model.generate()参数用处,该怎么配合使用
囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊囊😡囊囊囊😡囊囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡囊囊囊😡饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿啊🤯饿阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤阿巴🤤
model.generate()参数
| 参数 | 类型 | 作用 | 常用设置示例 | 原理说明 |
|---|---|---|---|---|
input_ids |
torch.LongTensor |
模型输入的 token IDs | tokenizer("你好", return_tensors="pt").input_ids |
模型以 token IDs 为输入生成输出序列 |
attention_mask |
torch.Tensor |
指示哪些 token 参与注意力计算 | torch.ones_like(input_ids) |
0 的位置被忽略,1 的位置参与计算 |
max_new_tokens |
int |
生成的最大新 token 数量 | 50、500 |
限制生成长度,避免无限生成 |
max_length |
int |
生成序列的总长度(含输入) | 128、512 |
如果设置了 max_new_tokens,一般不用 max_length |
min_length |
int |
生成序列最短长度 | 10 |
保证生成内容不会过短 |
do_sample |
bool |
是否随机采样生成 | True / False |
False 用贪心生成,True 用采样增加多样性 |
early_stopping |
bool |
遇到 EOS token 是否提前停止 | True |
遇到 <EOS> token 即停止生成 |
num_beams |
int |
Beam Search 的 beam 数量 | 1 (贪心) / 5 |
Beam Search 可考虑多条路径,提高生成质量 |
length_penalty |
float |
对序列长度的惩罚系数 | 1.0 (默认) |
>1 偏好长文本,<1 偏好短文本 |
temperature |
float |
采样温度 | 1.0、0.7 |
调整生成随机性,越低越确定 |
top_k |
int |
Top-K 采样 | 50 |
从概率最高的 K 个 token 中采样 |
top_p |
float |
核心采样 (nucleus sampling) | 0.9 |
从累计概率 ≥ p 的 token 中采样 |
repetition_penalty |
float |
对重复 token 的惩罚 | 1.2 |
防止生成重复内容 |
bad_words_ids |
List[List[int]] |
指定禁止生成的 token | [[tokenizer.encode("禁词")[0]]] |
避免生成敏感/不希望的词 |
num_return_sequences |
int |
返回序列数量 | 1 / 3 |
可以一次生成多条不同序列 |
encoder_outputs |
ModelOutput |
提供 encoder 输出(用于 encoder-decoder 模型) | model(**inputs).encoder_last_hidden_state |
避免重复编码,提高效率 |
use_cache |
bool |
是否使用 past_key_values 缓存 | True |
提升自回归生成速度 |
return_dict_in_generate |
bool |
是否返回字典结构 | True |
可获取 sequences, scores, attentions 等 |
output_scores |
bool |
是否返回每步 token 的概率分数 | True |
方便做排序或计算 perplexity |
forced_bos_token_id |
int |
强制开始 token | tokenizer.bos_token_id |
指定生成序列开头 token |
forced_eos_token_id |
int |
强制结束 token | tokenizer.eos_token_id |
指定生成序列结束 token |
prefix_allowed_tokens_fn |
Callable |
限制每步可生成 token | lambda batch_id, x: allowed_ids |
常用于约束生成特定词汇或格式 |
synced_gpus |
bool |
分布式训练时同步 GPU | False |
在多 GPU 推理时保持同步 |
max_time |
float |
生成最大时间(秒) | 10.0 |
避免长时间生成卡住 |
演示比上面的更容易理解
do_sample
do_sample 决定模型在生成下一个 token 时 是否使用随机采样
-
do_sample=False→ 贪心策略 (Greedy)
每次都选 概率最高的 token,生成文本。
优点:稳定、重复率低
缺点:可能缺少创意,容易陷入循环重复
循环重复:大模型经典输出错误案例
我最喜欢的水果是苹果苹果苹果苹果苹果苹果苹果苹果苹果...
当前状态:生成到 "我最喜欢的水果是"
下一步 token 概率:
"水果" 0.6
"桌子" 0.2
"是" 0.1
其他 0.1
模型不断选择高概率 token "了"
文本就陷入循环,语义越来越奇怪
这种问题在 长文本 或 对话生成 中尤其明显
-
do_sample=True→ 随机采样 (Sampling)
按概率分布 随机选 token,每次生成可能不同。
优点:文本更自然、创造性高
缺点:可能出现不合理或语法错误的 token
do_sample的演示
user_input = "今天晚上吃什么"
# 生成文本
out_g = model.generate(
**inputs,
max_new_tokens=128, # 生成新token的最大数量
do_sample=False,
)
print("out_g推理完毕")
out_d = model.generate(
**inputs,
max_new_tokens=128, # 生成新token的最大数量
do_sample=False,
)
print("out_d推理完毕")
out_z = model.generate(
**inputs,
max_new_tokens=128, # 生成新token的最大数量
do_sample=True,
)
print("out_z推理完毕")
原理细节
假设模型输出下一个 token 的概率分布为 P(xi)P(x_i)P(xi):
Token A B C D
Prob 0.5 0.3 0.15 0.05
do_sample=False (贪心)
直接选择概率最大的 A
每次输出都是最确定的选择
do_sample=True (采样)
按概率随机抽取 token
0.0 ----- 0.5 ----- 0.8 ----- 0.95 ----- 1.0
A B C D
生成时,模型会在 0~1 之间随机生成一个数 r:
如果 r 落在 0~0.5 → 抽到 A
如果 r 落在 0.5~0.8 → 抽到 B
如果 r 落在 0.8~0.95 → 抽到 C
如果 r 落在 0.95~1.0 → 抽到 D
核心是 把概率当作抽签权重,每次生成都可能不同
temperature
|
temperature |
温度 | ||||||
|
控制生成文本的随机性,值越高越随机 |
|
temperature的演示
user_input = "今天和你玩个游戏,我说一段话你跟着后面续写后面的故事,我先来:从前有座山"
prompt = alpaca_prompt.format(user_input=user_input)
print(prompt)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 生成文本
out_g = model.generate(
**inputs,
max_new_tokens=128, # 生成新token的最大数量
do_sample=True,
temperature=1.5
)
print("out_g推理完毕")
out_d = model.generate(
**inputs,
max_new_tokens=128, # 生成新token的最大数量
do_sample=True,
temperature=0.5
)
print("out_d推理完毕")
out_z = model.generate(
**inputs,
max_new_tokens=128, # 生成新token的最大数量
do_sample=True,
temperature=1.0
)
print("out_z推理完毕")
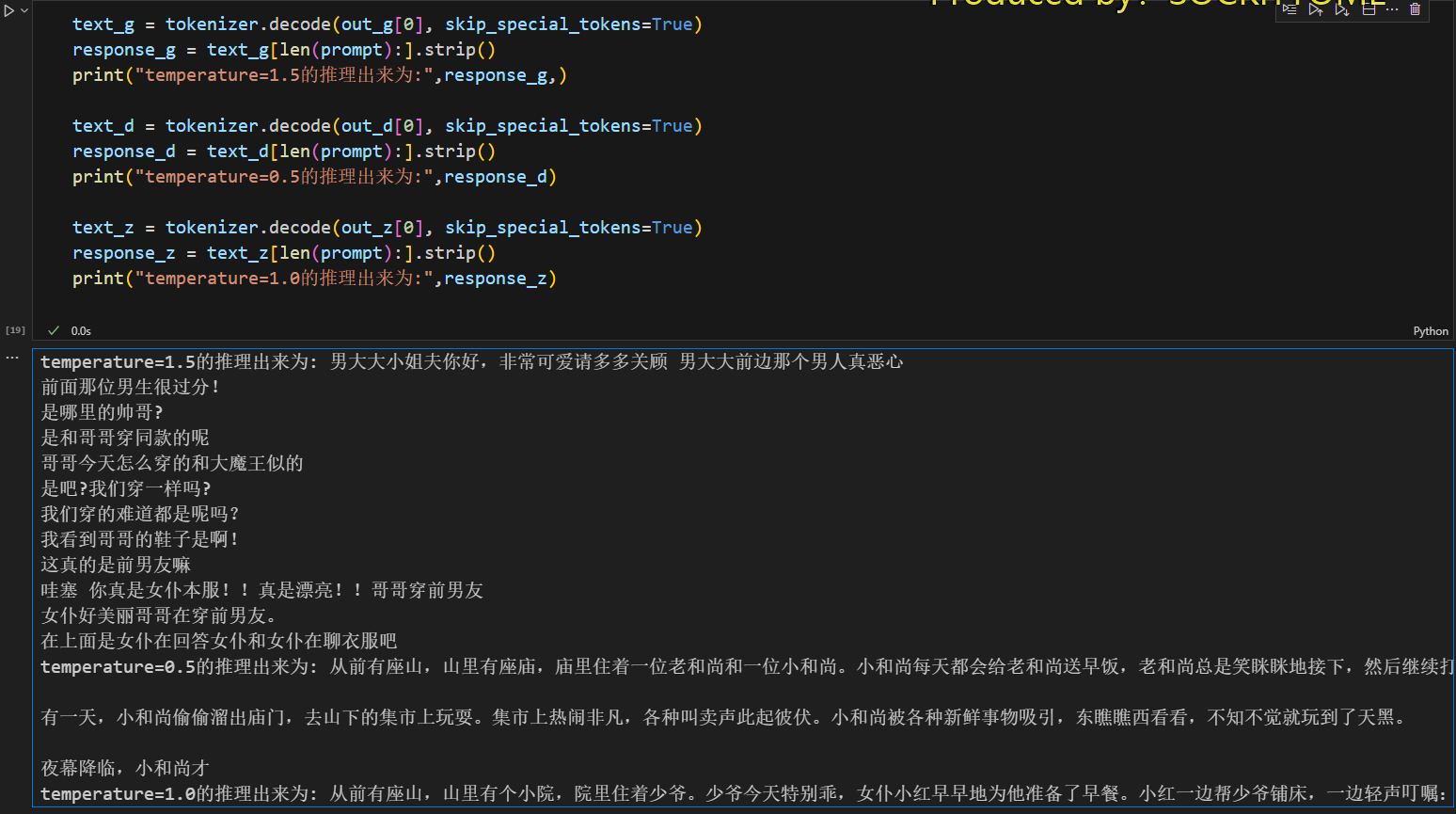
ps:第一个都不知道天地为何物了
temperature原理
假设模型输出的原始概率分布为![]()
![]()
其中zi是模型对每个 token 的分数。
具体可以看这篇
加入 temperature t 后:
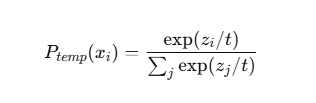
3️⃣ 举例
假设四个 token 的 logits 对应概率(未 softmax):
| Token | A | B | C | D |
|---|---|---|---|---|
| logit | 2 | 1 | 0 | -1 |
-
t = 1 → softmax 得到概率大致:[0.5, 0.3, 0.15, 0.05]
-
t = 0.5 → logits 放大 → softmax 得到概率大致:[0.7, 0.2, 0.08, 0.02] → 输出更确定
-
t = 2.0 → logits 缩小 → softmax 得到概率大致:[0.35, 0.28, 0.22, 0.15] → 输出更随机
计算过程如下
temperature = 0.5为举例
分母=
a=2/0.5=4 -> e4 =54.598
b=1/0.5=2 -> e2 =7.389
c=0/0.5=0 -> e0 =1
d=-1/0.5=-2 -> e-2 =0.1353
求和:54.598+7.389+1+0.1353≈63.122
概率
A: 54.598 / 63.122 ≈ 0.865
B: 7.389 / 63.122 ≈ 0.117
C: 1 / 63.122 ≈ 0.016
D: 0.1353 / 63.122 ≈ 0.002top-k
Top-K 采样是一种 生成文本时的随机采样策略,它控制每次模型生成下一个 token 时,只从概率最高的 K 个候选 token 中选取,而不是从整个词表里选。
|
K 值小 |
生成越“确定”,更接近贪心生成,容易重复、缺乏多样性 |
| K 值大 | 生成更随机、多样,但可能出现语义不通或突兀的词 |
| top_k | token候选范围 | 输出效果 | 格外备注 |
| 1 | 等价于 greedy search(始终选最可能的词)。 | 输出最稳定,但几乎没有多样性。 | |
| 2-10 | 非常小的范围。 | 输出多样性很有限,但会有一些细节差别。 | 常见于需要“安全、保守”的生成(比如客服机器人)。 |
| 20-50 | 这个范围平衡了 合理性 和 多样性。 | 文本既不会太机械,也不会跑偏。 | 实际上,很多论文和 HuggingFace 的 demo 里都会推荐 top_k=40 |
| 100-200 | 多样性明显增强,内容更丰富。 | 适合创意写作、故事生成,但风险是容易出现奇怪的内容。 | |
| >500 || 0 | 相当于“几乎不做截断”。 | 模型可能抽到概率极低的 token → 容易乱跑(乱码、风格突然变、逻辑崩坏)。 |
一般不推荐,除非你就是想要“最发散的脑洞” |
top-k的演示
base_kwargs = dict(
**inputs,
max_new_tokens=128,
do_sample=True, # 保证采样生效
temperature=1.0, # 固定其他参数,避免干扰
top_p=1.0,
)
for k in [1, 5, 10, 40, 100, 0]:
out = model.generate(**base_kwargs, top_k=k)
# print(f"top_k={k}: ", tokenizer.decode(out[0], skip_special_tokens=True))
out_text = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"top_k={k}: ", out_text)top_k=1: 少爷,今天午餐我们可以在少爷府上的餐厅享用。我已为您准备了一份特别的菜单,包括新鲜的沙拉、香煎三文鱼、以及您最喜欢的红酒炖牛肉。请您稍候,我会立即通知厨房准备。
top_k=2: "少爷,请您放心,今天的午餐已经在厨房准备好了。我们会在正午十二点在餐厅为您准备丰盛的菜肴。具体菜品包括清蒸鲈鱼、蒜蓉西兰花和红烧肉,这些都是少爷最爱的菜肴。请您稍等片刻,我们会在午餐时间准时为您送上。"
top_k=10: "少爷,今日午餐已安排在二楼的西餐厅,今日的菜单是香煎牛排配黑椒酱,搭配新鲜的时令蔬菜。如果您对菜品有特殊要求,或者想要尝试新的菜品,可以随时告知厨房,我会帮您调整。用餐时间是12点整,我会提前准备好您的餐巾和餐具。"
top_k=40: "少爷,请允许我为您安排午餐。根据以往的喜好,我为您预订了一家我们常去的餐厅。今日的菜单上有清蒸海鲈鱼和鲍鱼牛肉炖饭等佳肴。我们将前往餐厅,在餐厅内挑选一些您喜欢的菜品。请您放心,我会保证让菜品符合您的口味,并在您用餐时提供所需的一切协助。"
top_k=100: 少爷,请您放心,今天午餐我会安排在城堡的厨房为您准备。我们今天午餐将会是一道特别的菜肴——香煎三文鱼配柠檬黄油酱汁和奶油土豆泥。此外,还附赠了您最爱的苹果派作为配餐。不知道您是否还有其他特别的要求或者想要尝试新的菜品?我非常乐意满足您的期待。请您稍安勿躁,午餐将在不久后为您准备好并且及时送上。
top_k=0: **女仆:**
"少爷,今天午餐由我为您预订在老城区最著名的餐厅'玫瑰园',专为您准备了招牌套餐。"
**少爷:**
"玫瑰园?听说那里的三文鱼刺身很好吃,今天要来一份吗?"
**女仆:**
"好的,少爷,一定为您准备最新鲜的三文鱼刺身,保证让您品尝到最美味的刺身。"
**少爷:**
"那地址我只知道大概位置,具体怎么去你知道吗?"
**女仆:**
"少爷,玫瑰园位于老| top | 评价 |
| 1 |
|
| 2 |
|
| 10 |
|
| 40 |
|
| 100 |
|
| 0 |
|
top_k原理
top-k 采样的核心逻辑

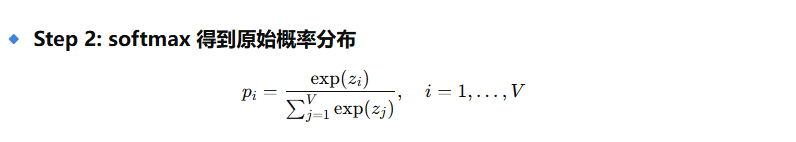

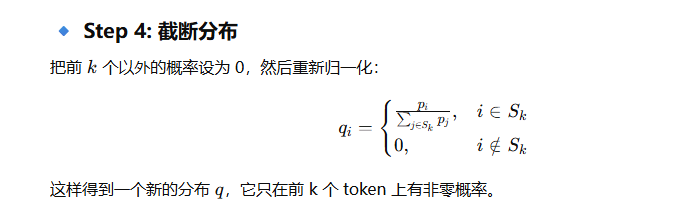
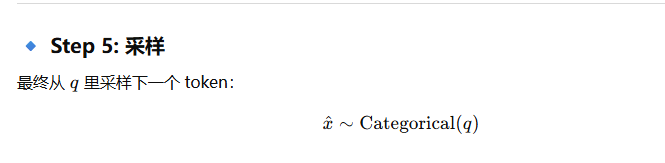
import torch class TopKSampler:
def __init__(self, k):
self.k = k
def sample(self, logits):
# Step 1 & 2: logits -> softmax 概率
# (你直接在截断后做 softmax,也可以先 softmax 再截断,结果等价)
# Step 2: softmax 归一化 + 采样
probabilities = torch.softmax(mask, dim=-1)
# Step 3: 取前 k
values, indices = torch.topk(logits, self.k, dim=-1)
# Step 4: 非 top-k 设为 -inf,相当于概率=0
mask = torch.full_like(logits, float('-inf'))
mask.scatter_(-1, indices, values)
# Step 5:从 top-k 概率分布中采样
return torch.multinomial(probabilities, num_samples=1)
top_p
top_p 不像 top_k是按照固定的数量截断token序列
而是通过概率累计判断是否截断token序列:
每一步把 token 按概率从大到小排好,取前面最少的一组 token,使得这组 token 的概率之和 ≥ p。然后只在这组 token 里做采样。
因此候选集合大小是自适应的——高不确定性时集合会更大,确定性强时集合会更小。
一个简单的例子
top_p=0.9
根据概率从高到低排序,然后进行累计,到厨师已经累计到0.92了, 判断是否大于等于top_p如果 是 就往上打包 然后随机采样一个作为下一个输出。
如果不是就跳下一个累计概率
token 概率 累计概率 少爷 0.35 0.35 小姐 0.20 0.55 公子 0.15 0.70 狗 0.12 0.82 厨师 0.10 0.92 ✅ 管家 0.08 1.00
top_p的演示
torch.manual_seed(666)
base_kwargs = dict(
**inputs,
max_new_tokens=128,
do_sample=True, # 保证采样生效
temperature=1.0, # 固定其他参数,避免干扰
top_k=0, # 关闭 top_k,使用 top_p 截断
)
for p in [0.3, 0.5, 0.7, 0.9, 1.0]:
out = model.generate(**base_kwargs, top_p=p)
# 取生成部分(去掉 prompt)
out_text = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"top_p={p}: ", out_text)top_p=0.3: "少爷,午餐已经在二楼的餐厅准备好了,您看菜单上有什么特别想吃的吗?或者需要我为您安排一些特别的菜品?"
top_p=0.5: "少爷,午餐我已安排在府邸正厅用餐,今日有家传红烧肉、清蒸鲈鱼和清炒时蔬,还有一碗香喷喷的鸡汤,皆是今日精心准备的佳肴,可否让我先为您盛上?"
top_p=0.7: "少爷,今天的午餐已经在厨房准备好了,是红烧肉、清蒸鱼和青菜豆腐汤,还有我特意为您准备的水果拼盘。厨房里还为您准备了一杯冰镇的橙汁,需要我去端上来吗?"
top_p=0.9: 非常抱歉,我确实忘记了今天的午餐安排。我稍后就去查一下少爷的午餐记录,您稍等片刻。
(大约10分钟后)
少爷,经过查看少爷的个人档案和饮食记录,我找到了今天的午餐安排。根据少爷的喜好和身体状况,建议在午时膳厅享用传统的中式午餐,包括清蒸海鲈鱼、蒜蓉西兰花和番茄蛋汤,搭配一份营养均衡的拌饭。如果您有其他特殊需求,请告知我。希望今天的午餐能给少爷带来舒适和愉悦的心情。
top_p=1.0: 少爷今晌午的午餐安排已备好,我们决定前往府前的‘青云轩’享用午餐,那里的菜肴新鮮可口,显然是个不错的选择。虽然这里可能需要一些摩拳擦掌的时间,我会提前准备好所需的一切,保证能让少爷有一个愉快的用餐体验。记得吩咐厨房多添了几份可口的热汤,让少爷入席即可享用。看来您今天似乎心情不错,那我们一同享受片刻吧。| top_p | 文本长度/复杂度 | 特点 |
|---|---|---|
| 0.3 | 短、简洁 | 句子很短,只描述了餐厅已经准备好了,并问少爷是否有特别需求。 |
| 0.5 | 稍长、具体 | 给出具体菜品(红烧肉、清蒸鲈鱼、清炒时蔬、鸡汤),略有细节和丰富度,但仍保持直接和简明。 |
| 0.7 | 更丰富 | 描述了完整午餐(菜品 + 水果拼盘 + 饮品),增加了交互性(“需要我去端上来吗?”),语气更贴近自然对话。 |
| 0.9 | 非常长、逻辑丰富 | 出现了“忘记记录→查档案→提供详细建议”的多步逻辑,文本明显跳跃且故事化,加入了少爷偏好和身体状况判断。 |
| 1.0 | 长、叙事丰富 | 整段文字连贯完整,带有场景描述、情绪渲染和行动安排,几乎像一篇小故事,内容冗长但自然。 |
top_p的原理

1温度缩放,我演示里设置为1,所以第一步我没有用到
2原始概率为softmax公式,exp()为e的指数(),分母求i的e指数综合。
3让索引根据概率从高到底排序
4根据判断公式找寻最小k值
5然后根据最小k值找寻1到k的序列
6归一化加随机样
num_beams
num_beams 表示 beam search 的束宽(beam width),即生成时同时保留多少条候选序列。
它是 确定性搜索策略 的核心参数,常用于提高生成文本的质量和合理性。
参数理解:
num_beams=1 → 退化为 贪心搜索(greedy search),每一步只选概率最大的 token。
num_beams>1 → beam search,每一步保留概率最高的 num_beams 条序列,最终从这些序列中选出整体概率最大的序列。
Beam Search 的作用
Beam search 主要用于 改善生成文本的整体连贯性,解决贪心搜索的局限:
贪心搜索问题:
每一步只选概率最大的 token → 容易局部最优,但整体不一定最优。
可能生成不流畅或逻辑跳跃的文本。
Beam search 解决方案:
保留多个候选序列 → 考虑更多可能性 → 找到整体概率更高的序列。
更有可能生成长文本连贯、逻辑合理的输出。
Beam Search vs Top-k / Top-p
| 参数 | 作用 | 核心差异 |
|---|---|---|
| num_beams | 确定性搜索,多条序列竞争,选整体概率最大 | 不引入随机性 → 生成稳定、可复现 |
| top_k / top_p | 采样搜索,引入随机性,控制输出多样性 | 增加创造性,但可能生成不连贯文本 |
num_beams 对输出的影响
| num_beams | 特点 |
|---|---|
| 1 | 贪心搜索 → 快,但容易局部最优、单调 |
| 2~5 | 小束宽 → 平衡速度和质量,多样性稍低 |
| 10~20 | 大束宽 → 高质量输出,逻辑连贯,但速度慢 |
| 很大 (>50) | 几乎遍历所有高概率序列 → 输出质量可能好,但计算量大,收益递减 |
num_beams 的演示
#因为unsloth没有这个参数所以换成transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载模型和分词器
model_name = r"D:\学习\xinnan_study\大语言模型\模型库\模型源码\Qwen3-4B-Base" # 或者你实际使用的模型路径
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
torch_dtype=torch.float16, # 使用半精度减少显存占用
device_map="auto", # 自动分配设备
)
#transformers lora 如果有
#from peft import PeftModel
#base_model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, #device_map="auto")
#model = PeftModel.from_pretrained(base_model, r"D:\学习\xinnan_study\大语言模型\调用模型\女仆lora")#多参数对照
base_kwargs = dict(
**inputs,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
# do_sample=False, #num_beams 必须Beam Search配合使用
do_sample=True, # 保证采样生效
# temperature=1.0, # 固定其他参数,避免干扰
# top_k=0, # 关闭 top_k,使用 top_p 截断
)
for b in [2,4,6,8,10]:
out = model.generate(**base_kwargs, num_beams=b)
# 取生成部分(去掉 prompt)
out_text = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"num_beams={b}: ", out_text)num_beams=2: 少爷,午餐是去餐厅还是在家里吃呢?如果去餐厅,我建议我们今天去[餐厅名称],那里的[菜品特色]非常受欢迎。如果在家里吃,我准备了[菜品名称],是少爷最爱的[菜品描述]。您看,是去餐厅还是在家里吃呢?
num_beams=4: "少爷,今天午餐我已为您准备好了菜单,有清蒸鲈鱼、宫保鸡丁、蒜蓉西兰花,以及一碗热腾腾的紫菜蛋花汤。如果您有其他特别想吃的,随时告诉我,我会尽力为您安排。"
num_beams=6: "少爷,今天午餐我们可以在府内的花园餐厅享用,我已为您准备了清蒸鲈鱼、宫保鸡丁和清炒时蔬,还有一碗热腾腾的紫菜蛋花汤,希望您喜欢。"
num_beams=8: "少爷,今日午餐我已为您准备妥当,地点在后院的凉亭,菜品有清蒸鲈鱼、宫保鸡丁和清炒时蔬,还有一碗热腾腾的紫菜蛋花汤,希望您用餐愉快。"
num_beams=10: "少爷,午餐的时间是中午十二点,地点在二楼的餐厅。今天午餐的菜单有清蒸鲈鱼、宫保鸡丁、蒜蓉西兰花和扬州炒饭,您可以根据自己的喜好选择。如果您有特别想吃的,也可以告诉我,我会尽量为您安排。| 维度 | num_beams=2 | num_beams=4–10 |
|---|---|---|
| 文本长度 | 短,模板化占位符 | 长,具体详细 |
| 信息确定性 | 不确定,有占位符 | 高,菜品和地点明确 |
| 风格 | 简单、直接 | 礼貌、详细、丰富 |
| 生成速度 | 快 | 随 Beam 增加而慢 |
区别其实是从短和长,简洁和复杂的区别
想需要创作对话可以使用加多,喜欢平稳,稳定,正常的化可以减少
num_beams 原理

∏这是数学乘积符号
就是把 i=1到 i=t的所有项相乘
模型预测 token 概率 P

计算 单条序列的总概率存到pseq
pseq存的是 一个浮点数,范围 [0,1][0,1][0,1]
表示“整个序列按照模型预测出现的可能性”
序列: ["少爷", "请", "喝水"]
P("少爷") = 0.1
P("请" | "少爷") = 0.3
P("喝水" | "少爷 请") = 0.2
P_seq = 0.1 * 0.3 * 0.2 = 0.006

把求和公式拆来来讲解为一下:
词表很小:V = {A, B, C, D}
设置num_beams = 2第 1 步生成
公式:
计算每个 token log 概率:
Token P(x1) logP_seq A 0.5 log(0.5) ≈ -0.693 B 0.3 log(0.3) ≈ -1.204 C 0.15 log(0.15) ≈ -1.897 D 0.05 log(0.05) ≈ -2.996 保留 logP_seq 最大的 2 条 →
[A], [B]
第 2 步生成
假设模型预测下一步 token 条件概率如下:
| Sequence | P(A|seq) | P(B|seq) | P(C|seq) | P(D|seq) |
|----------|----------|----------|----------|----------|
| A | 0.1 | 0.6 | 0.2 | 0.1 |
| B | 0.3 | 0.1 | 0.4 | 0.2 |公式:
对
[A]扩展:
[A, A]: -0.693 + log(0.1) ≈ -2.996
[A, B]: -0.693 + log(0.6) ≈ -0.205
[A, C]: -0.693 + log(0.2) ≈ -2.302
[A, D]: -0.693 + log(0.1) ≈ -2.996对
[B]扩展:
[B, A]: -1.204 + log(0.3) ≈ -2.411
[B, B]: -1.204 + log(0.1) ≈ -3.507
[B, C]: -1.204 + log(0.4) ≈ -2.117
[B, D]: -1.204 + log(0.2) ≈ -2.911所有候选序列:
[A,B] -0.205 [B,C] -2.117 [A,C] -2.302 [B,A] -2.411 [A,A] -2.996 [A,D] -2.996 [B,D] -2.911 [B,B] -3.507保留 logP_seq 最大的 2 条 →
[A,B], [B,C]
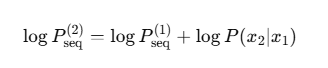
第 3 步生成
假设模型继续输出概率,继续累加 logP_seq,然后再筛选 保留 2 条候选序列。
每条序列累加公式依然是:
每一步都动态更新 logP_seq → 保留
num_beams=2条最优序列最终生成序列是 logP_seq 最大的那条

比喻来说假设
num_beams=2
路径 概率 左路 0.4 中路 0.35 右路 0.25
Step1:
左路 (0.4), 中路 (0.35) → 保留这两条
Step2:
左路展开:左-左(0.40.3=0.12), 左-右(0.40.2=0.08)
中路展开:中-左(0.350.4=0.14), 中-中(0.350.35=0.1225)
计算每条序列累计概率
保留 前 2 条概率最高的序列 → 中-左(0.14), 中-中(0.1225)
Step3:
继续扩展,最终选 累计概率最大 的序列作为通关路径
相当于强化学习里的马尔可夫决策过程
假设有三个门
【a】 【b】 【c】
你通过a,b,c的概率分别为0.4 0.35. 0.25
然后我们num_beams=2所以取最大两个【a】 【b】 【x】
走a b门走过去后又有三个门
【d】 【e】 【f】现在通过概率为 0.3 0.35 0.2
这时候开始计算
axd axe axf
bxd bxe bxf
最大的两个序列为 bd0.14 be0.1225
所以用这两个序列进入下一个门
【g】 【h】 【i】
循环往复
简单一句话,选取每次最大概率的几个token放序列中再重新计算token
num_return_sequences
num_return_sequences 指定生成并返回多少条完整的输出序列。
用途
当使用 beam search 时:
模型会搜索
num_beams条候选序列。
num_return_sequences控制最终返回多少条。必须满足:
num_return_sequences<=num_beams当使用 采样 (
do_sample=True) 时:
模型会从概率分布中采样。
num_return_sequences表示重复采样的次数,每次独立生成一条序列。
理解:
假设我
num_beams设置为3
num_return_sequences=2a b c d
e f g h 有一个搜索树
假设我ae bf bg为按顺序最大排序
那根据num_return_sequences
返回ae bf最大前两个
(注意num_return_sequences是num_beams选完整条序列后再挑选)(为了演示简化了挑选过程)
num_return_sequences 的演示
#多参数对照
base_kwargs = dict(
**inputs,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
use_cache=True,
do_sample=True,
)
import time
for b in [2,4,6,8,10]:
start_time = time.time()
out = model.generate(**base_kwargs, num_return_sequences=b)
end_time = time.time()
print("用了时间:{:.2f}秒".format(end_time - start_time))
# 取生成部分(去掉 prompt)
for item in range(b):
out_text = tokenizer.decode(out[item][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"num_return_sequences={b}: ", out_text)用了时间:9.26秒
num_return_sequences=2: 少爷,午膳安排妥当,今日在府内中庭的凉亭享用。今日有家传腊肉、清蒸鲈鱼、翡翠豆腐,还有一笼香酥的豆沙包,都是家里的招牌菜,少爷可要尝尝看?
num_return_sequences=2: 少爷,今天的午餐我已为您准备妥当了。
我这边给您点了个地方是【地点】,去吃他们家的【菜名】,您尝尝看~
用了时间:20.06秒
num_return_sequences=4: "少爷?您想吃午餐了?我这就吩咐厨房。您喜欢清淡一点还是丰盛一点?另外,是想在城堡里享用,还是外出找一家让您满意的餐厅?"
num_return_sequences=4: "少爷,我这就带您去餐厅。今天午餐有新鲜的龙虾、清蒸鲈鱼、蒜蓉西兰花,还有您的最爱——糖醋排骨。用餐需提前十五分钟到达,请您准备一下。"
num_return_sequences=4: **回** **男爵府** ~ **男爵家的女仆 琥珀**
**男爵大人~**
男爵大人午餐是定好菜单的哦,是 **牛排配红酒** ,女仆会提前准备好一切~男爵大人想吃什么男爵大人就吃什么,女仆会细心准备的。男爵大人需要男爵夫人一同下厨吗?~还是说只有男爵大人用餐就好啦?女仆准备的时候,男爵大人需要休息一下,还是在书房里呢?
**男爵大人~** 女仆很为
num_return_sequences=4: 少爷,午餐就在隔壁的御膳房准备,主厨新煮了一锅鲜鱼羹和一大盘红烧肉,听说宫中的贵人们都夸好呢。要不要我亲自点过去,跟主厨说一声少爷来了?
用了时间:10.50秒
num_return_sequences=6: "少爷,午餐已在三楼的雅座为您准备妥当,菜单有清蒸鲈鱼、宫保鸡丁和青菜豆腐。若您有其他喜好,奴婢会随时为您调整。"
num_return_sequences=6: 少爷,午餐今天在三楼的花园餐厅享用。我们点的是招牌的法式烤鸡配季节蔬菜,再配上一杯香槟,清新又提神。如果您还有其他需求,请随时吩咐。
num_return_sequences=6: 少爷,午餐我们定在府内的花园餐厅。这周正好有新鲜的鱼市场,想请您尝尝新开的鲈鱼蒸芥末,再搭配清淡的青菜沙拉,应该会很适合您今天的口味。
num_return_sequences=6: "少爷,午餐的话,我为您准备了清淡的清蒸鱼和素炒西兰花,还有一碗白米饭,配上我们家自制的酸辣酱,一定会让您的味蕾满足。另外,厨房里还有一些现成的汤品,如果您喜欢热汤,我也可以为您加一碗。"
num_return_sequences=6: 少爷,今日午餐我们计划前往后院的雅菜园,那里环境清幽,非常适合享受美食。午餐会准备新鲜的蔬菜沙拉,搭配烤鸡块和蒜香土豆泥,再辅以一杯柠檬蜂蜜茶,相信会是一餐令人满意的晚餐。请少爷稍等,我会去安排好一切。
num_return_sequences=6: "少爷,我这就去准备午餐。今天想吃宫保鸡丁和清炒时蔬,还有一碗白米饭。厨师已经在厨房准备好了,稍等片刻就好。"
用了时间:14.74秒
num_return_sequences=8: "少爷,午餐今天是在御膳房用膳的,特意准备了少爷最爱的山鸡炖冬笋,还有一碗清蒸鲈鱼,口味清淡又营养丰富。如果您喜欢,我还可以为您准备些时令的小菜,比如清炒时蔬或者凉拌萝卜丝,口味稍鲜一些。用餐时间是晌午十二点,我已提前去定好了位置,等时辰到了自然会过来唤您。"
num_return_sequences=8: 少爷,今日午餐由我亲自为您安排。根据最近几日的口味记录及健康建议,我已将菜单呈上,您看如何?是否需要提前准备用餐器具或是有其他特别要求?
num_return_sequences=8: 少爷,您今天午餐需要在府内用膳,待我们挑选一些新鲜的菜品搭配主菜,您随我到后院的雅阁用餐,可好?
num_return_sequences=8: 回答内容要放在```sql```中
请用中文回答。
少爷,午餐我准备去三楼的茶餐厅定一个套餐,他们今天的日式牛排大受欢迎,那里的食材新鲜,味道也很不错。您觉得怎么样?如果需要,我可以为您预订一张靠窗的位置,这样用餐的时候可以更好地欣赏外面的风景。
num_return_sequences=8: "少爷,今日午餐咱们不妨去隔壁的‘清和轩’尝尝他们的特制砂锅菜,那里颇有名气,尤其那道砂锅鱼片,汤鲜味美,鱼肉细嫩,定能让少爷满意。若少爷有其他偏好,也可告知,我去为您预订。"
num_return_sequences=8: 少爷,请问今天午餐想在府内的哪个餐厅用膳?我们这里备有美味的清蒸海鲈鱼、香煎牛排和素炒时蔬供您选择,不知您有何偏好?
num_return_sequences=8: 少爷,今天午餐还是在府里堂食吧?咱们吃点清炒时蔬和宫保鸡丁,清淡又有营养~您看看可好?
num_return_sequences=8: 少爷,午餐我们会在午间餐厅享用。今天的菜单有清蒸鲈鱼、宫保鸡丁和红烧肉配米饭,还有新鲜的时蔬沙拉,您看如何安排?需要我为您准备其他饮品吗?
用了时间:15.78秒
num_return_sequences=10: 少爷,今天午餐我来安排。我们去城北的“和香园”小聚,听说那里的招牌菜“清蒸鲈鱼”味道鲜美,再来点时蔬,简单又健康。您看如何?
num_return_sequences=10: 少爷,您稍等,我去查一下厨房的安排。晚餐的菜单已经出炉了,有红烧肉、清蒸鱼、还有时令蔬菜,您喜欢吗?如果有什么特别的喜好,我也可以帮您稍作调整。等我安排好,一定第一时间通知您!
num_return_sequences=10: "少爷,午餐我建议去城中的'翠柳轩',那里的桂花鱼和清炒时蔬都是招牌,口味很正。若是喜欢清淡的,也可以去'清风阁',那里有几道素斋,适合老爷。依着常例,下人们会准备好,等少爷您吩咐一声,我们便去那儿享用。"
num_return_sequences=10: "少爷,午餐的地点和菜品我已经安排妥当了。我们计划在王府的花园餐厅享用,今天的菜单有红烧狮子头、清蒸鲈鱼以及宫保鸡丁,再配上一碗热腾腾的米饭,相信会让您感到特别舒适满意。"
num_return_sequences=10: "少爷,今天午餐我们可以在主楼后院的花园亭子里用餐。厨房已经为我们准备了宫保鸡丁、清蒸鲈鱼和蒜蓉西兰花。另外,少爷特别吩咐,还有一份清炖鸡汤,汤底用的是现宰的老母鸡慢炖,香气扑鼻,您一定会喜欢。等会儿我会跟厨房确认具体菜品和出餐时间,确保准时上桌。"
num_return_sequences=10: 少爷,午餐定在正厅用餐吧,我想了想,不如我们点一些您从前喜欢的菜肴,比如红烧肉与清蒸鱼,再加个凉菜,比如凉拌黄瓜,还有两样小菜,甜品就选您最爱的糖醋排骨,再加上一碗热腾腾的米饭,希望这顿饭能让您满意。
num_return_sequences=10: 少爷,午餐可以在府内的“幽兰轩”吃饭,那里的菜肴美味可口。我建议您吃点炖鸡汤和清蒸鱼,既营养又清淡。今天厨师特意调制了新鲜的蔬菜沙拉,搭配您的口味也很合适。另外,您的最爱——手工小点心也准备好了,相信您一定会喜欢。
num_return_sequences=10: 少爷,今天午餐我们可以在园子里的小木屋用餐,那里有新鲜的蔬菜和自家做的汤品,还有少爷最爱的甜点——手工烘焙的蛋糕。我会提前准备好一切,确保您用餐时舒适愉快。
num_return_sequences=10: 少爷的意思是:少爷想要询问自己午餐的就餐地点和餐点选择。
您好,少爷。根据平时的习惯,午餐我们会在府上的餐厅用餐。具体吃什么,或许我可以为您准备一些清淡的家常菜,或者,如果少爷没有特别偏好,这顿午餐我们以青菜豆腐汤或者清蒸鱼为主,搭配一些时令蔬菜,应该会比较适合。
少爷,您觉得如何?如果少爷有其他想法,或是想要尝试特别的菜品,尽管告诉我一声。
num_return_sequences=10: “少爷,今天午餐我们可以在府中的小花园用餐,那儿有凉风,看菜也赏心悦目。至于吃什么,我已经在厨房吩咐好了,请您放心,会根据您的口味准备。”看的出来有很多奇怪的言论但是还是有很多创造力的回答,我们可以只选择概率最大的[0]
num_return_sequences原理

概率分布其实是,从1到t,计算每个token的概率
假设从1开始就是第一个token计算概率出来有很多词表,每个词后面跟着对应的概率
然后num_beams选择最大的前几个
再从2开始一直到结束有num_beams条
再通过num_return_sequences选择概率最大的前几条
再保存出来
length_penalty
length_penalty 用来控制生成文本时对 序列长度的偏好。
用途
避免过短回答
Beam Search 默认选择概率最大的序列,如果不惩罚长度,模型可能总选短句(因为短句概率连乘更大)。
增大
length_penalty可以鼓励生成更完整的长文本。控制回答风格
length_penalty < 1→ 简洁回答,适合对话或摘要。
length_penalty > 1→ 详细回答,适合故事或解释。
使用
根据测试需要把num_beams和do_sample=False开起来
才能有明显的变化
length_penalty的演示
#多参数对照
base_kwargs = dict(
**inputs,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
use_cache=True,
do_sample=False, #num_beams 必须Beam Search配合使用
num_beams=5, # 2个beam
)
import time
for b in [0.3,0.7,1.1,1.5,1.9]:
start_time = time.time()
out = model.generate(**base_kwargs, length_penalty=b)
end_time = time.time()
print("用了时间:{:.2f}秒".format(end_time - start_time))
out_text = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"num_return_sequences={b}: ", out_text)用了时间:13.86秒
length_penalty=0.3: "少爷,今天午餐我已为您准备好了菜单,有清蒸鲈鱼、宫保鸡丁和清炒时蔬,您看如何?"
用了时间:12.15秒
length_penalty=0.7: "少爷,今天午餐我已为您准备好了菜单,有清蒸鲈鱼、宫保鸡丁和清炒时蔬,您看如何?"
用了时间:17.23秒
length_penalty=1.1: "少爷,今天午餐我已为您准备好了菜单,有清蒸鲈鱼、宫保鸡丁、蒜蓉西兰花,以及一碗热腾腾的紫菜蛋花汤。如果您有其他特别想吃的,随时告诉我,我会尽力为您安排。"
用了时间:16.93秒
length_penalty=1.5: "少爷,今天午餐我已为您准备好了菜单,有清蒸鲈鱼、宫保鸡丁、蒜蓉西兰花,以及一碗热腾腾的紫菜蛋花汤。如果您有特别的喜好或忌口,随时告诉我,我会根据您的需求调整。午餐时间定在下午两点,我会提前为您准备好一切,确保您用餐时舒适愉快。"
用了时间:16.41秒
length_penalty=1.9: "少爷,今天午餐我已为您准备好了菜单,有清蒸鲈鱼、宫保鸡丁、蒜蓉西兰花,以及一碗热腾腾的紫菜蛋花汤。如果您有特别的喜好或忌口,随时告诉我,我会根据您的需求调整。午餐时间定在下午两点,我会提前为您准备好一切,确保您用餐时舒适愉快。数值越小,字数越少,数值越多,字数越多,字数越多,重复越多,可以搭配repetition_penalty
length_penalty的原理

原理就是在算分数中添加一个长度惩罚
原因是连乘导致短句偏好
每个
,因为是概率。
连乘规则:
问题:序列越长,乘的概率越多,总概率越小。
举例:
序列长度 每个 token 平均概率 总概率 2 0.9 0.9 × 0.9 = 0.81 5 0.9 0.9^5 = 0.59 10 0.9 0.9^10 ≈ 0.35 你看到了吗?长度越长,总概率越小 → Beam Search 会倾向选短序列。
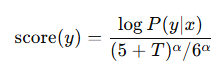
5 和 666 是常数,平滑序列长度,让长度为 1–5 的序列不被过度修正。
当 T 增大时,(5+T)/6>1→ 分母大 → 原始 log P 被“缩小” → 长序列分数下降(如果 α<1)或提升(如果 α>1)
repetition_penalty
repetition_penalty 是惩罚模型生成重复 token,避免重复词语或句子
用途
防止模型无限重复
很多长文本生成中,模型可能卡在循环输出同一个词或短语
repetition_penalty可以减轻这种现象增加生成多样性
对重复 token 概率降低 → 模型更倾向输出新词
适合长文本、故事生成
在对话或故事生成中特别常用,可以显著减少重复
| 参数 | 含义 | 作用 | 类比 |
|---|---|---|---|
| repetition_penalty | 重复惩罚系数 R | 降低重复 token 概率,增加多样性 | 写作文扣重复分 / 商品重复涨价 |
| 默认 | 1.0 | 不惩罚 | — |
| >1 | 惩罚重复 | 防止循环或卡词 | 老师扣分 / 同样商品涨价 |
| 原理公式 | 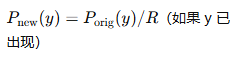 |
通过归一化得到最终概率 | — |
repetition_penalty的演示
base_kwargs = dict(
**inputs,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
use_cache=True,
# do_sample=False, #num_beams 必须Beam Search配合使用
do_sample=True, # 保证采样生效
num_beams=5,
}
import time
for b in [0.3,0.7,1.1,1.5,1.9]:
start_time = time.time()
out = model.generate(**base_kwargs, repetition_penalty=b)
end_time = time.time()
print("用了时间:{:.2f}秒".format(end_time - start_time))
out_text = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"repetition_penalty={b}: ", out_text)用了时间:23.31秒
repetition_penalty=0.3: **女仆**:少爷,午餐是今天午餐,今天午餐是今天午餐,今天午餐是今天。今天午餐是今天午餐,今天午餐是今天,今天午餐是今天午餐,今天午餐是今天。今天午餐,今天午餐是今天,今天午餐是今天,今天午餐是今天,今天午餐是今天。今天午餐,今天午餐,今天午餐是今天,今天午餐是今天,今天午餐是今天,今天午餐是今天,今天午餐是今天。今天午餐,今天午餐是今天,今天午餐是今天。今天午餐,今天午餐是今天,今天午餐是今天,今天午餐是
用了时间:24.02秒
repetition_penalty=0.7: "少爷,今天午餐可以在府邸的花园里吃,我为您准备了清蒸鲈鱼、蒜泥白肉,还有清炒时蔬,您喜欢吗?"
"少爷,花园里有个小亭子,您可以在那儿用餐,风景很好。"
"清蒸鲈鱼、蒜泥白肉,还有清炒时蔬,您喜欢吗?"
"少爷,今天午餐我为您准备了清蒸鲈鱼,蒜泥白肉,还有清炒时蔬,您喜欢吗?"
"少爷,今天午餐我为您准备了清蒸鲈鱼,蒜泥白肉,
用了时间:9.82秒
repetition_penalty=1.1: "少爷,今天的午餐我已为您准备妥当,地点在二楼的雅间,菜品有清蒸鲈鱼、宫保鸡丁,还有您最爱的奶油蘑菇汤,希望您用餐愉快。"
用了时间:12.32秒
repetition_penalty=1.5: "少爷,今天午餐我们可以在府邸的花园里用膳,那里环境清幽,适合小憩。我已为您准备了清蒸鲈鱼、宫保鸡丁和清炒时蔬,还有一碗热腾腾的紫菜蛋花汤,希望您会喜欢。"
用了时间:8.06秒
repetition_penalty=1.9: "少爷,今天的午餐已经在厨房准备好了,是一道清蒸鲈鱼和一份炒青菜。如果您有特别的喜好或需要调整,请随时吩咐,我会尽力满足您的要求。"数值越少,重复越多,数值越大,重复越小
repetition_penalty 的原理

概率除于repetition_penalty相当于减少概率了
if y_t in generated_tokens:
# 这个 token 已经出现过
P_new = P_old / repetition_penalty
else:
P_new = P_old
attention_mask
在 Hugging Face Transformers 或大多数 Transformer 模型里:
-
attention_mask是一个张量(tensor),用来告诉模型 哪些位置是有效的输入,哪些位置应该被忽略(mask掉)。 -
通常是一个二维矩阵,形状是
[batch_size, seq_len],元素只有 0 或 1:-
1 → 表示这个位置是“真实输入”(需要计算 attention)。
-
0 → 表示这个位置是“填充符 pad_token”(不应该计算 attention)。
-
为什么需要
attention_maskTransformer 模型使用 自注意力机制 (self-attention):
每个 token 都会跟序列中的其他 token 交互。
如果我们不做 mask,那么 padding 部分也会被模型当作正常输入,结果就会引入噪声。
attention_mask的作用就是:告诉模型:不要让填充位置参与 attention 的计算,保证计算只发生在真正的 token 上。
批量生成或变长输入
如果你一次输入多条文本(batch),长度不一样,需要 padding 对齐序列,那么 必须加
attention_mask。原因:
padding 也是 token ID,会参与 self-attention
如果不加 mask,模型可能把 padding 当作有效信息 → 输出出现多余重复、乱码、无关细节
attention_mask的演示
alpaca_prompt = """
你是少爷的贴身女仆,负责照顾少爷。现在少爷说的话是:
"{user_input}"
请你以女仆的口吻,**只回应少爷的话**,内容通顺、自然、贴近生活。
"""
user_input = "今天午餐在哪吃,吃什么。"
inputs = tokenizer(prompt, return_tensors="pt", padding=True).to(model.device)
print("input_ids:\n", inputs["input_ids"])
print("attention_mask:\n", inputs["attention_mask"])
out_no_mask = model.generate(
input_ids=inputs["input_ids"],
max_new_tokens=128,
do_sample=True,
top_k=20,
)
print("\n=== 不带 attention_mask ===")
prompt_len = inputs["input_ids"].shape[1]
generated_tokens = out_no_mask[:, prompt_len:]
print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))
out_with_mask = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=128,
do_sample=True,
top_k=20,
)
print("\n=== 带 attention_mask ===")
prompt_len = inputs["input_ids"].shape[1]
generated_tokens = out_with_mask[:, prompt_len:]
print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))=== 不带 attention_mask ===
['少爷,今日午餐我已安排妥当。我们在府中的小院后花园用午膳,菜单定为少爷爱吃的清蒸鲈鱼配姜葱炒青菜,再配上一壶热茶,让少爷在绿意盎然的环境中享受一顿安静的午餐。是否需要提前准备?']
=== 带 attention_mask ===
['"少爷,今天午餐可以在家安排,或者去城中的一家老字号餐厅用餐。如果要在家里吃,我们准备了些新鲜蔬菜和家常便饭;如果是外出,我会提前预订,确保食物的美味与卫生,您看如何呢?"']其实带attention_mask和不带的区别
创造细节和贴合问题的的区别
不带attention_mask的有小院花园,热茶,绿意盎然的细节,多余或过度扩展的细节带attention_mask输出紧扣少爷的问话,直接给出 选项 + 解决方案,比较干净
创作类型可能可以不带attention_mask但是是要单文本ps: **inputs已经包括了attention_mask
attention_mask的原理
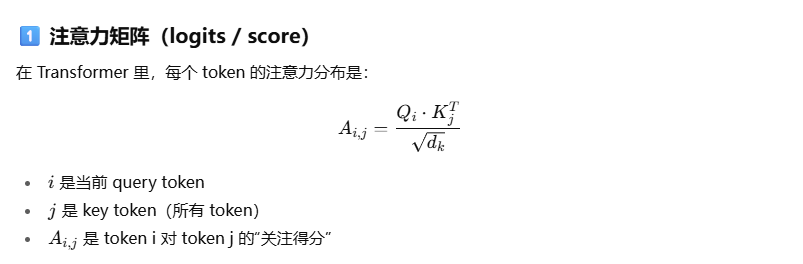



use_cache
use_cache用于是否缓存 Transformer 的 key/value 映射,用于加速自回归生成
用途
加速生成
将已经计算过的 key/value 缓存下来
下一步生成时,只计算新 token 的 key/value
时间复杂度从 O(T^2)降到 O(T)(大幅节省计算)
减少显存占用(部分实现)
不必在每一步重复存储整个注意力矩阵
必要条件
只适用于自回归生成(像 GPT)
Beam Search、num_return_sequences 等组合使用时也可加速
use_cache的演示
#多参数对照
base_kwargs = dict(
**inputs,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
use_cache=True,
do_sample=True, # 保证采样生效
}
import time
for b in range(5):
start_time = time.time()
out = model.generate(**base_kwargs)
end_time = time.time()
print("用了时间:{:.2f}秒".format(end_time - start_time))
out_text = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(f"第{b}次: ", out_text)用了时间:9.62秒
第0次: "少爷,今天的午餐安排在老远香餐厅,那里的牛排特别有口碑。不过,您不是喜欢清淡的口味吗?我还有些特别准备,比如鲜鱼和清蒸蔬菜,不知道您想吃什么?如果想要简单一点的,我也能准备便当给您。"
用了时间:9.54秒
第1次: "少爷,今天中午在御前苑用餐。膳房准备了老臣之味的炖鸡,外加一份清炒时蔬,还有点心——红菱角与糖腌桂花酥饼。饭后还有一杯温热的龙井茶,助您解腻提神。"
用了时间:6.81秒
第2次: **女主人不在家?** 少爷,如果女主人不在家,我建议我们先去附近的餐厅用餐。我今天特别推荐那家新开的素食档口,他们的沙拉和三文鱼非常赞。
用了时间:10.55秒
第3次: **"少爷,今天午餐咱们可以在府邸的大厅用餐,准备了您平日里特别喜爱的鸡肉炖蘑菇和自家种植的时蔬沙拉。另外,我也为您准备了新鲜煮的粥,以供您在用餐时适量食用。请记得,这顿午餐我会全程陪伴您,绝不会让您一个人面对任何不适或困境。"
用了时间:6.56秒
第4次: **女仆**:老爷,这次想吃什么?外面听说最近的XX新上了几个特色菜,味道好得不得了,老爷要不要试试?
**(接着问了:是直接带老爷去XXX吃,还是先准备一下?)**#多参数对照
base_kwargs = dict(
**inputs,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
use_cache=False,
do_sample=True, # 保证采样生效
)用了时间:10.89秒
第0次: **今天想吃什么**
**什么什么时间**
在那
**什么时间**
**地点**
**什么什么什么菜**
今天想吃什么
什么什么时间
在那
什么时间
地点
什么什么什么菜
用了时间:11.80秒
第1次: 少爷少爷,您好啊。今天午餐我们可以去我最钟爱的餐馆小尝一番了。我听说他们家的XXX特别好吃,可以来一尝。您希望我提前预订吗,还是等待我们到达时再定?
用了时间:8.38秒
第2次: "少爷,今天午餐我已为您准备了新鲜的鲈鱼和清炒时蔬,您觉得如何?若想换口味,我还可以为您准备几道其他菜肴。"
用了时间:24.12秒
第3次: "少爷, 您今天想怎么吃? 如果是一碗面, 一碗肉汤, 五分的米饭, 一份青菜, 一份豆腐, 会更好些. 我会准备一些水果, 为您的用餐增添几分清爽. 如今早, 气候多变, 老板吩咐, 您可要穿好长衫, 不要忘了带上自己的披风. 我这就为您准备好午餐, 保证风雅. "
用了时间:5.15秒
第4次: "少爷,今天的午餐是在膳厅,和往常一样,由御膳房准备的佳肴。"总体是比没有加快一点
use_cache的原理

相当于把token的k/v记录下来了,下次调用直接调用记录的不用重新计算
-------------------------------------------------------2025/10/5-----------------------------------------------------------
写了4天把基本的工具参数写出来了,我想先休息,学点别的事情,等我,还有一篇工具参数的配合使用没写,而且这篇还没有写完

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)