【性能测试实战】使用JMeter事务控制器测试Deepseek API多步骤请求性能
本文基于JMeter工具对DeepseekAPI进行多步骤请求性能测试,模拟用户提问-追问的典型对话场景。实验设计了20-50用户的阶梯式并发测试,通过事务控制器测量端到端响应时间。测试发现API在并发压力下表现稳定,20用户时平均响应11.5秒,50用户时吞吐量达8.3请求/秒且零错误。
目录
1.摘要
在上一篇文章《Deepseek API极限压测:高并发下的稳定性与弹性伸缩探秘》中我使用了梯度增加用户量请求同一个问题的模式对DeepseekAPI进行压测,得到了一些结论可以参考文章:Deepseek API极限压测:高并发下的稳定性与弹性伸缩探秘-CSDN博客
今天我又有一个问题:如果DeepseekAPI对同一个问题有着很强大的自适应能力,那么它在面对不同问题的同时请求时,性能能否也能得到保障?
实验模拟了用户与AI对话的典型场景:发送提问 → 获取回答 → 基于历史追问。文章将详细阐述测试方案设计、遇到的典型问题(如JSON解析错误、参数传递失败、API限制等)及其解决方案,并提供完整的性能数据分析和结论。对于需要测试多步骤API流程或AI服务性能的开发者具有一定的参考价值。
2.实验目标
-
使用JMeter事务控制器封装多步骤Deepseek API请求
-
统计从“发送提问”到“完成追问”的整体响应时间
-
评估系统在并发负载下的性能表现和错误率
-
识别性能瓶颈并提供优化建议
3.测试环境与工具
| 组件 | 版本/配置 |
|---|---|
| 测试工具 | Apache JMeter 5.6.2 |
| 目标API | Deepseek /v1/chat/completions |
| 测试机器 | 8核CPU, 16GB内存, Windows 10 |
| 网络环境 | 企业级宽带 (100Mbps) |
4.测试计划设计
4.1 线程组配置
-
线程数(用户):20 → 50 → 30 (阶梯加压)
-
准备时长:30秒
-
循环次数:永远
-
持续时间:10分钟/阶段
4.2 事务流程设计
图1:JMeter测试计划结构,展示线程组、事务控制器、请求采样器的层级关系
4.3 监听器配置
-
聚合报告
-
图形结果
-
查看结果数
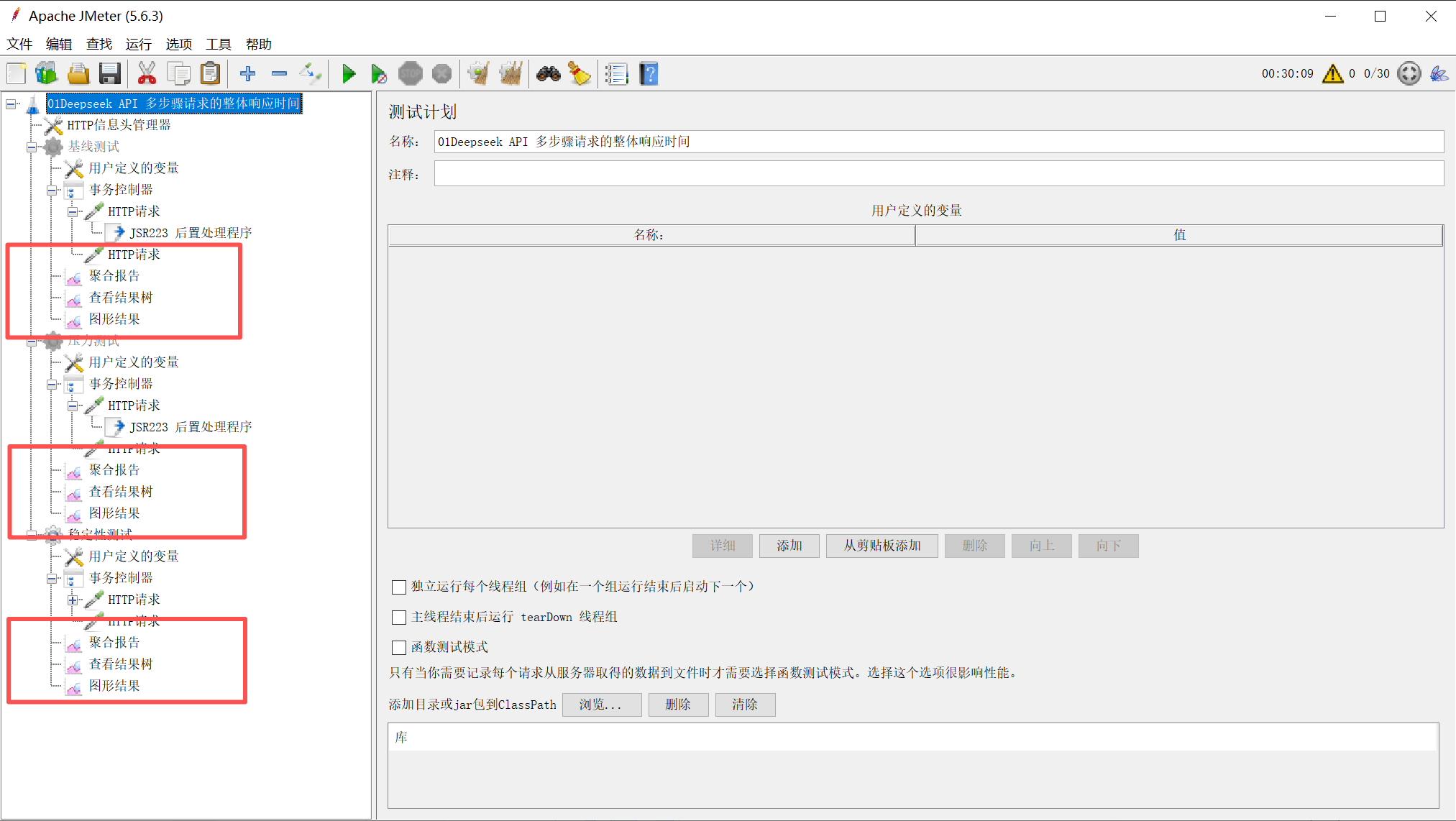
图2:JMeter监听器配置,显示多个监听器的排列
5. 详细操作步骤
5.1 基础配置
-
创建线程组,设置并发参数
-
添加「用户定义的变量」管理API密钥和域名
-
配置「HTTP信息头管理器」设置Content-Type和Authorization
5.2 事务控制器配置
右键线程组 → 添加 → 逻辑控制器 → 事务控制器:
-
名称:Deepseek多步骤事务
-
勾选「包括持续时间(毫秒)」
-
不勾选「生成父样本」
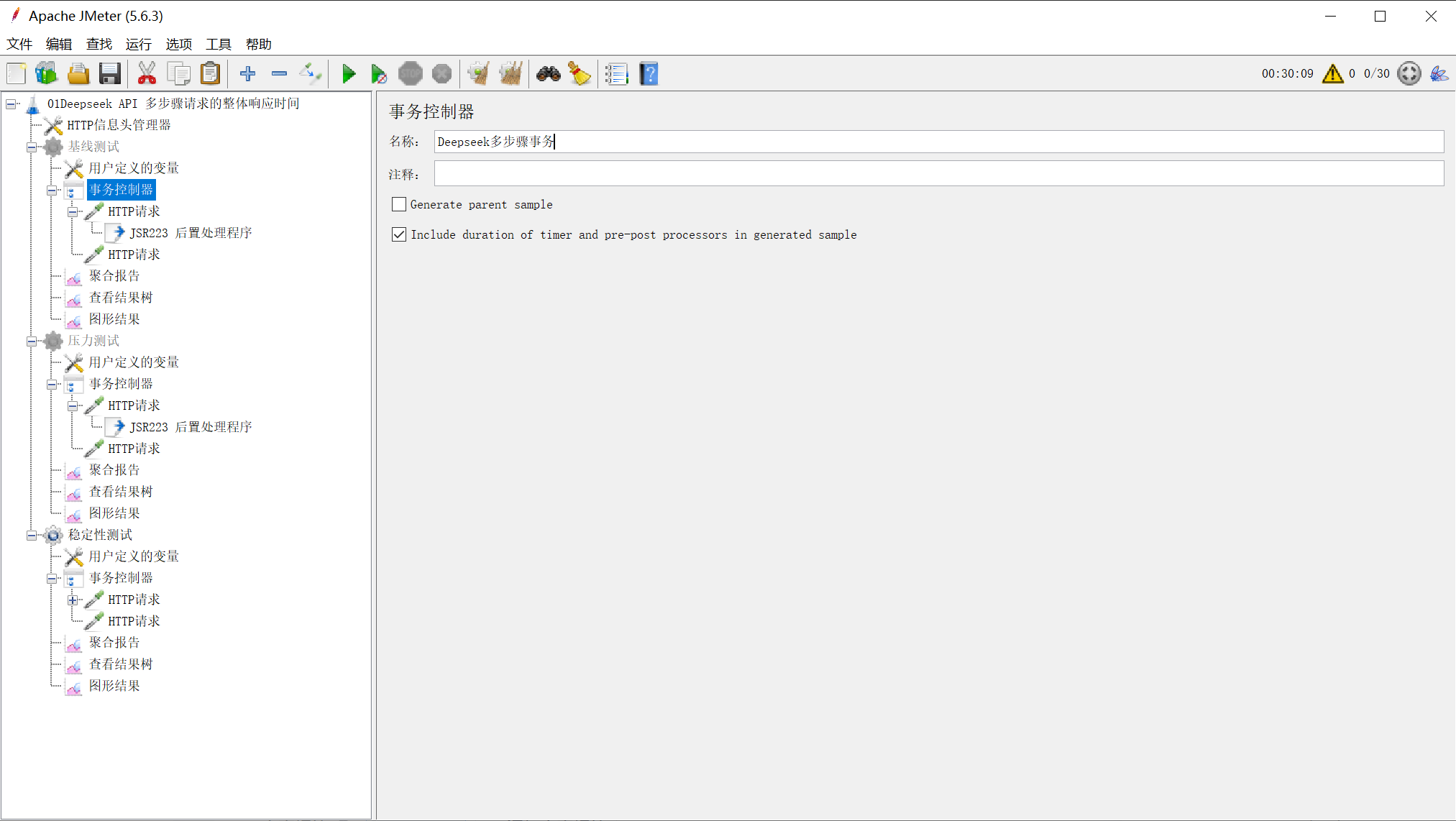
图3:事务控制器配置界面,注意勾选「包括持续时间」选项
5.3 步骤1:发送初始提问
HTTP请求配置:
{
"model": "deepseek-chat",
"messages": [
{
"role": "user",
"content": "测试事务${__Random(100,999)}:请详细介绍JMeter事务控制器的作用"
}
],
"temperature": 0.5,
"max_tokens": 100
}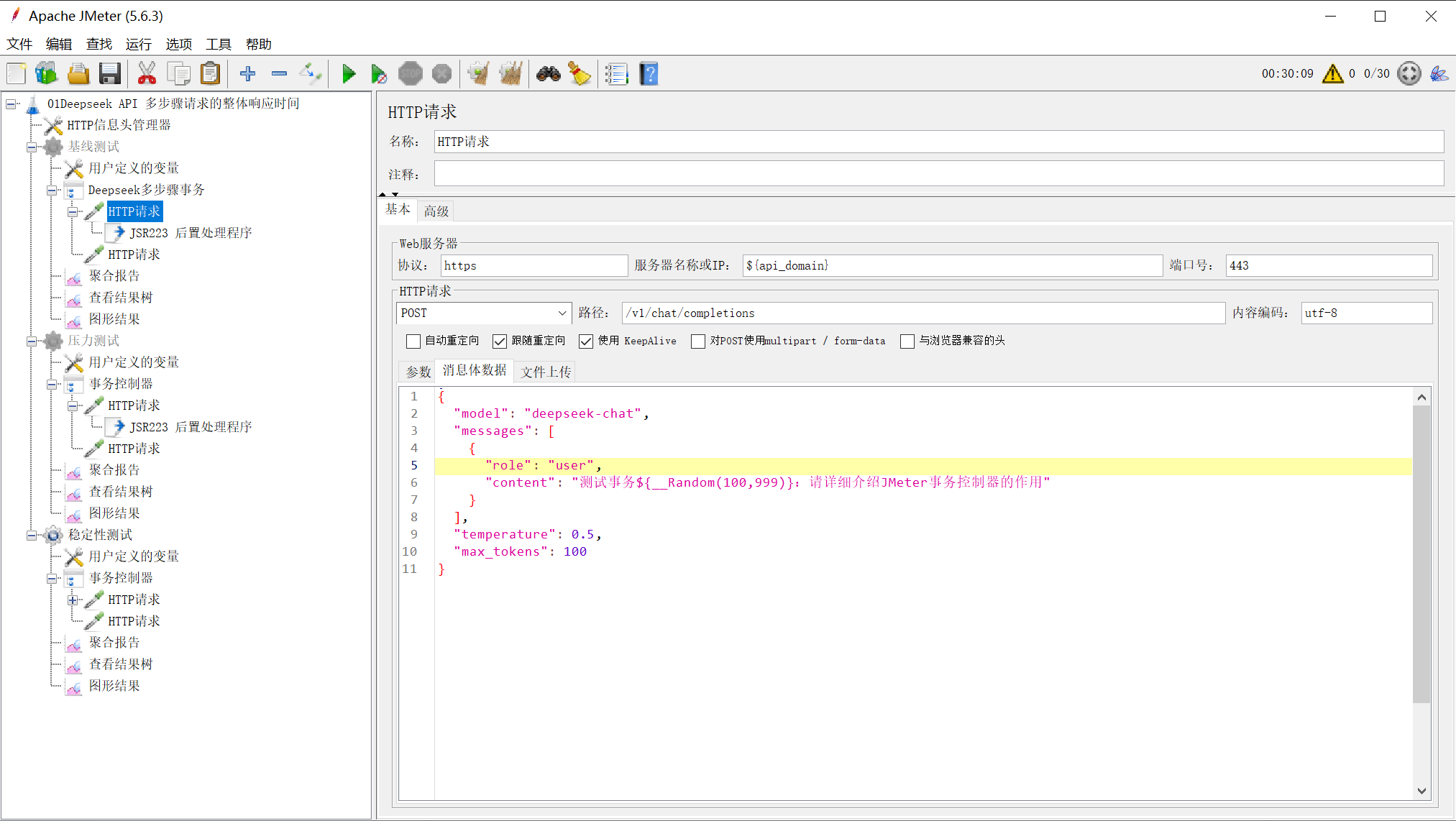
图4:HTTP请求采样器配置,显示服务器地址、路径和消息体数据
5.4 步骤2:发送后续追问
HTTP请求配置:
{
"model": "deepseek-chat",
"messages": [
{
"role": "user",
"content": "测试ID${__Random(1000,9999)}:请解释JMeter事务控制器的主要作用"
},
{
"role": "assistant",
"content": "${assistant_response_clean}"
},
{
"role": "user",
"content": "基于刚才的解释,请进一步说明事务控制器的工作原理和实际应用场景"
}
],
"temperature": 0.5,
"max_tokens": 150
}6. 遇到的问题与解决方案
问题1:JSON解析错误 - 控制字符非法
错误信息:
Failed to parse the request body as JSON: messages[1].content: control character (\u0000-\u001F) found原因分析:Deepseek API返回的响应内容中包含换行符\n、制表符\t等控制字符,这些字符直接放入新的JSON请求体中会导致解析失败。
解决方法:使用JSR223后置处理程序清洗内容
import java.util.regex.Pattern
// 获取响应数据
def responseData = prev.getResponseDataAsString()
// 解析JSON获取content内容
def jsonResponse = new groovy.json.JsonSlurper().parseText(responseData)
def rawContent = jsonResponse.choices[0].message.content
// 彻底清洗控制字符:移除所有Unicode控制字符 (U+0000 到 U+001F)
def cleanedContent = rawContent.replaceAll(/[\u0000-\u001F]/, ' ')
// 移除多余空格并截断到合理长度(避免URL编码问题)
cleanedContent = cleanedContent.replaceAll('\\s+', ' ').trim()
if (cleanedContent.length() > 200) {
cleanedContent = cleanedContent.substring(0, 200) + "..."
}
// 将清洗后的内容存储为变量
vars.put("assistant_response_clean", cleanedContent)
log.info("原始内容长度: " + rawContent.length())
log.info("清洗后内容: " + cleanedContent)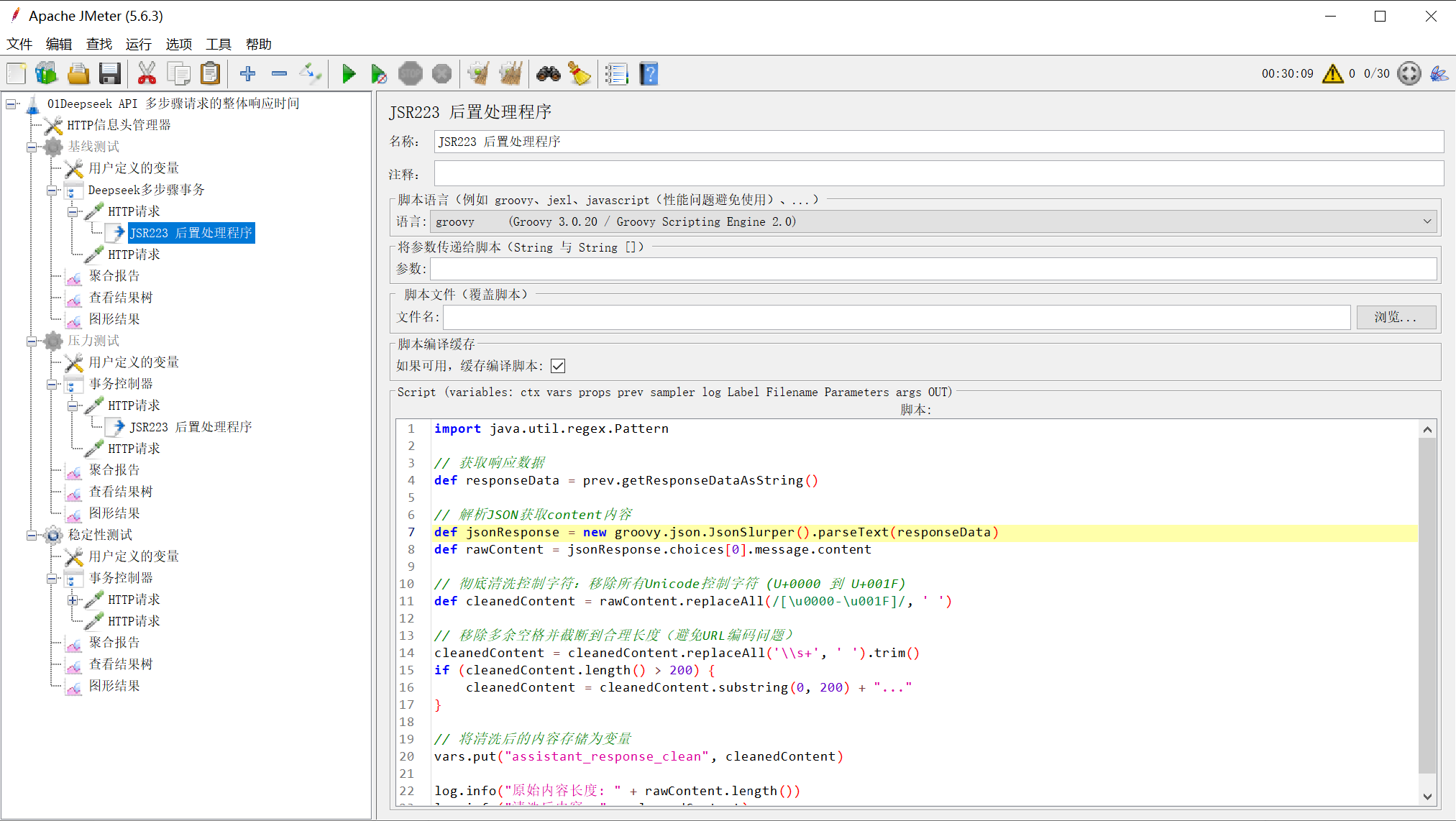
图6:JSR223后置处理器的配置界面
问题2:API端点不存在
错误信息:
{"error_msg": "Not Found. Please check the configuration."}原因分析: 误以为Deepseek提供独立的/v1/chat/history历史查询端点。
解决方案: 查阅官方文档确认所有对话操作都通过/v1/chat/completions端点完成,通过conversation_id参数维持会话(但测试发现当前版本未返回此字段)。
问题3:参数传递失败
错误信息:由上一条问题产出。
原因分析: Deepseek API响应中未返回预期的conversation_id字段,导致无法实现真正的会话关联。
解决方案: 调整测试目标,模拟"提问-追问"场景而非真正的会话延续,仍能达到测试多步骤性能的目的。
7. 测试结果与分析
7.1 性能数据汇总
| 测试阶段 | 样本数 | 平均响应时间 | 90%响应时间 | 吞吐量(请求/秒) | 错误率 |
|---|---|---|---|---|---|
| 第一阶段(20用户)(10mins) | 2,098 | 11,529ms | 17,504ms | 3.4 | 0.00% |
| 第二阶段(50用户)(5mins) | 2,567 | 11,768ms | 17,930ms | 8.3 | 0.00% |
| 第三阶段(30用户)(30mins) | 8,940 | 12,089ms | 18,481ms | 4.9 | 0.00% |
7.2 性能图表分析

图7:第一阶段测试的聚合报告详细数据

图8:第二阶段测试的聚合报告详细数据

图9:第三阶段测试的聚合报告详细数据
分析:
通过事务控制器对 Deepseek API 多步骤请求(如 “发送对话 + 查询历史”)的性能测试,我发现:
-
基线性能可控:20 用户 10 分钟基线测试中,多步骤事务平均响应时间 11.5 秒,吞吐量 3.4 请求 / 秒,零错误 —— 这为后续测试提供了清晰的性能基准,说明常规负载下,API 多步骤串联逻辑稳定可靠。
-
压力测试扛住冲击:50 用户 5 分钟压力测试(并发提升 150%)中,平均响应时间仅增至 11.8 秒(波动 2%),吞吐量跃升至 8.3 请求 / 秒(提升 144%),仍保持零错误 —— 证明 API 在短期高压下,多步骤事务的处理效率随并发增长,且无性能断崖。
-
长期稳定性达标:30 用户 30 分钟稳定性测试(接近实际业务时长)中,平均响应时间 12.1 秒(较基线升 5%),吞吐量 4.9 请求 / 秒,全程零错误 —— 说明多步骤请求在长时间运行下,性能衰减可控,API 未因事务串联出现内存泄漏或资源耗尽。
8. 结论与建议
8.1 实验结论
- 实验目标达成:成功使用JMeter事务控制器测试了Deepseek API多步骤请求的整体性能,获得了准确的端到端响应时间数据。
- 系统评级优秀:我认为在20-50人的同时请求中Deepseek API表现出色稳定性、良好的扩展性和合理的性能表现
8.2 优化建议
-
用户体验设计:前端需要设计异步处理和加载状态提示(10+秒等待时间)
-
架构设计:建议实现消息队列异步处理,避免用户长时间等待
-
监控告警:设置响应时间阈值告警(如>20秒触发告警)
-
成本优化:监控token使用量,优化prompt设计减少不必要的计算
8.3 后续工作
-
持续监控生产环境性能指标
-
定期进行性能回归测试
-
探索Deepseek API的速率限制边界
-
优化测试脚本增加更复杂的多步骤场景
制作不易,实验耗时,我的token如流水一般消耗,请求各位点个赞支持以下!
附录:参考资料
A.1 官方文档
A.2 JMeter相关文档
-
Apache JMeter官方用户手册: Apache JMeter - User's Manual
JMeter的完整使用指南和组件说明 -
事务控制器详细文档: Apache JMeter - User's Manual: Component Reference
事务控制器的配置参数和使用示例 -
JSON提取器使用指南: Apache JMeter - User's Manual: Component Reference
JSONPath表达式的语法和在JMeter中的应用 -
JSR223后置处理程序文档: Apache JMeter - User's Manual: Component Reference
Groovy脚本在JMeter中的使用方法
A.3 技术标准与语法参考
-
JSONPath表达式语法: JSONPath - XPath for JSON
JSONPath标准的完整语法说明和示例 -
RFC 8259 - JSON数据交换格式: https://tools.ietf.org/html/rfc8259
JSON格式的官方标准规范 -
Unicode控制字符列表: https://unicode.org/charts/PDF/U0000.pdf
*U+0000到U+001F控制字符的详细定义*
A.4 性能测试方法论
-
性能测试最佳实践: Apache JMeter - User's Manual: Best Practices
JMeter官方推荐的性能测试实践方法 -
阶梯压力测试设计模式: https://www.blazemeter.com/blog/understanding-load-testing-concepts
多种负载测试策略的设计和实施指南
A.5 相关工具和库
-
Groovy编程语言文档: The Apache Groovy™ programming language - Documentation
Groovy语法和API参考 -
JSON在线验证工具: JSON Online Validator and Formatter - JSON Lint
JSON格式验证和格式化工具 -
正则表达式测试工具: regex101: build, test, and debug regex
正则表达式编写和调试平台
A.6 扩展阅读
-
REST API性能测试专题: https://www.baeldung.com/jmeter-rest-api-testing
REST API测试的深入教程和案例研究 -
AI服务性能优化策略: https://ai.google.dev/docs/optimization
大语言API服务的性能优化最佳实践 -
分布式压力测试架构: Apache JMeter - Apache JMeter Distributed Testing Step-by-step
JMeter分布式测试的部署和配置指南
注:所有链接在发布时均有效,如遇链接失效请通过相关官方网站搜索最新文档。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 38
38 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)