和指针/拷贝机制。这些实用技术能有效提升大语言模型的输出准确性,是开发者解决模型幻觉问题的完整参考指南。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
在当今人工智能领域,大语言模型(LLMs)已经成为了自然语言处理的核心力量。然而,随着模型规模的不断扩大,一个令人头疼的问题也逐渐浮幻觉(Hallucinations)。这些幻觉以各种形式出现,严重影响了模型输出的准确性和可靠性。本文将深入探讨大语言模型幻觉的类型、成因,并结合实际案例,展示如何通过一系列技术手段解决这些问题。
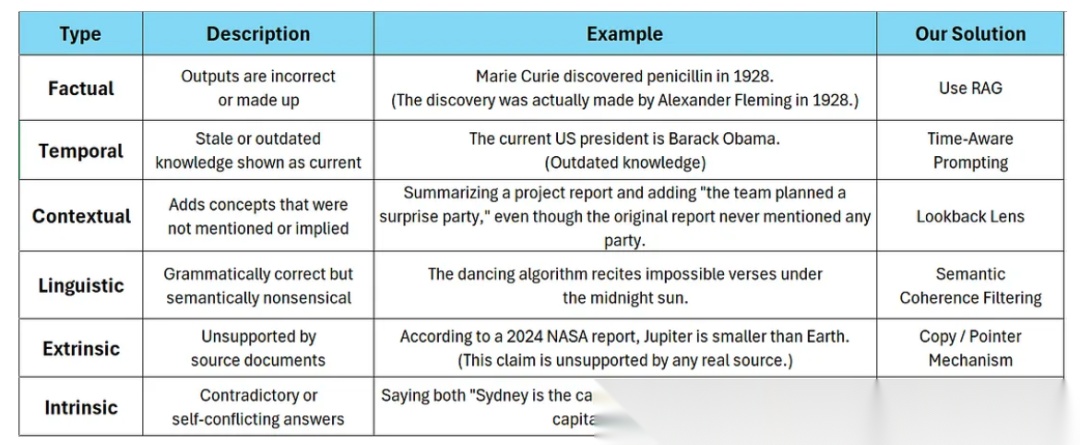
幻觉的类型
事实性幻觉(Factual Hallucinations)
这种幻觉表现为模型输出错误或虚构的信息。例如,模型声称“居里夫人在1928年发现了青霉素”,而实际上这一发现是由亚历山大·弗莱明完成的。这种错误不仅会误导用户,还可能在学术、新闻等领域引发严重的后果。
时间性幻觉(Temporal Hallucinations)
这种幻觉表现为模型提供了过时的知识,却将其呈现为当前的信息。例如,模型声称“现任美国总统是奥巴马”,这显然是基于过时的数据。这种幻觉在需要实时更新信息的场景中尤为危险,如金融、政策分析等领域。
上下文幻觉(Contextual Hallucinations)
这种幻觉表现为模型在生成内容时,添加了原文中未提及或未暗示的概念。例如,在总结一份项目报告时,模型突然插入了“团队计划了一个惊喜派对”,尽管原始报告中从未提到任何派对。这种幻觉可能会使生成的内容偏离主题,甚至引发误解。
语言幻觉(Linguistic Hallucinations)
这种幻觉表现为模型生成的内容在语法上正确,但在语义上毫无意义。例如,“跳舞的算法在午夜阳光下背诵不可能的诗句”。这种幻觉可能会让用户感到困惑,甚至对模型的可信度产生怀疑。
外部幻觉(Extrinsic Hallucinations)
这种幻觉表现为模型生成的内容与源文档不一致,甚至完全无中生有。例如,声称“根据2024年NASA的报告,木星比地球小”,而这一说法没有任何真实来源支持。这种幻觉可能会误导用户,甚至在学术研究中引发错误的结论。
内部幻觉(Intrinsic Hallucinations)
这种幻觉表现为模型生成的内容自相矛盾或自我冲突。例如,模型同时声称“悉尼是澳大利亚的首都”和“堪培拉是澳大利亚的首都”。这种幻觉会让用户感到困惑,甚至对模型的逻辑性产生质疑。
用RAG解决事实性幻觉
小型语言模型的训练数据量有限,可能无法覆盖所有事实性知识。即使训练数据中包含正确答案,模型也可能因为上下文理解不足或生成逻辑错误而给出错误的回答。此外,模型在生成答案时往往不会主动验证信息的真实性,这进一步增加了错误回答的风险。
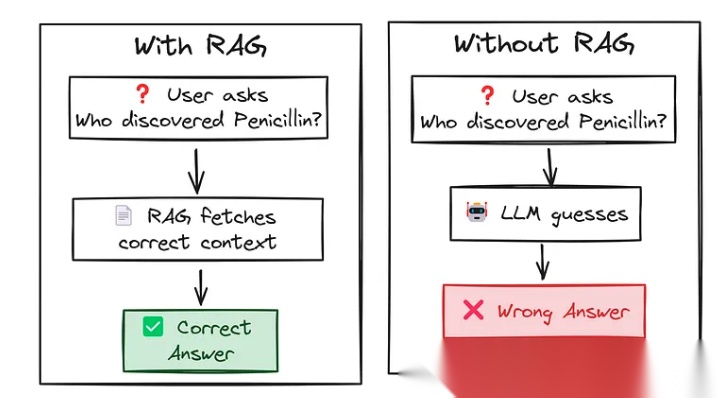
为了克服这一问题,检索增强生成(Retrieval-Augmented Generation,简称RAG) 是一种被广泛采用的技术。RAG的核心思想是结合外部知识库中的信息,为模型提供更准确的上下文支持,从而生成更可靠的答案。
RAG通过以下步骤实现事实性纠正:
- 检索(Retrieval):根据用户的问题,从知识库中检索与问题最相关的文档片段。
- 生成(Generation):将检索到的文档片段作为上下文,输入到语言模型中,生成更准确的答案。
为了找到与用户问题最相关的文档,我们需要将问题和文档转换为嵌入向量(embeddings),并通过计算向量相似度来检索最相关的文档。
将检索到的文档内容作为上下文,输入到语言模型中,生成更准确的答案:
# 明确告诉模型使用提供的上下文回答问题rag_system_prompt = f"""You are an AI Chatbot!Use the following context to answer the user's question accurately.If the context does not contain enough information to answer the question, respond that you don't have sufficient information from the provided context.Context:{retrieved_context}"""# 用户问题保持不变user_prompt = "Who discovered Penicillin in 1928?"# 使用RAG系统提示和原始用户提示生成回答rag_response = generate_response(rag_system_prompt, user_prompt)# 输出RAG增强后的回答print(rag_response)
时间提示:解决时间幻觉
时间幻觉不仅会误导用户,还可能在需要实时信息的场景中引发严重后果。例如,当用户询问“今天法国的总统是谁”时,模型可能会给出过时的答案,如“法国总统是埃马纽埃尔·马克龙”,而实际上,马克龙的任期可能已经结束。这种错误的回答会降低模型的可信度,并影响用户体验。
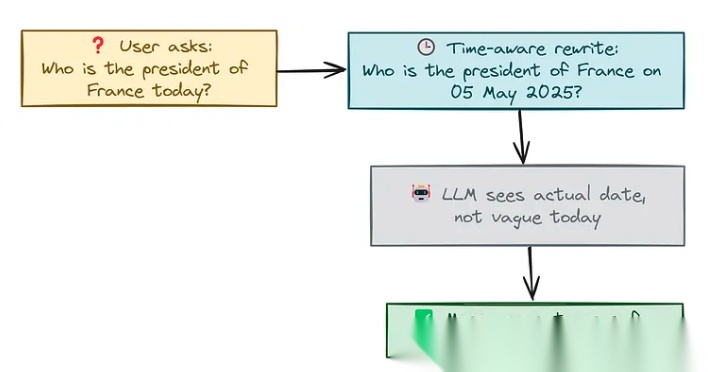
为了克服时间幻觉,我们可以采用时间感知提示(Time-Aware Prompting) 技术。这种方法的核心思想是通过在用户问题中明确指定时间范围,引导模型生成更准确的回答。例如,将“今天”替换为具体的日期(如“2025年5月5日”),从而消除模型对时间的模糊理解。
时间感知提示通过以下步骤实现:
- 识别时间关键词:在用户问题中识别出与时间相关的关键词(如“今天”“今年”“本月”等)。
- 替换为具体时间:将这些关键词替换为当前的具体日期或时间范围。
- 生成时间感知的提示:将替换后的问题作为输入,传递给语言模型。
from datetime import datetimedef make_query_time_aware(user_prompt: str) -> str: """ 重写用户问题,将时间关键词替换为当前日期,以提供时间上下文。 这是一个简化的示例,仅针对特定关键词。 参数: - user_prompt (str): 原始用户问题。 返回: - str: 重写后的时间感知问题。 """ current_date_str = datetime.now().strftime("%d %B %Y") # 例如:"05 May 2025" # 简单替换逻辑,可根据需要扩展更多时间关键词 rewritten_prompt = user_prompt.replace("today", current_date_str) rewritten_prompt = rewritten_prompt.replace("this year", datetime.now().strftime("%Y")) rewritten_prompt = rewritten_prompt.replace("this month", datetime.now().strftime("%B %Y")) # 可以添加更复杂的逻辑或正则表达式来处理不同的时间短语 return rewritten_prompt
用回溯透镜解决上下文幻觉
上下文幻觉的出现往往是因为模型在生成回答时未能充分理解或利用上下文中的关键信息。例如,当要求模型总结一段财务报告时,它可能会忽略或误解上下文中的重要细节,从而生成错误的总结。
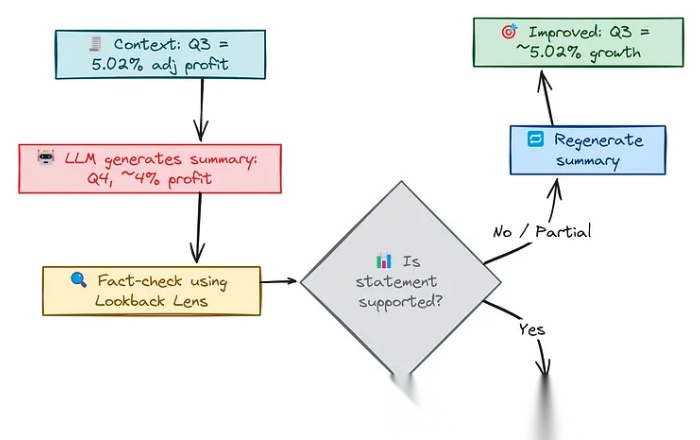
为了解决上下文幻觉问题,我们可以采用Lookback Lens方法。这种方法的核心思想是让模型在生成回答后,重新审视原始上下文,验证其生成的内容是否准确。具体来说,我们可以从生成的总结中提取关键信息,并将其作为验证问题重新提交给模型,让模型在原始上下文中查找支持或反驳这些信息的证据。
从生成的总结中提取关键信息(如“净利约为4”),并将其作为验证问题重新提交给模型。例如:
# 验证系统提示verification_system_prompt = f"""You are a fact-checking assistant. Your task is to determine if the following STATEMENT is fully and directly supported by the provided CONTEXT.Answer (only one option to select):1. Yes2. No3. Partially SupportedCONTEXT:{source_context}"""# 提取关键信息作为验证问题hallucinated_summary = response
语义过滤:解决语言幻觉
语言幻觉的核心问题是模型生成的内容虽然在语法上正确,但在语义上却与实际问题无关或存在错误。这种问题不仅会影响用户体验,还可能导致错误信息的传播。例如,当用户询问“解释植物的光合作用过程”时,模型可能会生成以下回答:
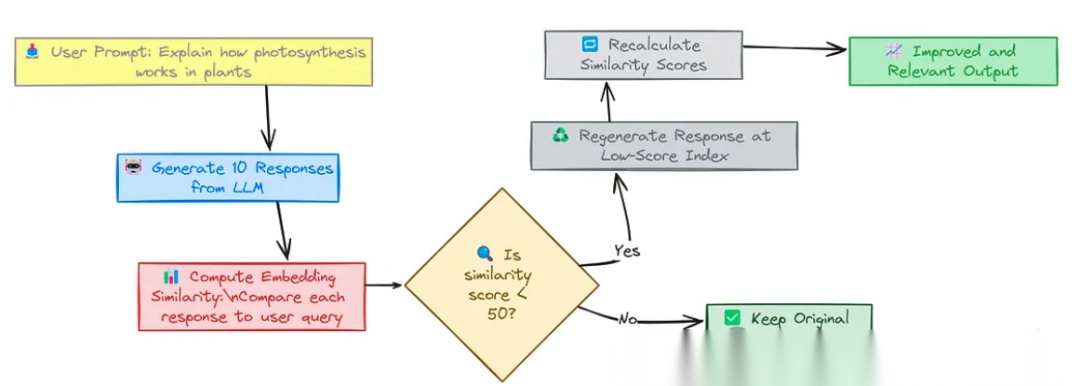
为了解决语言幻觉问题,我们可以采用语义一致性过滤(Semantic Coherence Filtering) 技术。这种方法的核心思想是通过计算用户问题与生成回答之间的语义相似度,筛选出与问题语义不一致的回答,并重新生成更准确的内容。
首先,我们生成多个回答,并计算每个回答与用户问题之间的语义相似度。
为了确保生成的回答与用户问题语义一致,我们可以设置一个相似度阈值(例如50),低于该阈值的回答将被标记为需要重新生成。
矛盾检测提升语言准确性
内在幻觉的核心问题是模型生成的内容与输入源存在直接矛盾。例如,输入为“狗在公园里跑”,而模型生成的输出可能是“狗在公园里飞”。这种输出不仅与事实不符,还违背了常识,导致生成的内容完全不可信。
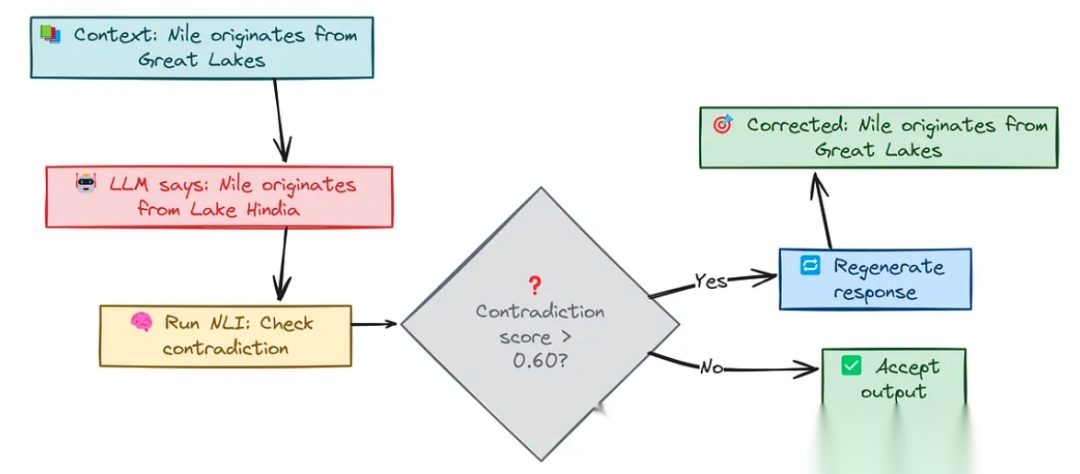
为了解决内在幻觉问题,我们可以采用矛盾检测(Contradiction Checking) 技术。这种方法的核心思想是通过自然语言推理(Natural Language Inference, NLI)模型,检测模型输出与输入源之间的矛盾关系。具体来说,我们可以使用预训练的BERT或其他NLI模型,对输入源和模型输出进行推理,判断它们之间的关系是否为矛盾。
我们可以使用facebook/bart-large-mnli,这是一个在多体裁自然语言推理(MNLI)数据集上微调的模型,能够有效检测输入源和模型输出之间的矛盾关系。以下是实现代码:
from transformers import pipeline# 输入源(前提)和模型输出(假设)premise = source_contexthypothesis = response# 加载NLI模型nli_pipeline = pipeline("text-classification", model="facebook/bart-large-mnli")# 使用NLI模型检测矛盾result = nli_pipeline(f"Premise: {premise} Hypothesis: {hypothesis}")print(result)
指针/拷贝让生成更可靠
外在幻觉的核心问题是模型生成的内容超出了输入源的范围。这种问题在模型被设置为生成较长文本时尤为明显,因为它可能会为了填补字数而编造信息。例如,当用户要求总结一份会议记录时,模型可能会生成一些原始文档中不存在的内容。
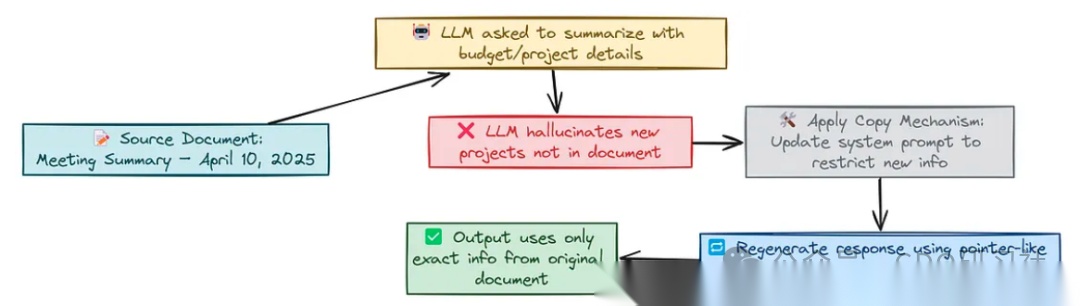
为了解决外在幻觉问题,我们可以采用指针/拷贝机制(Copy/Pointer Mechanism)。这种方法的核心思想是让模型直接从输入源中提取内容,而不是生成新的信息。例如,指针生成网络(Pointer-Generator Network)允许模型在生成新词或从输入中拷贝词汇之间进行选择。
我们可以通过设计一个系统提示,明确告诉模型只使用输入源中的信息,不要添加任何新的事实或细节。以下是一个示例:
# 系统提示system_prompt = """Please summarize the following document, but make sure to only use information that is present in the text.Do not add any new facts or details that are not in the original document."""
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献162条内容
已为社区贡献162条内容

所有评论(0)