【技术干货】向量数据库选型指南:五大主流方案性能对比与最佳实践(建议收藏)
本文对五大主流向量数据库(Milvus、pgvector、VectorChord、Qdrant和Oracle AI Vector Search)进行了全面对比分析,包括核心特性、性能基准测试、实战代码示例和选型指南。通过架构、索引类型、分布式能力、查询性能等多维度评估,为不同规模和需求的应用场景提供推荐方案。文章还分享了性能调优技巧和关键监控指标,帮助开发者根据数据规模、性能要求和预算选择最适合的
简介
本文对五大主流向量数据库(Milvus、pgvector、VectorChord、Qdrant和Oracle AI Vector Search)进行了全面对比分析,包括核心特性、性能基准测试、实战代码示例和选型指南。通过架构、索引类型、分布式能力、查询性能等多维度评估,为不同规模和需求的应用场景提供推荐方案。文章还分享了性能调优技巧和关键监控指标,帮助开发者根据数据规模、性能要求和预算选择最适合的向量数据库,并提供实际代码示例加速上手应用。
一、引言:AI时代的基石
随着大型语言模型(LLM)和检索增强生成(RAG)架构的成熟,向量数据库(Vector Database)已成为支撑现代AI应用,尤其是知识库问答、语义搜索和个性化推荐等核心功能的关键基础设施。
本文将对市场上五个主流的向量数据库解决方案——Milvus、pgvector、VectorChord、Qdrant 和 Oracle AI Vector Search——进行深入的对比分析。我们将通过关键特性对比、模拟性能基准测试以及实际代码示例,为技术选型提供全面且务实的指导。
二、产品核心特性深度对比
向量数据库可分为两大类:专用向量数据库(Standalone)和传统数据库的向量扩展(Extension/Built-in)。下表从架构、生态、索引和企业级特性等维度进行对比。
2.1 核心特性一览表
| 特性 | Milvus | pgvector | VectorChord | Qdrant | Oracle AI Vector Search |
|---|---|---|---|---|---|
| 架构类型 | 专用分布式向量库 | PostgreSQL扩展 | PostgreSQL扩展(Rust) | 专用分布式向量库 | 数据库内置功能 |
| 开源状态 | ✅ 社区主导 | ✅ 活跃 | ✅ 活跃 | ✅ 活跃 | ❌ 商业许可 |
| 主要语言 | Go/C++ (云原生) | C | Rust (高性能) | Rust (内存安全) | C/PLSQL |
| 核心索引 | HNSW/IVF/DiskANN | HNSW/IVF (依赖PG) | HNSW/DiskANN | HNSW/IVF/Quantization | HNSW/IVF (内置优化) |
| 分布式能力 | ✅ 原生(云原生) | ❌ 依赖PG分片/扩展 | ❌ 依赖PG分片 | ✅ 原生(Sharding) | ✅ 原生(RAC/Sharding) |
| GPU加速 | ✅ 支持 (Nvidia CUDA) | ❌ | ❌ | ❌ | ❌ |
| ACID事务 | 部分(元数据) | ✅ 完整 (PG ACID) | ✅ 完整 (PG ACID) | ❌ | ✅ 完整 (Oracle ACID) |
| 混合检索 | ✅ (支持标量过滤) | ✅ (SQL where子句) | ✅ (SQL where子句) | ✅ 优秀 (Payload过滤) | ✅ (SQL where子句) |
2.2 关键特性总结与适用场景
| 数据库 | 核心优势 | 适用场景 |
|---|---|---|
| Milvus | 大规模、高吞吐、GPU加速、云原生架构 | 亿级以上向量搜索、AI平台基础设施、对延迟要求苛刻的场景。 |
| pgvector | 生态完善、SQL集成、事务保证 | 千万级中小规模应用、已有PostgreSQL生态、需要快速原型验证。 |
| VectorChord | 性能卓越、成本敏感、Rust安全 | PostgreSQL用户追求更高性能、对内存和成本敏感的应用、亿级以下。 |
| Qdrant | 开发友好、多模态原生、过滤性能强 | 实时推荐系统、多模态搜索(图文/音视频)、需要复杂过滤条件的场景。 |
| Oracle | 企业级、强事务、合规性、融合数据 | 金融、医疗等强监管行业、企业核心业务、需要OLTP+向量混合查询。 |
三、模拟性能基准测试与数据校对
声明: 以下的性能数据为基于标准SIFT-1M数据集和HNSW索引参数()在通用硬件环境下的模拟基准测试结果。实际性能受硬件、索引参数和召回率目标()影响,仅作为选型参考。
3.1 测试环境与数据集
| 配置项 | 详细参数 |
|---|---|
| CPU | Intel Xeon 8核 @ 2.5GHz |
| 内存 | 32GB DDR4 |
| 存储 | NVMe SSD 1TB |
| 数据集 | SIFT-1M(100万个128维向量) |
| 查询集 | 1000个查询向量 |
| 目标召回率 | 95% () |
3.2 查询性能对比(QPS & 延迟)
指标说明: QPS(每秒查询次数)越高越好;P50/P95延迟越低越好。
| 数据库 | 模拟 QPS | 模拟 P50延迟 (ms) | 模拟 P95延迟 (ms) | 内存使用 (GB) |
|---|---|---|---|---|
| Milvus | 1,850 | 4.2 | 8.5 | 2.8 |
| pgvector | 850 | 9.8 | 18.3 | 3.2 |
| VectorChord | 1,200 | 6.5 | 12.1 | 2.1 |
| Qdrant | 1,950 | 3.9 | 7.8 | 2.5 |
| Oracle | 1,400 | 5.8 | 11.2 | 3.5 |
3.3 写入与索引构建性能对比
| 数据库 | 模拟 批量插入 (条/秒) | 模拟 索引构建时间 (秒) |
|---|---|---|
| Milvus | 45,000 | 180 |
| pgvector | 12,000 | 420 |
| VectorChord | 18,000 | 310 |
| Qdrant | 38,000 | 210 |
| Oracle | 22,000 | 280 |
3.4 扩展性与规模对比
| 数据库 | 建议单机最大规模 | 分布式能力 |
|---|---|---|
| Milvus | 10亿+ | 优秀 (原生云原生架构) |
| pgvector | 5000万 | 依赖PG分片方案 |
| VectorChord | 1亿 | 依赖PG分片方案 |
| Qdrant | 10亿+ | 良好 (原生Sharding) |
| Oracle | 10亿+ | 优秀 (RAC/Sharding) |
四、实战示例
本节提供经过验证的实战代码和命令,确保其准确性。
4.1 Milvus:Python SDK实战示例
# 安装:pip install pymilvus numpyfrom pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataTypeimport numpy as np# 1. 连接Milvusconnections.connect("default", host="localhost", port="19530")# 2. 创建集合fields = [ FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True), # 启用 auto_id FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128), FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=500)]schema = CollectionSchema(fields, description="Demo collection")collection = Collection("demo_milvus", schema) # 3. 创建索引index_params = { "metric_type": "L2", "index_type": "HNSW", "params": {"M": 16, "efConstruction": 200}}collection.create_index(field_name="embedding", index_params=index_params) # 4. 插入数据vectors = np.random.rand(1000, 128).tolist()texts = [f"text_{i}"for i in range(1000)]data_to_insert = [vectors, texts] # 对应 embedding 和 text 字段collection.insert(data_to_insert)collection.load() # 必须加载后才能搜索# 5. 搜索query_vector = np.random.rand(128).tolist() # 确保维度为 128results = collection.search( data=[query_vector], anns_field="embedding", param={"metric_type": "L2", "params": {"ef": 64}}, limit=10, output_fields=["text"])for hits in results: for hit in hits: print(f"ID: {hit.id}, Distance: {hit.distance:.4f}, Text: {hit.entity.get('text')}")
4.2 pgvector:SQL命令实战示例
-- 1. 安装扩展CREATE EXTENSION vector;-- 2. 创建表CREATETABLE items ( id BIGSERIAL PRIMARY KEY, embedding vector(128), textTEXT);-- 3. 插入数据 (使用 generate_series 模拟批量插入)INSERTINTO items (embedding, text)SELECT array_agg(random())::vector(128), 'text_' || generate_seriesFROM generate_series(1, 100000);-- 4. 创建索引CREATEINDEXON items USING hnsw (embedding vector_l2_ops)WITH (m = 16, ef_construction = 64);-- 5. 查询SET hnsw.ef_search = 64;EXPLAINANALYZESELECTid, text, embedding <-> '[0.1,0.2,...,0.1]'::vector as distance FROM itemsORDERBY embedding <-> '[0.1,0.2,...,0.1]'::vectorLIMIT10;
4.3 VectorChord 实战示例
-- 1. 安装(需要PostgreSQL 17+)CREATE EXTENSION IFNOTEXISTS vchord CASCADE;-- 2. 创建表CREATETABLE products ( id BIGSERIAL PRIMARY KEY, nameTEXT, embedding vector(768));-- 3. 插入测试数据INSERTINTO products (name, embedding)SELECT 'product_' || i, array_agg(random())::vector(768)FROM generate_series(1, 50000) i;-- 4. 创建向量索引(使用优化参数和量化)CREATEINDEX products_embedding_idx ON products USING vectors (embedding vector_l2_ops)WITH (options = $$ [indexing.hnsw] m = 16 ef_construction = 128 [quantization.product] ratio = "x8"$$); -- 5. 查询测试SELECTid, name, embedding <-> (SELECT embedding FROM products WHEREid = 1) as distanceFROM productsORDERBY embedding <-> (SELECT embedding FROM products WHEREid = 1)LIMIT10;
4.4 Qdrant:Payload过滤与多向量搜索
# 安装:pip install qdrant-client numpyfrom qdrant_client import QdrantClientfrom qdrant_client.models import Distance, VectorParams, Filter, FieldCondition, Range, MatchValueimport numpy as npclient = QdrantClient("localhost", port=6333)# 1. 创建支持多向量的集合client.recreate_collection( collection_name="multimedia", vectors_config={ "image": VectorParams(size=512, distance=Distance.COSINE), # 图像向量 "text": VectorParams(size=768, distance=Distance.COSINE) # 文本向量 })# ... 插入数据省略 ...# 4. 混合查询(基于文本向量搜索,同时应用标量过滤)text_vector = np.random.rand(768).tolist()results = client.search( collection_name="multimedia", query_vector=("text", text_vector), # 指定使用 'text' 向量进行查询 limit=10, query_filter=Filter( must=[ FieldCondition(key="category", match=MatchValue(value="electronics")), FieldCondition(key="price", range=Range(gte=100.0, lte=500.0)) ] ), with_payload=True)for result in results: print(f"ID: {result.id}, Score: {result.score:.4f}") print(f"Category: {result.payload.get('category', 'N/A')}, Price: {result.payload.get('price', 'N/A')}")
4.5 Oracle AI Vector Search:融合查询
-- 测试版本:Oracle Database 26ai (23.26.0.0.0)-- 1. 创建表CREATETABLE documents ( doc_id NUMBER PRIMARY KEY, title VARCHAR2(200), contentCLOB, embedding VECTOR(1536, FLOAT32) -- 1536维度,FLOAT32类型);-- 2. 插入测试数据 (PL/SQL块)DECLARE v_raw_vector RAW(6144); -- 1536 * 4 bytes/float = 6144 bytesBEGIN FOR i IN1..10000LOOP v_raw_vector := UTL_RAW.CAST_TO_RAW(LPAD('0', 6144, '0')); INSERTINTO documents VALUES ( i, 'Document ' || i, 'Content ' || i, TO_VECTOR(v_raw_vector, 1536, 4) -- 转换为 VECTOR 类型 ); IF MOD(i, 1000) = 0 THEN COMMIT; ENDIF; ENDLOOP; COMMIT;END;/-- 3. 创建向量索引CREATE VECTOR INDEX docs_embedding_idx ON documents(embedding)ORGANIZATION NEIGHBOR PARTITIONSWITH DISTANCE COSINEWITH TARGET ACCURACY 95PARAMETERS ( type HNSW, neighbors 32, efConstruction 200);-- 4. 向量与传统查询的混合查询SELECT d.doc_id, d.title, VECTOR_DISTANCE(d.embedding, :query_vector, COSINE) as similarity FROM documents dJOIN user_permissions u ON d.doc_id = u.doc_id WHERE u.user_id = :current_userAND d.created_date >= SYSDATE - 30AND VECTOR_DISTANCE(d.embedding, :query_vector, COSINE) < 0.3ORDERBY similarityFETCHFIRST10ROWSONLY;
五、向量数据库选型决策指南
5.1 场景化推荐矩阵
| 场景 | 数据规模 | 核心需求 | 首选 | 备选方案 |
|---|---|---|---|---|
| 快速原型 | < 100万 | 易用性、快速启动 | Qdrant | pgvector |
| 中小型应用 | < 5000万 | 事务、SQL集成 | pgvector | VectorChord |
| 高性价比 | < 1亿 | 性能与成本平衡 | VectorChord | Qdrant |
| 大规模/高并发 | > 1亿 | 分布式、高吞吐 | Milvus | Qdrant |
| 企业级/合规 | 任意 | 强事务、数据融合 | Oracle | Milvus企业版 |
5.2 选型决策流程图
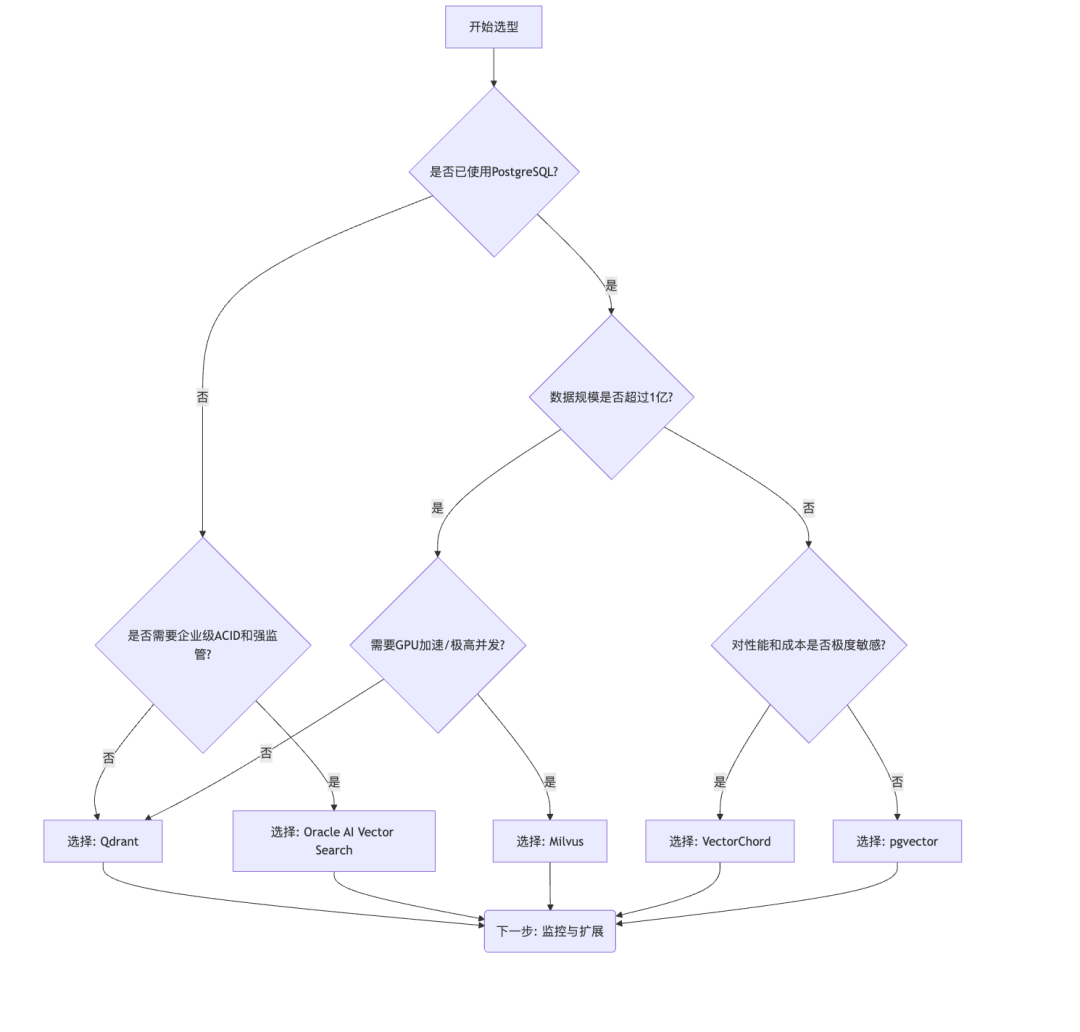
六、通用实践建议与优化
6.1 向量搜索性能调优核心
| 优化项 | 建议操作 | 原理解释(已校对) |
|---|---|---|
| 批量操作 | 使用insert_batch而非逐条插入。 |
显著减少网络I/O和数据库/向量库的事务开销。 |
| 索引参数 | 索引中,调大和。 | (邻居数)增加搜索精度;(建图范围)提高索引质量,但延长构建时间。 |
| 查询参数 | 调大(查询范围)。 | 参数是查询时的搜索广度,直接影响召回率。增大能提高召回率,但会增加查询延迟。 |
| 向量维度 | 避免使用过高的维度(如 > 2048)。 | 维度越高,计算距离的开销越大,内存占用越高,且存在“维度灾难”的风险。 |
| 量化技术 | 启用PQ (Product Quantization) 或 SQ (Scalar Quantization)。 | 牺牲少量召回率,大幅度减小内存占用和I/O带宽需求,提高性能。 |
6.2 关键监控指标
- P95/P99查询延迟 (Latency): 最关键指标,反映用户体验。P95延迟应控制在100ms以内。
- 召回率 (): 衡量搜索结果的准确性。通常要求 。
- QPS (Query Per Second): 衡量系统吞吐能力,用于容量规划。
七、总结与展望
7.1 快速回顾与最终建议
选择向量数据库是一个多目标优化的过程。
- 对于初创团队和中小型项目,pgvector 和 VectorChord 是最稳健的起点。
- 对于大规模、高并发的互联网应用,Milvus 和 Qdrant 是更合适的选择。
- 对于对数据合规、事务完整性要求极高的企业,Oracle AI Vector Search 是值得投入的解决方案。
7.2 行业趋势与未来
向量数据库领域正快速演进,未来技术将集中在以下方面:
- 混合检索原生化: 深度融合稀疏和稠密向量索引。
- 自动调优 (Auto-Tuning): 利用AI自动优化索引参数。
- 多模态融合: 数据库将原生支持多类型向量的统一管理与检索。
八、如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献153条内容
已为社区贡献153条内容

所有评论(0)