Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks 解读与个人思考
本文提出了一种创新的多模态学习方法AMSS(Adaptively Mask Subnetworks Considering Modal Significance),旨在解决多模态学习中普遍存在的模态不平衡问题。该方法通过细粒度的子网络更新机制,动态调整不同模态的参数更新策略,从而实现更均衡的多模态优化。
Metadata
- 标题:: “Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks”
- 作者::Yang Yang, Hongpeng Pan, Qing-Yuan Jiang, Yi Xu, Jinhui Tang
- 引用键:: yangLearningRebalanceMultiModal2025
- 日期::2025-06-01
- 出处::“IEEE Transactions on Pattern Analysis and Machine Intelligence”
- 标签:: #多模态学习 #颗粒度子网络 #模态平衡
- 简介::创造了一种细颗粒度来更新子网络的方法,以此来缓解不同模态更新不平衡的问题
- pdf::PDF
- 文献来源: https://ieeexplore.ieee.org/document/10915567/
- status:: “待复习”
- 引文目录: 1.Yang Y, Pan H, Jiang Q-Y, et al (2025) Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks. IEEE Trans Pattern Anal Mach Intell 47:4553–4566. https://doi.org/10.1109/TPAMI.2025.3547417
📖 摘要
[!abstract]+
« Multi-modal learning aims to enhance performance by unifying models from various modalities but often faces the “modality imbalance” problem in real data, leading to a bias towards dominant modalities and neglecting others, thereby limiting its overall effectiveness. To address this challenge, the core idea is to balance the optimization of each modality to achieve a joint optimum. Existing approaches often employ a modal-level control mechanism for adjusting the update of each modal parameter. However, such a global-wise updating mechanism ignores the different importance of each parameter. Inspired by subnetwork optimization, we explore a uniform sampling-based optimization strategy and find it more effective than globalwise updating. According to the findings, we further propose a novel importance sampling-based, element-wise joint optimization method, called Adaptively Mask Subnetworks Considering Modal Significance (AMSS). Specifically, we incorporate mutual information rates to determine the modal significance and employ non-uniform adaptive sampling to select foreground subnetworks from each modality for parameter updates, thereby rebalancing multi-modal learning. Additionally, we demonstrate the reliability of the AMSS strategy through convergence analysis. Building upon theoretical insights, we further enhance the multi-modal mask subnetwork strategy using unbiased estimation, referred to as AMSS+. Extensive experiments reveal the superiority of our approach over comparison methods. »
📌 核心摘要 (Summary)
制定了衡量模态信息主导度的互信息率 u ^ ( k ) = I ( X ( k ) ; Y ) H ( X ( k ) ) \hat{u}^{(k)}=\frac{\mathbb{I}(\mathbf{X}^{(k)};\mathbf{Y})}{\mathbb{H}(\mathbf{X}^{(k)})} u^(k)=H(X(k))I(X(k);Y)根据这个来决定不同模态对应模型的更新程度,并且模型更新的参数取决于Fisher information
- 注:1. 其中 I ( X ( k ) ; Y ) \mathbb{I}(\mathbf{X}^{(k)};\mathbf{Y}) I(X(k);Y)表示[[互信息]],测量 X ( k ) X^{(k)} X(k) 和 Y Y Y 之间共享了多少信息,这可以看作是知道 Y Y Y 在多大程度上降低了我们对 X ( k ) X^{(k)} X(k) 的不确定性, H ( X ( k ) ) H(X^{(k)}) H(X(k))表示第 k 个模态的[[信息熵]]。2. [[Fisher information]]精确量化了观测数据中蕴含的关于未知参数的信息量
🎯 研究目标 (Research Objective)
作者的研究目标是什么?试图解决什么关键问题?
- 目标:作者旨在提升多模态学习的整体效能。在现实数据中,多模态学习常常面临"模态不平衡"的挑战。这指的是在训练过程中,由于不同模态的数据特征或学习难度存在差异,模型会表现出对主导模态的偏好,而忽视非主导模态的学习。这种不平衡导致模型无法充分利用所有模态的信息,从而限制了其性能,有时甚至会使多模态模型的性能低于仅使用单一模态的模型。
- 关键问题:
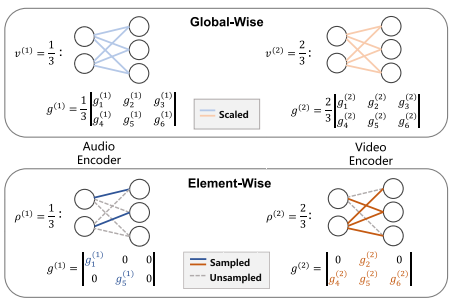
- 现有平衡策略的粗粒度缺陷:以往的方法(如OGM-GE)通常采用模态级的梯度调制。例如,为整个主导模态的参数更新赋予一个较低的全局权重(梯度调制系数)。然而,这种"全局式"更新机制忽略了同一模态内不同参数对目标任务的重要性差异,将所有参数等同对待,这被作者认为是次优的。
- 寻求更精细的优化路径:受子网络优化研究的启发,作者探索了一种元索级的更新机制。初步实验发现,随机掩码一部分参数进行更新的策略,其效果优于全局调制。这证明了精细化参数更新的潜力。因此,关键问题是如何超越简单的随机采样,实现自适应、基于重要性的参数子网络选择,以更智能地重新平衡多模态学习。
⚙️ 方法 (Methodology)
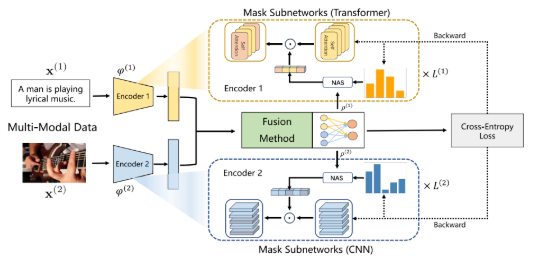
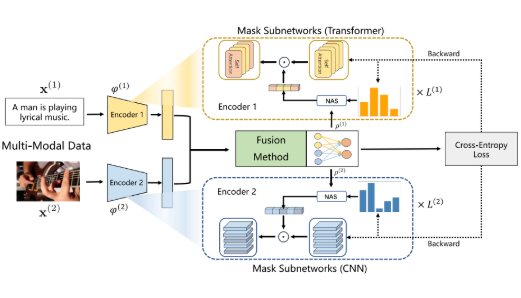
- 核心思想/框架: 根据模态的重要性,为每个模态自适应地选择不同大小的、富含信息的参数子网络进行梯度更新
- 关键技术/算法(步骤):
-
基于模态显著性的子网络规模确定:通过计算每个模态的预测与真实标签之间的互信息率,来动态评估一个模态在当前批次数据中的重要性(模态显著性)。非主导模态(重要性较低)会被分配一个较小的参数更新比例,意味着更少的参数被更新,以刺激其学习;而主导模态(重要性较高)则被分配一个较大的参数更新比例,意味着更多的参数被更新,以抑制其过快的优化速度。
-
基于任务指导的参数选择标准:在确定了每个模态需要更新的参数数量后,并非随机选择,而是根据费舍尔信息来衡量每个参数对目标任务的重要性。然后,采用非均匀自适应采样方法,优先选择重要性更高的参数构成子网络,确保每次更新都集中在信息量最大的参数上。
此外,作者还从理论层面分析了AMSS的收敛性,并在此基础上提出了其改进版本**AMSS+**。AMSS+引入了无偏估计技术来修正原始AMSS中可能存在的梯度估计偏差,从而进一步提升了算法的可靠性和性能。[[AMSS和AMSS+原理]]
-
- 创新点(与前人方法的区别):
-
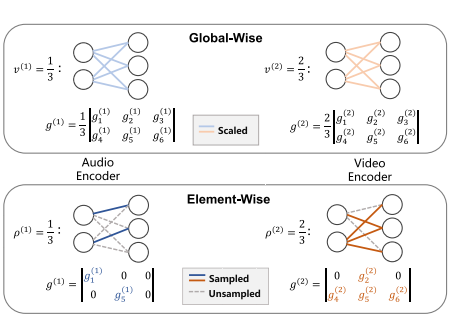
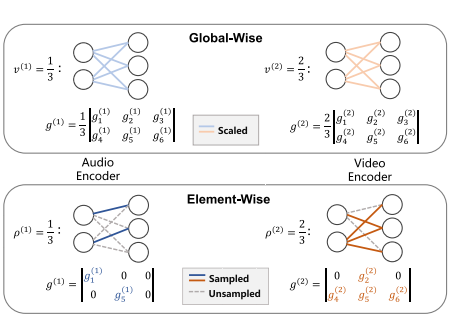
优化机制的革新:从“模态级”到“元素级”
这是最根本的创新。此前解决模态不平衡的方法(如OGM-GE, AGM)主要采用模态级 的梯度调制。-
前人方法(模态级/全局式):为一个模态的所有参数施加一个统一的梯度缩放系数。例如,降低主导模态的整体学习率。
-
本文创新(元素级):作者认为,同一模态内的不同参数其重要性也不同。因此,AMSS方法不再对整个模态进行“一刀切”的调整,而是在参数级别进行精细操作,只更新每个模态中一部分重要的参数(子网络),而掩码其他参数。这种元素级更新机制是首次被引入到多模态学习领域,实现了更精细的优化控制。
-
-
自适应子网络策略:从“固定/随机”到“动态/智能”
即使同样进行子网络操作,AMSS也引入了更智能的自适应策略。
-
与前人子网络方法的区别:已有的子网络优化(如Dropout)多针对单模态模型,且通常采用随机或静态的掩码方式,并未考虑多模态间的平衡问题。本文的初步实验也表明,简单的均匀采样 虽有效果,但非最优。
-
本文创新(自适应):AMSS的核心创新在于其子网络的构建是自适应且基于数据驱动的。
-
子网络大小动态决定:每个模态需要更新的参数比例 ρ(k)不是超参数,而是通过互信息率 动态计算出的模态显著性来决定的。这使得非主导模态(重要性低)更新更少的参数以受保护,主导模态(重要性高)更新更多的参数以受抑制。
-
参数选择基于重要性:选择哪些参数进行更新并非随机,而是基于费舍尔信息 进行非均匀自适应采样,优先选择对目标任务更重要的参数,从而提高了每次参数更新的效率。
-
-
理论深化与算法增强:从“经验性”到“理论支撑与无偏改进”
本文不仅提出了新方法,还为其提供了坚实的理论分析并进行了改进。
-
理论收敛分析:作者对AMSS策略进行了收敛性分析,从理论上证明了该优化方法的可靠性,这为方法的有效性提供了超越实验结果的数学保障。
-
提出AMSS+(无偏估计):基于理论分析中发现的有偏估计问题,作者进一步提出了AMSS+。该方法通过引入无偏估计技术来修正梯度,克服了原始AMSS在某些假设下的局限性,从而获得了更稳定、更优越的性能。这种从理论发现到算法改进的闭环,是区别于许多纯经验性工作的一个重要创新。
-
-
灵活性与通用性:从“特定架构”到“即插即用”
与一些为特定模型设计、难以复用的复杂模块(如Greedy方法中的层次交互模块)不同,AMSS/AMSS+被设计为一种灵活的优化策略。它可以作为一种“即插即用”的模块,与各种不同的融合方法(早期融合、晚期融合等)和模型架构(CNN、Transformer等)相结合,具有很高的通用性。
-
📊 实验评估 (Evaluation)
- 实验设置(数据集、评价指标、基线模型):
- 数据集:论文在五个多模态数据集上进行了全面评估
- 音频-视频模态:Kinetics-Sound(视频动作识别,31个类别,19k视频片段)和CREMA-D(语音情感识别,6种情感,7.4k样本)
- 文本-图像模态:Sarcasm Detection(讽刺检测,2个类别,24.6k文本-图像对)和Twitter-15(情感识别,3个类别,5.3k样本)
- 多模态扩展:NVGesture(手势识别,25个类别,包含RGB、深度和光流三种模态)
- 数据集:论文在五个多模态数据集上进行了全面评估
- 评价指标:不同类别不同指标
- 音频-视频数据集:准确率(Acc)和平均精度均值(mAP)
- 文本-图像和NVGesture数据集:准确率(Acc)和宏观F1分数(Mac-F1)
- 基线模型:
- 模态重平衡方法:ORG-GB、MSES、OGM-GE、Greedy、DOMFN、MSLR、PMR、AGM
- 传统融合方法:特征拼接(Concat)、仿射变换(Affine)、通道融合(Channel)、多层LSTM融合(ML-LSTM)、预测求和(Sum)、预测加权(Weight)、ETMC
-
主要结果(关键数据或图表结论):
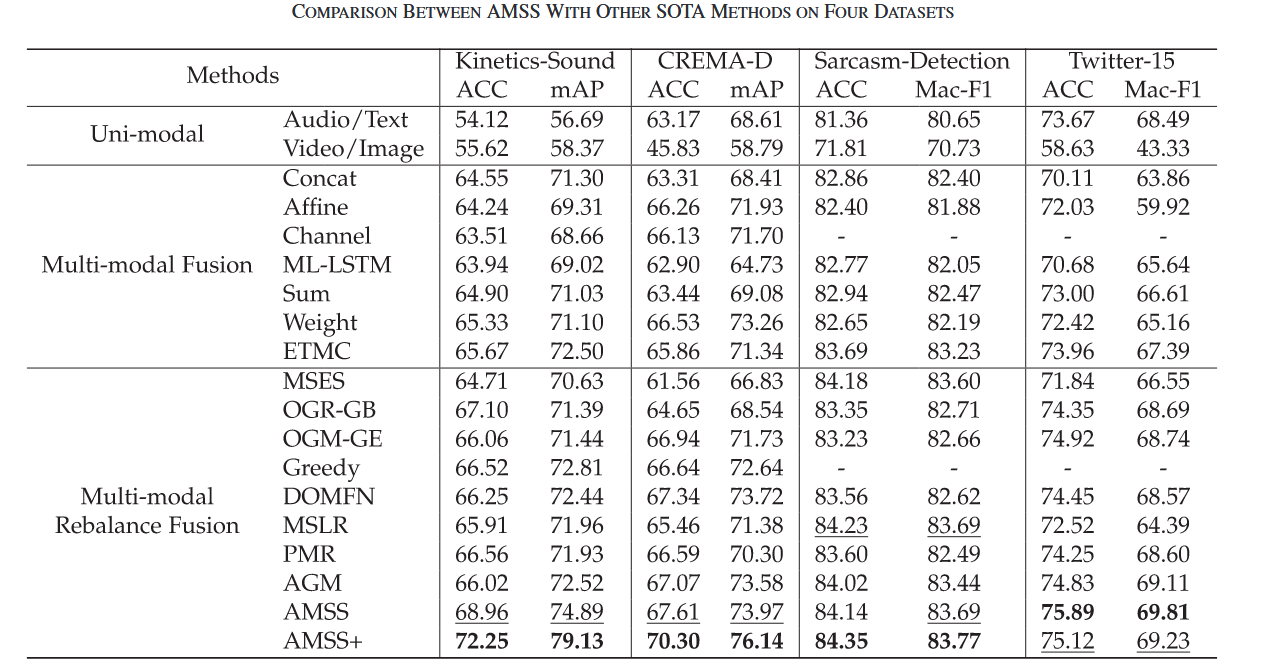
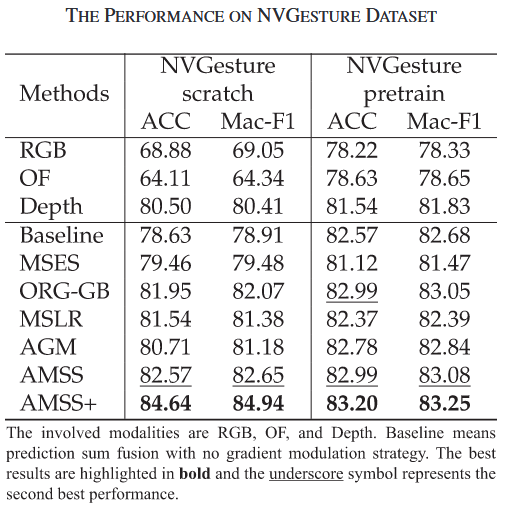
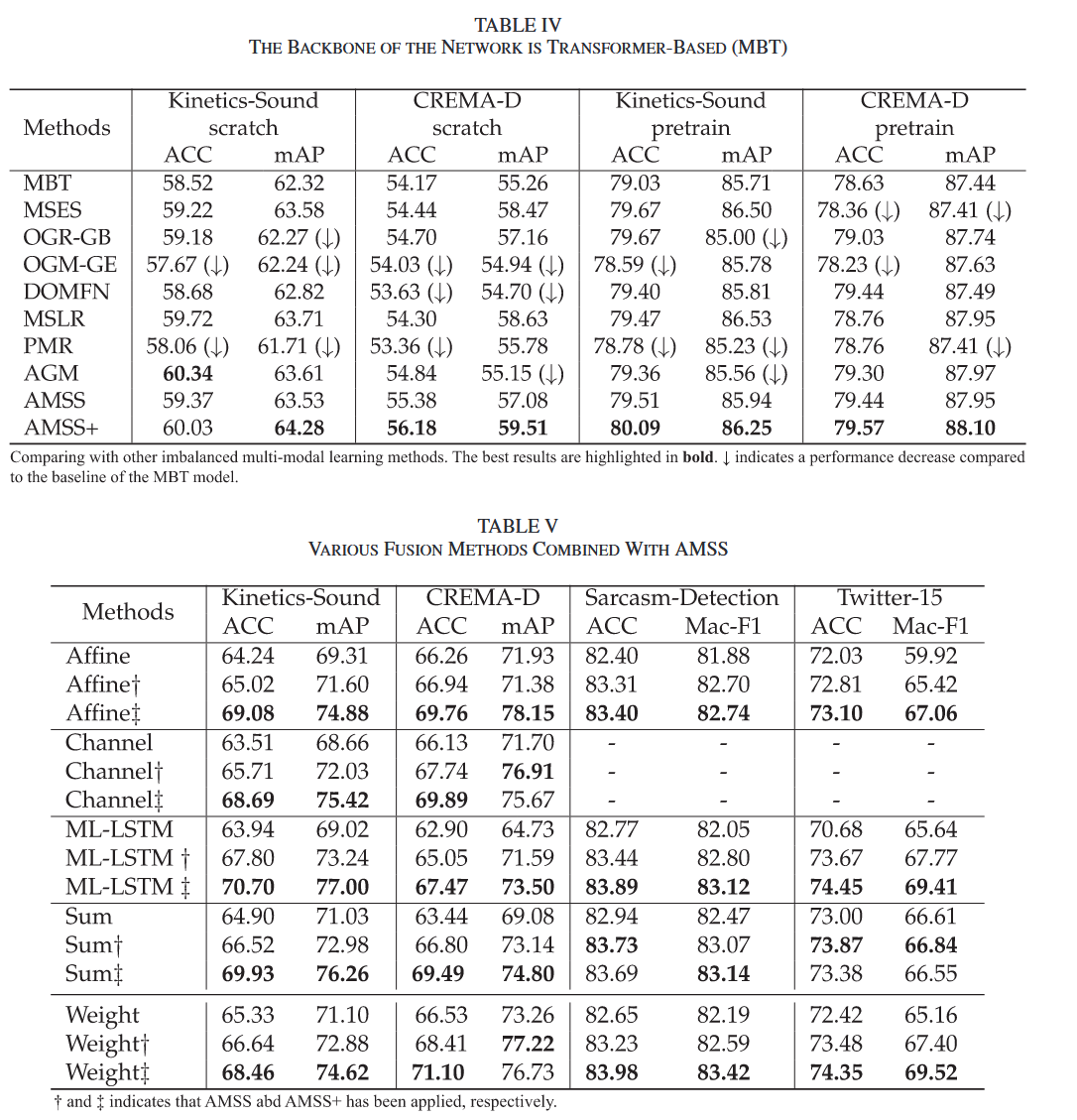 关键数据表现:
关键数据表现:- 在Kinetics-Sound上,AMSS+相比第二优方法提升5.15%(Acc)和7.70%(相比Concat)
- 在CREMA-D上,相应提升为2.96%和6.99%
- 在NVGesture三模态任务中,AMSS+在从头训练设置下达到最佳性能(85.27% Acc)
Transformer架构适配性: - 在复杂的MBT架构上,AMSS+在Kinetics-Sound预训练设置下达到71.43% Acc,显著优于其他方法
- 传统重平衡方法(如OGM-GE、PMR)在复杂交互场景下甚至劣于基线
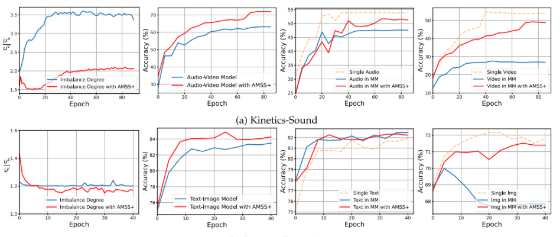
消融实验关键发现
采样机制(表VI):
- 非均匀自适应采样相比随机采样在Kinetics-Sound上提升2.14%(AMSS+)
- 验证了基于Fisher信息的重要性采样有效性
组件分析(表VII): - 骨干网络掩码相比分类器掩码贡献更大(提升约1.5-2.0%)
- 组合使用所有组件达到最优效果
-
结果分析(优势/局限/可借鉴点):
- 有效性突出:在所有数据集和架构上一致优于基线,特别是在模态不平衡严重的场景(如Kinetics-Sound)提升显著
- 架构适应性:在CNN和Transformer架构上均表现优异,证明方法的通用性
- 理论支撑强:AMSS+基于无偏估计的理论改进在实践中得到验证,性能稳定优于AMSS
- 融合策略兼容性:可与不同层次融合方法(特征级、预测级)有效结合
潜在局限 - 计算开销:重要性采样和模态显著性计算增加额外计算成本
- 超参数调优:τ需要仔细调整以适应不同数据集特性
- 理论假设:收敛分析基于特定假设,在实际复杂场景中可能存在偏差
💎 结论 (Conclusion)
- 强结论(有充分实验证据支持):
- 弱结论/讨论(基于结果的分析与展望):
🤔 个人思考 (Personal Notes)
-
创新点与价值: 为何能发表于顶刊?其核心贡献是什么
1. 范式转变:从粗粒度到细粒度优化
-
传统方法局限:现有方法(如OGM-GE、AGM)采用模态级梯度调制,对所有参数同等对待
-
本文突破:提出基于参数重要性的差异化更新策略,实现更精细的优化控制
2. 理论框架创新
-
重要性采样理论应用:将非均匀采样理论引入多模态优化
-
收敛性证明:为子网络优化策略提供严格的理论保证(Theorem 1-2)
-
无偏估计改进:提出AMSS+解决估计偏差问题,体现理论深度
3. 方法设计创新
-
模态显著性度量:基于互信息率的动态评估机制(公式3)
-
Fisher信息引导采样:将参数重要性量化与优化过程结合(公式6)
-
多架构适配:设计通道级(CNN)和头级(Transformer)掩码单元
实验验证的全面性
多维度评估体系
-
数据集覆盖:5个数据集,涵盖音频-视频、文本-图像、三模态场景
-
架构测试:CNN(ResNet)和Transformer(MBT)双架构验证
-
对比基线:与8种模态重平衡方法和7种传统融合方法对比
显著性能提升
表II显示AMSS+在Kinetics-Sound上相比次优方法提升5.15%,这种一致且显著的性能提升为方法有效性提供了强有力证据
-
-
局限与启示: 方法或实验存在哪些不足?对你的研究有何启发?
方法局限性
1. 计算复杂度问题
- 额外计算开销:模态显著性计算和参数重要性评估增加训练成本
- 实时应用挑战:动态掩码策略在资源受限环境中可能受限
2. 理论假设限制
- 理想化假设:收敛分析依赖于相对严格的假设条件
- 实际数据偏差:真实数据分布可能不完全符合理论假设
3. 超参数敏感性
- τ调优需求:需要针对不同数据集调整超参数(表VIII显示τ=0.2最优)
- 自适应机制缺失:缺乏动态调整掩码策略的机制
4. 模态扩展性
- 多模态泛化:在超过3个模态的场景中验证不足
- 跨领域适用性:在专业领域(如医疗、遥感)的适用性待验证
研究启示
理论方向
- 放松理论假设:探索更一般化条件下的收敛性分析
- 动态理论框架:建立自适应掩码比例的理论基础
- 跨模态理论:发展多模态协同优化的统一理论框架
方法改进
- 效率优化:设计轻量级显著性评估方法
- 自适应机制:开发基于训练进度的动态掩码策略
- 预训练适配:针对大规模预训练模型设计专用策略
应用拓展
- 新模态组合:探索传感器数据、生理信号等新模态
- 领域适配:在医疗诊断、自动驾驶等关键领域应用验证
- 边缘计算:开发适合边缘设备的简化版本
-
写作/图表亮点: 可借鉴的句式、图表展示方式等。
- 对比表格设计(表II)
- 分层结构:按数据集分组,清晰展示不同场景性能
- 重点突出:加粗最优结果,下划线次优结果
- 信息完整:包含多个评估指标(Acc/mAP/Mac-F1)
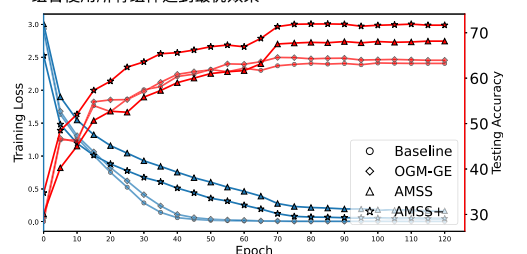
- 可视化优化过程(图4)
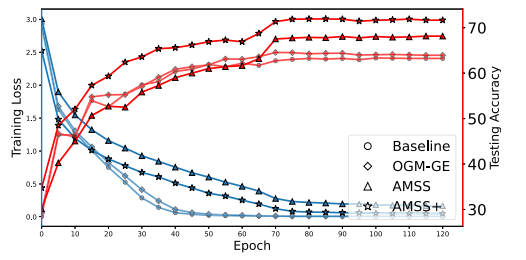
借鉴点:
- 双Y轴设计:同时展示训练损失和测试性能
- 对比清晰:多种方法在同一图中对比
- 分析指导:直观展示收敛性和泛化能力关系
- 机制对比图示(图1)
借鉴点:
- 并行布局:传统方法与新方法直观对比
- 标注详细:关键参数和过程清晰标注
- 概念可视化:抽象机制通过图形具体化
- 消融实验展示(表VI-VIII)
借鉴点:
- 结构化设计:分组件、分超参数系统展示
- 数据充分:提供多角度验证结果
- 分析深入:不仅展示结果,还提供原因分析
🔗 知识连接 (Knowledge Links)
- 相关概念: [[多模态优化]], [[自适应掩码]]
- 相关方法: [[AdamW优化器]], [[子网络训练]],[[SGD优化器]],[[DropConnect]]

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)