大模型微调:不冻结参数 vs 冻结主干
大模型微调主要有两种方式:不冻结参数的全模型微调和冻结主干仅训练线性分类头。全模型微调更新所有参数,适用于数据量大、任务复杂的场景,能获得最佳性能但计算成本高;冻结主干方式仅训练分类层,计算效率高、避免过拟合,适合小数据集和简单任务。本文对比了两种方法的优缺点,提供了BERT模型微调的代码示例,并列举了相关论文应用案例。
大模型微调方式:不冻结参数与冻结主干部分仅加入线性分类头
随着大模型(如BERT、GPT、ResNet、CLIP等)的发展,微调(Fine-tuning)已经成为深度学习中处理特定任务的主要方法之一。微调通过在已有的大规模预训练模型的基础上进行少量调整,使得模型能够更好地适应下游任务。大模型微调有多种策略,常见的两种方式是不冻结参数和冻结主干部分,仅加入线性分类头。本文将详细探讨这两种微调方式的原理、优缺点、适用场景,并提供相关的代码示例和公式。
微调方式概述
1. 不冻结参数,在大模型上继续训练现有的数据
在这种方式下,整个大模型的所有参数都会被更新。也就是说,不仅仅是任务头(如分类层、回归层等)被训练,而是包括特征提取部分(如BERT中的Transformer层或ResNet中的卷积层)的参数都进行优化。通过在下游任务数据集上继续训练,模型会更好地适应新任务的要求。
2. 冻结主干部分,仅加入线性分类头
这种方式则是冻结主干网络的参数(例如,BERT中的Transformer层或ResNet中的卷积层),只对任务相关的输出层(通常是一个线性分类头)进行微调。冻结主干部分的参数意味着这些层的参数在训练过程中不会被更新,从而减少了计算成本,且能够避免过拟合。
不冻结参数,在大模型上继续训练现有的数据
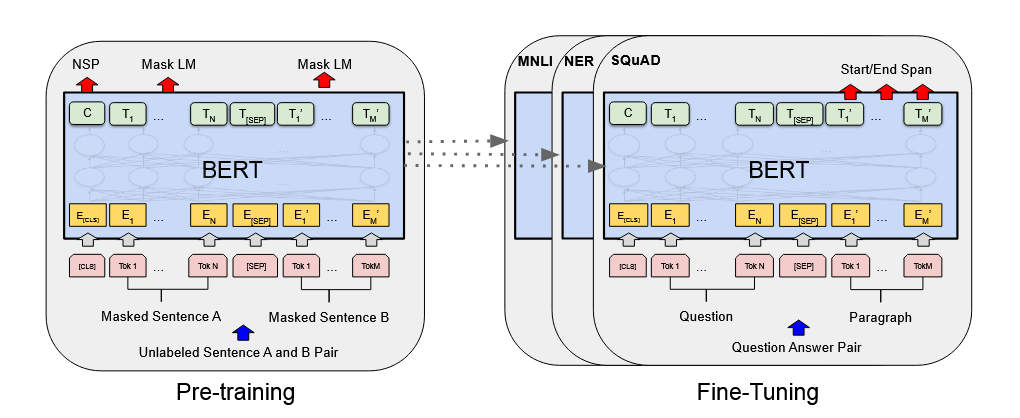
工作原理
这种方式的核心是继续优化整个大模型,包括预训练阶段已学到的特征提取层和任务相关的输出层。训练过程中,所有层的参数都会通过梯度下降算法进行调整,以最小化损失函数。
过程:
- 加载预训练模型:从头开始加载一个在大规模数据集(如ImageNet、Coco、Wiki等)上预训练好的大模型。
- 替换任务头:根据具体任务(如图像分类、情感分析等),替换或调整模型的输出层(例如,使用一个与类别数相匹配的线性层)。
- 继续训练整个模型:使用目标任务的数据继续训练整个模型,所有参数都会更新。
- 更新所有参数:模型在任务数据上的损失(如交叉熵损失、均方误差损失等)会通过反向传播更新模型的所有参数。
公式:
假设我们在进行分类任务时使用交叉熵损失函数,模型的输出为 ( \hat{y} ),真实标签为 ( y ),那么损失函数为:
L∗cross-entropy=−∑∗i=1Nyilog(y^i) \mathcal{L}*{\text{cross-entropy}} = - \sum*{i=1}^{N} y_i \log(\hat{y}_i) L∗cross-entropy=−∑∗i=1Nyilog(y^i)
其中,( NNN ) 是类别数,( yiy_iyi ) 是真实标签的 one-hot 编码,( y^i\hat{y}_iy^i ) 是模型预测的概率分布。
在反向传播过程中,所有模型参数(包括特征提取部分和输出层)都会通过梯度下降算法更新。
优缺点:
-
优点:
- 最大化适应性:微调整个模型,所有层次的参数都能根据新任务的数据进行优化。
- 更高的任务适应性:对于复杂任务,微调整个模型能够让其在特定任务上表现得更好。
-
缺点:
- 训练成本高:需要更新所有参数,这对于大模型来说意味着巨大的计算量。
- 过拟合风险:如果任务数据量较少,整个模型微调可能会导致过拟合,尤其是在数据不足的情况下。
适用场景:
- 数据集较大,计算资源充足时。
- 需要深度微调,尤其是处理复杂任务时。
冻结主干部分,仅加入线性分类头
工作原理
与第一种方式不同,这种方式冻结大模型的主干部分(例如,BERT中的Transformer层或ResNet中的卷积层),只训练任务头部(如分类层或回归层)。冻结主干部分的参数意味着预训练时学到的知识不会受到修改,而只是通过修改任务相关的输出层来调整模型。
过程:
- 加载预训练模型:加载一个预训练好的大模型,通常包括图像或文本特征提取的主干部分。
- 冻结主干部分:将特征提取部分的参数冻结,即设置这些层的
requires_grad=False,确保它们不会在训练过程中被更新。 - 添加任务头:根据任务要求添加一个适当的任务头,如一个线性分类层或回归层。
- 训练任务头:仅训练任务头部分的参数,这样可以节省计算资源并避免过拟合。
公式:
假设我们使用线性分类头进行分类任务,模型的输出为 ( \hat{y} = W \cdot x + b ),其中 ( W ) 为任务头的权重,( x ) 为从主干部分提取的特征,( b ) 为偏置项,损失函数依旧使用交叉熵损失:
L∗cross-entropy=−∑∗i=1Nyilog(y^i) \mathcal{L}*{\text{cross-entropy}} = - \sum*{i=1}^{N} y_i \log(\hat{y}_i) L∗cross-entropy=−∑∗i=1Nyilog(y^i)
在这个过程中,只有任务头的参数 ( WWW ) 和 ( bbb ) 会被更新,而特征提取部分的参数将保持不变。
优缺点:
-
优点:
- 计算效率高:只需要训练任务头,大大减少了训练的计算量和时间消耗。
- 更少的内存需求:不需要存储和更新整个模型的所有参数。
- 避免过拟合:通过冻结主干部分,避免在小数据集上过拟合。
-
缺点:
- 模型适应性有限:冻结主干部分的参数限制了模型对新任务的适应能力,可能无法充分发挥预训练模型的潜力。
- 无法优化特征提取层:对于一些任务,预训练的特征提取层可能不足以处理新任务的数据,导致性能不如全模型微调。
适用场景:
- 数据集较小,计算资源有限时。
- 目标任务与预训练任务非常相似时,或者任务相对简单时。
比较表格
| 微调方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 不冻结参数 | - 适应性强,能够获得最佳性能 | - 训练成本高,计算资源消耗大,可能过拟合 | - 数据量大,任务复杂,计算资源充足时 |
| 冻结主干部分,仅加入线性分类头 | - 训练效率高,计算资源消耗少,避免过拟合 | - 模型适应性有限,无法充分优化 | - 数据集较小,计算资源有限,任务简单时 |
代码示例
不冻结参数的微调
假设我们使用的是BERT模型进行文本分类,下面是一个简单的代码示例:
from transformers import BertForSequenceClassification, AdamW
from torch.utils.data import DataLoader
# 加载预训练的BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 定义优化器
optimizer = AdamW(model.parameters(), lr=1e-5)
# 数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=16)
# 训练过程
model.train()
for batch in train_dataloader:
inputs = batch['input_ids']
labels = batch['labels']
optimizer.zero_grad()
outputs = model(input_ids=inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
冻结主干部分,仅加入线性分类头
在这种情况下,我们冻结主干部分,只训练任务头部:
from transformers import BertForSequenceClassification, AdamW
from torch.utils.data import DataLoader
# 加载预训练的BERT模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 冻结BERT的主干部分(即Transformer层)
for param in model.bert.parameters():
param.requires_grad = False
# 定义优化器,只优化任务头部分
optimizer = AdamW(model.classifier.parameters(), lr=1e-5)
# 数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=16)
训练过程
model.train()
for batch in train_dataloader:
inputs = batch['input_ids']
labels = batch['labels']
optimizer.zero_grad()
outputs = model(input_ids=inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
相关论文:两种微调方式的应用
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018)
这篇论文介绍了BERT模型的预训练方法,并讨论了在下游任务中使用不冻结参数的微调方式,帮助模型充分适应任务数据,尤其是在文本分类和问答任务中取得了显著的效果。 -
Universal Visual Representation Learning via Contrastive Multimodal Pre-training (Lu et al., 2021)
该论文提出了一种视觉-语言预训练方法,使用了冻结主干部分和微调任务头的方式,在图像描述生成和视觉问答任务中获得了良好的性能。冻结主干部分的计算效率使得该方法在数据和计算资源较为有限的场景下表现出色。 -
Attention is All You Need (Vaswani et al., 2017)
论文介绍了Transformer架构,并讨论了该架构在自然语言处理中的应用。基于Transformer的BERT和GPT等模型通常采用不冻结参数的微调方式来处理下游任务,获得更高的适应性。 -
Deep Residual Learning for Image Recognition (He et al., 2015)
该论文提出了ResNet模型,并展示了如何使用冻结主干部分微调技术应用于图像分类任务。通过冻结卷积层,只训练全连接层,ResNet在较小数据集上取得了良好的性能。
结论
根据任务的复杂性和计算资源的限制,我们可以选择不同的微调方式。不冻结参数适合需要深入调整的大规模任务,而冻结主干部分,仅加入线性分类头则在计算资源有限或任务较为简单时更加高效。通过合理选择微调方式,我们可以在不同的应用场景中获得最佳的模型表现。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)