【上下文工程】真正工程级别的上下文工程是什么样的?来看看 Manus 的上下文工程哲学与实践
Manus联合创始人Peak的访谈精华,主要讲了Manus在实际生产级项目中使用的上下文工程技巧。如何通过上下文缩减、分层动作空间、上下文隔离等技术,构建高效、智能的 AI Agent。
今年10月4日,LangChain 的创始工程师之一 Lance 与 Manus 的联合创始人兼首席科学家 Peak 展开了一场访谈播客:Context Engineering for AI Agents with LangChain and Manus。
这场对话含金量极高,不仅涵盖了 LangChain 对当前 Agent 开发痛点的观察,更核心的是 Manus 联合创始人 Peak 毫无保留地分享了他们生产环境中的独家秘籍。
Manus 作为目前顶尖的智能体产品,其处理超长上下文、复杂任务规划以及工具调用的方式,代表了当前 AI 工程化的前沿水平。更难能可贵的是,他们非常乐于分享自己在构建Manus中总结出的经验教训,而这些结论通常是需要大量烧钱实验才能得出的。所以,有人也把Manus叫做Agent工程届的DeepSeek。
笔者将整场博客的一些核心思路与原则做了总结,希望与大家一起分享。
Manus 的上下文工程(Context Engineering)哲学与实践
核心哲学:为什么选择上下文工程而非微调?
在深入技术细节前,Peak 首先确立了 Manus 的技术路线选择。这是一个战略层面的最佳实践:
-
拒绝过早微调:
- 痛苦的教训: Peak 分享了创业早期的教训,过早训练自有模型会导致产品迭代受限于模型训练周期(通常 1-2 周),且容易陷入刷榜而非解决用户痛点的陷阱。
- MCP 的冲击: 随着 MCP(Model Context Protocol)的出现,Agent 的动作空间(Action Space)从封闭变为无限开放。在非固定动作空间下,强化学习和微调极难设计奖励函数,且难以泛化。
- 结论: 上下文工程是应用层与模型层之间最清晰、最实用的边界。 创业公司应尽可能利用通用强模型,通过上下文工程解决问题,而非试图重建 OpenAI 已经做好的基础层。
-
少点人为约束,多点自主智能(Less structure, more intelligence):
- Manus 经历了 5 次重构,最大的性能飞跃往往来自于做减法——移除不必要的复杂层,更多地信任模型本身的能力。
一、 上下文缩减(Context Reduction):压缩的艺术
Manus 提出了一种精细化的上下文管理策略,将缩减分为Compaction(紧凑化)和Summarization(摘要化)两个阶段。
1. Compaction(紧凑化):可逆的信息折叠
这是 Manus 处理上下文的第一道防线,原则是不丢失信息,只卸载主体。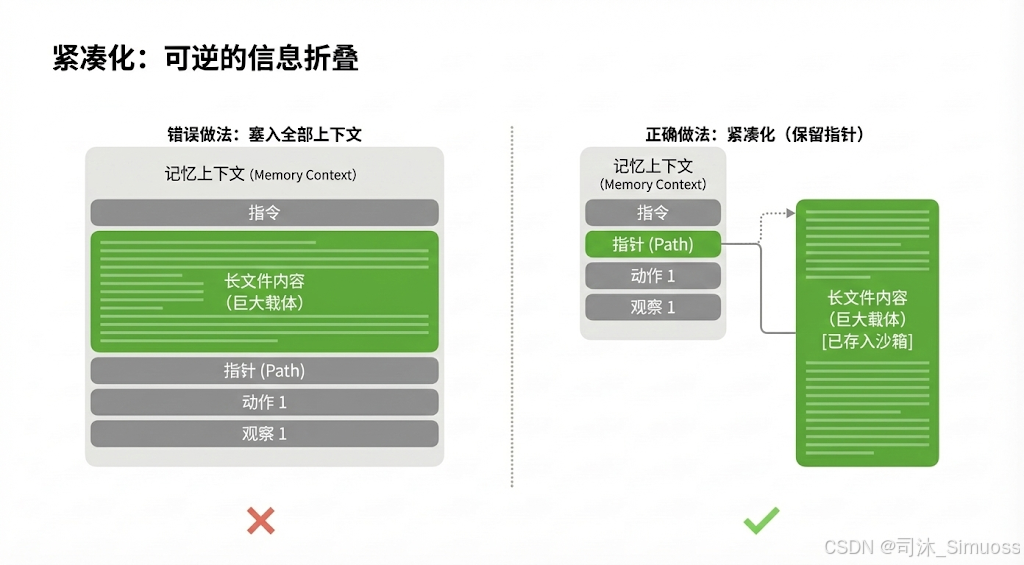
- 机制: 将工具调用(Tool Call)及其结果(Tool Result)中的冗余信息剥离,只保留“引用”。
-
笔者按:大多数Agent框架与论文一般将大模型自己写出的工具执行的步骤称为Tool Call或Action,将工具执行后输出的结果叫做Tool Result或Observation。
- 案例: 当 Agent 写入一个文件时,原始消息包含
path和巨大的content。但在返回结果后,文件已存在于沙箱文件系统中。 - 操作: 将历史消息中的
content字段删除,仅保留path。
- 案例: 当 Agent 写入一个文件时,原始消息包含
- 优势:
- 可恢复: 如果 Agent 未来需要该信息,可以通过
path再次读取。 - 保持连贯: 避免了因摘要导致的细节丢失,支持 Agent 进行基于历史行为的链式推理。
- 可恢复: 如果 Agent 未来需要该信息,可以通过
2. Summarization(摘要化):不可逆的信息有损压缩
当 Compaction 仍不足以应对 Context Window 限制时,才会触发摘要。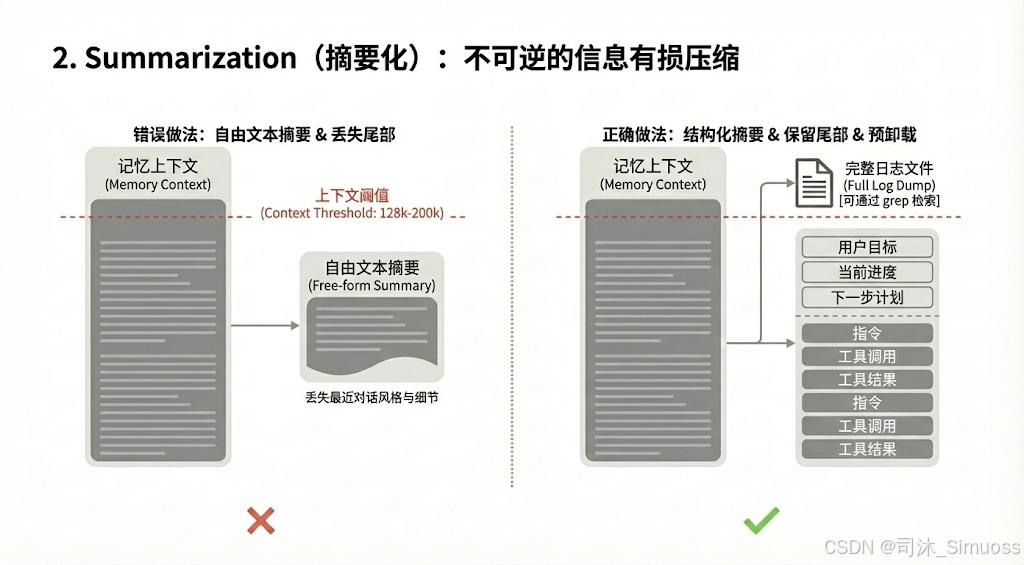
- 触发阈值
- 尽管模型宣称支持 1M 上下文,但性能通常在 128k - 200k 左右就开始退化(Context Rot)。Manus 将此区间设为触发缩减的红线。
- 最佳实践:
- 结构化摘要: 严禁让 AI 随意总结出不带结构限制的摘要。必须定义 Schema(一个预设好的结构),强制 AI 填写“用户目标”、“当前进度”、“下一步计划”等字段,确保关键信息不丢失。
-
笔者按:如果你有使用过国产AI IDE Trae,你可能会对这种结构化摘要有印象。当用户手动触发上下文压缩,或Agent内部因为上下文过长而触发上下文压缩时,其压缩窗口滚动显示的压缩进度就是结构化的,包含本轮行动和观察。事实上,许多优秀的AI工具中都能发现或是学到各种各样的Agent构建技巧。
- 保留上下文首尾部不压缩: 在摘要历史的同时,必须保留最后几轮完整的工具调用和结果。
- 原因: 保持 Few-shot(少样本)效应。如果全部摘要,模型会丢失当前的说话风格和工具使用格式,导致后续输出质量下降。
- 预卸载: 在摘要前,将即将被压缩的完整上下文 Dump 到日志文件中。Agent 甚至可以通过 Grep/Glob 检索这些旧日志。
二、 上下文卸载与分层动作空间
这是 Manus 最具创新性的架构设计。为了解决工具过多导致模型困惑(Context Confusion)的问题,Manus 设计了三层抽象的动作空间。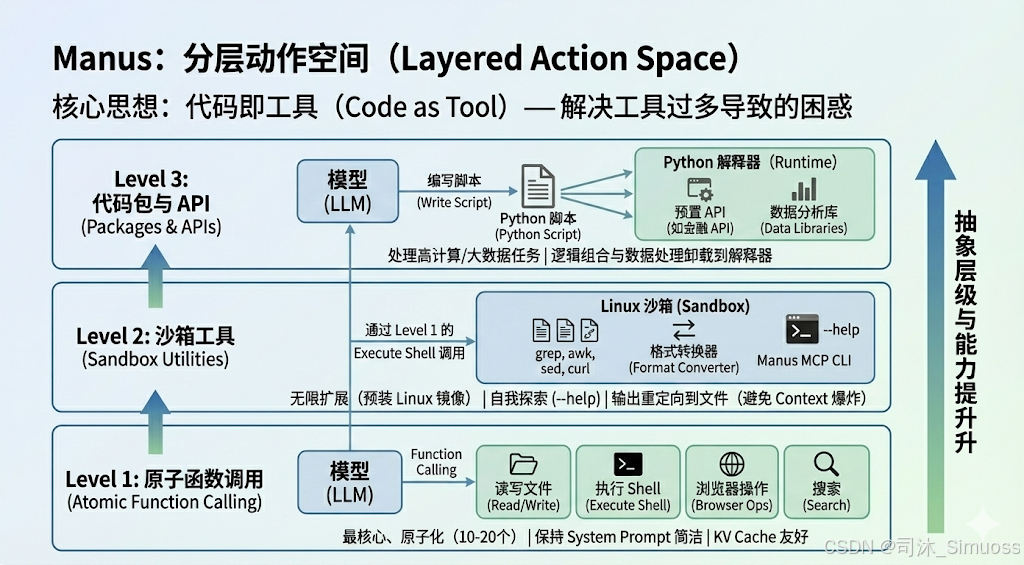
笔者按:Manus创始人曾经提到过,他们不希望做一个垂类场景的Agent工具,而是想做通用场景。为了实现这个目的,我们可以看到,Manus在设计时非常强调工具的通用性,通过了一系列技巧来确保模型注意力集中且拥有足够的能力解决通用问题。
然而,如果你的业务是垂类Agent,那么这种在沙盒中执行动作的范式就不一定适合你了,因为这种做法需要给每个Agent都配备一个沙盒环境。如果你需要跑数万个Agent并行,这是很大的一笔资源消耗。同时,垂类场景通常会有比较固定的工作流,所以大多数情况只使用Level1就可以解决大多数问题。
当然,Manus的工具设计哲学无论对于通用场景还是垂类场景,都是有许多值得借鉴之处的。不同场景一定有各自的最优解,所以辨证地学习即可
Level 1: 原子函数调用 (Atomic Function Calling)
- 定义: 仅保留 10-20 个最核心、最原子化的工具。
- 内容: 读写文件、执行 Shell 命令、浏览器基础操作、搜索。
- 目的: 保持系统提示词(System Prompt)的简洁,利用模型最擅长的 Function Calling 能力,确保高可靠性和对 KV Cache 的友好。
Level 2: 沙箱工具 (Sandbox Utilities)
- 定义: 运行在虚拟机(Linux Sandbox)内的命令行工具。
- 实现: 不直接作为 Function 暴露给模型,而是让模型通过 Level 1 的
Execute Shell工具来调用。 - 内容:
- Linux 标准工具:
grep,awk,sed,curl。 - Manus 自研 CLI:格式转换器、Manus MCP CLI(在沙箱内通过命令行调用 MCP 工具)。
- Linux 标准工具:
- 优势:
- 无限扩展: 添加新工具只需在该 Linux 镜像中预装,无需更新 Prompt。
- 自我探索: 模型可以使用
--help查看工具用法。 - 输出管理: 巨大的输出结果(如 grep 结果)可以直接重定向到文件,避免挤爆上下文窗口。
Level 3: 代码包与 API (Packages & APIs)
- 定义: 处理高计算量或大数据量的任务。
- 实现: 模型编写 Python 脚本,在脚本中调用预置的 API 或库。
- 案例: 分析全年股票数据。模型不应该读取所有数据(Token 爆炸),而是写一个 Python 脚本调用金融 API,在内存中计算平均值,只返回这一个数字。
- 核心思想: 代码即工具(Code as Tool)。 将逻辑组合和数据处理的过程下放到代码中,而非LLM中。
三、 上下文隔离(Context Isolation):架构设计的取舍
Manus 在多智能体(Multi-Agent)协作中,对上下文共享持谨慎态度。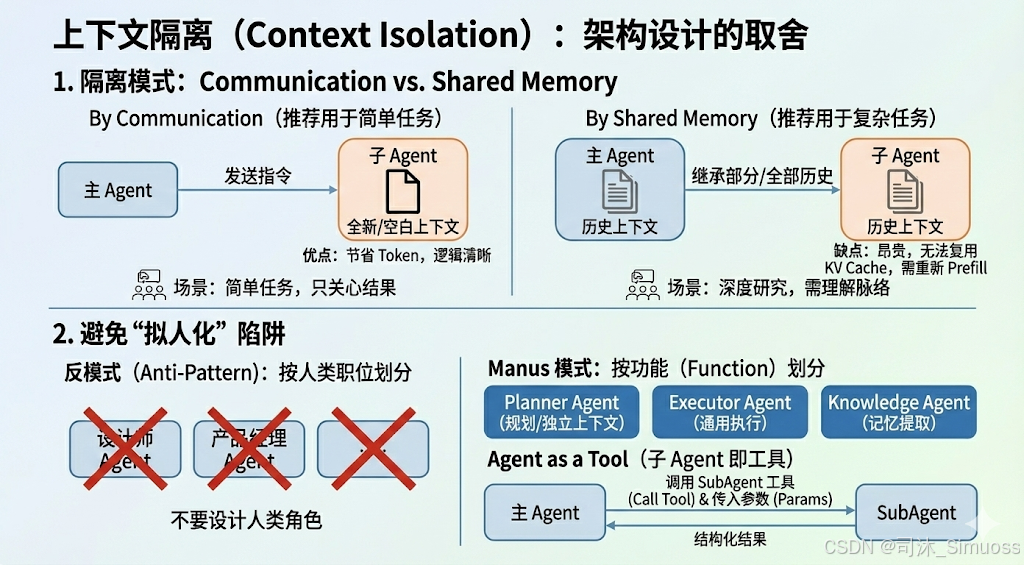
1. 隔离模式:Communication vs. Shared Memory
- By Communication (推荐用于简单任务): 主 Agent 只发送指令给子 Agent,子 Agent 拥有全新的、空白的上下文。
- 优点: 节省 Token,逻辑清晰。
- 场景: 比如“去代码库里找个东西”,主 Agent 不关心过程,只关心结果。
- By Shared Memory (推荐用于复杂任务): 子 Agent 继承父 Agent 的全部或部分历史上下文。
- 缺点: 昂贵。因为 System Prompt 不同,无法复用 KV Cache,必须重新计算 Prefill。
- 场景: Deep Research(深度研究),子 Agent 需要理解之前的搜索脉络。
2. 避免“拟人化”陷阱
- 反模式: 不要设计“设计师 Agent”、“产品经理 Agent”这种按人类职位划分的角色。
- Manus 模式: 按功能划分。
- Planner Agent: 负责规划(独立的上下文窗口)。
- Executor Agent (General): 通用执行器,负责干活。
- Knowledge Agent: 负责长期记忆的提取。
- Agent as a Tool: 在 Manus 眼中,子 Agent 只是一个高级的工具调用。主 Agent 调用
SubAgent工具,传入参数,获得符合 Schema 的结构化结果。
笔者按:这种Agent as Tool的思路在笔者日常的实践中,也是最好用的一种。很多时候,让两个单独执行的Agent通过诸如A2A等协议沟通时,其效果并不尽如人意;同时,两个并行的Agent还会平白浪费许多Tokens,增加成本。对此,笔者自己有一个暴论:如果你设计的Agent系统必须需要两个Agent通过A2A协议来交互,那这个Agent体系在设计上可能就是不合理的。
比如,是否可以使用一个共享文档作为公共区,在其中更新一些指标或者状态信息,来作为Agent交互的方式?这样Agent之间就不需要理解彼此,既降低了困惑度,也减少了A2A协议带来的额外Tokens消耗。
当然,这种观点也有前提,比如斯坦福小镇这种本就是MultiAgent体系探索的项目,就势必需要类似A2A的Agent交互协议。还是如上文,一切理论都要结合实际场景来辩证看待。
四、 检索与规划(Retrieval & Planning)
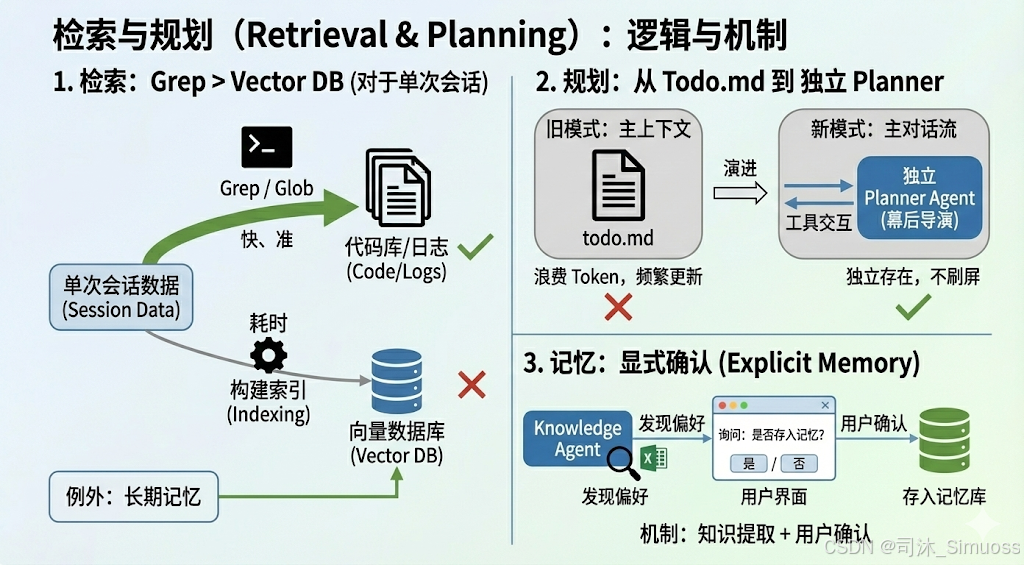
1. 检索:Grep > Vector DB (对于单次会话)
- 对于一次性的 Agent 会话,Manus 不建立动态向量索引(Vector Index)。
- 原因: 构建索引耗时,且对于代码库或日志文件,简单的
grep和glob(文件名匹配)往往比语义搜索更精准、更快速。 - 例外: 长期记忆或企业知识库仍需向量数据库。
2. 规划:从 Todo.md 到 独立 Planner
- 演进:
- 早期:在 Context 中维护一个
todo.md文件。- 问题: 浪费 Token,每次都要更新整个文件,且占用大量推理步骤。
- 现在:独立 Planner Agent。
- 实现: 作为一个独立的 Agent 存在,使用专门的工具(Agent as a Tool)进行交互。它不在主对话流中频繁刷屏,而是作为幕后导演。
- 早期:在 Context 中维护一个
3. 记忆:显式确认 (Explicit Memory)
- Manus 目前不完全依赖隐式记忆,而是采用知识发现 + 用户确认机制。
- 当 Knowledge Agent 发现用户偏好(如总是用 Excel 格式),会弹出对话框询问用户:“我学到了这个规则,是否存入记忆?”
五、 评估(Eval)与模型选择
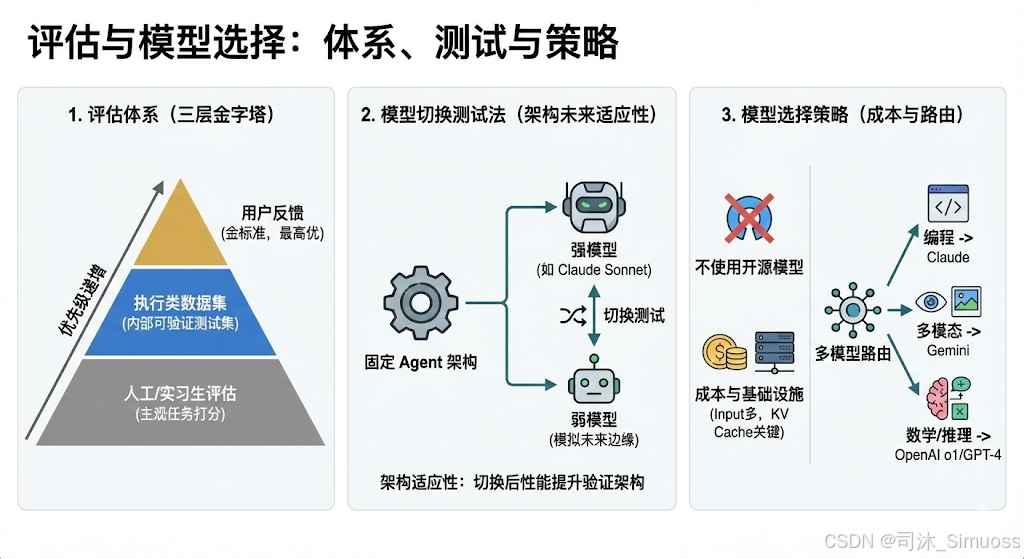
1. 评估体系
Manus 放弃了学术风格的 Benchmark(如 GAIA),转而使用以下三层标准进行评估:
- 用户反馈 (1-5星): 金标准,最高优先级。
- 执行类数据集: 内部构建的、包含实际执行动作(不仅仅是问答)的可验证测试集。
- 人工/实习生评估: 对于审美、网页布局等主观任务,依赖人工打分。
笔者按:学术风格的 Benchmark 在某些场景确实不适合给工程类应用作为评估标准。比如某些榜单会使用Agent是否能不出错地完成某项任务为指标,但生产中我们通常会允许模型在调用工具时犯错,无论是语法错误还是逻辑错误,并把报错的输出作为Observation添加进上下文,模型就可以依此改进自己的行为。
在学术角度,一个执行了10次能犯错8次的模型当然不如一个只犯错两三次的模型评分高,但是在工程角度,如果一个执行了10次能犯错8次的Agent在犯错一次的基础上能实现95%以上的正确率,那他在大多数场景都比执行了10次只犯错2次,但是Tokens消耗增大好几成,或者犯错的两次无论如何也不会自主纠偏回来的Agent要好。
2. 模型切换测试法
- 理念: 架构应该具备“未来适应性”。
- 做法: 固定 Agent 架构,在强模型(如 Claude 3.5 Sonnet)和弱模型之间切换。
- 目的: 如果架构在更换更强模型后性能显著提升,说明架构设计良好。同时,使用当前的弱模型可以模拟未来的边缘情况,或为未来更强的模型做预演。
笔者按:非常赞同。如果一款AI产品的技术团队在基础LLM能力提升后反而变得沮丧(比如产品对某款老模型做过微调,有硬依赖导致无法无缝升级到新模型,或者先前复杂的流程对强模型的效果还不如弱模型),那这款产品的设计是需要重新斟酌的。至少在未来的一两年里,Scaling Law还不会完全失效,我们更应该将希望与精力集中在模型迭代带来的能力增强上。
除非必要,否则先不微调,因为好的工程设计可以起到与微调类似的效果,而好的工程设计与模型能力迭代是相得益彰的。
3. 模型选择策略
- 不使用开源模型: 并非因为质量,而是成本与基础设施。
- 对于 Agent,Input Token 远多于 Output Token,KV Cache 是降低成本和延迟的关键。
- 商业模型提供商(如 Anthropic)的分布式 KV Cache 基础设施目前远优于自建开源模型服务。
- 多模型路由: 在不同场景下使用不同的模型,如
- 编写代码 -> Claude
- 多模态任务 -> Gemini
- 数学/推理 -> OpenAI o1/GPT-4
六、 总结
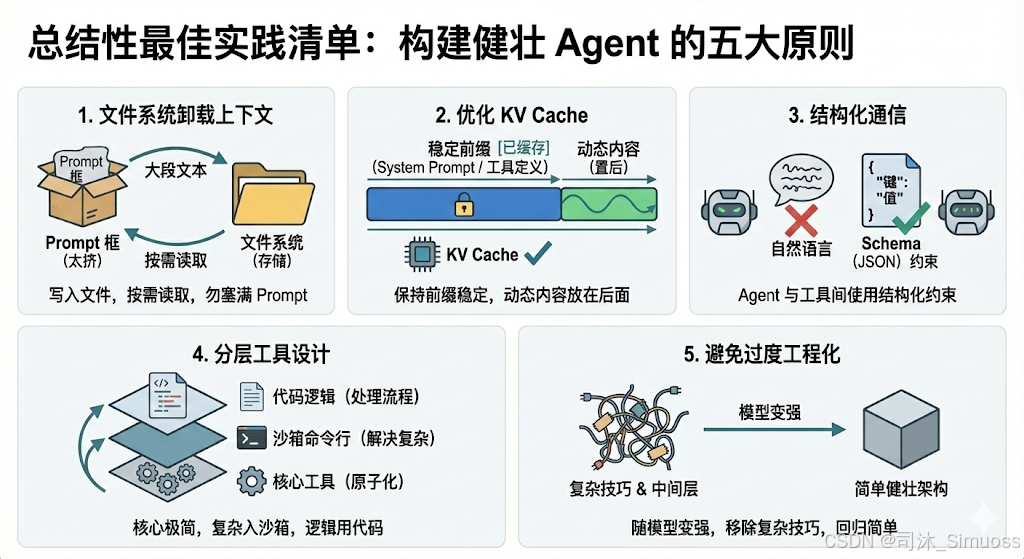
- 文件系统是最好的上下文卸载地: 不要把所有东西塞进 Prompt,把大段文本写入文件,让 Agent 按需读取。
- 善用 KV Cache: 保持 System Prompt 和前缀工具定义稳定,将动态变化的内容放在后面。
- 结构化通信: Agent 之间、工具返回结果,尽量使用 Schema (JSON) 约束,而非自然语言。
- 分层工具设计: 核心工具保持极简(原子化),复杂工具扔进沙箱用命令行解决,逻辑处理用代码解决。
- 不要过度工程化: 随着模型变强,移除复杂的 Prompt 技巧和中间层。简单的架构往往更健壮。
参考来源

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)