Provable Robust Watermarking for AI-Generated Text(从“统计小改动”到“可证明鲁棒”的文本水印)
我们能否“可靠地标记出”哪段文本来自某个大模型,而不是靠猜?论文解决的问题是什么?大模型生成文本越来越像人写的,传统“AI 内容检测器”靠统计模式去猜,很容易被分布漂移、提示工程和简单的改写攻击打崩。论文要解决的是:如何给模型生成的文本打上一个“几乎擦不掉”的水印,并且在数学上证明:想抹掉水印,需要付出很大的编辑代价。有何历史意义和性能突破?作者做了三件关键事:1. 给文本水印提出了一个严谨的理论
1. 论文基本信息
标题:Provable Robust Watermarking for AI-Generated Text
作者:Xuandong Zhao, Prabhanjan Ananth, Lei Li, Yu-Xiang Wang
年份:2023
领域关键词:Large Language Models, Text Watermarking, Robustness, Hypothesis Testing, Differential Privacy
2. 前言:为什么读这篇论文?
这篇论文在讨论一件很现实的事:我们能否“可靠地标记出”哪段文本来自某个大模型,而不是靠猜?
-
论文解决的问题是什么?
大模型生成文本越来越像人写的,传统“AI 内容检测器”靠统计模式去猜,很容易被分布漂移、提示工程和简单的改写攻击打崩。论文要解决的是:
> 如何给模型生成的文本打上一个“几乎擦不掉”的水印,并且在数学上证明:想抹掉水印,需要付出很大的编辑代价。
-
有何历史意义和性能突破?
作者做了三件关键事:
1. 给文本水印提出了一个严谨的理论定义(质量、I/II 类错误、安全性都被形式化),而不是“实验好用就行”。
2. 提出了一个极其简单的 Unigram-Watermark 方法,却证明了它在质量损失可控的前提下,对编辑攻击具有线性级别的鲁棒性(需要 Θ(n) 级编辑才能稳定抹掉)。
3. 在多种模型(GPT2-XL、OPT-1.3B、LLaMA-7B)和数据集上验证,检测准确率高、文本困惑度几乎不变,并且在 paraphrase / 编辑攻击下明显优于之前的 K-gram 水印(Kirchenbauer et al., 2023)。 -
为什么值得写一篇解读?
对我来说,这篇论文有几个很“值得细读”的点:
- 它把“水印鲁棒性”这件事从经验问题,提升到了可证明的理论层面;
- 方法本身简单到可以在已有推理代码里几行实现,却能导出挺强的理论结论;
- 它与差分隐私、统计假设检验等工具的连接,实际给日后 LLM 安全方向提供了一套模板;
- 在目前“检测 AI 文本是否可能本身就是不可能任务”的争论中,这篇工作给出了一个有边界、有条件的“可以”。
3. 基础概念铺垫(阅读所需的最小知识)
先把论文里反复出现的几个概念用尽量通俗的话铺垫一下,方便后面阅读。
语言模型与 token 分布
大语言模型可以看成这样一个过程:给定一个前缀 ,模型输出下一 token 的概率分布
。内部实现上它会算一堆 logits (
),再过 softmax 得到概率。采样出来的序列 (
),就是我们看到的回答。
文本水印的基本想法
水印不去“事后猜这是不是模型写的”,而是在生成时故意往某些 token 上“轻轻偏一下概率”,让模型更倾向于选择一小撮“绿色 token”。
只要这种偏好足够稳定,我们就可以在检测时数一数:这段文本里绿色 token 比例是否显著偏高,从而判断“这是不是被打过这个水印的模型写的”。
编辑距离(Edit Distance)
论文里讨论鲁棒性时的“代价”是编辑距离:
> 从原文本变成攻击后的文本,需要做多少次插入 / 删除 / 替换操作。
它不关心语义,只看“你动了多少 token”。
Type I / Type II 错误
- Type I(假阳性):把无水印文本错判成“有水印”;
- Type II(假阴性):把有水印文本错判成“无水印”。
论文给出了这两类错误概率随文本长度增长而指数衰减的理论保证。
安全性(鲁棒性)
在这篇论文里,“安全性”主要指:
> 如果对手想通过编辑文本来绕过检测,那在绝大多数情况下,要么被检测出来,要么就不得不做大量编辑(编辑距离至少达到某个下界)。
4. 历史背景与前置技术
围绕“识别 AI 生成文本”这个目标,社区大概有两条路:
-
被动检测(post-hoc detection)
这条路线基于“AI 写的东西在统计上看起来有点不一样”。典型例子有:
- GLTR:看每个 token 在模型中的概率分位,如果整体都太“高频”,就怀疑是模型自己写的;
- DetectGPT:利用“概率曲率”来区分人类文本和模型文本;
- 各种 fine-tuned classifier,比如 OpenAI 提供过的 AI 文本分类器。
问题是:
- 模型一旦升级,统计模式会变化,旧检测器常常失效;
- 简单的 paraphrase、再生成、消融等攻击就能显著降低检测率;
- 对非母语写作有明显偏见——容易把他们写的文章当成 AI 写的。 -
主动水印(active watermarking)
另一条路是:既然被动猜不靠谱,那干脆在生成的时候就刻意加一点“隐形痕迹”。
Kirchenbauer et al. (2023) 提出了一类 K-gram 软水印:
- 根据前缀(长度 (K-1))通过哈希把词表切分成 green/red 两组;
- 对 green 组 token 的 logits 加上一点偏移,让模型更爱选 green;
- 检测时数 green token 比例,用 z-score 决定是否“有水印”。
它在正常情况下效果不错,但存在两个现实问题:
- 可编辑性:只要攻击者做足够的同义替换 / paraphrase,green / red 划分就被打乱了;
- 分析不足:鲁棒性的性质主要是实验观察,缺少清晰的理论界定。
除此之外,还有一系列更偏密码学的“不可检测水印”(cryptographic watermark),强调在“计算上不可区分”,但往往缺少“编辑鲁棒性”的保证,并且落地成本较高。
在这样的背景下,这篇论文做的事情可以看成是:
> 把 K-gram 思路中的 (K=1) 特殊情况拎出来,彻底分析清楚它在质量、检测错误率、安全性上的数学性质,并顺带改进鲁棒性。
5. 论文核心贡献(叙述式概括)
读完论文,我会把它的核心贡献总结成这样几句话:
首先,作者给出了一个形式化的“语言模型水印方案”定义:包含加水印算法 Watermark、检测算法 Detect,外加三类性质——质量保证、I/II 类错误界以及一个基于编辑距离的安全性定义。这些定义把“鲁棒水印”这个概念从口头描述变成了可证明、可比较的对象。
其次,他们提出了一个非常简单的方案 Unigram-Watermark:不再随前缀动态改变 green list,而是固定一次划分整个词表的 green/red,在生成时一直用同一组列表。这一点看上去反直觉(太简单、太容易学?),但作者证明,在这个家族里,这种“朴素”的做法其实是鲁棒性最强的。
第三,基于这个具体方案,他们给出了比较完整的理论分析:
- 质量方面:水印模型在任意 Rényi divergence 下与原模型的距离都被 上界住;
- 检测方面:对任意固定文本,z-score 的上界依赖文本多样性,因而能控制 Type I 错误;而在一些自然的“高熵 + 同质性”假设下,水印文本的 z-score 会随着长度以 增长,从而指数下降 Type II 错误。
- 安全方面:他们给出了一个明确的不等式,描述 z-score 在出现 次编辑后的最小下降幅度,由此推导出“想让 z-score 掉到阈值以下,必须做
级别编辑”。
最后,实验部分则证明:在多个模型、数据集以及 paraphrase / 编辑攻击之下,Unigram-Watermark 的检测 AUC、TPR 都比原 K-gram 方案高不少,而 perplexity 几乎不变,人工评价质量也几乎一模一样。这说明这个简单的设计在实践上也相当可用。
6. 方法详解:Unigram-Watermark 是怎么工作的?
6.1 问题形式与威胁模型
论文从一个比较抽象的角度重新描述了“给语言模型加水印”这件事:
-
语言模型
模型 (M) 在给定 prompt (x) 和前缀时,给出下一 token 的条件分布
。词表大小 (N=|V|) 一般是 50k 起步。
-
Watermark 算法
给定模型 (M),输出一个带水印的模型以及一个检测密钥 (k)。
,与
很接近,但对某些 token 施加了偏好。
-
Detect 算法
给定密钥 (k) 和待检文本 (y),输出 0 / 1:是否认为这是 -
质量约束
对任意 t,要求某种分布距离,确保不会严重损害生成质量。
-
错误类型
- Type I:对于任何“与 k 独立的固定文本” (y),误判为 1 的概率不超过 (\alpha_y);
- Type II:对于。
-
编辑鲁棒性 / 安全性
对任意对手 (A),它可以看到。
安全性要求:
> 以高概率,要么检测器仍然输出 1,要么 (ED(y, y_A)) 至少达到某个函数 (\eta(k,y,\epsilon))。
-
换句话说,想躲过检测,要么失败,要么付出很大的编辑代价。
威胁模型方面,论文假设对手只对模型有 黑盒访问(只见到输入输出),可以做任意后处理,但编辑距离有限。
6.2 Unigram-Watermark 的整体结构

【插图:论文 Algorithm 1 & 2 的主流程伪代码(第 5–6 页)】
6.2.1 Watermark:如何给模型“轻轻偏个心眼”
这一步的关键是:用密钥 (k) 把词表随机切成 绿色列表 (G) 和 红色列表 (R),比例由参数 (\gamma) 控制(一般 (\gamma \in (0,1)),如 1/3 或 0.5)。
具体做法:
-
使用随机数生成器 (F),根据密钥 (k) 把词表 (V) 划分为:
- 绿色列表 (G),大小;
- 红色列表。
-
对于每一个生成步骤 t:
- 先让原模型 (M) 计算 logits ();
- 对于 (v \in G),把它的 logit 加上常数 (
;
- 对于 (v \in R),保持不变。
- 然后在上做 softmax 得到
直觉上,这相当于对 green token 乘了一个常数因子 ,却没有改 prompt、没有改网络结构,实现上只是一层 logits 偏移。
参数角色:
- 越大,green token 越多,水印信号更“稀释”;一般
不宜太大;
- 越大,对 green 的偏好越强,检测更容易,但对原始概率分布扰动更大,质量风险更高。
6.2.2 Detect:统计上的“绿化偏好”检验
检测算法要做的事其实很简单——给定密钥 k,它知道 green list 是哪一批 token,于是:
-
数数这段文本中出现了多少个 green token:
。
-
计算 z-score:
如果文本是“随机”与 G 独立地生成的, 可以被看作 n 次伯努利试验,期望是 ,标准差是
,所以
正态化后大致在 0 左右波动。
-
设定一个阈值
:
- 若,输出 1(认为有水印);
- 否则输出 0。
论文里在实验上常用 作为经验阈值:
- 人类文本和无水印文本的 多在 [-3, 3] 内晃;
- 水印文本则经常能跑到 8、10 以上。

【插图:论文 Table 1 的示例回答对比(第 6–7 页),展示水印前后文本 + z-score】
6.3 质量保证:水印到底扰动了多少?
这里是论文比较“硬核”的第一块结果。
作者证明:对任意一步 t,水印前后分布在 任意 Rényi divergence 下都满足:
并且对称方向 也一样有这个上界。
这背后用到的是差分隐私里的一个分析套路——把 logits 加常数类比成“指数机制”,利用“有界范围(bounded range)”性质导出 Rényi DP 的界,再转成分布距离界。
这条结论有几个直接 corollary:
-
KL 散度:取
,得到
;
-
(L_1) / Total Variation:通过 Pinsker 不等式,得到 TV 距离上界约为
;
-
Max-divergence:令
,得到一个“乘性差分隐私”式的上界,说明对任意事件 S,
。
实话说,这些具体数字对日常直觉的意义就是一句话:
> 只要 (\delta) 不太大,水印版模型在单步分布上的改变是很小的,而且可以严格量化。
当考虑整个长度为 n 的序列时,利用自回归分解 + 组合定理,KL 散度大致是 级别,这也侧面解释了为什么 perplexity 几乎不变(实验部分会看到)。
6.4 Type I 错误:如何保证“没有乱抓人”?
对于任何 固定文本 (y)(不依赖密钥 k),并不假设它是人写的还是 AI 写的,只要求它的生成过程与 green list 无关。作者证明:在随机选择 green list 的前提下,(z_y) 会以高概率被一个 和文本多样性有关 的函数上界住。
为此他们引入了两个量:
-
:文本中出现次数最多的 token 的频数;
-
:大致是“token 频数平方和 / n”,可以理解为一个“多样性 / 重复度”的指标。
然后给出这样的高概率界(简化版):
直觉:
-
如果文本非常单一,比如全是同一个词(“goal goal goal ...”),那
很大、多样性很差,无论水印与否,green token 比例都可以极端偏离
,这时任何统计水印都无能为力;
-
在正常文本里,大部分词不会重复太多次,V 与
会集中在一个常数级的区间内。
更实用的一点是:阈值 可以根据具体文本的 V、
自适应选取,从而控制“对这段文本的特定假阳性率”。
6.5 Type II 错误:在什么条件下,一定能“抓得住”水印文本?
对于水印文本,作者需要两类假设来证明:z-score 会随着长度增长而系统性地变大。
-
On-average high entropy(平均高熵)
简而言之,要求模型在 roll-out 的过程中,平均来说每一步的分布不要太“尖”。
他们使用了作为“尖锐度”的 proxy:如果所有概率都差不多,
;如果几乎全压在一个词上(比如重复打印 alphabet),
假设是:
其中要足够小(大致与
同量级)。
-
Homophily(同质性)假设
这是论文中比较有意思、也颇具争议的一个假设:
> 当你把某个 token 标成 green,并在当前步稍微提高它的概率后,在未来的生成中,这个 token 的出现概率不会反而降低(平均意义上)。 -
换句话说,模型倾向于在后续继续沿用已经出现过、被偏好的词汇,而不是“专门避开它”。
这个假设用来排除一些刻意构造的反例,例如明确要求“后面不要再出现之前提到的那个颜色名”。
在这两个假设下,论文给出主定理:
- 期望上,green token 数量的增长速度会大于 ,偏差项与
成正比;
- z-score 的期望值大致为
这说明:z-score 的“信号强度”随长度 增长。
结合前面 Type I 的上界,可以选一个介于 与
之间的阈值
,让 Type I、Type II 错误都随 n 指数衰减。
6.6 安全性:对编辑攻击的鲁棒性分析
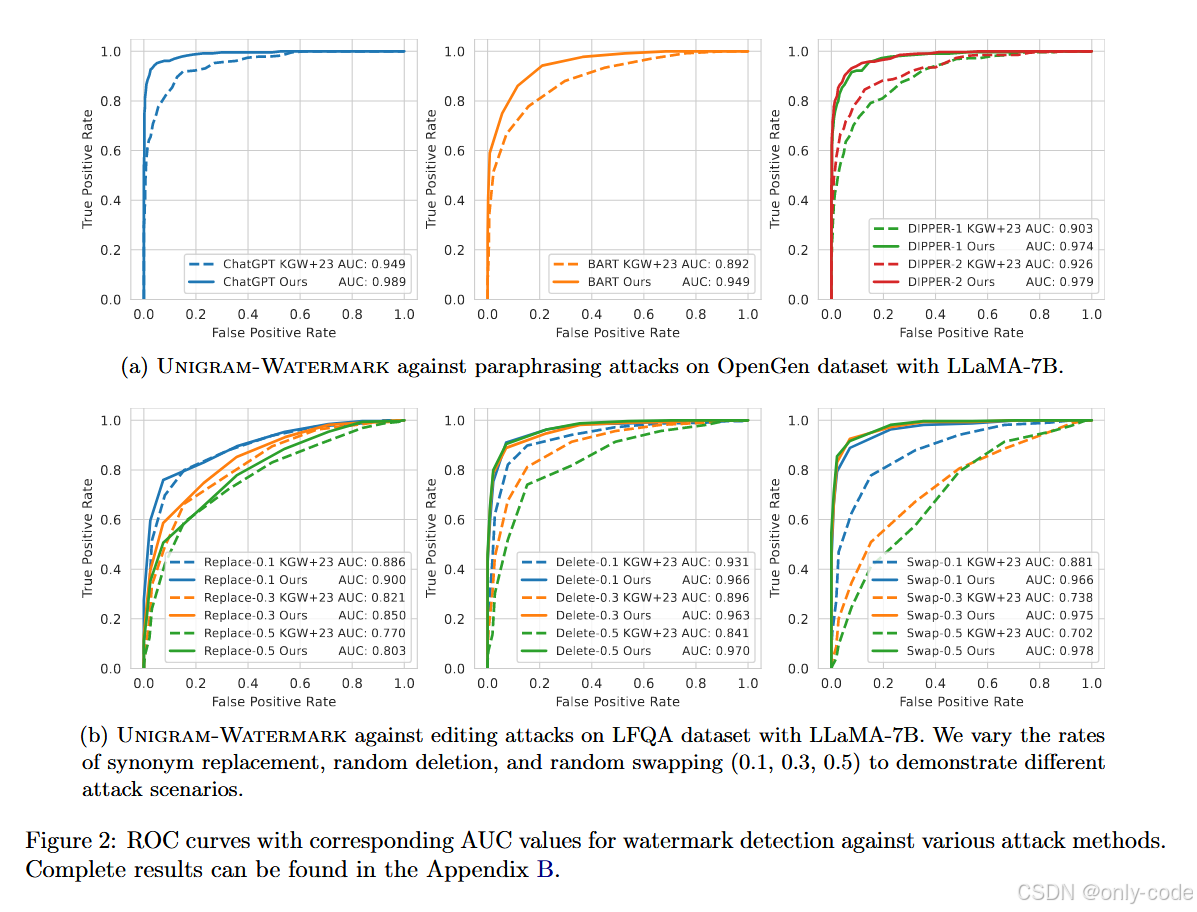
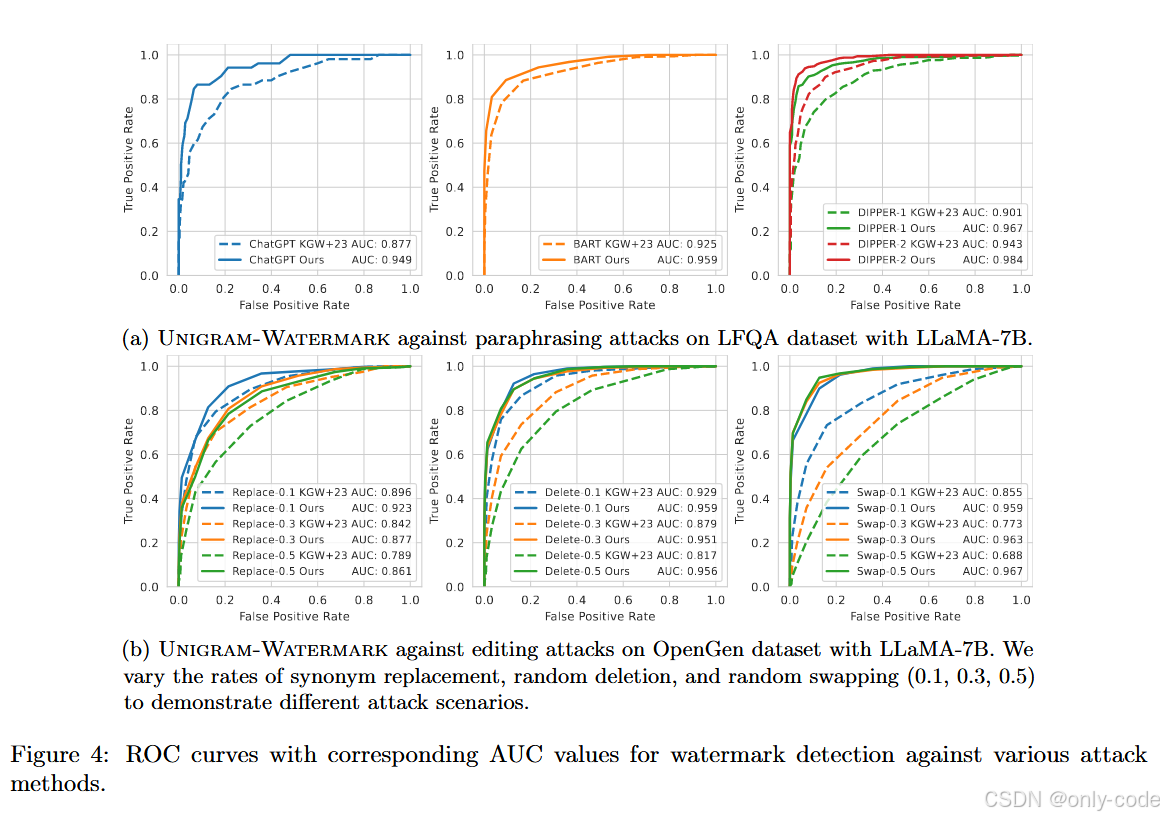
【插图:论文 Figure 2 & Figure 4 的 ROC 曲线(第 12、18–19 页),展示在各种攻击下的 AUC】
这里的直觉是:
-
每做一次“插入 / 删除 / 替换”,最多只能改变 1 个绿色计数以及总长度;
-
经过
次操作,总的绿色计数最多变化
,而归一化的 z-score 是除以
的,所以整体下降量是
;
-
只要原始 z-score 大约是
,阈值又在常数级别,那攻击者想把
压到阈值以下,就必须让
论文还对比了 Kirchnebauer 等人提出的 K-gram 方案(K≥2):
-
在 K-gram 里,每次编辑会影响 最多 2 个 bigram、甚至更多 K-gram;
因此可以说:
> 在同样的攻击强度下,Unigram-Watermark 至少是之前 soft watermark 的“两倍鲁棒”。
6.7 一点延伸:Unique 检测器与 Emoji 攻击
在附录中,作者还提出了一个“Unique” 版本的检测器:在计算 z-score 之前,先把文本去重、只统计 unique token 的 green 比例。这种检测器对一些“重复刷 emoji / 重复刷单词”的攻击更加稳健,也更容易控制 Type I 错误。
在大模型扩展实验(LLaMA-13B/65B)下,Unique 检测器在 ChatGPT paraphrase 攻击下依然能保持不错的 TPR。
7. 实验结果与性能分析
7.1 实验设置
数据集与 prompt
-
OpenGen:从 WikiText-103 中抽取两句开头作 prompt,后面 300 个 token 作为人类续写;
-
LFQA:长文问答数据集,从 Reddit 抓取问题和长答案,各领域共 3k QA 对。
在实验中,模型使用这些 prompt 生成续写或答案,供水印与检测使用。
语言模型
-
GPT2-XL(1.5B)
-
OPT-1.3B
-
LLaMA-7B
统一使用 nucleus sampling 作为默认解码策略,引入一定随机性但保证文本自然。
评估指标
-
检测方面:固定假阳性率为 1% / 10%,看真阳性率(TPR)、F1 与 ROC-AUC;
-
质量方面:用 GPT-3 (text-davinci-003) 做 perplexity 评估;
-
人工评估:AMT 工人对水印 / 无水印文本进行 1–5 分打分。
7.2 基础检测性能与文本质量
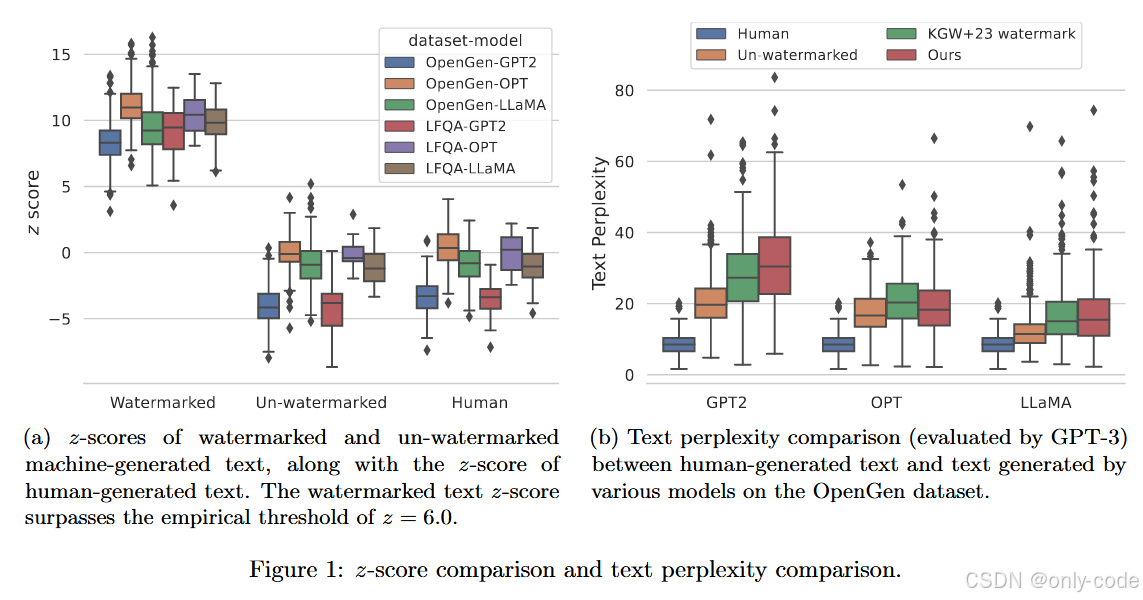
【插图:论文 Figure 1(a) – 不同模型 & 数据集下水印 / 无水印 / 人类文本 z-score 分布箱线图(第 10 页)】
图 1(a) 很形象地画出了三个分布:
-
人类文本的 z-score 基本围绕 0,略有波动;
-
无水印机器文本分布与人类很接近,略偏负;
-
水印文本整体明显右移,z-score 通常大于 6,很多甚至超过 10。
在阈值取 6 的情况下,三种模型 + 两个数据集的实验中,几乎看不到假阳性,而真阳性率在 0.94–1.0 之间(详见 Table 4),验证了理论里“错误率随长度指数衰减”的说法。
图 1(b) 对比了不同文本的 perplexity(由 GPT-3 测算):
-
人类文本 perplexity 最低,主要是因为 WikiText-103 与 GPT-3 的训练数据高度相关;
-
无水印机器文本、KGW+23 水印、Unigram 水印三者的 perplexity 非常接近;
-
在 LLaMA-7B 上,Unigram 水印的困惑度几乎与无水印相同。
人工评价方面(Table 3):
-
无水印文本平均得分 3.660,水印文本 3.665,标准差也几乎一样;
-
工人的盲评结果表明:从主观质量上几乎感受不到水印痕迹。
7.3 Paraphrasing 攻击的鲁棒性
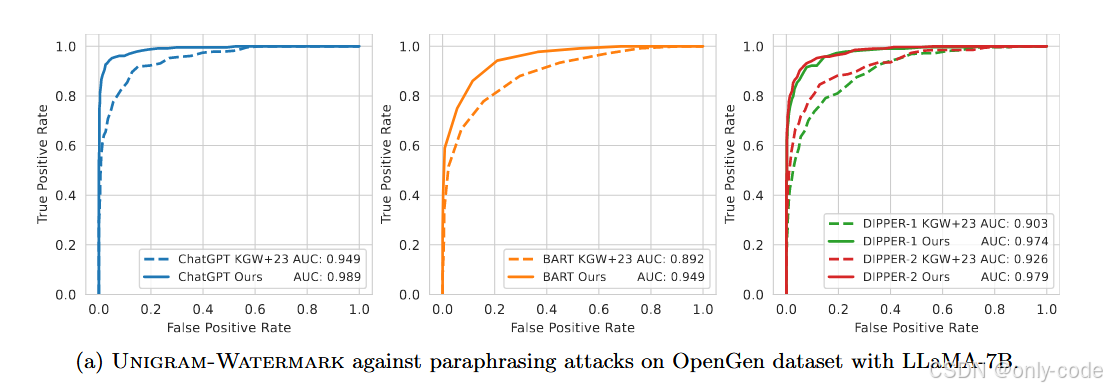
【插图:论文 Figure 2(a) – OpenGen + LLaMA-7B 下 paraphrasing 攻击 ROC 曲线(第 12 页)】
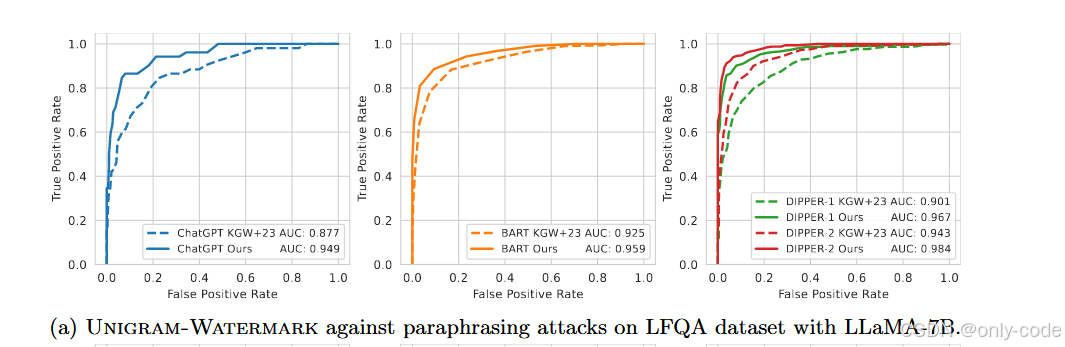
【插图:论文 Figure 4(a) – LFQA + LLaMA-7B 下 paraphrasing 攻击 ROC 曲线(第 19 页)】
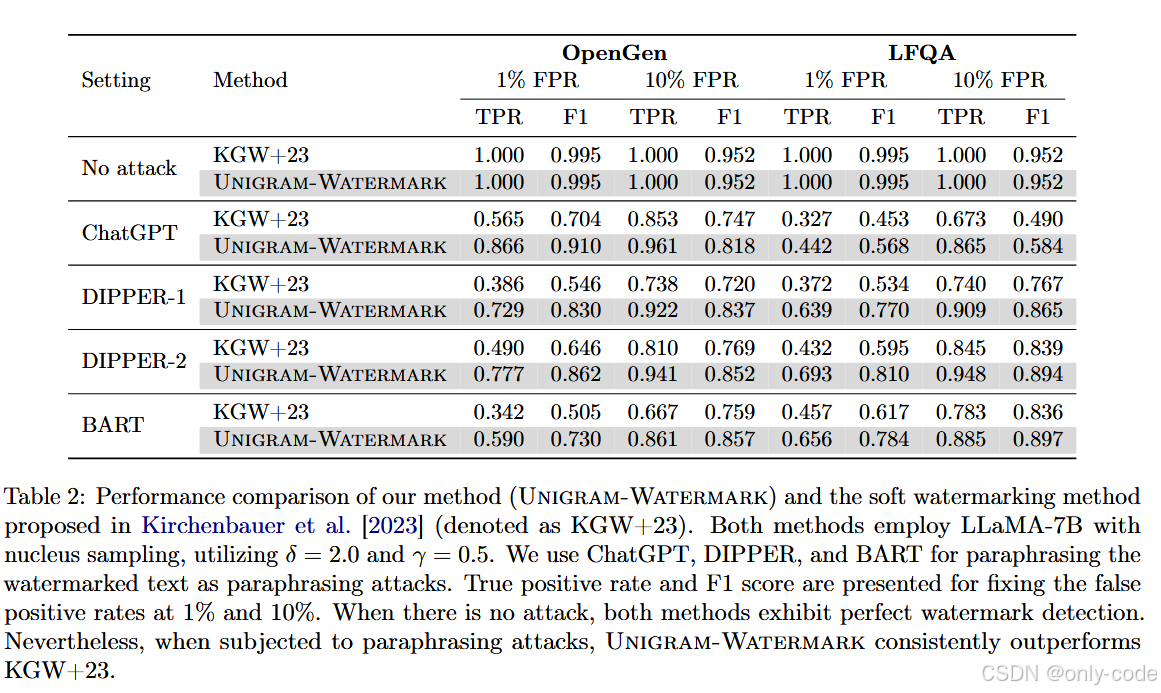
【插图:论文 Table 2 – 各类 paraphrasing 攻击下 Unigram vs KGW+23 的 TPR/F1 对比表(第 11 页)】
论文尝试了多种 paraphrasing 攻击:
-
DIPPER-1 / DIPPER-2:两种风格不同的 paraphrase 模型,2 在多样性上更激进;
-
ChatGPT paraphrase:直接让 ChatGPT “Rewrite the following paragraph”;
-
BART summarization:用 BART-large-CNN 做摘要,相当于“压缩 + 改写”攻击。
以 LLaMA-7B 为例,固定 10% FPR 时:
-
ChatGPT 攻击:
- KGW+23:OpenGen 上 TPR 0.853,LFQA 上 0.673;
- Unigram:OpenGen 上 0.961,LFQA 上 0.865。 -
DIPPER-2 攻击:
- KGW+23:OpenGen 0.810,LFQA 0.845;
- Unigram:OpenGen 0.941,LFQA 0.948。 -
BART 攻击:
- KGW+23:OpenGen 0.759,LFQA 0.783;
- Unigram:OpenGen 0.861,LFQA 0.885。
换成 ROC-AUC 看(Figure 2 & 4),在几乎所有攻击设置下,Unigram 的 AUC 都比 KGW+23 高出 0.04–0.10 左右。这与前面的安全性理论吻合:在同等 下,Unigram 的 z-score 下降更慢。
7.4 编辑攻击(Synonym / 删除 / 交换)
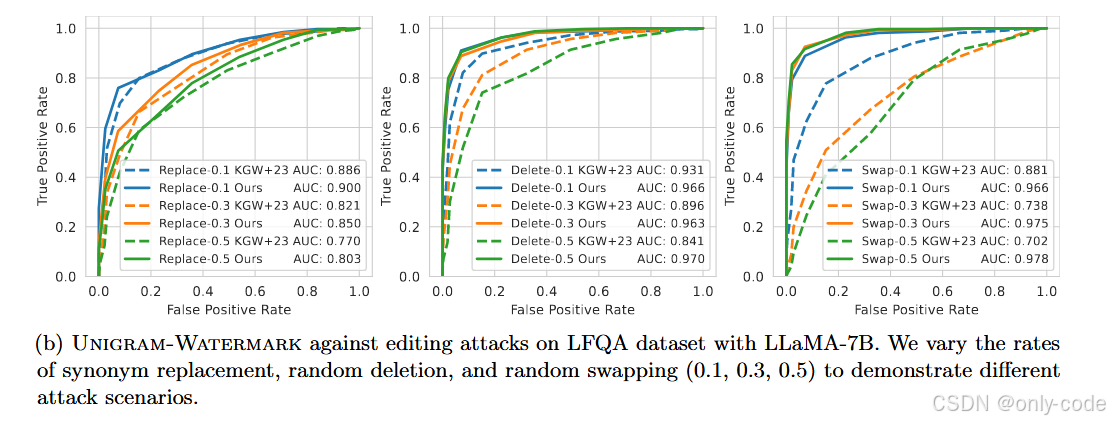
【插图:论文 Figure 2(b) – LFQA + LLaMA-7B 下编辑攻击 ROC(第 12 页)】
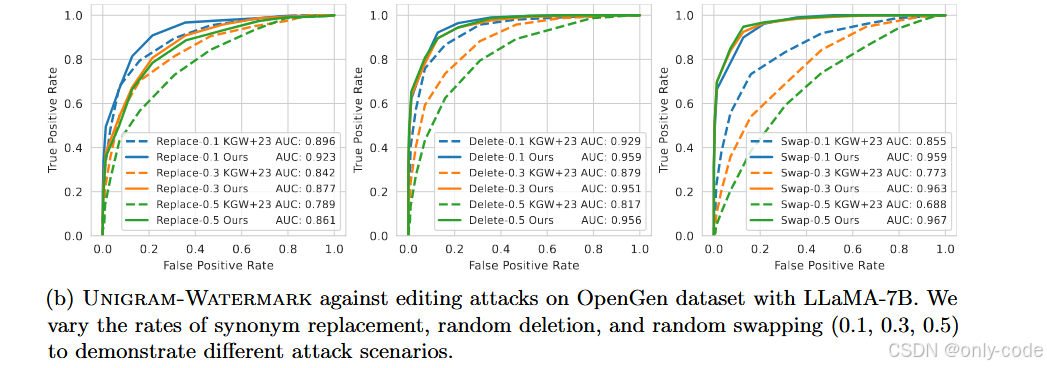
【插图:论文 Figure 4(b) – OpenGen + LLaMA-7B 下编辑攻击 ROC(第 19 页)】
作者又构造了几类纯编辑攻击:
-
Synonym Replacement:以 0.1 / 0.3 / 0.5 的概率把词替换成同义词;
-
Random Deletion:随机删除部分 token;
-
Random Swapping:随机交换相邻 token。
结果中可以看到:
-
在 OpenGen 上,Replace-0.5 情况下,
- KGW+23 AUC ≈ 0.77,
- Unigram AUC ≈ 0.80–0.86(看不同数据集); -
Delete-0.5、Swap-0.5 等更强攻击下,Unigram 的 AUC 依然在 0.86–0.97 之间,而 KGW+23 常常退到 0.7 左右。
这说明:即使在比较粗暴的随机编辑攻击下,Unigram 的检测优势仍然明显。
7.5 人类文本区分与偏见问题
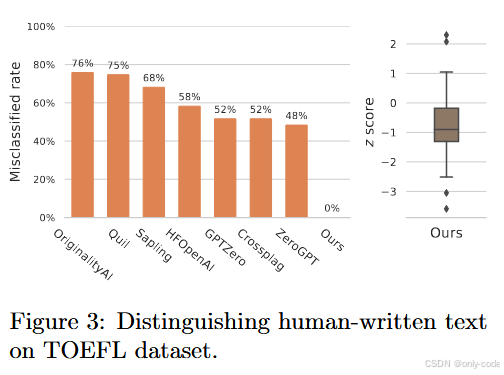
【插图:论文 Figure 3 – TOEFL 人类作文上各类 AI 检测器的误判率柱状图 + Unigram z-score 分布(第 11 页)】
论文还专门在一个 TOEFL 人类作文数据集上测试了当前一些 AI 文本检测器——OriginalityAI、ZeroGPT、GPTZero 等。这些检测器误将人类作文判为 AI 文本的比例高达 40–70% 不等,印证了 Liang et al. (2023) 提到的“对非母语写作存在强偏见”。
而对同一批作文,Unigram 检测器给出的 z-score 分布整体靠近 0,远低于 6 的阈值。这一点很重要:
> 水印方案不试图解决“所有 AI 文本检测”的难题,而是专注于“检测来自某个水印模型的文本”。因此对人类文本天然是保守且友好的。
7.6 白盒攻击与 green list 可学习性
考虑到 Unigram 的 green list 是固定的,直觉上攻击者可能尝试“估计哪一批 token 是 green”,然后在生成时刻意避开。作者模拟了这样一个“白盒”场景:
-
用 LLaMA-13B 水印模型生成约 70 万 token;
-
收集三种“人类分布”:真实人类回答、C4 数据集、非母语作文;
-
用“频率差分”去猜每个 token 是 green 还是 red。
结果是:即便在数据丰富、人类分布近似的情况下,对 green list 的估计也不够准确;即使假设攻击者已经知道真实的 green list,利用同义替换做针对性攻击时,想保持检测 AUC 大幅下降,就要牺牲相当多的文本质量(perplexity 飙升到 100+)。
这表明:从实际攻击成本的角度看,Unigram 在“可学习性 vs. 鲁棒性”的权衡上处在一个还算合理的位置。
8. 亮点与创新点总结
如果要挑几个我个人觉得最值得记住的点,大概会是这些:
第一,它把“LLM 文本水印”这件事做成了一个完整的理论对象。
之前的工作大多只是描述一个 heuristic,也许给出一点误差界,但很少把“质量、I/II 错误、安全性”统一在一个定义里。这里的 Definition 2.2 + 一系列定理,实际上为后续所有水印工作提供了一个“公共语言”。
第二,一个极其简单的设计,却有很强的鲁棒性证明。
Unigram-Watermark 不需要看前缀,只是固定一次 green list,把 logits 加一下。
结果却是:
- 质量可以通过 Rényi divergence 严格上界;
- 检测的 z-score 在水印 vs. 非水印之间有 的间隙;
- 对编辑攻击的鲁棒性是之前 K-gram 的“两倍”。
这种“简单 + 可证明”的组合,在安全方向里是非常有吸引力的。
第三,它把差分隐私、浓缩不等式等数学工具用在了一个很具体的 LLM 安全问题上。
单步分布的分析用到了 DP 中的 bounded range / concentrated DP;多步 roll-out 的分析使用了一些针对依赖随机变量的集中不等式。这说明,用对了抽象层级,很多看似“遥远”的理论其实可以服务于具体工程问题。
第四,它给出了一个关于“水印 vs. paraphrasing 不可能性”的细致回应。
在“检测 AI 文本是否可能”这场争论中,有人从信息论角度给出了很多负面结果。但这篇论文的立场是:
- 如果只看 token 级别的统计,我们可以把水印模型和原模型做得非常接近;
- 但在 序列级别(长上下文)上,通过累积偏差,仍然可以分辨两者;
- 只要攻击者的编辑能力被限制为“有限编辑距离”,那水印就有机会变成“几乎不可擦除”。
这种有边界、条件清晰的“乐观结论”,比简单说“检测不可能 / 检测可能”要成熟得多。
9. 局限性与不足
论文最后也坦率提到了一些限制,我在这里稍微展开一点。
-
固定 green-red 划分的“可学习性”问题没有完全解决。
虽然作者实证表明估计 green list 不容易,但在更长时间、更强对手(比如联合使用多个未水印模型做对抗训练)的场景下,这个假设能不能撑住,还是一个问号。未来可能需要在“定期刷新 green list / 多密钥混用”上做更多设计。 -
安全定义依赖编辑距离,对“语义保持的 paraphrasing”刻画不足。
从用户/监管者角度看,很多攻击是“把意思不变地重写一遍”,这类操作在语义空间代价很小,但 edit distance 可能很大。
论文承认:在这种情况下,虽然检测可能仍然奏效,但“编辑距离大所以攻击代价大”的论证就显得有点形式主义了。 -
高熵与同质性假设在实际 prompt 下是否普遍满足,还缺少系统检验。
比如在一些非常结构化的任务(代码生成、模板填空)里,分布可能远比自然语言答复尖锐得多;
而在有明确否定指令的 prompt 中,“homophily” 可能明显不成立。
在这些场景下,理论保证会变得较弱,或者需要重新分析。 -
计算与部署的视角比较乐观。
虽然在单模型上,加水印的开销确实很小,但在现实中:
- 不同机构、不同模型之间如何协同使用相同或兼容的水印方案?
- 如何管理密钥、轮换策略,并防止被泄露或滥用?
这些在论文中都还没有展开。 -
对多语种、跨领域的表现尚未充分评估。
目前实验主要集中在英文 Wiki 与 Reddit 风格文本上。对其他语言、其他风格(法律、医学、代码)文本的熵特性与 homophily,可能会很不同,水印效果也可能显著变化。
10. 全文总结
把前面的内容压缩成几句话,大致是这样:
这篇论文试图在“给 LLM 文本打水印”这件事上,画出一条理论上站得住脚的分界线。 它定义了什么是一个合格的水印方案——既要控制质量损失,又要在 I/II 类错误和安全性上给出清晰的概率界。
具体实现上,它选了一个极简的方案:固定 green list,一直对其 logits 加常数。在这个看似朴素的设计上,作者用 Rényi divergence、集中不等式、高熵与 homophily 假设等工具,证明了生成质量基本不变、检测 z-score 在有无水印之间存在 的显著间隙,并给出了对编辑攻击的明确鲁棒性界——想擦掉水印,必须做与长度同阶的编辑。
从实验侧看,在多个公开模型和数据集上,这个水印方法在保证文本自然度的前提下,展现出了比以往 K-gram 方案更好的检测和鲁棒性表现,同时对人类文本保持了较低的误判率。它并没有解决“所有 AI 文本检测”的终极难题,但在“识别来自特定模型的生成文本”这一更窄的问题上,给出了一个既简单又有说服力的答案。
如果后续围绕 LLM 安全、合规的制度设计真的要落地,像这样的“可证明、可部署的水印协议”,很可能会成为工具箱里不可或缺的一员。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)