LangVAE 和 LangSpace:构建和探测语言模型 VAE
我们提出了 LangVAE,这是一种基于预训练大型语言模型(LLM)模块化构建变分自编码器(VAE)的新框架。这种语言模型 VAE 可以将其预训练组件的知识编码为更紧凑且语义上解耦的表示形式。通过这种方式获得的表示可以使用 LangVAE 的配套框架 LangSpace 进行分析,LangSpace 实现了一系列探测方法集合,例如向量遍历和插值、解耦度量以及聚类可视化。
丹尼洛·S·卡尔沃 1{ }^{1}1,张英基 2{ }^{2}2,哈丽雅特·昂斯沃思 1{ }^{1}1,安德烈·弗雷塔斯 1,2,3{ }^{1,2,3}1,2,3
英国国家生物标志物中心,CRUK-MI,曼彻斯特大学 1{ }^{1}1
计算机科学系,曼彻斯特大学,英国 2{ }^{2}2 瑞士 Idiap 研究所 3{ }^{3}3
© https://github.com/neuro-symbolic-ai/{LangVAE, LangSpace} | 短视频
摘要
我们提出了 LangVAE,这是一种基于预训练大型语言模型(LLM)模块化构建变分自编码器(VAE)的新框架。这种语言模型 VAE 可以将其预训练组件的知识编码为更紧凑且语义上解耦的表示形式。通过这种方式获得的表示可以使用 LangVAE 的配套框架 LangSpace 进行分析,LangSpace 实现了一系列探测方法集合,例如向量遍历和插值、解耦度量以及聚类可视化。LangVAE 和 LangSpace 提供了一种灵活、高效且可扩展的方式来构建和分析文本表示,同时简单地集成了 HuggingFace Hub 上可用的模型。此外,我们进行了一系列实验,涉及不同的编码器和解码器组合以及带注释的输入,揭示了架构家族和大小在泛化和解耦方面的广泛交互作用。我们的研究结果展示了一个有前景的框架,用于系统化文本表示的实验和理解。
1 动机与目的
变分自编码器(VAE)(Kingma 等人,2013 年)由于其能够整合先验知识、量化不确定性、增强泛化能力并提供可解释性,在机器学习领域具有相当重要的意义。首先,先验分布的整合充当归纳偏差,使模型能够利用现有知识,并提供一种原则性的方法来融入领域专业知识。例如,在计算语言学领域,层次句法信息可以通过双曲先验很好地编码(Davidson 等人,2018;Cho 等人,2023)。其次,它们的概率公式允许明确的不确定性量化,不仅提供点估计,还提供潜在变量和重建的置信区间,这在安全和可信人工智能领域非常重要,例如 LLM 的幻觉问题(Ji 等人,2023)。第三,通过强制执行平滑且连续的潜在空间,VAE 促进了更好的组合和泛化,因为它们捕捉了输入分布的基本生成因素(Bonnet 和 Macfarlane,2024)。第四,潜在空间可以将知识压缩为抽象级概念,这类似于人类理解世界的方式(Barrault 等人,2024)。同时,大型语言模型(LLM)的快速发展显著提高了各种 NLP 任务的表现,展示了卓越的知识表示能力(Kauf 等人,2023;Selby 等人,2025),但在可解释性和细粒度控制方面仍面临关键挑战(Kunz 和 Kuhlmann,2022;Friedman 等人,2024)。
为了利用语言模型(LM)和 VAE 的优势,基于语言模型的 VAE(LM-VAE)(Bowman 等人,2015)被提出并在受控文本生成领域得到了广泛应用,如风格迁移任务:根据情感、正式程度、肯定/否定标记修改句子(Bao 等人,2019;Vasilakes 等人,2022;Gu 等人,2022;Liu 等人,2023;Gu 等人,2023;Liu 等人,2024)以及文本、句法、语义表示学习领域(Mercatali 和 Freitas,2021;Carvalho 等人,2023;Zhang 等人,2024b,c)。然而,尽管 LM-VAE 在提供更可控的潜在表示方面具有战略地位,但支持 LM-VAE 实验的软件基础设施有限,特别是针对大规模语言模型配置(LLM-VAE)的扩展。
在本工作中,我们通过提出一个新框架解决了这些问题,该框架称为 LangVAE,旨在基于不同规模的预训练语言模型模块化构建 LM-VAE,以及其配套框架 LangSpace,专注于潜在空间探测和评估。LangVAE 引入了一种新的方法,用于将潜在向量解池化到自回归语言模型中,显著减少了计算和内存需求,同时兼容现代 LLM 和硬件优化。
最后,我们进行了一系列实验作为案例研究,以展示这些框架的能力,并突出不同编码器和解码器模型组合在泛化和潜在空间解耦方面的效果,证明了跨不同编码器-瓶颈-解码器组合和参数化的系统分析的影响。
这两个框架均可作为 Python 库在 PyPI 包存储库和公共源代码存储库中获取 12{ }^{12}12。演示视频可在以下链接查看:youtu.be/DVcrdIX9CfI。
2 语言模型 VAEs
语言模型 VAE(LM-VAE)是一种变分自编码器,其中编码器和解码器组件均为语言模型(LM)(Bowman 等人,2015;Li 等人,2020;Tu 等人,2022;Zhang 等人,2023)。它可以将预训练组件的知识编码为紧凑的潜在向量,并使用这些向量从抽象层面引导语言生成。此类模型的优势还扩展到可解释性(由于其更好的解耦属性),因为 VAE 架构瓶颈提供了一个单一的切入点,用于探测模型的潜在空间结构及其句法/语义表示(Li 等人,2020;Mercatali 和 Freitas,2021;Carvalho 等人,2023;Zhang 等人,2024b,c)和推断属性(Bonnet 和 Macfarlane,2024)。创建具有更好解耦和分离句法/语义属性的连续潜在表示空间,为支持句子层面(Bao 等人,2019;Felhi 等人,2022;Zhang 等人,2024c)和自然语言推理(Yu 等人,2022)的生成控制提供了关键机制。
在其最基本的构想中,LM-VAE 包括以下内容:(a) 编码器类型 LLM(例如,BERT,T5),为输入文本的每个标记提供基础表示;(b) 池化过程,累积输入标记表示;© 投影层,将基础编码转换为正则化 VAE 潜在空间;(d) 解池化过程,从潜在向量派生标记表示并将其馈送到解码器;(e) 解码器类型 LLM(例如,GPT,Llama),能够从输入表示序列生成标记。此结构如图 2 所示。在此基本配置之上,句法和语义特征可以注入潜在空间,通过条件化机制(如 CVAE 或聚类损失)改善这些特征的定位和控制。此外,还可以集成进一步的架构干预措施以实现额外控制,例如添加 INN 层(Zhang 等人,2024a),以提高语义特征的分离性。
2.1 Optimus
开创性的 LLVAE 是 Optimus(Li 等人,2020),它结合了 BERT 编码器和 GPT-2 解码器进行句子编码,使用均值池化过程、线性投影层(MLP)和两种并发方案的潜在记忆注入解码器:
Memory:将潜在向量的投影附加到解码器的每一隐藏层作为隐藏记忆向量,供解码器关注。
Embedding:在每一步解码时,将潜在向量的投影添加到解码器嵌入层。
Optimus 是端到端训练的,这意味着编码器投影层和记忆及嵌入注入层与基础编码器和解码器模型联合训练。这样,预训练模型经过微调以“焊接”到投影和注入层,促进收敛。
尽管 Optimus 展示了其能力和潜力,但它存在一些局限性,特别是在模型耦合和可扩展性方面。接下来我们将讨论我们提出的构建 LMVAEs 的方法及其对当前最先进方法的改进。
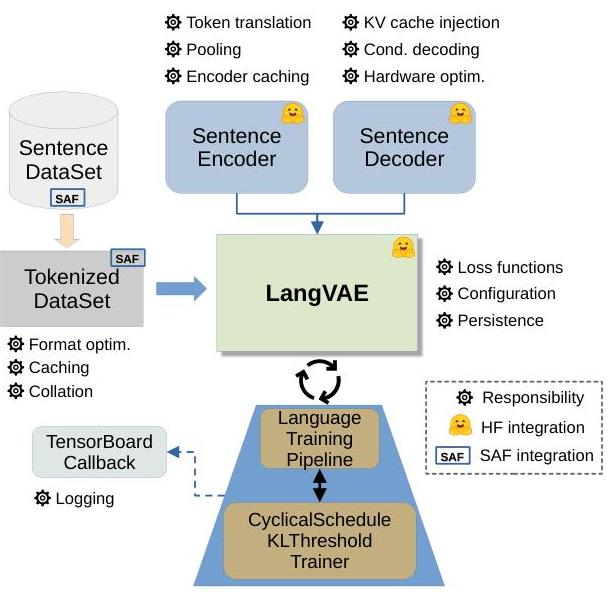
图 3:LangVAE 框架概览。
3 LangVAE:构建模块化 LM-VAE
为了应对当前 LM-VAE 的局限性并促进下一代 LLM 的专业化模型开发和实验,我们开发了 LangVAE。这是一个专门针对 LM-VAE 研究的新框架,重点在于模块化开发前一节讨论的架构组件(尤其是投影和解池化过程),并与 python transformers 库 3{ }^{3}3 强烈集成。LangVAE 作为一个 Python 库 1{ }^{1}1 开发和分发,采用 GPLv3 许可证。它基于 pythae 库构建(Chadebec 等人,2022)。图 3 提供了 LangVAE 模块和职责的概述。
3.1 架构
LangVAE 以以下方式实现了基本的 LM-VAE 架构(图 2):
预训练 LLM 编码器:作为加载器,适用于通过 automodel 类(AutoModel,AutoModelForTextEncoding)与 transformers 库兼容的编码器类型 LLM。
池化过程:基础编码器的均值池化、最后一层隐藏状态或 CLS 标记隐藏状态,具体取决于预训练编码器模型配置自动选择。
潜在投影层:一个线性 MLP,用于调整训练时间的输入编码大小。
3{ }^{3}3 https://github.com/huggingface/transformers
解池化过程:一种 Optimus 内存注入方案的变化版本,称为 KV 缓存注入,无需定制预训练解码器代码。相反,它使用 transformers 库的 KV 缓存机制来引导解码器(详见下一节)。
预训练 LLM 解码器:与编码器相同,但依赖于 transformers AutoModelForCausalLM 类来进行关于标记器配置和硬件优化(例如,flash attention 和多 GPU 分布)的模型参数化。
此外,LangVAE 提供以下功能:
数据转换:TokenizedDataSet 类,方便高效地对文本数据集进行标记化处理,包括注释处理。
训练管道:支持循环计划 KL 衰减,以避免 KL 消失问题,带有 beta 和 KL 阈值。
训练监控:支持 tensorboard 日志记录。
3.2 KV 缓存注入
LangVAE 背后的核心贡献之一是键值(KV)缓存注入方案,作为 Optimus 内存注入的替代方案。这个新方案使用 Causal LM 模型类中的 KV 缓存机制在 transformers 库内注入潜在向量的位置投影。潜在向量 hcache =Wmzh_{\text {cache }}=W_{m} zhcache =Wmz 的线性投影扮演额外上下文的角色,以隐藏 KV 缓存条目 XthX_{t}^{h}Xth 的形式指导生成,这些条目与解码器产生的条目交错,其中 Wm∈RLH×SW_{m} \in \mathbb{R}^{L H \times S}Wm∈RLH×S 被分为 S×LS \times LS×L(序列长度 ∗*∗ #层数)个隐藏大小为 H=K×VH=K \times VH=K×V 的向量。图 4 描述了该方案。
这种方法有两个主要优势。首先,它消除了改变隐藏层布局以适应注入内存向量的需求。因此,它与任何支持 KV 缓存机制的模型兼容。最后,它使得在冻结基础预训练模型权重的情况下训练 LM-VAE 模型成为可能,极大地减少了计算和内存需求。此外,这种方案允许分布式训练注入层,因为投影矩阵可以在训练时间内与各自的隐藏层共置,而且上下文大小(隐藏缓存条目数)可以调整。
3.3 主要优势和局限性
LangVAE 的主要优势可以总结如下:
-
模块化架构允许灵活开发不同的 LM-VAE 配置。灵活组合基础模型和瓶颈参数化、损失函数等。
-
- 与大多数最先进的自回归模型兼容。
-
- 与当前最先进的 LM-VAE(Optimus)相比,训练的计算需求大幅减少,使用参数范围在 3B 到 7B 的解码器模型时,平均参数减少超过 95%95 \%95%(第 5.1 节)。
-
- 支持多 GPU 训练和推理。
其主要局限性与缓存注入机制有关:
- 支持多 GPU 训练和推理。
-
收敛速度较慢,因为可调整的参数较少。
-
- 为了补偿整体参数减少,潜在向量大小往往比 Optimus 更大。
3.4 安装和 API 示例
LangVAE 可直接从 PyPI 包存储库安装:pip install langvae
我们在补充材料(附录 A.1 节)中简要说明了 LangVAE API 的关键组件及其实例化过程。完整的模型训练示例可以在代码存储库的 README 文件 1{ }^{1}1 和支持的 Python 笔记本 4{ }^{4}4 中找到。
4 LangSpace:简化 LM-VAE 探测
LangSpace 2{ }^{2}2 是 LangVAE 的配套框架,专注于 LM-VAE 的评估和潜在空间探测。它提供了一个易于使用的 API 来对预训练的 LM-VAE 模型进行各种分析,主要包括:
- 探测:向量算术和插值、潜在空间遍历、解耦和聚类可视化。
-
- 度量:解耦(z-diff, z-min-var, MIG, 解耦, 信息性, 完整性)、插值(质量, 平滑度)。
4.1 安装和 API 示例
像 LangVAE 一样,LangSpace 也可以从 PyPI 存储库安装:pip install langspace。
我们下面简要说明 LangSpace 探测之一的使用:潜在遍历。所有可用探测的完整示例可以在本公开笔记本 5{ }^{5}5 中找到。
种子句子以进行遍历
sentences = [
“动物需要食物才能生存”,
“水蒸气是看不见的”
]
# 数据集导入器
ds = ListImporter()(
[sent.split() for sent in sentences]
).sentences
# 创建数据集标记器
seeds = TokenizedDataSet(
ds, model.decoder.tokenizer,
model.decoder.max_len
)
# 创建探测器并生成报告:一个包含原始句子、遍历维度、遍历距离和生成结果的列的数据框。
trav_report = TraversalProbe(
model, trav_dataset,
sample_size=10,
dims=list(range(128))
).report()
5 案例研究和模型可用性
为了展示 LangVAE 和 LangSpace 的能力,并突出不同编码器和解码器模型组合在潜在空间泛化和解耦方面的效果,我们进行了一系列实验作为案例研究。实验包括一个简单的解释句子建模任务(Zad 等人,2021;Dalvi 等人,2021),随后对诱导的潜在空间进行评估。本研究中呈现的所有模型组合的预训练检查点均可在我们的公共 HF Hub 存储库中获取 6{ }^{6}6。
5.1 实验设置
对于预训练的 LLM,我们选择了三个不同规模的编码器模型,按参数大小顺序排列:BERT (base-cased)(Devlin 等人,2019),FlanT5 (base)(Chung 等人,2024)和 Stella (en1.5B_v5)(Zhang 等人,2025),以及四个解码器模型:GPT-2 (base)(Radford 等人),Qwen (2.53B)(Team,2024),Llama (3.2-3B)(Grattafiori 等人,2024)和 Mistral (7B-v0.3)(Jiang 等人,2023)。选择考虑了包括不同模型家族和规模。对于每种组合,使用不带和带语义角色标注(SRL)注释的输入(作为语义特征),其中 SRL 注释作为额外变量(独热编码)传递给编码器,经过单独的池化过程(始终为均值池化)。潜在大小(128)和最大句子长度在所有测试中保持不变。所有模型均训练 50 个周期,LR=0.001L R=0.001LR=0.001,目标_kl =2.0=2.0=2.0,max_beta =1.0=1.0=1.0,40 个 beta 衰减周期,批量大小为 50。解耦测量使用 LangSpace 的解耦探测器获得指标 z-diff(Higgins 等人,2017),z-min-var(Kim 和 Mnih,2018)和信息性(Eastwood 和 Williams,2018)。
所有实验均在具有以下规格的计算机上进行:CPU:AMD EPYC 7413 24-Core,GPU:2x NVIDIA A100-SXM4-80GB,内存:200GB。LangVAE 允许缓存基础编码器输出,导致训练时间主要由基础解码器推理时间主导。最短的训练时间为约 1 小时(GPT-2),最长约为 4.5 小时(Mistral-7B)。较大解码器的训练要求与推理类似扩展,Phi-4 (14B) 的训练运行也大约需要 4.5 小时完成。LangVAE 训练模型与基础 LLM 的比例为:GPT-2 = 0.547,Qwen2.5-3B = 0.024,Llama3.2-3B = 0.076,Mistral-7B = 0.037。排除 GPT-2 后,这代表了超过 95%95 \%95% 的参数减少。
5.2 数据
所有测试均使用相同的数据:EntailmentBank 数据集(Dalvi 等人,2021)中所有解释句子的一个子集,使用 saf-datasets 7{ }^{7}7 库加载。该数据集包含 12496 句话,其中 99%99 \%99% 用于训练,1%1 \%1% 用于验证 8{ }^{8}8。评估是在包括验证集和一小部分训练集在内的 200 句随机样本上进行的。
SRL 注释使用 AllenNLP 9{ }^{9}9 库和最先进的 SRL 模型(Shi 和 Lin,2019)进行。
5.3 结果
表 1 展示了解释句子建模任务的结果。第一个观察结果是,最小模型组合(针对 SRL)取得了最高的重建性能。虽然这不是预期的结果,但这可以归因于潜在空间大小的限制,加上有限的训练数据,导致较简单的模型更好地泛化输入。
编码器复杂性对模型的泛化能力有重大影响:即使 bert-base-cased 和 flan-t5-base 的编码大小相同(768),BERT 在大多数情况下优于 T5,表明 T5 的信息纠缠程度更高。另一方面,Stella 的编码大小更大(1536),基于信息损失对降维的主导效应更大。
在模型中注入 SRL 类别在所有组合中都改善了重建性能,除非 Mistral 是解码器。这是一个令人惊讶的结果,表明 Mistral 的内部表示有一些特殊性,值得进一步研究。
最后,SRL 类别并未在解耦得分上带来一致的改进,
表 1:解释句子建模实验的结果。每列的最佳值加粗显示。
除了 Llama3.2,它带来了定性改进,如图 5(附录 B)所示。
6 结论
在本工作中,我们介绍了 LangVAE,这是一个用于构建语言模型 VAE(LM-VAE)的模块化和高效的库,以及其配套框架 LangSpace,专注于 LM-VAE 潜在空间的控制、探测和评估。为了降低这一研究领域的实验障碍,它引入了一种新的方法,用于将潜在向量解池化到自回归 LM 中,显著减少了训练此类模型的计算和内存需求,同时还提供了一个面向现代 LLM 开发的灵活代码架构。
我们通过一系列实验展示了 LangVAE 和 LangSpace 的能力,使用不同的编码器和解码器组合以及带注释的输入,揭示了在泛化和解耦方面跨越架构家族和规模的广泛交互作用。这些交互作用指出了模型内部表示属性及其信息交换的未被发现的因素。
7{ }^{7}7 https://github.com/neuro-symbolic-ai/saf_ datasets
8{ }^{8}8 验证拆分在这里只是为了跟踪过拟合的训练进度,因为数据集较小。
9{ }^{9}9 https://github.com/allenai/allennlp-models
参考文献
略
A API 示例
A.1 LangVAE
创建基于 GPT-2 的解码器,期望
潜在向量大小为 128,
最多生成 32 个标记,
分布在任意数量的 CUDA GPU 上。
decoder = SentenceDecoder(
“gpt2”, latent_size=128,
max_len=32, device=“cuda”,
device_map=“auto”
)
# 创建基于 BERT 的编码器,生成
# 潜在向量大小为 128,期望
# GPT-2 标记化输入。
encoder = SentenceEncoder(
“bert-base-cased”, latent_size=128,
decoder.tokenizer, device=“cuda”
)
# 定义基本 VAE 模型配置
model_config = VAEConfig(latent_dim=128)
# 初始化 LangVAE 模型
model = LangVAE(
model_config, encoder, decoder
)
# 或者,从 HF Hub 加载预训练
# 检查点。
org = “neuro-symbolic-ai”
name=“eb-langvae-flan-t5-base-gpt2-1128”
model = LangVAE.load_from_hf_hub(
f"{org}/{name}"
)
B 定性结果
我们在这里展示了未能放入正文的定性结果。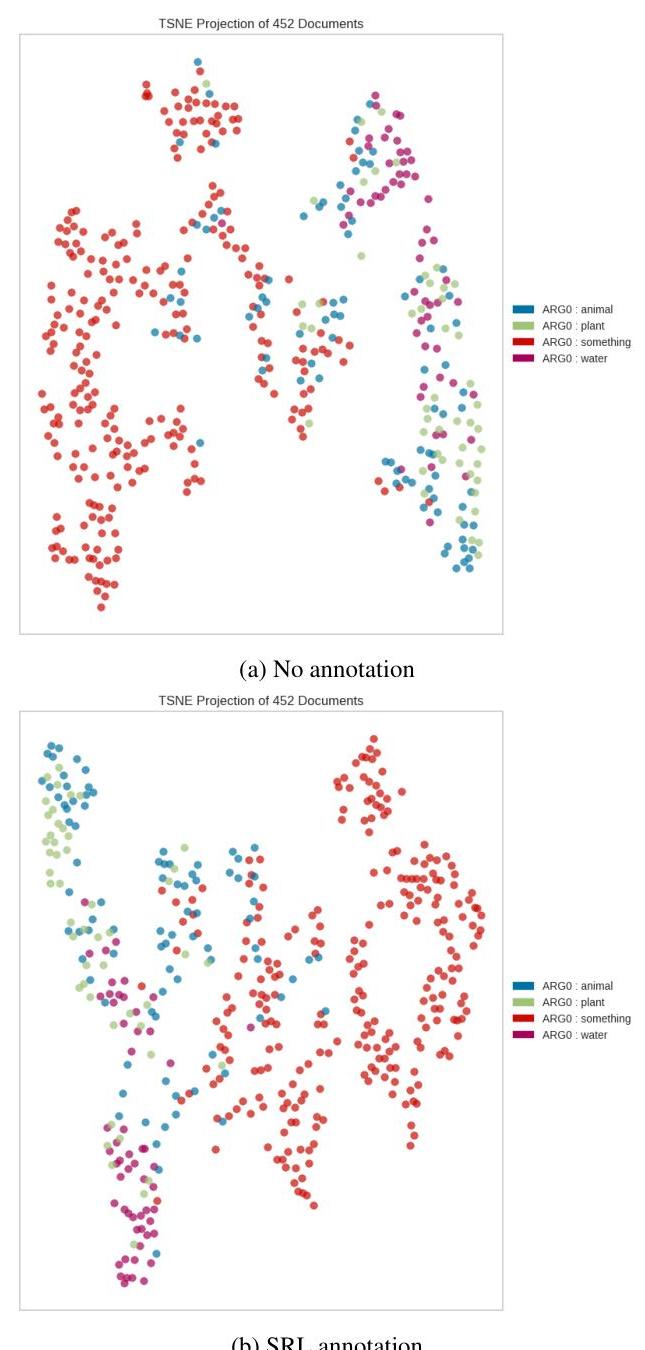
图 5:[bert-base-cased, Llama-3.2-3B] 组合的 TSNE 图,无(a)和有(b)SRL 注释输入。我们可以观察到注释模型中水和动物主题的更好分离。
| 源 | 目标 | 距离 | 生成 |
|---|---|---|---|
| 大海深处 | 大陆 | 0.361 | 1. the high 2. the high 3. the sea 4. the sea 5. the sea 6. the sea 7. the sea 8. the land 9. the world 10. the world |
| 小学生 | 大学生 | 0.299 | 1. a primary school 2. a primary school 3. a junior school 4. a junior school 5. a high school 6. a high school 7. a high student 8. a college 9. a college 10. a student |
表 2:使用 Wiktionary 数据集训练的 LangVAE 模型的插值示例。连接源和目标潜在向量的十个点被解码以生成插值句子列表。我们可以观察到当连接具有中间含义的术语时的语义进展。
参考论文:https://arxiv.org/pdf/2505.00004

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)