Flow Matching and Diffusion Models
本文介绍了基于常微分方程(ODEs)和随机微分方程(SDEs)的生成模型框架,包括Flow Model和Diffusion Model。Flow Model通过确定性ODE将初始分布转化为数据分布,而Diffusion Model通过引入随机性的SDE实现转换。二者都通过优化目标向量场来训练模型,其中Flow Model直接学习向量场,Diffusion Model还需学习分数函数。文章详细推导了
Introduction
生成对象(Object):对图像,视频,蛋白质等数据类型可视为向量,即 z∈Rdz \in \mathbb{R}^dz∈Rd
生成(Generation):从数据分布中采样,z∼pdataz \sim p_{data}z∼pdata
数据集(Dataset):服从数据分布的有限样本,z1,...,zN∼pdataz_1, ...,z_N \sim p_{data}z1,...,zN∼pdata
条件生成(Conditional Generation):从条件分布中采样,z∼pdata(⋅∣y)z \sim p_{data}(\cdot \mid y)z∼pdata(⋅∣y)
目标:训练生成模型,将初始分布(pinitp_{\text{init}}pinit)的样本转化为数据分布样本pdatap_{\text{data}}pdata
Flow and Diffusion Models
通过模拟常微分方程(Ordinary Differential Equations, ODEs)和随机微分方程(Stochastic Differential Equations, SDEs)可以实现从初始分布到数据分布的转换,分别对应Flow Model和Diffusion Model
Flow Models
Flow Model可以由ODE来描述,即
X0∼pinit▹random initddtXt=utθ(Xt)▹ODEGoal: X1∼pdata⇔ψ1θ(X0)∼pdata X_0 \sim p_{\text{init}} \quad \triangleright \text{random init}\\ \frac{d}{dt}X_t=u_t^\theta(X_t) \quad \triangleright \text{ODE} \\ \text{Goal: } X_1 \sim p_{\text{data}} \Leftrightarrow \psi_{1}^{\theta}(X_0) \sim p_{\text{data}} X0∼pinit▹random initdtdXt=utθ(Xt)▹ODEGoal: X1∼pdata⇔ψ1θ(X0)∼pdata
其中向量场 utθ:Rd×[0,1]→Rdu_t^\theta: \mathbb{R}^d\times[0,1] \rightarrow \mathbb{R}^dutθ:Rd×[0,1]→Rd 为神经网络,θ\thetaθ为参数。ψtθ\psi^\theta_tψtθ描述了由utθu_t^\thetautθ引起的Flow,为ODE方程解(Trajectory)的集合
通过使用Euler算法,可以模拟ODE计算出Flow,实现从Flow Model中采样

Diffusion Models
Diffusion Model可以由SDEs描述,如下所示(由于其随机性SDEs不使用微分表示形式)
dXt=utθ(Xt)dt+σtdWt▹SDEX0∼pinit▹random initializationGoal: X1∼pdata dX_t = u_t^\theta(X_t)dt +\sigma_tdW_t \quad \triangleright \text{SDE} \\ X_0 \sim p_{init} \quad \triangleright \text{random initialization} \\ \text{Goal: } X_1 \sim p_{\text{data}} dXt=utθ(Xt)dt+σtdWt▹SDEX0∼pinit▹random initializationGoal: X1∼pdata
其中 σt≥0\sigma_t \geq 0σt≥0为diffusion系数,WtW_tWt为随机过程 布朗运动(Brownian motion)
可以看出Diffusion Model是Flow Model的一个拓展,当σt=0\sigma_t = 0σt=0时即为Flow Model
同样的,可以使用以下算法实现从Diffusion Model中采样

Training Target and Train Loss
对于Flow Model和Diffusion Model
X0∼pinit,dXt=utθ(Xt)dt(Flow model)X0∼pinit,dXt=utθ(Xt)dt+σtdWt(Diffusion model) \begin{align*} X_0 \sim p_{\text{init}},\quad dX_t &= u_t^\theta(X_t) dt & \text{(Flow model)} \\ X_0 \sim p_{\text{init}},\quad dX_t &= u_t^\theta(X_t) dt + \sigma_t dW_t & \text{(Diffusion model)} \end{align*} X0∼pinit,dXtX0∼pinit,dXt=utθ(Xt)dt=utθ(Xt)dt+σtdWt(Flow model)(Diffusion model)
训练可以通过最小化以下损失实现
L(θ)=∥utθ(x)−uttarget(x)⏟training target∥2 \mathcal{L}(\theta) = \left\| u_t^\theta(x) - \underbrace{u_t^{\text{target}}(x)}_{\text{training target}} \right\|^2 L(θ)=
utθ(x)−training target
uttarget(x)
2
utθu_t^\thetautθ 为网络模型,uttarget(x)u_t^{\text{target}}(x)uttarget(x)为目标向量场,其实现将初始数据分布转化为目标数据分布,为了实现计算 L(θ)\mathcal{L}(\theta)L(θ) 或者间接计算 L(θ)\mathcal{L}(\theta)L(θ)需要构建uttarget(x)u_t^{\text{target}}(x)uttarget(x)。
Probability Path
Probability Path是从初始分布到目标数据分布的渐进插值(gradual interpolation),分为条件概率路径(conditional probability path)和边缘概率路径(marginal probability path),分别为pt(⋅∣z)p_t(\cdot \mid z)pt(⋅∣z) 和 pt(⋅)p_t(\cdot)pt(⋅),其中:
p0(⋅∣z)=pinit,p1(⋅∣z)=δzfor all z∈Rd p_0(\cdot \mid z) = p_{\text{init}}, \quad p_1(\cdot \mid z) = \delta_z \quad \text{for all } z \in \mathbb{R}^d p0(⋅∣z)=pinit,p1(⋅∣z)=δzfor all z∈Rd
pt(⋅)p_t(\cdot)pt(⋅) 可由以下公式获得
z∼pdata, x∼pt(⋅∣z) ⟹ x∼pt▹sampling from marginal pathpt(x)=∫pt(x∣z)pdata(z)dz▹density of marginal pathp0=pinitandp1=pdata▹noise-data interpolation \begin{align*} &z \sim p_{\text{data}},\ x \sim p_t(\cdot \mid z) \implies x \sim p_t &\triangleright \text{sampling from marginal path} \\ &p_t(x) = \int p_t(x \mid z) p_{\text{data}}(z)dz &\triangleright \text{density of marginal path} \\ &p_0 = p_{\text{init}} \quad \text{and} \quad p_1 = p_{\text{data}} &\triangleright \text{noise-data interpolation} \\ \end{align*} z∼pdata, x∼pt(⋅∣z)⟹x∼ptpt(x)=∫pt(x∣z)pdata(z)dzp0=pinitandp1=pdata▹sampling from marginal path▹density of marginal path▹noise-data interpolation
Training Target for Flow Model
对于z∈Rd∼pdataz \in \mathbb{R^d} \sim p_{data}z∈Rd∼pdata,记uttarget(⋅∣z)u_t^{target}(\cdot \mid z)uttarget(⋅∣z)为条件概率路径 pt(⋅∣z)p_t(\cdot \mid z)pt(⋅∣z) 对应的条件向量场,即
X0∼pinit,ddtXt=uttarget(Xt∣z)⇒Xt∼pt(⋅∣z)(0≤t≤1) X_0 \sim p_{\text{init}},\quad \frac{\mathrm{d}}{\mathrm{d}t}X_t = u_t^{\text{target}}(X_t|z) \quad \Rightarrow \quad X_t \sim p_t(\cdot|z) \quad (0 \leq t \leq 1) X0∼pinit,dtdXt=uttarget(Xt∣z)⇒Xt∼pt(⋅∣z)(0≤t≤1)
则uttarget(x)u_t^{target}(x)uttarget(x)可定义为
uttarget(x)=∫uttarget(x∣z)pt(x∣z)pdata(z)pt(x) dz u_t^{\text{target}}(x) = \int u_t^{\text{target}}(x|z) \frac{p_t(x|z)p_{\text{data}}(z)}{p_t(x)} \,\mathrm{d}z uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz
且满足:
X0∼pinit,ddtXt=uttarget(Xt)⇒Xt∼pt(0≤t≤1) X_0 \sim p_{\text{init}},\quad \frac{\mathrm{d}}{\mathrm{d}t}X_t = u_t^{\text{target}}(X_t) \quad \Rightarrow \quad X_t \sim p_t \quad (0 \leq t \leq 1) X0∼pinit,dtdXt=uttarget(Xt)⇒Xt∼pt(0≤t≤1)
其中X1∼pdataX_1 \sim p_{data}X1∼pdata。
这可以由Continuity Equation 证明
Continuity Equation
对于向量场uttargetu_t^{target}uttarget 且 X0∼pinitX_0 \sim p_{init}X0∼pinit,有Xt∼ptX_t \sim p_tXt∼pt 在0≤t≤10 \leq t \leq 10≤t≤1 成立有且仅有
∂tpt(x)=−div(ptuttarget)(x)for all x∈Rd,0≤t≤1 \partial_t p_t(x) = -\mathrm{div}(p_t u_t^{\text{target}})(x) \quad \text{for all } x \in \mathbb{R}^d, 0 \leq t \leq 1 ∂tpt(x)=−div(ptuttarget)(x)for all x∈Rd,0≤t≤1
其中∂tpt(x)=ddtpt(x)\partial_t p_t(x) = \frac{\mathrm{d}}{\mathrm{d}t} p_t(x)∂tpt(x)=dtdpt(x),div(vt)(x)=∑i=1d∂∂xivt(x)\mathrm{div}(v_t)(x) = \sum_{i=1}^d \frac{\partial}{\partial x_i} v_t(x)div(vt)(x)=∑i=1d∂xi∂vt(x)
Training Target for Diffusion Model
同样的,对于Diffusion Model,可以构建uttargetu_t^{target}uttarget如下所示,满足Xt∼pt(0≤t≤1)X_t \sim p_t \quad (0 \leq t \leq 1)Xt∼pt(0≤t≤1) ,即
X0∼pinit,dXt=[uttarget(Xt)+σt22∇logpt(Xt)]dt+σtdWt⇒Xt∼pt(0≤t≤1) \begin{align*} &X_0 \sim p_{\text{init}}, \quad \mathrm{d}X_t = \left[ u_t^{\text{target}}(X_t) + \frac{\sigma_t^2}{2} \nabla \log p_t(X_t) \right] \mathrm{d}t + \sigma_t \mathrm{d}W_t \\ &\Rightarrow X_t \sim p_t \quad (0 \leq t \leq 1) \end{align*} X0∼pinit,dXt=[uttarget(Xt)+2σt2∇logpt(Xt)]dt+σtdWt⇒Xt∼pt(0≤t≤1)
并且将pt(x),uttargetp_t(x), u_t^{target}pt(x),uttarget 替换为 pt(x∣z),uttarget(x∣z)p_t(x\mid z), u_t^{target}(x \mid z)pt(x∣z),uttarget(x∣z) 时仍然成立
其中,∇logpt(x)\nabla \log p_t(x)∇logpt(x) 称为marginal score function,∇logpt(x∣z)\nabla \log p_t(x \mid z)∇logpt(x∣z) 称为conditional score function,二者满足
∇logpt(x)=∇pt(x)pt(x)=∇∫pt(x∣z)pdata(z) dzpt(x)=∫∇pt(x∣z)pdata(z) dzpt(x)=∫∇logpt(x∣z)pt(x∣z)pdata(z)pt(x) dz \nabla \log p_t(x) = \frac{\nabla p_t(x)}{p_t(x)} = \frac{\nabla \int p_t(x|z) p_{\text{data}}(z) \,\mathrm{d}z}{p_t(x)} = \frac{\int \nabla p_t(x|z) p_{\text{data}}(z) \,\mathrm{d}z}{p_t(x)} = \int \nabla \log p_t(x|z) \frac{p_t(x|z) p_{\text{data}}(z)}{p_t(x)} \,\mathrm{d}z ∇logpt(x)=pt(x)∇pt(x)=pt(x)∇∫pt(x∣z)pdata(z)dz=pt(x)∫∇pt(x∣z)pdata(z)dz=∫∇logpt(x∣z)pt(x)pt(x∣z)pdata(z)dz
这可以由Fokker-Planck Equation证明
Fokker-Planck Equation
对于X0∼pinit,dXt=ut(Xt) dt+σt dWtX_0 \sim p_{\text{init}}, \quad \mathrm{d}X_t = u_t(X_t)\,\mathrm{d}t + \sigma_t\,\mathrm{d}W_tX0∼pinit,dXt=ut(Xt)dt+σtdWt 描述的SDE,Xt∼ptX_t \sim p_tXt∼pt 成立,当且仅当
∂tpt(x)=−div(ptut)(x)+σt22Δpt(x)for all x∈Rd,0≤t≤1 \partial_t p_t(x) = -\mathrm{div}(p_t u_t)(x) + \frac{\sigma_t^2}{2} \Delta p_t(x) \quad \text{for all } x \in \mathbb{R}^d, 0 \leq t \leq 1 ∂tpt(x)=−div(ptut)(x)+2σt2Δpt(x)for all x∈Rd,0≤t≤1
其中,Δwt(x)=∑i=1d∂2∂xi2wt(x)=div(∇wt)(x)\Delta w_t(x) = \sum_{i=1}^d \frac{\partial^2}{\partial x_i^2} w_t(x) = \mathrm{div}(\nabla w_t)(x)Δwt(x)=∑i=1d∂xi2∂2wt(x)=div(∇wt)(x)
Remark Langevin dynamics
当pt=pp_t=ppt=p时,即概率路径为静态时,有
dXt=σt22∇logp(Xt) dt+σt dWt \mathrm{d}X_t = \frac{\sigma_t^2}{2} \nabla \log p(X_t)\,\mathrm{d}t + \sigma_t\,\mathrm{d}W_t dXt=2σt2∇logp(Xt)dt+σtdWt
此时 X0∼p⇒Xt∼p(t≥0)X_0 \sim p \quad \Rightarrow \quad X_t \sim p \quad (t \geq 0)X0∼p⇒Xt∼p(t≥0),即Langevin dynamics
Gaussian probability path
设噪声调度αt,βt\alpha_t, \beta_tαt,βt为单调连续可微函数且α0=β1=0,α1=β0=1\alpha_0=\beta_1=0, \alpha_1=\beta_0=1α0=β1=0,α1=β0=1,定义Gaussian conditional probability path为
pt(⋅∣z)=N(αtz,βt2Id) p_t(\cdot|z) = \mathcal{N}(\alpha_t z, \beta_t^2 I_d) pt(⋅∣z)=N(αtz,βt2Id)
其满足 p0(⋅∣z)=N(α0z,β02Id)=N(0,Id),andp1(⋅∣z)=N(α1z,β12Id)=δzp_0(\cdot|z) = \mathcal{N}(\alpha_0 z, \beta_0^2 I_d) = \mathcal{N}(0, I_d), \quad \text{and} \quad p_1(\cdot|z) = \mathcal{N}(\alpha_1 z, \beta_1^2 I_d) = \delta_zp0(⋅∣z)=N(α0z,β02Id)=N(0,Id),andp1(⋅∣z)=N(α1z,β12Id)=δz
则从其marginal path中采样可以通过以下方法得到
z∼pdata, ϵ∼pinit=N(0,Id)⇒x=αtz+βtϵ∼pt z \sim p_{\text{data}},\ \epsilon \sim p_{\text{init}} = \mathcal{N}(0, I_d) \Rightarrow x = \alpha_t z + \beta_t \epsilon \sim p_t z∼pdata, ϵ∼pinit=N(0,Id)⇒x=αtz+βtϵ∼pt
基于Gaussian probability path的conditional Gaussian vector field可以计算得到
uttarget(x∣z)=(α˙t−β˙tβtαt)z+β˙tβtx u_t^{\text{target}}(x|z) = \left( \dot{\alpha}_t - \frac{\dot{\beta}_t}{\beta_t} \alpha_t \right) z + \frac{\dot{\beta}_t}{\beta_t} x uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
其中α˙t=∂tαt\dot{\alpha}_t = \partial_t \alpha_tα˙t=∂tαt,β˙t=∂tβt\dot{\beta}_t = \partial_t \beta_tβ˙t=∂tβt
同样的可以得到其marginal score function为
∇logpt(x∣z)=−x−αtzβt2 \nabla \log p_t(x|z) = -\frac{x - \alpha_t z}{\beta_t^2} ∇logpt(x∣z)=−βt2x−αtz
Flow Matching
对于Flow Model,定义flow matching loss为
LFM(θ)=Et∼Unif,x∼pt[∥utθ(x)−uttarget(x)∥2]=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥utθ(x)−uttarget(x)∥2] \begin{align*} \mathcal{L}_{\text{FM}}(\theta) &= \mathbb{E}_{t \sim \text{Unif}, x \sim p_t}[\|u_t^\theta(x) - u_t^{\text{target}}(x)\|^2] \\ &= \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, x \sim p_t(\cdot|z)}[\|u_t^\theta(x) - u_t^{\text{target}}(x)\|^2] \end{align*} LFM(θ)=Et∼Unif,x∼pt[∥utθ(x)−uttarget(x)∥2]=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥utθ(x)−uttarget(x)∥2]
z∼pdata, x∼pt(⋅∣z) ⟹ x∼ptz \sim p_{\text{data}},\ x \sim p_t(\cdot \mid z) \implies x \sim p_tz∼pdata, x∼pt(⋅∣z)⟹x∼pt
定义conditional flow matching loss为
LCFM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥utθ(x)−uttarget(x∣z)∥2] \mathcal{L}_{\text{CFM}}(\theta) = \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, x \sim p_t(\cdot|z)}[\|u_t^\theta(x) - u_t^{\text{target}}(x|z)\|^2] LCFM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥utθ(x)−uttarget(x∣z)∥2]
其中uttarget(x∣z)u_t^{\text{target}}(x|z)uttarget(x∣z)可以人为构造获得(例如Gaussian probability path)
可以证明,
LFM(θ)=LCFM(θ)+C \mathcal{L}_{\text{FM}}(\theta) = \mathcal{L}_{\text{CFM}}(\theta) + C LFM(θ)=LCFM(θ)+C
即
∇θLFM(θ)=∇θLCFM(θ) \nabla_\theta \mathcal{L}_{\text{FM}}(\theta) = \nabla_\theta \mathcal{L}_{\text{CFM}}(\theta) ∇θLFM(θ)=∇θLCFM(θ)
因此优化LCFM\mathcal{L}_{\text{CFM}}LCFM即优化LFM\mathcal{L}_{\text{FM}}LFM,而对于LCFM\mathcal{L}_{\text{CFM}}LCFM,只需构造probability path即可,至此可以得到训练Flow Model的算法,整个流程即称为Flow Matching
Flow Matching for Gaussian Conditional Probability Paths
对于Gaussian Probability Path,有
ϵ∼N(0,Id)⇒xt=αtz+βtϵ∼N(αtz,βt2Id)=pt(⋅∣z) \epsilon \sim \mathcal{N}(0, I_d) \quad \Rightarrow \quad x_t = \alpha_t z + \beta_t \epsilon \sim \mathcal{N}(\alpha_t z, \beta_t^2 I_d) = p_t(\cdot|z) ϵ∼N(0,Id)⇒xt=αtz+βtϵ∼N(αtz,βt2Id)=pt(⋅∣z)
uttarget(x∣z)=(α˙t−β˙tβtαt)z+β˙tβtx u_t^{\mathrm{target}}(x|z)=\left(\dot{\alpha}_t-\frac{\dot{\beta}_t}{\beta_t}\alpha_t\right)z+\frac{\dot{\beta}_t}{\beta_t}x uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
LCFM(θ)=Et∼Unif,z∼pdata,x∼N(αtz,βt2Id)[∥utθ(x)−(α˙t−β˙tβtαt)z−β˙tβtx∥2]=(i)Et∼Unif,z∼pdata,ϵ∼N(0,Id)[∥utθ(αtz+βtϵ)−(α˙tz+β˙tϵ)∥2] \begin{gathered} \mathcal{L}_{\mathrm{CFM}}(\theta)=\mathbb{E}_{t\sim\mathrm{Unif},z\sim p_{\mathrm{data}},x\sim\mathcal{N}(\alpha_{t}z,\beta_{t}^{2}I_{d})}[\|u_{t}^{\theta}(x)-\left(\dot{\alpha}_{t}-\frac{\dot{\beta}_{t}}{\beta_{t}}\alpha_{t}\right)z-\frac{\dot{\beta}_{t}}{\beta_{t}}x\|^{2}] \\ \overset{(i)}{\operatorname*{=}}\mathbb{E}_{t\sim\mathrm{Unif},z\sim p_{\mathrm{data}},\epsilon\sim\mathcal{N}(0,I_{d})}[\|u_{t}^{\theta}(\alpha_{t}z+\beta_{t}\epsilon)-(\dot{\alpha}_{t}z+\dot{\beta}_{t}\epsilon)\|^{2}] \end{gathered} LCFM(θ)=Et∼Unif,z∼pdata,x∼N(αtz,βt2Id)[∥utθ(x)−(α˙t−βtβ˙tαt)z−βtβ˙tx∥2]=(i)Et∼Unif,z∼pdata,ϵ∼N(0,Id)[∥utθ(αtz+βtϵ)−(α˙tz+β˙tϵ)∥2]
特别的,对于αt=t\alpha_t=tαt=t,βt=1−t\beta_t=1-tβt=1−t,有
pt(x∣z)=N(tz,(1−t)2) p_{t}(x|z)=\mathcal{N}(tz,(1-t)^{2}) pt(x∣z)=N(tz,(1−t)2)
Lcfm(θ)=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[∥utθ(tz+(1−t)ϵ)−(z−ϵ)∥2] \mathcal{L}_{\mathrm{cfm}}(\theta)=\mathbb{E}_{t\sim\mathrm{Unif},z\sim p_{\mathrm{data}},\epsilon\sim\mathcal{N}(0,I_{d})}[\|u_{t}^{\theta}(tz+(1-t)\epsilon)-(z-\epsilon)\|^{2}] Lcfm(θ)=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[∥utθ(tz+(1−t)ϵ)−(z−ϵ)∥2]
称之为(Gaussian) CondOT probability path,训练过程如下所示

Score Matching
对于Diffusion Models,由于uttargetu_t^{target}uttarget 难以得到,因此使用score network σt2:Rd×[0,1]→R\sigma_t^2 : \mathbb{R}^d \times [0, 1] \to \mathbb{R}σt2:Rd×[0,1]→R对score function进行拟合,同样的,存在score matching loss和conditional score matching loss如下
LSM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥stθ(x)−∇logpt(x)∥2]▹ score matching lossLCSM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥stθ(x)−∇logpt(x∣z)∥2]▹ conditional score matching loss \begin{align*} \mathcal{L}_{\text{SM}}(\theta) &= \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, x \sim p_t(\cdot|z)}[\|s_t^\theta(x) - \nabla \log p_t(x)\|^2] \quad \triangleright \text{ score matching loss} \\ \mathcal{L}_{\text{CSM}}(\theta) &= \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, x \sim p_t(\cdot|z)}[\|s_t^\theta(x) - \nabla \log p_t(x|z)\|^2] \quad \triangleright \text{ conditional score matching loss} \end{align*} LSM(θ)LCSM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥stθ(x)−∇logpt(x)∥2]▹ score matching loss=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥stθ(x)−∇logpt(x∣z)∥2]▹ conditional score matching loss
同样的,虽然∇logpt(x)\nabla \log p_t(x)∇logpt(x)未知,但∇logpt(x∣z)\nabla \log p_t(x \mid z)∇logpt(x∣z)可以人工构造,且存在
LSM(θ)=LSFM(θ)+C ⟹ ∇θLSM(θ)=∇θLCSM(θ) \begin{align*} &\mathcal{L}_{\text{SM}}(\theta) = \mathcal{L}_{\text{SFM}}(\theta) + C \\ &\implies \nabla_\theta \mathcal{L}_{\text{SM}}(\theta) = \nabla_\theta \mathcal{L}_{\text{CSM}}(\theta) \end{align*} LSM(θ)=LSFM(θ)+C⟹∇θLSM(θ)=∇θLCSM(θ)
因此,优化LCSM(θ)\mathcal{L}_{\text{CSM}}(\theta)LCSM(θ)即可,此时采样过程如下所示
X0∼pinit,dXt=[utθ(Xt)+σt22stθ(Xt)]dt+σtdWt ⟹ X1∼pdata X_0 \sim p_{\text{init}}, \quad \mathrm{d}X_t = \left[ u_t^\theta(X_t) + \frac{\sigma_t^2}{2} s_t^\theta(X_t) \right] \mathrm{d}t + \sigma_t \mathrm{d}W_t \implies X_1 \sim p_{data} X0∼pinit,dXt=[utθ(Xt)+2σt2stθ(Xt)]dt+σtdWt⟹X1∼pdata
其中,尽管理论上对任意σt≥0\sigma_t \geq 0σt≥0均可实现采样,但由于存在对随机微分方程模拟不精确导致的精度误差,以及训练误差,因此存在一个最优的σt\sigma_tσt。同时观察采样过程可以发现模拟该SDE还需学习utθu_t^\thetautθ,但其实通常可以使用一个两输出的网络同时处理utθu_t^\thetautθ和stθs_t^\thetastθ,并且对于特定的概率路径,两者可以相互转化。
Denoising Diffusion Models: Score Matching for Gaussian Probability Paths
对于Gaussian Probability Paths,有
∇logpt(x∣z)=−x−αtzβt2 \nabla \log p_t(x|z) = -\frac{x - \alpha_t z}{\beta_t^2} ∇logpt(x∣z)=−βt2x−αtz
则
LCSM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥stθ(x)+x−αtzβt2∥2]=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[∥stθ(αtz+βtϵ)+ϵβt∥2]=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[1βt2∥βtstθ(αtz+βtϵ)+ϵ∥2] \begin{align*} \mathcal{L}_{\text{CSM}}(\theta) &= \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, x \sim p_t(\cdot|z)}\left[\left\|s_t^\theta(x) + \frac{x - \alpha_t z}{\beta_t^2}\right\|^2\right] \\ &= \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, \epsilon \sim \mathcal{N}(0, I_d)}\left[\left\|s_t^\theta(\alpha_t z + \beta_t \epsilon) + \frac{\epsilon}{\beta_t}\right\|^2\right] \\ &= \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, \epsilon \sim \mathcal{N}(0, I_d)}\left[\frac{1}{\beta_t^2} \left\|\beta_t s_t^\theta(\alpha_t z + \beta_t \epsilon) + \epsilon\right\|^2\right] \end{align*} LCSM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[
stθ(x)+βt2x−αtz
2]=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[
stθ(αtz+βtϵ)+βtϵ
2]=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[βt21
βtstθ(αtz+βtϵ)+ϵ
2]
由于1βt2\frac{1}{\beta^2_t}βt21在βt\beta_tβt趋近于0时loss趋近于无穷大,因此通常舍弃常数项1βt2\frac{1}{\beta^2_t}βt21,并用以下方法reparameterize stθs^\theta_tstθ为ϵtθ\epsilon_t^\thetaϵtθ(噪声预测网络)得到DDPM损失函数
−βtstθ(x)=ϵtθ(x)⇒LDDPM(θ)=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[∥ϵtθ(αtz+βtϵ)−ϵ∥2] -\beta_t s_t^\theta(x) = \epsilon_t^\theta(x) \quad \Rightarrow \quad \mathcal{L}_{\text{DDPM}}(\theta) = \mathbb{E}_{t \sim \text{Unif}, z \sim p_{\text{data}}, \epsilon \sim \mathcal{N}(0, I_d)}\left[\left\|\epsilon_t^\theta(\alpha_t z + \beta_t \epsilon) - \epsilon\right\|^2\right] −βtstθ(x)=ϵtθ(x)⇒LDDPM(θ)=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[
ϵtθ(αtz+βtϵ)−ϵ
2]
其训练过程如下所示

此外,对于Gaussian Probability Paths,vector field和score可以相互转化,即
uttarget(x∣z)=(βt2α˙tαt−β˙tβt)∇logpt(x∣z)+α˙tαtxuttarget(x)=(βt2α˙tαt−β˙tβt)∇logpt(x)+α˙tαtx u_t^{\text{target}}(x|z) = \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) \nabla \log p_t(x|z) + \frac{\dot{\alpha}_t}{\alpha_t} x \\ u_t^{\text{target}}(x) = \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) \nabla \log p_t(x) + \frac{\dot{\alpha}_t}{\alpha_t} x uttarget(x∣z)=(βt2αtα˙t−β˙tβt)∇logpt(x∣z)+αtα˙txuttarget(x)=(βt2αtα˙t−β˙tβt)∇logpt(x)+αtα˙tx
proof
uttarget(x∣z)=(α˙t−β˙tβtαt)z+β˙tβtx=(i)(βt2α˙tαt−β˙tβt)(αtz−xβt2)+α˙tαtx=(βt2α˙tαt−β˙tβt)∇logpt(x∣z)+α˙tαtx u_t^{\text{target}}(x|z) = \left( \dot{\alpha}_t - \frac{\dot{\beta}_t}{\beta_t} \alpha_t \right) z + \frac{\dot{\beta}_t}{\beta_t} x \stackrel{(i)}{=} \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) \left( \frac{\alpha_t z - x}{\beta_t^2} \right) + \frac{\dot{\alpha}_t}{\alpha_t} x = \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) \nabla \log p_t(x|z) + \frac{\dot{\alpha}_t}{\alpha_t} x uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx=(i)(βt2αtα˙t−β˙tβt)(βt2αtz−x)+αtα˙tx=(βt2αtα˙t−β˙tβt)∇logpt(x∣z)+αtα˙txuttarget(x)=∫uttarget(x∣z)pt(x∣z)pdata(z)pt(x) dz=∫[(βt2α˙tαt−β˙tβt)∇logpt(x∣z)+α˙tαtx]pt(x∣z)pdata(z)pt(x) dz=(i)(βt2α˙tαt−β˙tβt)∇logpt(x)+α˙tαtx \begin{align*} u_t^{\text{target}}(x) &= \int u_t^{\text{target}}(x|z) \frac{p_t(x|z) p_{\text{data}}(z)}{p_t(x)} \,\mathrm{d}z \\ &= \int \left[ \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) \nabla \log p_t(x|z) + \frac{\dot{\alpha}_t}{\alpha_t} x \right] \frac{p_t(x|z) p_{\text{data}}(z)}{p_t(x)} \,\mathrm{d}z \\ &\stackrel{(i)}{=} \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) \nabla \log p_t(x) + \frac{\dot{\alpha}_t}{\alpha_t} x \end{align*} uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz=∫[(βt2αtα˙t−β˙tβt)∇logpt(x∣z)+αtα˙tx]pt(x)pt(x∣z)pdata(z)dz=(i)(βt2αtα˙t−β˙tβt)∇logpt(x)+αtα˙tx
utθu_t^\thetautθ和stθs^\theta_tstθ 也可以相互转化,有
utθ(x)=(βt2α˙tαt−β˙tβt)stθ(x)+α˙tαtx u_t^\theta(x) = \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t \right) s_t^\theta(x) + \frac{\dot{\alpha}_t}{\alpha_t} x utθ(x)=(βt2αtα˙t−β˙tβt)stθ(x)+αtα˙tx
stθ(x)=αtutθ(x)−α˙txβt2αt−αtβ˙tβt s_t^\theta(x) = \frac{\alpha_t u_t^\theta(x) - \dot{\alpha}_t x}{\beta_t^2 \alpha_t - \alpha_t \dot{\beta}_t \beta_t} stθ(x)=βt2αt−αtβ˙tβtαtutθ(x)−α˙tx
因此对于Gaussian probability paths来说,只需训练utθu_t^\thetautθ或stθs^\theta_tstθ 即可,且使用flow matching或者使用score matching的方法均可
最后,对于训练好的stθs_t^\thetastθ 从SDE中采样过程如下
X0∼pinit,dXt=[(βt2α˙tαt−β˙tβt+σt22)stθ(x)+α˙tαtx]dt+σtdWt ⟹ X1=pdata X_0 \sim p_{\text{init}}, \quad \mathrm{d}X_t = \left[ \left( \beta_t^2 \frac{\dot{\alpha}_t}{\alpha_t} - \dot{\beta}_t \beta_t + \frac{\sigma_t^2}{2} \right) s_t^\theta(x) + \frac{\dot{\alpha}_t}{\alpha_t} x \right] \mathrm{d}t + \sigma_t \mathrm{d}W_t \\ \implies X_1=p_{data} X0∼pinit,dXt=[(βt2αtα˙t−β˙tβt+2σt2)stθ(x)+αtα˙tx]dt+σtdWt⟹X1=pdata
Summary
总的来说,Flow Matching比Score Matching更简洁并且Flow Matching更具有拓展性,可以实现从一个任意初始分布pinitp_{init}pinit得到任意分布pdatap_{data}pdata,但是denoising diffusion models只适用于Gaussian initial distributions and Gaussian probability path。Flow Matching类似于Stochastic Interpolants。
Conditional (Guided) Generation
在给定条件下进行生成(generate an object conditioned on some additional information),称之为conditional generation,为了和conditional vector field区分多称为guided generation
用数学语言描述即,对于y∈Yy \in \mathcal{Y}y∈Y,对pdata(x∣y)p_{data}(x \mid y)pdata(x∣y)中采样,因此模型包含条件向量场utθ(⋅∣y)u_t^{\theta}(\cdot \mid y)utθ(⋅∣y),模型架构如下所示
Neural network: utθ:Rd×Y×[0,1]→Rd,(x,y,t)↦utθ(x∣y)Fixed: σt:[0,1]→[0,∞),t↦σt \begin{align*} \text{Neural network: } & u_t^\theta : \mathbb{R}^d \times \mathcal{Y} \times [0, 1] \to \mathbb{R}^d, \quad (x, y, t) \mapsto u_t^\theta(x|y) \\ \text{Fixed: } & \sigma_t : [0, 1] \to [0, \infty), \quad t \mapsto \sigma_t \end{align*} Neural network: Fixed: utθ:Rd×Y×[0,1]→Rd,(x,y,t)↦utθ(x∣y)σt:[0,1]→[0,∞),t↦σt
对于给定的y∈Rdyy \in \mathbb{R}^{d_y}y∈Rdy,采样过程可以描述为
Initialization:X0∼pinit▹ Initialize with simple distributionSimulation:dXt=utθ(Xt∣y) dt+σt dWt▹ Simulate SDE from t=0 to t=1.Goal:X1∼pdata(⋅∣y)▹X1 to be distributed like pdata(⋅∣y) \begin{align*} \text{Initialization:} \quad & X_0 \sim p_{\text{init}} \quad &\triangleright \text{ Initialize with simple distribution} \\ \text{Simulation:} \quad & \mathrm{d}X_t = u_t^\theta(X_t|y)\,\mathrm{d}t + \sigma_t\,\mathrm{d}W_t \quad &\triangleright \text{ Simulate SDE from } t=0 \text{ to } t=1. \\ \text{Goal:} \quad & X_1 \sim p_{\text{data}}(\cdot|y) \quad &\triangleright X_1 \text{ to be distributed like } p_{\text{data}}(\cdot|y) \end{align*} Initialization:Simulation:Goal:X0∼pinitdXt=utθ(Xt∣y)dt+σtdWtX1∼pdata(⋅∣y)▹ Initialize with simple distribution▹ Simulate SDE from t=0 to t=1.▹X1 to be distributed like pdata(⋅∣y)
上述在σt=0\sigma_t=0σt=0时即为guided flow model
Guided Models
Guided Flow Models的训练损失(优化目标,或者说guided conditional flow matching objective)很容的得到,如下所示
LCFMguided(θ)=E(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z)[∥utθ(x∣y)−uttarget(x∣z)∥2] \begin{align*} \mathcal{L}_{\text{CFM}}^{\text{guided}}(\theta) &= \mathbb{E}_{(z,y) \sim p_{\text{data}}(z,y),\, t \sim \text{Unif}(0,1),\, x \sim p_t(\cdot|z)} \left[ \left\| u_t^\theta(x|y) - u_t^{\text{target}}(x|z) \right\|^2 \right] \end{align*} LCFMguided(θ)=E(z,y)∼pdata(z,y),t∼Unif(0,1),x∼pt(⋅∣z)[
utθ(x∣y)−uttarget(x∣z)
2]
同样的,对于Guided Diffusion Models,有guided conditional score matching objective如下
LCSMguided(θ)=E□[∥stθ(x∣y)−∇logpt(x∣z)∥2]□=(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z) \begin{align*} \mathcal{L}_{\text{CSM}}^{\text{guided}}(\theta) &= \mathbb{E}_{\square} \left[ \| s_t^\theta(x|y) - \nabla \log p_t(x|z) \|^2 \right] \\ \square &= (z, y) \sim p_{\text{data}}(z, y),\ t \sim \text{Unif}(0,1),\ x \sim p_t(\cdot|z) \end{align*} LCSMguided(θ)□=E□[∥stθ(x∣y)−∇logpt(x∣z)∥2]=(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z)
虽然理论上上述以及足够生成标签yyy对应样本,但是实际上生成效果并不十分fit yyy,以及,无法控制生成内容对label的fit程度。一种解决方法是人为加强yyy的作用,比较先进的技术是Classifier-Free Guidance。
Classifier-Free Guidance
对于Flow Models,以Gaussian probability paths为例
uttarget(x∣y)=atx+bt∇logpt(x∣y) \begin{align*} u_t^{\text{target}}(x|y) = a_t x + b_t \nabla \log p_t(x|y) \end{align*} uttarget(x∣y)=atx+bt∇logpt(x∣y)
其中
(at,bt)=(α˙tαt,α˙tβt2−β˙tβtαtαt) \begin{align*} (a_t, b_t) = \left( \frac{\dot{\alpha}_t}{\alpha_t}, \frac{\dot{\alpha}_t \beta_t^2 - \dot{\beta}_t \beta_t \alpha_t}{\alpha_t} \right) \end{align*} (at,bt)=(αtα˙t,αtα˙tβt2−β˙tβtαt)
又
∇logpt(x∣y)=∇log(pt(x)pt(y∣x)pt(y))=∇logpt(x)+∇logpt(y∣x) \begin{align*} \nabla \log p_t(x|y) = \nabla \log \left( \frac{p_t(x) p_t(y|x)}{p_t(y)} \right) = \nabla \log p_t(x) + \nabla \log p_t(y|x) \end{align*} ∇logpt(x∣y)=∇log(pt(y)pt(x)pt(y∣x))=∇logpt(x)+∇logpt(y∣x)
则
uttarget(x∣y)=atx+bt(∇logpt(x)+∇logpt(y∣x))=uttarget(x)+bt∇logpt(y∣x) \begin{align*} u_t^{\text{target}}(x|y) = a_t x + b_t (\nabla \log p_t(x) + \nabla \log p_t(y|x)) = u_t^{\text{target}}(x) + b_t \nabla \log p_t(y|x) \end{align*} uttarget(x∣y)=atx+bt(∇logpt(x)+∇logpt(y∣x))=uttarget(x)+bt∇logpt(y∣x)
可以看出,guided vector field是由unguided vector field和guided score相加得到,一种很自然的想法是对guided score进行加权,得到
u~t(x∣y)=uttarget(x)+wbt∇logpt(y∣x) \begin{align*} \tilde{u}_t(x|y) = u_t^{\text{target}}(x) + wb_t \nabla \log p_t(y|x) \end{align*} u~t(x∣y)=uttarget(x)+wbt∇logpt(y∣x)
其中guided score可以看作是噪声类别分类器,早期的工作确实使用这样的方法实现,但是进一步对guided score进行分析得到如下:
u~t(x∣y)=uttarget(x)+wb∇logpt(y∣x)=uttarget(x)+wb(∇logpt(x∣y)−∇logpt(x))=uttarget(x)−(wax+wb∇logpt(x))+(wax+wb∇logpt(x∣y))=(1−w)uttarget(x)+wuttarget(x∣y). \begin{align*} \tilde{u}_t(x|y) &= u_t^{\text{target}}(x) + w_b \nabla \log p_t(y|x) \\ &= u_t^{\text{target}}(x) + w_b (\nabla \log p_t(x|y) - \nabla \log p_t(x)) \\ &= u_t^{\text{target}}(x) - (w_a x + w_b \nabla \log p_t(x)) + (w_a x + w_b \nabla \log p_t(x|y)) \\ &= (1 - w) u_t^{\text{target}}(x) + w u_t^{\text{target}}(x|y). \end{align*} u~t(x∣y)=uttarget(x)+wb∇logpt(y∣x)=uttarget(x)+wb(∇logpt(x∣y)−∇logpt(x))=uttarget(x)−(wax+wb∇logpt(x))+(wax+wb∇logpt(x∣y))=(1−w)uttarget(x)+wuttarget(x∣y).
即u~t(x∣y)\tilde{u}_t(x|y)u~t(x∣y)由unguided vector field和guided vector field加权得到,并且,通过构造y=∅y = \varnothingy=∅其对应概率为人为设计的超参数η\etaη,从而实现使用uttarget(x∣∅)u_t^{\text{target}}(x|\varnothing)uttarget(x∣∅)代替uttarget(x)u_t^{\text{target}}(x)uttarget(x),具体可公式化描述为
LCFMCFG(θ)=E□[∥utθ(x∣y)−uttarget(x∣z)∥2]□=(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z), replace y=∅ with prob. η \begin{align*} \mathcal{L}_{\text{CFM}}^{\text{CFG}}(\theta) &= \mathbb{E}_{\square} \left[ \| u_t^\theta(x|y) - u_t^{\text{target}}(x|z) \|^2 \right] \\ \square &= (z, y) \sim p_{\text{data}}(z, y),\ t \sim \text{Unif}(0,1),\ x \sim p_t(\cdot|z),\ \text{replace } y = \varnothing \text{ with prob. } \eta \end{align*} LCFMCFG(θ)□=E□[∥utθ(x∣y)−uttarget(x∣z)∥2]=(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z), replace y=∅ with prob. η
对于Diffusion Models,s~t(x∣y)\tilde{s}_t(x|y)s~t(x∣y)同样可改写如下
s~t(x∣y)=∇logpt(x)+w∇logpt(y∣x)=∇logpt(x)+w(∇logpt(x∣y)−∇logpt(x))=(1−w)∇logpt(x)+w∇logpt(x∣y)=(1−w)∇logpt(x∣∅)+w∇logpt(x∣y) \begin{align*} \tilde{s}_t(x|y) &= \nabla \log p_t(x) + w \nabla \log p_t(y|x) \\ &= \nabla \log p_t(x) + w (\nabla \log p_t(x|y) - \nabla \log p_t(x)) \\ &= (1 - w) \nabla \log p_t(x) + w \nabla \log p_t(x|y) \\ &= (1 - w) \nabla \log p_t(x|\varnothing) + w \nabla \log p_t(x|y) \end{align*} s~t(x∣y)=∇logpt(x)+w∇logpt(y∣x)=∇logpt(x)+w(∇logpt(x∣y)−∇logpt(x))=(1−w)∇logpt(x)+w∇logpt(x∣y)=(1−w)∇logpt(x∣∅)+w∇logpt(x∣y)
training objective如下
LCSMCFG(θ)=E□[∥stθ(x∣(1−ξ)y+ξ∅)−∇logpt(x∣z)∥2]□=(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z), replace y=∅ with prob. η \begin{align*} \mathcal{L}_{\text{CSM}}^{\text{CFG}}(\theta) &= \mathbb{E}_{\square} \left[ \| s_t^\theta(x|(1 - \xi)y + \xi \varnothing) - \nabla \log p_t(x|z) \|^2 \right] \\ \square &= (z, y) \sim p_{\text{data}}(z, y),\ t \sim \text{Unif}(0,1),\ x \sim p_t(\cdot|z),\ \text{replace } y = \varnothing \text{ with prob. } \eta \end{align*} LCSMCFG(θ)□=E□[∥stθ(x∣(1−ξ)y+ξ∅)−∇logpt(x∣z)∥2]=(z,y)∼pdata(z,y), t∼Unif(0,1), x∼pt(⋅∣z), replace y=∅ with prob. η
训练时,我们通常也可同时优化stθ(x∣y){s}_t^\theta(x|y)stθ(x∣y)和utθ(x∣y){u}_t^\theta(x|y)utθ(x∣y),对应的,有
s~tθ(x∣y)=(1−w)stθ(x∣∅)+wstθ(x∣y),u~tθ(x∣y)=(1−w)utθ(x∣∅)+wutθ(x∣y). \begin{align*} \tilde{s}_t^\theta(x|y) &= (1 - w) s_t^\theta(x|\varnothing) + w s_t^\theta(x|y), \\ \tilde{u}_t^\theta(x|y) &= (1 - w) u_t^\theta(x|\varnothing) + w u_t^\theta(x|y). \end{align*} s~tθ(x∣y)u~tθ(x∣y)=(1−w)stθ(x∣∅)+wstθ(x∣y),=(1−w)utθ(x∣∅)+wutθ(x∣y).
采样时,有
dXt=[u~tθ(Xt∣y)+σt22stθ(Xt∣y)]dt+σtdWt \mathrm{d}X_t = \left[ \tilde{u}_t^\theta(X_t|y) + \frac{\sigma_t^2}{2} s_t^\theta(X_t|y) \right] \mathrm{d}t + \sigma_t \mathrm{d}W_t dXt=[u~tθ(Xt∣y)+2σt2stθ(Xt∣y)]dt+σtdWt
Network architectures
网络模型的设计随建模数据的复杂程度各有差别,但都需满足
Neural network: utθ:Rd×Y×[0,1]→Rd,(x,y,t)↦utθ(x∣y) \text{Neural network: } u_t^\theta : \mathbb{R}^d \times \mathcal{Y} \times [0, 1] \to \mathbb{R}^d, \quad (x, y, t) \mapsto u_t^\theta(x|y) Neural network: utθ:Rd×Y×[0,1]→Rd,(x,y,t)↦utθ(x∣y)
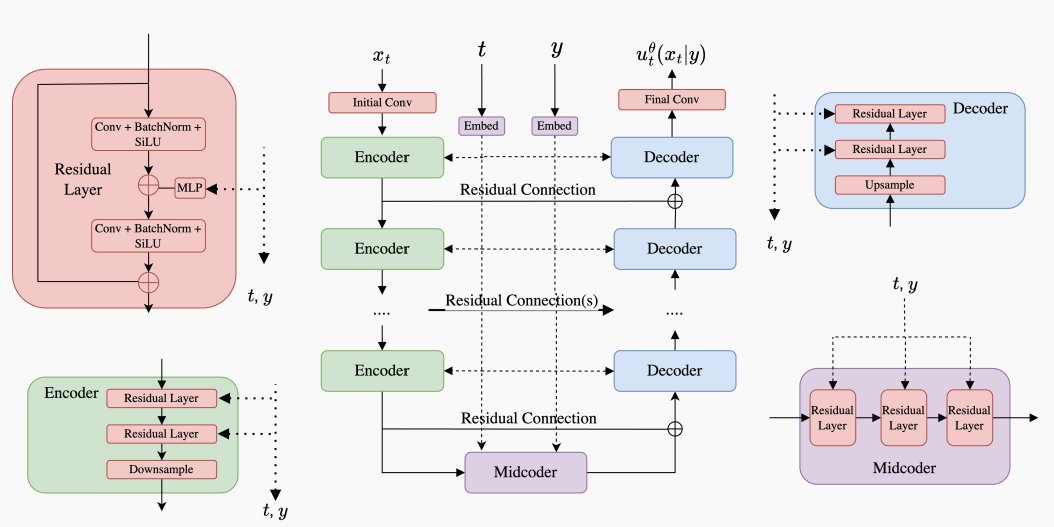
U-Nets
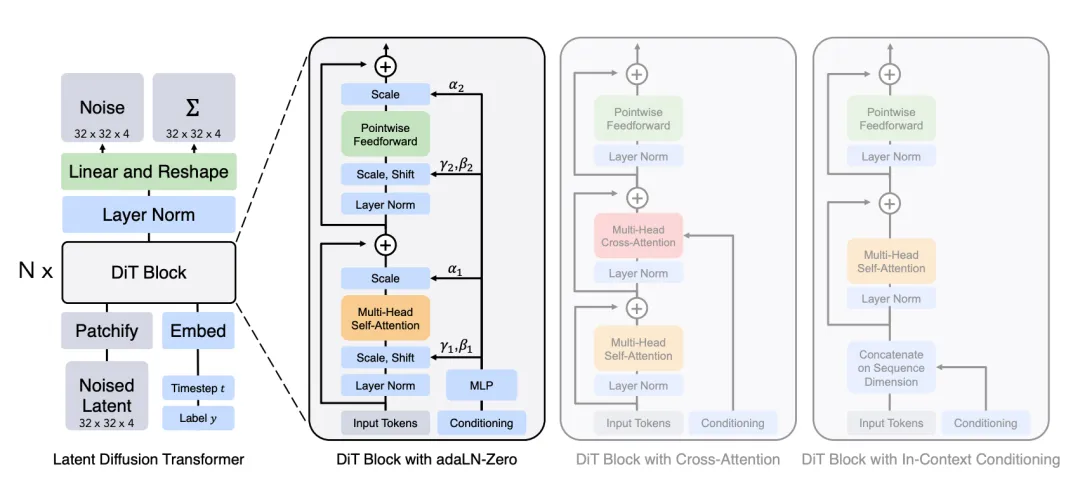
Diffusion Transformers
References
[1] Peter Holderrieth and Ezra Erives.An Introduction to Flow Matching and Diffusion Models[EB/OL].https://arxiv.org/abs/2506.02070,2025.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)