大模型在线辅导小模型,正确率提50%、推理效率涨90%
想一下,一个刚学数学的小学生(小模型SLM),虽然做题快,但遇到复杂问题就容易卡壳。在于:让小学生自己尝试解题,只在关键步骤(比如解方程或逻辑推理)时,导师才出手指导。:比如最高难度题(Lv5),小模型正确率从20%飙升至50%+。成本优势:相比全程用大模型,SMART的LLM调用量减少90%。:小模型自己写解题步骤(比如:“先算加法,再算乘法”)。手机本地运行小模型,遇到复杂问题时联网求助大模型
想一下,一个刚学数学的小学生(小模型SLM),虽然做题快,但遇到复杂问题就容易卡壳。而博士生导师(大模型LLM)知识渊博,但计算成本高。
论文:Guiding Reasoning in Small Language Models with LLM Assistance
链接:https://arxiv.org/pdf/2504.09923v1
论文的突破点在于:让小学生自己尝试解题,只在关键步骤(比如解方程或逻辑推理)时,导师才出手指导。这种“外挂大脑”模式,就是SMART框架的核心。
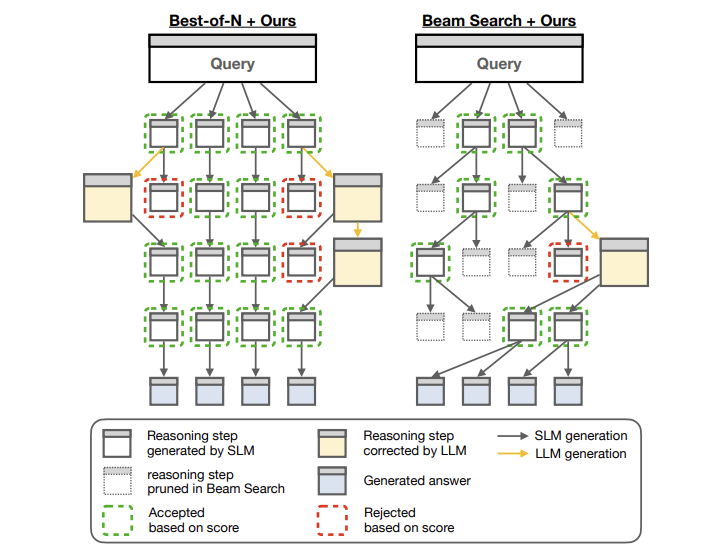
SMART框架:像老师辅导学生一样工作
三步流程
-
第一步:小模型自己写解题步骤(比如:“先算加法,再算乘法”)。
-
第二步:给每一步“打分”——用两种方法:
-
-
PRM分数:像老师批改作业,直接判断对错;
-
TLC分数:看小模型自己有多自信(比如概率高低)。
-
-
第三步:分数低于阈值时,召唤大模型修正这一步。
生成推理路径的概率公式:
简单说,就是每一步都依赖前面的步骤,像搭积木一样。
得分阈值τ:决定是否需要大模型介入的“分数线”。
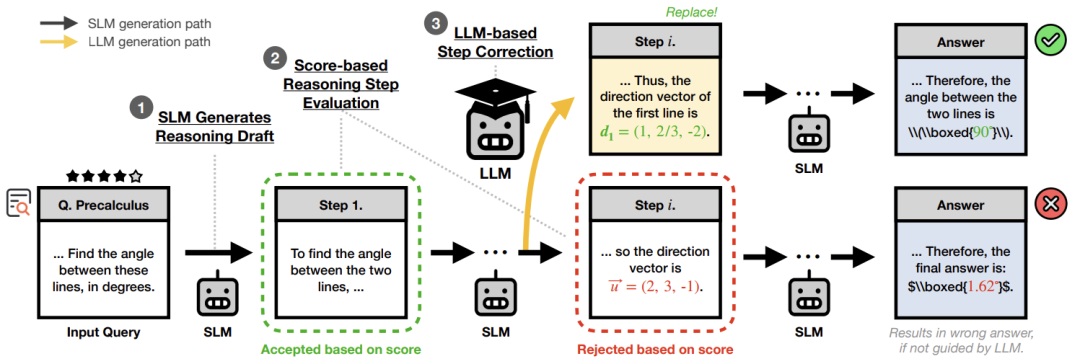
实验:小模型逆袭,接近大模型水平
论文用500道数学题测试,发现:
-
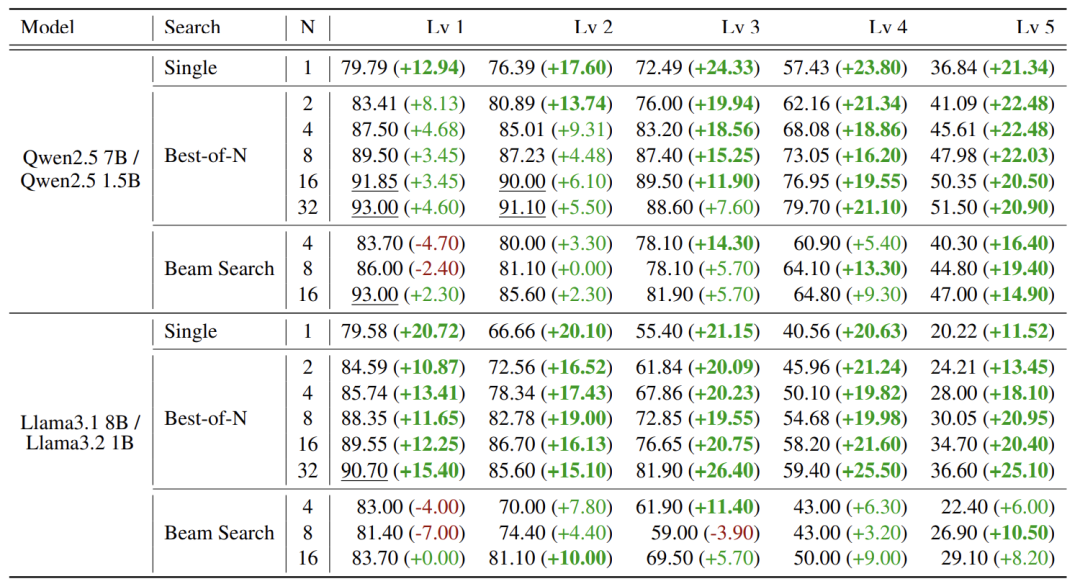
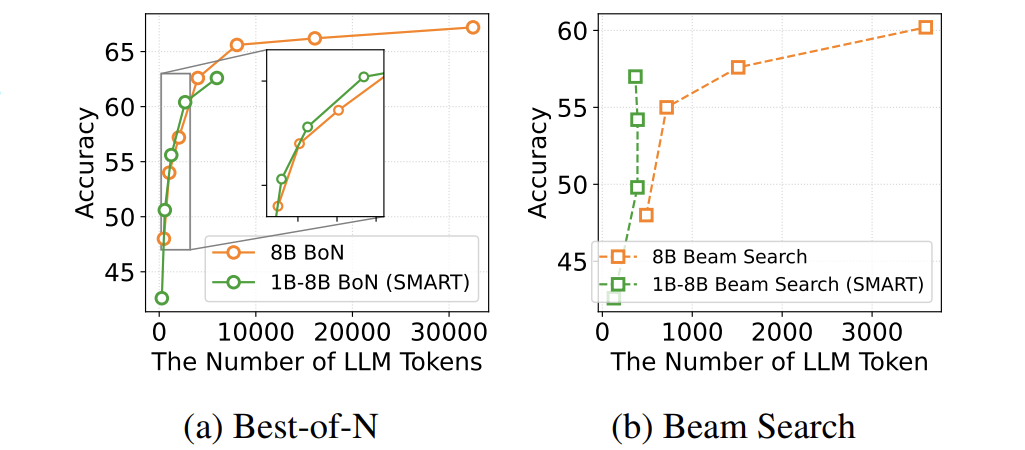
单次生成(N=1):SMART让小模型正确率提升10-20%。
-
多次生成(N=32):小模型能达到大模型90%以上的水平!
-
越难的题越明显:比如最高难度题(Lv5),小模型正确率从20%飙升至50%+。
关键发现
-
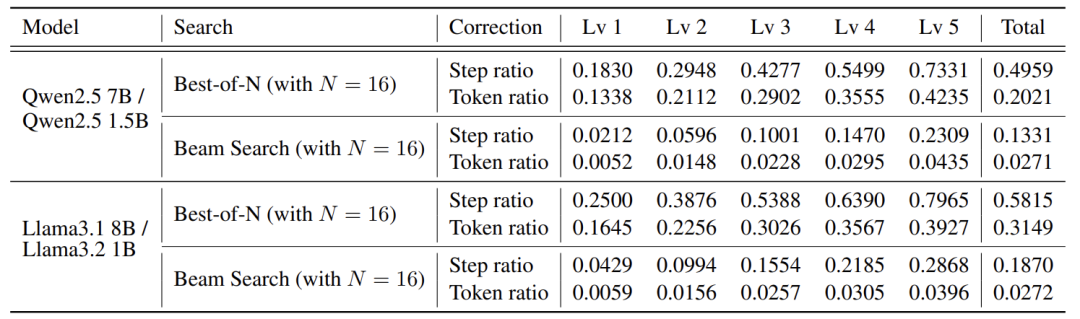
大模型只需修改约20%的步骤,就能大幅提升效果。
-
成本优势:相比全程用大模型,SMART的LLM调用量减少90%。
未来手机也能跑高级AI?
-
手机本地运行小模型,遇到复杂问题时联网求助大模型。
-
既保证响应速度,又降低流量费用。
展望
-
未来可能结合强化学习,动态调整“辅导频率”。
-
隐私保护:敏感数据留在本地,只上传必要问题。
启示:“团队协作”新思路
SMART框架揭示了一个趋势:大小模型协同,而非取代。
-
小模型的优势:速度快、成本低;
-
大模型的价值:关键时刻提供深度推理。
这种“师徒制”或许会成为AI落地的新范式。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献257条内容
已为社区贡献257条内容

所有评论(0)