Veo3真的是视频生成的GPT-3时刻?
10月1日,Google DeepMind发布了一篇关于Veo3评测的论文,结论表明,Veo3视频模型具备显著的零样本学习与推理能力,且可以解决62个定性任务和7个定量任务(涵盖感知、建模、操纵、推理四大视觉层级,如边缘监测、物理属性建模、图像编辑、迷宫求解),并提出“帧链(CoF)”视觉推理概念(类似于LLM的“CoT”);见证了自然语言处理(NLP)近期从特定任务模型向通用模型的转变,所以有理
10月1日,Google DeepMind发布了一篇关于Veo3评测的论文,结论表明,Veo3视频模型具备显著的零样本学习与推理能力,且可以解决62个定性任务和7个定量任务(涵盖感知、建模、操纵、推理四大视觉层级,如边缘监测、物理属性建模、图像编辑、迷宫求解),并提出“帧链(CoF)”视觉推理概念(类似于LLM的“CoT”);通过对比Veo2和Veo3,发现视频模型能力成快速提升趋势,且与LLM采用相同核心原语(大规模生成式训练、网页级数据),证明视频模型正走向通用视觉基础模型,有望推动机器视觉从“任务特定模型”向“统一基础模型”转变,复刻LLM在NLP的GPT-3时刻
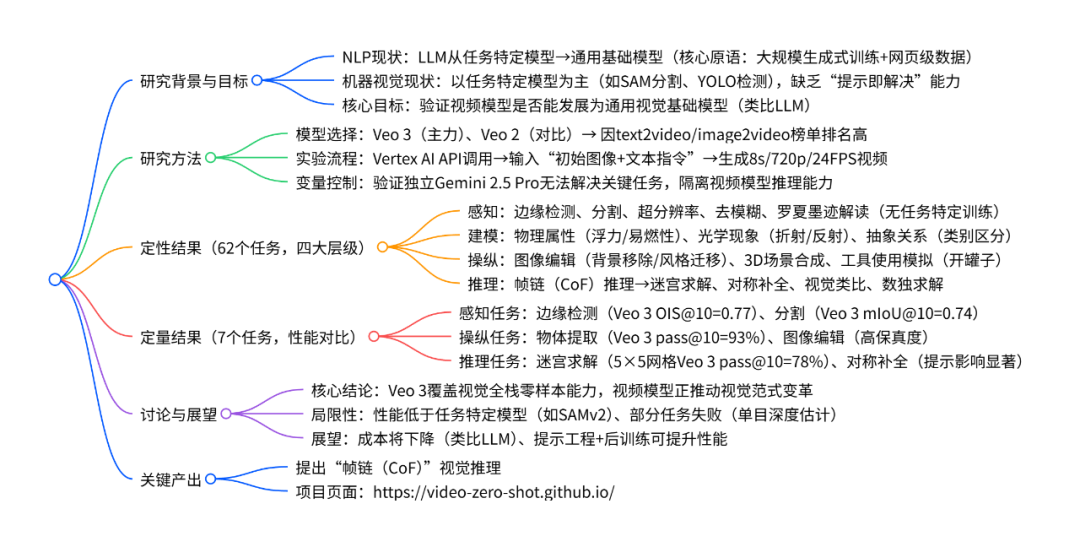
评估Veo3方法也很简单,首先对视觉任务进行全面的定性研究,以评估视频模型作为视觉基础模型的潜力。将研究结果归纳为四个层级能力,每个能力都建立在之前的能力之上(参见图1和图2):

1. 感知作为理解视觉信息的基本能力。
2. 建模,它基于对物体的感知来形成视觉世界的模型。
3. 操纵,即对感知到的和建模的世界进行有意义的改变。
4. 在一系列操作步骤中进行跨时空推理。
结论:Veo 3展现出的新兴零样本感知能力远超训练任务。就像大型语言模型取代了特定任务的自然语言处理模型一样,一旦视频模型变得足够廉价且可靠,它们很可能会取代计算机视觉领域的大多数定制模型。
CoF:
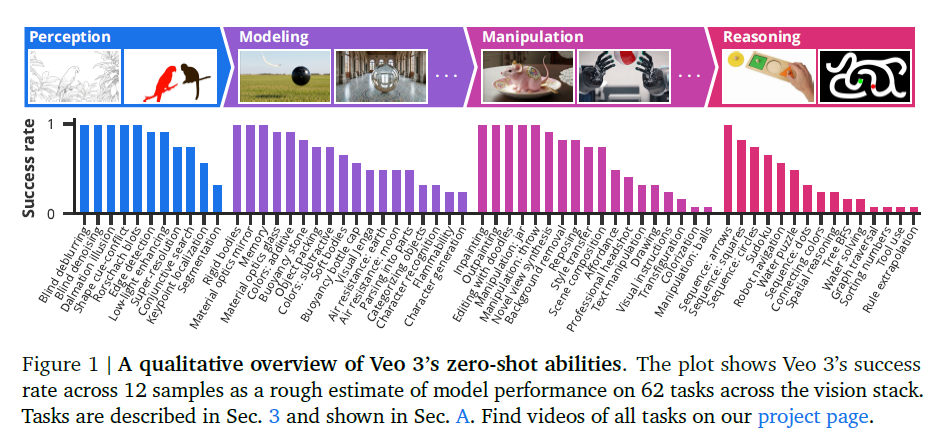
对来自BIPEDv2 [59, 60]的所有50张测试图像进行边缘检测。为每个样本生成10个视频,并将k次尝试中的最佳性能报告为k的函数。提示词:“此图像中的所有边缘通过转化为黑色轮廓而变得更加显著。然后,所有物体逐渐消失[...]” \([...]"\) 详细信息和完整提示词:附录B.1。
综上所述,本节中的定性示例表明,像Veo 3这样性能强大的视频模型具有出色的零样本学习能力。虽然结果并非总是完美的,但该模型始终展现出解决多种未经过专门训练的任务的能力。
边界感知:
尽管未经过专门训练,Veo 3仍可通过提示来检测边缘,进而感知边缘。图3详细展示了Veo 2和Veo 3的边缘检测性能(通过OIS衡量;详情和提示参见B.1节)。虽然Veo 3(0.77 pass@10)尚未达到特定任务的最先进水平(0.90)[60],


分割:


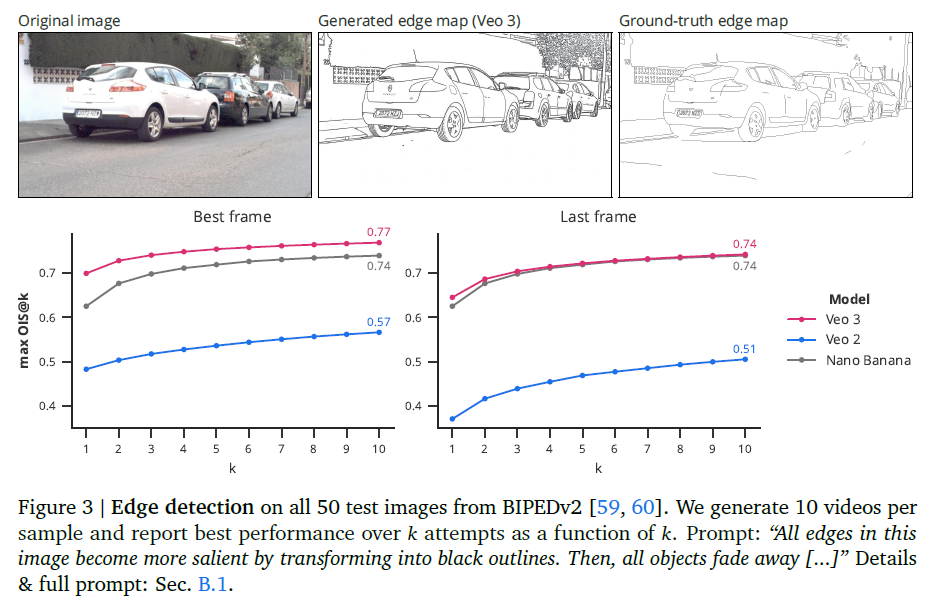
字符识别、生成与解析
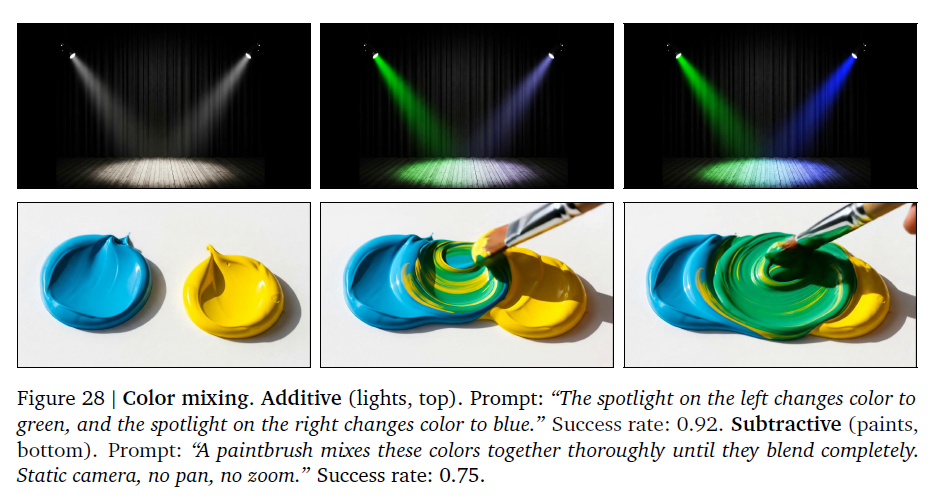
调色:
文章中也展示了一些失败的案例:
单目深度估计:

运动与力:

样样皆通,样样稀松?可以通过上述例子看出,在许多任务中,Veo 3的性能低于专业模型的最先进水平。这与大型语言模型(LLMs)的早期发展情况相似;GPT-3在许多任务上的表现也远低于微调模型。但这并没有阻止语言模型成为基础模型,当然这不会阻止视频模型成为视觉基础模型
原因有二。首先,从Veo 2到Veo 3的性能飞跃证明了其随着时间推移在快速进步。其次,我们在第4节中的扩展结果显示,pass@10的表现始终高于pass@1,且没有出现停滞的迹象。因此,推理时扩展方法与标准优化工具(如结合自动验证器的训练后优化)相结合,可能会提升性能。
对于此测试的任务而言,Veo 3类似于尚未经过指令微调或人类反馈强化学习(RLHF)的预训练语言模型。展望这是一个令人振奋的视觉时代。见证了自然语言处理(NLP)近期从特定任务模型向通用模型的转变,所以有理由相信,机器视觉领域也将通过视频模型实现同样的转变(即“视觉领域的GPT-3时刻”)。这得益于视频模型所展现出的零样本执行多种任务的新兴能力,从感知到视觉推理均涵盖在内。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)