【具身智能】-- HPT模型
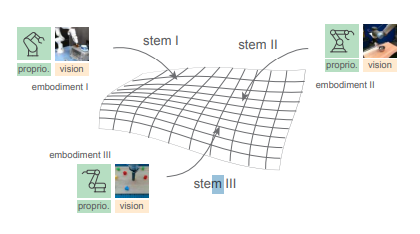
当前我们在训练通用的机器人模型的时候,面临的主要问题在于数据的异构性。现在市面上各家机器人都会针对各自的机器人采集数据进行模型的训练,但是不同的数据采集实施形式和机器人平台的差异性导致数据很难具有通用性。这篇论文主要从通用性出发,研究如何实现将不同的潜在空间对齐,并研究策略学习中的扩展行为。将可扩展的置于策略中间,无需从头开始训练!HPT 模型Stem(输入)、Trunk(骨干)、Head(输出)
论文:https://arxiv.org/pdf/2409.20537
官网:Scaling Proprioceptive-Visual Learning with
一、整体介绍
当前我们在训练通用的机器人模型的时候,面临的主要问题在于数据的异构性。现在市面上各家机器人都会针对各自的机器人采集数据进行模型的训练,但是不同的数据采集实施形式和机器人平台的差异性导致数据很难具有通用性。这篇论文主要从通用性出发,研究如何实现将不同的潜在空间对齐,并研究策略学习中的扩展行为。将可扩展的 Transformer 置于策略中间,无需从头开始训练!
二、技术介绍
2.1 模型架构
HPT 模型结构分为三个部分:Stem(输入)、Trunk(骨干)、Head(输出);其中 Trunk 包含了 96% 的参数,预训练之后就固定了;而 Stem 和 Head 会根据任务和机器人的不同,而重新初始化和微调。这种通用架构将来自不同实施形式的特定本体感觉和视觉输入对齐到一个短的 token 序列,然后处理这些 token,并将其映射到控制机器人以执行不同的任务。利用最近的大规模多实施形式真实世界机器人数据集以及模拟、已部署机器人和人类视频数据集,研究了跨异构环境的预训练策略。
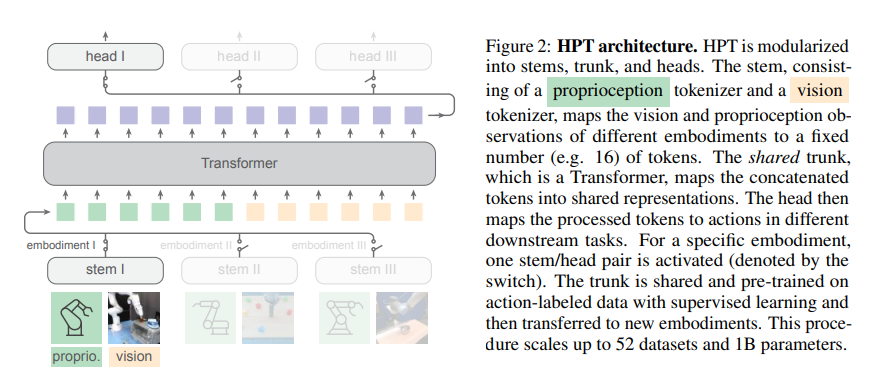
Stem作为输入部分,主要对图像和语言等多种模型信息进行编码到同一向量空间。对于图像输入,可以使用MAE ViT、DinoV2、CLIP ViT等。对于语言直接使用T5,并且预先把 embedding 存下来。对于本体感知数据(proprioception)和动作(action)就直接归一化拉平。这些输入都可以叠加多帧历史,然后通过 cross-attention + MLP 把图像、本体感知、语言分别转化为 16、16、8 tokens。
Trunk 部分就是一个 decoder-only transformer,在维度为d的潜在空间中由θ_trunk参数化。输出令牌序列长度L与输入令牌序列长度保持一致。
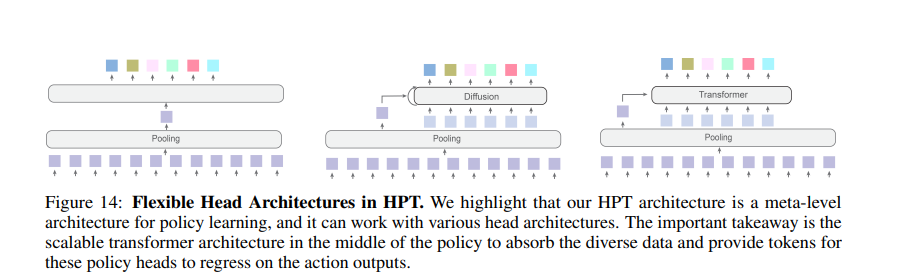
Head部分作为action policy,θhead接收主干Transformer的输出,并将其映射到各数据集对应的动作空间A。针对不同的实体形态(embodiment)和任务,策略头可采用任意架构(例如多层感知机MLP),其输入为主干网络的池化特征,输出为归一化的动作轨迹。在迁移至新实体形态时,策略头需重新初始化。
2.2 数据构建
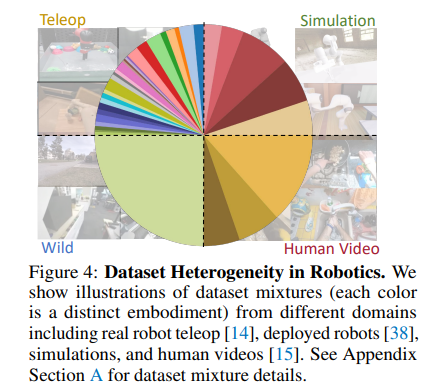
整个模型训练的数据具有多样性,这个多样性主要体现在机器人本体的多样性和数据采集场景以及数据样式的多样性。数据是从不同领域(例如模拟和真实机器人)生成的,跨感官模式(例如RGB图像、语言指令、深度图、3D点云和触觉图像)。同时每个机器人都有自己独特的硬件配置(不同的自由度、末端执行器、传感器配置、控制器和动作空间以及特定于应用的物理设置)。
训练数据包含四大类:
- teleoperation:人操作机器人去采集的数据
- simulation:模拟器中采集的数据
- human video:人佩戴摄像头采集的数据(没有本体感知数据)
- deployed:策略部署到实际机器人上采集的数据
2.3 模型训练
训练目标就是最小化对不同数据源的预测误差。L是行为克隆损失,计算为基于数据集统计和网络动
作预测的标准化动作标签之间的Huber损失。

作者采用27个机器人操作数据集作为模型预训练集对模型进行训练。
三、实验
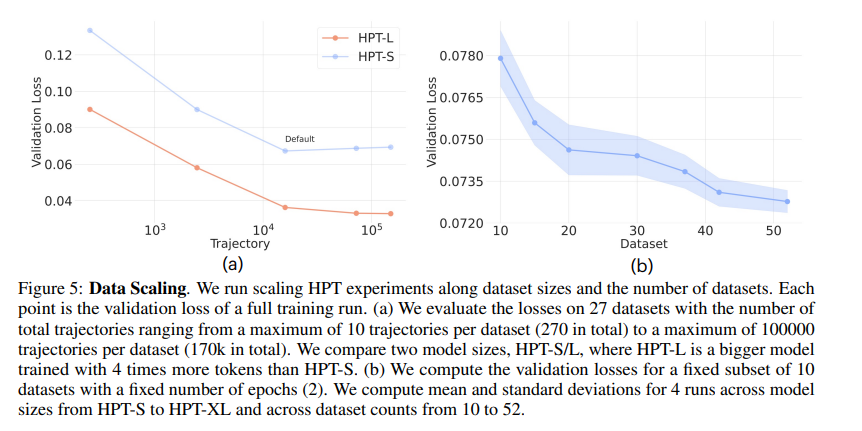
3.1 Data Scaling
采用Data Scaling策略进行观察异构数据对模型训练的效果。随着样本增多、数据集增多、训练轮次增多和模型规模增大,validation loss (对于动作的预测误差)降低。
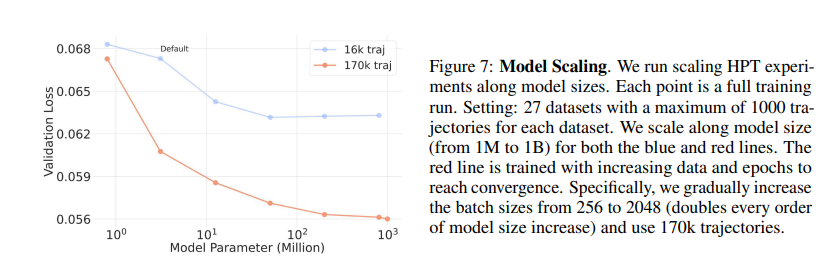
3.2 Model Scaling
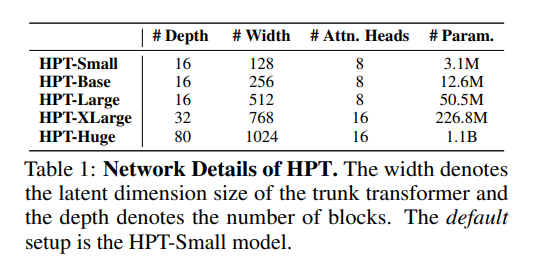
通过以下方式进行模型规模化研究:
(1) 模型参数量从100万到10亿逐步扩大;
(2) 批次大小随模型规模呈指数增长(从256开始,模型规模每提升一个数量级即翻倍,最终达到2048);
(3) 使用包含17万条轨迹的大规模数据集进行训练。
实验结果表明:当采用更大计算量的模型时(图中黄色曲线),预训练验证损失可以降低到更低的水平。模型深度(层数)与宽度(隐层维度)的扩展方式对最终性能未产生显著差异(没有给出实验图)。
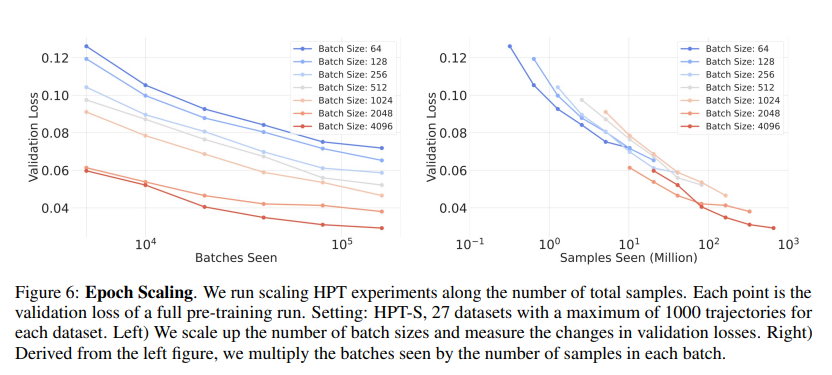
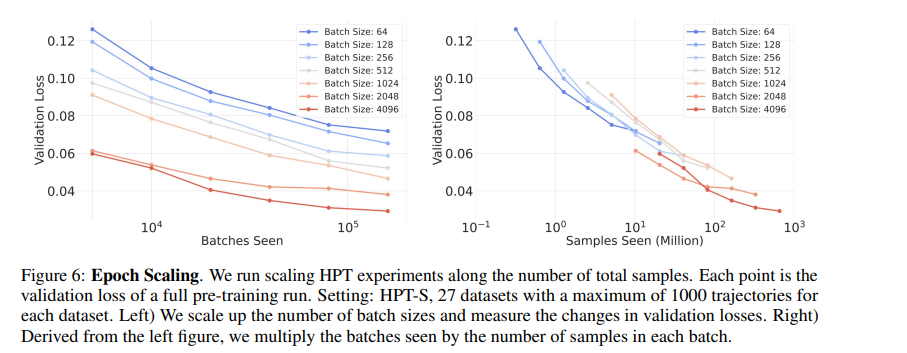
3.3 Epoch Scaling
文章固定使用27个数据集,且每个数据集最多采用1000条轨迹数据。进行以下实验:
(1)增大批次规模能有效增加训练token量,从而持续提升模型性能直至收敛;
(2)采用分布式工作节点从尽可能多的数据集中并行加载数据,以聚合形成每个训练批次。
四、结论
本文主要从机器人当前异构性出发,探索如何解决异构条件下模型多样性数据训练,对于当前机器人训练数据稀缺状况下,是一个不错的方向探索。但是在数据集构建与预训练目标等诸多方面仍有改进空间:
(1)本研究中平衡数据集混合的具身智能体划分方案较为简单,且为确保数据质量而进行的数据精细过滤工作尚未充分探索。
(2)本研究采用监督学习作为预训练目标,其token级数据规模与FLOPs级训练算力仅达到大型语言模型训练的中等规模以确保充分收敛。
(3)虽然模型架构与训练流程采用模块化设计且独立于具身配置,但异构预训练可能存在收敛缓慢的问题。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)