知道要领:一种基于LLM的多智能体系统设计的启发式策略
李震昆1∗†^{1 * \dagger}1∗†南佛罗里达大学zhenkun@usf.edu林书航罗格斯大学shuhang.lin@rutgers.edu李灵瑶∗†^{* \dagger}∗†南佛罗里达大学lingyaol@usf.edu张永锋罗格斯大学yongfeng.zhang@rutgers.edu单智能体LLM遇到硬性限制——有限上下文、角色过载、脆弱的领域转移。传统的多智能体修复方法虽然缓
李震昆1∗†^{1 * \dagger}1∗†
南佛罗里达大学
zhenkun@usf.edu
林书航
罗格斯大学
shuhang.lin@rutgers.edu
李灵瑶∗†^{* \dagger}∗†
南佛罗里达大学
lingyaol@usf.edu
张永锋
罗格斯大学
yongfeng.zhang@rutgers.edu
摘要
单智能体LLM遇到硬性限制——有限上下文、角色过载、脆弱的领域转移。传统的多智能体修复方法虽然缓解了这些问题,但也暴露出新的痛点:问题分解不当、合同模糊以及削弱收益的验证开销。因此,我们提出了“知道要领”(KtR),一个将领域先验转化为算法蓝图层次结构的框架:任务被递归地划分为类型化且由控制器中介的子任务,每个子任务通过零样本或最轻量的有效增强(链式思维、微调、自检等)解决。基于无免费午餐定理,KtR放弃了对通用提示的追求,而选择了有纪律的分解。在背包问题基准测试中(3-8个物品),三个GPT-4o-mini智能体通过修补单一瓶颈智能体,将准确率从3%的零样本提升到大小为5实例的95%。在更困难的任务分配套件中(6-15个任务),六智能体o3-mini蓝图在大小为10时达到100%,大小为13-15时达到84%及以上,相比之下零样本准确率为11%或更低。因此,算法感知的分解加上有针对性的增强可以将 modest models 转变为可靠的合作者——无需不断增大的单体模型。
1 引言
单独的大型语言模型(LLM)智能体通常在其优化的特定领域表现优异(Thirunavukarasu等人,2023;Kasneci等人,2023;Wu等人,2023b),但在实现普遍多功能方面却面临挑战(Zhang等人,2024;Xu等人,2024)。自然的解药是分工合作——将任务拆分为专门化的智能体以协商联合答案——早期框架如混合智能体确实表明,精心编排的团队可以超越其最佳成员的表现(Wang等人,2024;Guo等人,2024;Bo等人,2024)。
然而,大规模审计冷却了这种乐观情绪。首先,每个问题都需要经过精心设计的提示,这需要显著的手动努力。尽管一些多智能体框架似乎取得了令人满意的结果,但当移除评估泄漏和提示过度拟合后,天真智能体群的头条提升滑落到个位数百分比——并且一旦任务需要超过两到三轮协调,甚至可能转为负增长(Pan等人,2025;Zhu等人,2025)。事后分析追踪到不足的原因在于一种反复出现的模式:不当的分解传播了歧义,松散的角色定义造成了盲点或重复,验证层要么调用脆弱的链式思维启发法,要么大幅增加令牌预算,每条额外的消息几乎按轮数的平方复合延迟和成本(Ye,2025;Shu等人,2024)。简而言之,简单地向问题投入更多的“大脑”并不能保证进展;可持续的收益需要有纪律、有原则的系统工程——正是我们的工作旨在弥补的差距。
“知道要领”(KtR)将领域先验转化为算法层次结构:递归地分割任务,直到每个叶节点适合基础LLM的零样本范围或最轻量的增强(链式思维(Wei等人,2022)、小规模微调、自检循环等)。类型化的输入/输出合同由轻量级控制器强制执行,隔离智能体并防止交叉对话、上下文膨胀或无声覆盖。多智能体系统(MAS)构建因此类似于经典管道调整——定位瓶颈,细化分割,并附加最便宜的可行修复。
理论证明了这种方法的合理性。无免费午餐定理(Wolpert和Macready,1997;Wolpert,2021)规定,没有任何单一智能体或编排规则能在所有问题分布上占据优势——没有银弹。稳健性因此必须来自利用领域结构,而不是依赖于越来越大的提示模板。KtR
†{ }^{\dagger}† 第一作者同等贡献。
†{ }^{\dagger}† 对应作者。
通过重用行为已知且优化的经典算法满足这一要求。
我们的实证预览包括以下内容:
-
背包问题(使用轻量级基础模型的概念验证)。在3-8个物品的实例中,GPT-4o-mini仅能达到60%→0%60 \% \rightarrow 0 \%60%→0% 的零样本准确率,而任务级别的微调几乎没有帮助。应用KtR产生了一个三智能体蓝图;在1200个样例上微调“修剪器”,将准确率提升至 $95 % - 70 % $,这表明KtR可以将紧凑、低容量模型转化为高性能的多智能体系统。
-
- 任务分配问题(使用更强的基础模型的概念验证可扩展性)。使用o3mini,六智能体KtR蓝图处理大小为6-15的任务。将一个瓶颈智能体拆分为两个更细的叶子节点,使这些叶子节点分别达到 100%100 \%100% 和 97%97 \%97% 的准确率,并将整体系统准确率提升至所有大小的 ≥84%\geq 84 \%≥84% ——这证明了KtR的收益随着基础模型容量的增长而增长,并且背包问题的结果并非孤立的成功。
我们的贡献体现在两个方面。
- 任务分配问题(使用更强的基础模型的概念验证可扩展性)。使用o3mini,六智能体KtR蓝图处理大小为6-15的任务。将一个瓶颈智能体拆分为两个更细的叶子节点,使这些叶子节点分别达到 100%100 \%100% 和 97%97 \%97% 的准确率,并将整体系统准确率提升至所有大小的 ≥84%\geq 84 \%≥84% ——这证明了KtR的收益随着基础模型容量的增长而增长,并且背包问题的结果并非孤立的成功。
-
KtR框架。通过形式化蓝图层次结构,我们应用基于NFL的算法设计,绕过了已记录的MAS缺陷,简化了组装流程,并缓解了性能瓶颈。
-
- 实证验证。在两个经典的优化问题上,KtR将适度的基础模型转化为能够匹配或超过其微调对应物的系统,同时使用的专用数据少几个数量级。
2 相关工作
多智能体系统(MAS)已被广泛应用于增强LLM解决复杂任务的能力(Qiu等人,2024;Yan等人,2024;Ma等人,2024;Lin等人,2024;Hua等人,2023;Yu等人,2024)。这是因为MAS通常将任务分布在协作以实现共同目标的智能体之间,从而提高效率和适应性。最近的框架如CAMEL(Li等人,2023)通过为智能体分配不同的人格来实现基于角色的合作对话,而AutoGen(Wu等人,2023a)和MetaGPT(Hong等人,2023)则通过结构化的对话循环和预定义的工作流来协调多角色智能体团队。在数学优化中,OR-LLM-Agent可以将自然语言问题描述转换为正式的Gurobi
模型——在现实世界基准测试中实现了85%85 \%85% 的正确解决方案率(Zhang和Luo,2025)。
尽管如此,研究表明,仅仅扩展到基于LLM的MAS往往只能在单智能体基线上带来边际收益(Pan等人,2025)。LLM智能体仍然在上下文管理和一致性方面存在困难,这意味着复杂的多智能体提示可能会失败以实现预期的合作(Bo等人,2024)。最近对流行MAS框架的系统审计识别出14种不同的失败模式(Cemri等人,2025),这些可以归类为三类,包括设计缺陷(例如,角色定义模糊)、智能体间错配(例如,通信失败)和质量控制(例如,没有可靠的检查机制)。
为了解决这些挑战,研究人员提出了多种策略以使基于LLM的MAS更加可靠(Zhu等人,2025;Tran等人,2025)。关键策略之一是改进智能体交互结构(Zhu等人,2025)。例如,AgentDropout框架提出了一种动态智能体剪枝策略,在训练过程中寻求丢弃不太重要的参与者(Wang等人,2025)。另一种有效策略是引入反馈和验证循环(Hong等人,2023)。最近的一项研究显示,具有强角色专业化和迭代反馈机制的框架往往优于那些缺乏这些特征的框架(Anonymous,2025)。此外,系统评估表明通信拓扑很重要:精心设计的智能体间协议可以显著提高复杂任务上的集体表现(Zhu等人,2025)。
虽然现有的多智能体框架和策略已经展示了显著的进步(Li等人,2025;Hong等人,2023;Zhu等人,2025),但它们在动态角色重新分配和高效智能体间通信方面仍面临挑战。这些局限性在解决复杂任务时尤为明显,例如NP难优化问题。为了弥补这一差距,我们的工作提出了一种启发式策略,将领域特定规则和算法直接嵌入智能体协调中。这种方法允许实时角色适应和任务分解,特别是在传统MAS框架常常挣扎的数学优化背景下。
3 方法论
3.1 框架设计——知道要领
我们提出了启发式框架“知道要领”。该框架提供了一种结构化的方法来设计利用LLM的专用MAS。这个启发式重点在于将已知的有效程序或算法翻译成连贯的多智能体架构。如图1所示,核心思想是将复杂的总体任务分解为其基本计算阶段。每个阶段随后映射到一个良好制定的子任务,旨在使其对单个智能体可处理。这些专业化的智能体随后被编排以反映原始程序的数据/控制流,从而有效地将问题解决逻辑嵌入多智能体系统。以下定义形式化了此框架的组件。
定义3.1。一个良好制定的任务是一个元组 T=(I,O,R)T=(I, O, R)T=(I,O,R),包含以下内容:
- 输入域 I: 所有可接受输入的明确描述
-
- 输出余域 OOO: 所有可接受输出的明确描述
-
- 需求关系 R⊂I×OR \subset I \times OR⊂I×O : 一种关系,对于每个输入 x∈Ix \in Ix∈I 它明确定义了子集 R(x)⊂OR(x) \subset OR(x)⊂O 作为被认为是正确的输出集合。
- 定义3.2。一个工作流蓝图 B=(T,P)\mathcal{B}=(\mathcal{T}, \mathcal{P})B=(T,P) 包含以下内容。
-
- 一组有限的良好制定任务 T=\mathcal{T}=T= {T1,⋯ ,Tn}\left\{T_{1}, \cdots, T_{n}\right\}{T1,⋯,Tn}。
-
- 一个编排协议 P\mathcal{P}P,它指定:
-
- 控制流图,确定何时调用每个 TiT_{i}Ti。
-
- 数据依赖边,将某些任务的输出映射到其他任务的输入。
-
- 实现 B\mathcal{B}B 的端到端目标所需的任何全局不变量、错误处理规则或通信通道。
- 定义3.3。给定一个工作流蓝图 B=\mathcal{B}=B= (T,P)(\mathcal{T}, \mathcal{P})(T,P),一个分解选择一个任务 T∈TT \in \mathcal{T}T∈T 并将其替换为一个子蓝图 BT=(TT,PT)\mathcal{B}_{T}=\left(\mathcal{T}_{T}, \mathcal{P}_{T}\right)BT=(TT,PT),使得以下条件成立。
-
- 每个任务 T′∈TTT^{\prime} \in \mathcal{T}_{T}T′∈TT 都严格比 TTT 简单。
-
- 综合协议 P′\mathcal{P}^{\prime}P′,通过将 PT\mathcal{P}_{T}PT 嵌入到 P\mathcal{P}P 中代替 TTT 获得,保留所有 TTT 的外部接口。
分解的结果是一个新蓝图 S′=(T′,P′)\mathcal{S}^{\prime}=\left(\mathcal{T}^{\prime}, \mathcal{P}^{\prime}\right)S′=(T′,P′),其中 T′=(T\{T})∪\mathcal{T}^{\prime}=(\mathcal{T} \backslash\{T\}) \cupT′=(T\{T})∪
TT\mathcal{T}_{T}TT。我们将此过程记录为
- 综合协议 P′\mathcal{P}^{\prime}P′,通过将 PT\mathcal{P}_{T}PT 嵌入到 P\mathcal{P}P 中代替 TTT 获得,保留所有 TTT 的外部接口。
B∼DB′ \mathcal{B} \stackrel{D}{\sim} \mathcal{B}^{\prime} B∼DB′
定义3.4。设 M\mathcal{M}M 是一组LLM模型。如果一个模型在 M\mathcal{M}M 内部经过可选增强(例如,链式思维提示、工具调用、自我反思循环或微调)后,能够以高且经实证验证的准确性满足需求关系 RTR_{T}RT,那么该良好制定的任务 TTT 就被称为 M\mathcal{M}M-可处理。
定义3.5。给定一组LLM模型 M\mathcal{M}M 和一个蓝图 B\mathcal{B}B,一个 M\mathcal{M}M-可处理层次结构是一系列分解
B∼D1B1∼D2⋯∼DnBn \mathcal{B} \stackrel{D_{1}}{\sim} \mathcal{B}_{1} \stackrel{D_{2}}{\sim} \cdots \stackrel{D_{n}}{\sim} \mathcal{B}_{n} B∼D1B1∼D2⋯∼DnBn
使得终端蓝图 Bn\mathcal{B}_{n}Bn 中的每个任务在定义3.4的意义上都是 M\mathcal{M}M-可处理。
定义3.6。给定一组LLM模型 M\mathcal{M}M 和一个 M\mathcal{M}M-可处理蓝图 B=(T,P)\mathcal{B}=(\mathcal{T}, \mathcal{P})B=(T,P),系统实例化是通过以下方式实例化 B\mathcal{B}B 成为一个多智能体系统(MAS)。
- 我们为每个可处理任务 Ti∈T_{i} \inTi∈ T\mathcal{T}T 创建一个代理 AiA_{i}Ai,并将任何必要的增强与代理捆绑在一起。
-
- 我们通过在代理之间进行消息传递或函数调用来实现编排协议 P\mathcal{P}P,同时保留数据依赖性和控制流。
算法1 “知道要领”(KtR)伪代码
过程 KnowTheRopes ((T,M))((T, \mathcal{M}))((T,M))
(B←CreateBLUEPRINT({T})(B \leftarrow \operatorname{CreateBLUEPRINT}(\{T\})(B←CreateBLUEPRINT({T}), trivial_protocol)
while (∃U∈B)(\exists U \in B)(∃U∈B).tasks (&¬MTractable(U,M))(\& \neg \operatorname{MTractable}(U, \mathcal{M}))(&¬MTractable(U,M)) do
(U′←ChooseTaskToDecompose(U))(U^{\prime} \leftarrow \operatorname{ChooseTaskToDecompose}(U))(U′←ChooseTaskToDecompose(U))
(Bsub ←DESIGNSubBLUEPRINT(U′))(B_{\text {sub }} \leftarrow \operatorname{DESIGNSubBLUEPRINT}\left(U^{\prime}\right))(Bsub ←DESIGNSubBLUEPRINT(U′))
(B←EmbedSUBBlueprint(B,U′,Bsub ))(B \leftarrow \operatorname{EmbedSUBBlueprint}\left(B, U^{\prime}, B_{\text {sub }}\right))(B←EmbedSUBBlueprint(B,U′,Bsub ))
end while
MAS (←)(\leftarrow)(←) InSTANTIATESYSTEM()
for all (V∈B)(V \in B)(V∈B).tasks do
(aug←)(\operatorname{aug} \leftarrow)(aug←) SelectAugmentations ((V,M))((V, \mathcal{M}))((V,M))
agent (←CreateAgent(V,M)(\leftarrow \operatorname{CreateAgent}(V, \mathcal{M})(←CreateAgent(V,M), aug ())())())
MAS.AddAgent(agent)
end for
IMPLEMENTPROTOCOL(MAS, (B)(B)(B).protocol)
return MAS
end 过程
我们的方法。对于给定的(良好制定的)任务 TTT 和一组将用于解决任务的LLM模型 M\mathcal{M}M,我们执行以下操作。(参见算法1和图1)
-
定义初始蓝图 B=(T,P)\mathcal{B}=(\mathcal{T}, \mathcal{P})B=(T,P),其中 T={T}\mathcal{T}=\{T\}T={T} 且 P\mathcal{P}P 是平凡的。
-
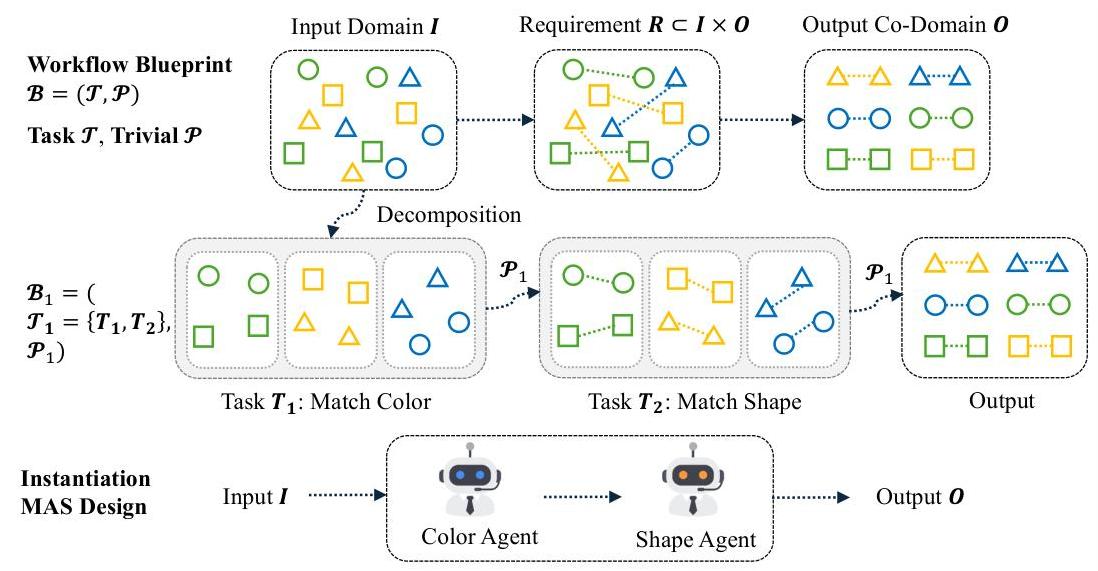
图1:说明“知道要领”(KtR)策略:基于启发式和先验知识的复杂任务分解为子任务,每个子任务实例化为多智能体架构中的协调LLM智能体。 -
根据领域启发式、先验知识和特定任务的实验,我们构建一个M-可处理层次结构
B∼D1B1∼D2⋯∼DnBn \mathcal{B} \stackrel{D_{1}}{\sim} \mathcal{B}_1 \stackrel{D_2}{\sim} \cdots \stackrel{D_n}{\sim} \mathcal{B}_n B∼D1B1∼D2⋯∼DnBn -
将终端蓝图 Bn\mathcal{B}_nBn 实例化为一个多智能体系统 MAS(Bn\mathcal{B}_nBn, M\mathcal{M}M),以针对初始任务 TTT。
这三个步骤的过程——原子蓝图、可处理层次结构构建和系统实例化——提供了一条从任意复杂任务到可部署多智能体解决方案的原理路径,其正确性取决于已明确验证的模型能力。为了展示“知道要领”框架在创建此类专用MAS方面的实际应用和有效性,我们提供了两个案例研究。在每个案例中,一个复杂问题的算法解决方案被分解为一个M-可处理层次结构并实例化为一个MAS。
4 实验设计
4.1 概念验证:0/1 背包问题(KSP)
为了清楚地验证KtR,我们从经典的NP难背包问题(KSP)开始——这是资源分配、物流和投资规划中的一个典型问题。通过故意使用轻量级、通用的GPT-4o-mini作为每个智能体的骨干,我们建立了一个适度的基线,让我们可以突出KtR的多智能体编排如何将小型模型的能力放大远远超出其单人限制。
以下是问题的数学表述,而更详细的解释及算法解决方案可以在附录B中找到。
4.1.1 问题表述
对于大小为N的背包问题,其输入涉及一个重量向量 w⃗=(w1,⋯ ,wN)\vec{w} = (w_1, \cdots, w_N)w=(w1,⋯,wN),一个价值向量 v⃗=(v1,⋯ ,vN)\vec{v} = (v_1, \cdots, v_N)v=(v1,⋯,vN),以及一个容量 WWW。为了表述目标,我们引入状态向量 x⃗=(x1,⋯ ,xN)∈{0,1}N\vec{x} = (x_1, \cdots, x_N) \in \{0, 1\}^Nx=(x1,⋯,xN)∈{0,1}N,即其所有项取值在 {0,1}\{0, 1\}{0,1}。然后问题的目标是找到以下值
Z=maxx⃗∈{0,1}Nx⃗⋅w⃗≤Wx⃗⋅v⃗. Z = \max_{\vec{x} \in \{0, 1\}^N \atop \vec{x} \cdot \vec{w} \leq W} \vec{x} \cdot \vec{v}. Z=x⋅w≤Wx∈{0,1}Nmaxx⋅v.
4.1.2 KtR 多智能体设计
根据KtR启发式方法,附录B.2中的KSP迭代动态规划解决方案被分解为三个专业智能体的任务,如下所述。为每个单独的智能体设计的提示语附在附录D中。
系统控制器:控制器初始化一组可行状态 S0={(0,0)}S_0 = \{(0, 0)\}S0={(0,0)} 并控制 kkk 从1到 NNN 的循环。对于每个 kkk,它发送 Sk−1S_{k-1}Sk−1 和 (wk,vk)(w_k, v_k)(wk,vk) 到工作者智能体,然后将结果加 WWW 发送到修剪者智能体。控制器随后将修剪者智能体的输出与 Sk−1S_{k-1}Sk−1 取并集以获得 SkS_kSk。一旦所有项目都被处理完,控制器调用报告者智能体获取最终结果。
工作者智能体:此智能体负责通过以下公式进行迭代状态扩展:
Sadd={(w+wk,v+vk) 对于所有 (w,v)∈Sk−1}S_{a d d}=\left\{\left(w+w_{k}, v+v_{k}\right)\text { 对于所有 }(w, v) \in S_{k-1}\right\}Sadd={(w+wk,v+vk) 对于所有 (w,v)∈Sk−1}。
修剪者智能体:此智能体根据以下公式执行修剪任务:
Strimmed ={(w,v)∈Sadd∣w≤W} S_{\text {trimmed }}=\left\{(w, v) \in S_{a d d} \mid w \leq W\right\} Strimmed ={(w,v)∈Sadd∣w≤W}
报告者智能体:此智能体执行解决方案报告。它在最终状态集 SNS_{N}SN 中查找具有最大值的元素。
4.2 可扩展性验证——任务分配问题(TAP)
基于前一部分——在KtR已经在紧凑的GPT-40-mini上拉伸了背包基线的能力——我们现在测试KtR的可扩展性。我们将骨干升级到更大的o3-mini,并处理更具挑战性的任务分配问题(TAP),演示了该框架的性能随着底层模型的容量同步提升。
再次,下面只呈现数学表述,详细信息请参考附录B。
4.2.1 问题表述
对于大小为N的任务分配问题,其输入涉及一个 N×NN \times NN×N 成本矩阵 C=(Cij)N×NC=\left(C_{i j}\right)_{N \times N}C=(Cij)N×N。我们用 SN\mathfrak{S}_{N}SN 表示n个元素的排列集合,或者等价地,表示从集合 {1,2,⋯ ,N}\{1,2, \cdots, N\}{1,2,⋯,N} 到自身的双射集合。问题的目标是找到以下值:
Z=maxσ∈SN(∑i=1NCiσ(i)) Z=\max _{\sigma \in \mathfrak{S}_{N}}\left(\sum_{i=1}^{N} C_{i \sigma(i)}\right) Z=σ∈SNmax(i=1∑NCiσ(i))
4.2.2 KtR 多智能体设计
附录B.4中的算法现在映射到我们KtR方法下的MAS。如第5.2.2节所述,基于智能体任务的测试结果和启发式论证,我们进一步分解原始系统设计中的任务以进一步提高性能。最终的系统设计包含以下六个智能体。设 NNN 为问题的大小,CCC 为原始成本矩阵。
行约简器:此智能体将矩阵 CCC 的行约简以获得 C′C^{\prime}C′。
列约简器:此智能体进一步约简 C′C^{\prime}C′ 的列以获得 C′′C^{\prime \prime}C′′。
匹配器:此智能体在约简矩阵 C′′C^{\prime \prime}C′′ 中找到最大的零集合,使得任何两个零不在同一行或列。设 LLL 为最大集合中的零的数量。
绘图器:当 L<NL<NL<N 时,基于匹配器的输入,绘图器被提示找到最小的行和列集合覆盖所有零。
规范化器:接收绘图器的输入,规范化器在选定的行和列之外创建更多的零以获得更新后的矩阵 C′′′C^{\prime \prime \prime}C′′′。
报告器:当 L=NL=NL=N 时,报告器将匹配器找到的最大零集合对应的原始成本矩阵 CCC 的条目值相加,并将该总和作为问题的最终解报告。
系统控制器安排行约简器和列约简器的线性任务,然后控制一个循环:匹配器首先找到一组零,控制器检查零的数量 LLL 是否等于问题的大小 NNN。如果是,则循环中断,并将零的位置发送给报告器以输出最终结果。否则,调用绘图器找到最小的线条集合覆盖零,然后规范化器跟随以创建更多的零。然后控制器迭代循环并将更新后的矩阵发送给匹配器。
5 实验结果
我们的实验协议分为两个阶段。首先,我们在一系列基线模型上运行统一基准测试——包括几种GPT和Llama变体——以固定每个任务的参考点。第二阶段则按目标划分:对于KSP,我们提供概念验证,而对于TAP,我们提供可扩展性验证。对于真实值,我们使用python代码随机生成问题,然后使用Google OR-Tools(Perron和Furnon,2022)如附录C中所述生成解决方案进行比较。
5.1 KSP实验结果
5.1.1 基线LLM性能
图2显示了基线LLM在多个难度级别上的性能。在KSP场景中,跨难度级别(从3到8个项目)的准确性揭示了所测试的LLM之间的显著性能差异。其中,GPT-o3-mini作为一种推理模型,始终表现出优越的准确性。模型GPT-4.1在较小的同类模型GPT-4.1-mini和它的初级版本GPT-4o-mini中表现出色。其他
LLMs,包括Claude-haiku、Llama和通义千问系列也显示出性能下降,尤其是在更高难度级别时波动更大。同时,最终的KtR多智能体系统的性能也在图2中绘制出来。对比显示,KtR显著提升了性能,验证了其有效性。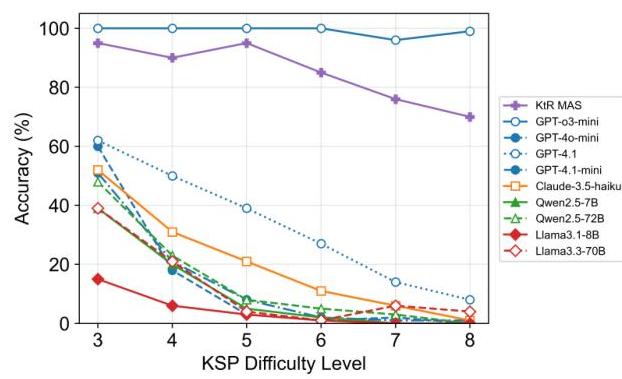
图2:单个LLM的KSP基线性能以及KtR多智能体系统。
5.1.2 多智能体性能
基于图2,GPT-4o-mini在4项实例开始时表现出明显的性能下降,突显了其在更复杂场景中的有限可扩展性;因此,我们选择它作为KtR框架设计的基线模型。图3进一步展示了由此产生的多智能体系统以及我们提出的策略的实验结果。
单个LLM性能。我们为GPT-4o-mini作为单个智能体解决KSP建立了两个基线性能。首先,零样本的GPT-4o-mini直接被提示处理KSP实例。如图3B所示,其准确性从3项的60%60 \%60%下降到8项的0%0 \%0%。其次,我们评估了微调后的GPT-4o-mini(独立)。图3C表明,微调相较于零样本有所改善,但对于8项的KSP,准确率仍仅为3%3 \%3%。
标准MAS性能。按照我们的KtR启发式方法,我们将KSP算法映射到MAS设计,如图3F所示。最初,每个智能体都由标准的非微调GPT-4o-mini驱动。该标准MAS的性能如图3F所示。其性能从3项的18%18 \%18%下降到8项的4%4 \%4%。这一初步结果表明,如果不增强智能体的能力,MAS无法有效处理任务。
我们单独分析每个智能体(图3E),发现一个单一的瓶颈:修剪器。其准确性随着可行状态集SkS_{k}Sk(参见B.2节)的增长而崩溃——对于1-8个状态为54%54 \%54%,对于9-16个状态为24%24 \%24%,对于17-24个状态为7%7 \%7%,对于25-32个状态仅为5%5 \%5%。由于算法每次状态循环一次,即使每轮的小误差也会累积,这种累进不准确最终导致整个运行失败。
增强MAS性能。为了消除瓶颈,我们微调了修剪器的GPT-4o-mini主干(图3G,突出显示为“增强型修剪器”)。准确性跃升至1-8个可行状态的95%95 \%95%,9-16个状态的89%89 \%89%,17-24个状态的81%81 \%81%,以及25-32个状态的67%67 \%67%(图3H)。添加轻量级的自我检查提示——让模型审核自己的答案——保持或略微提高了这些收益。用微调过的修剪器替换瓶颈,将端到端的KSP准确性提升至接近饱和的程度(图3I):3项实例为95%95 \%95%,4项为90%90 \%90%,5项为95%95 \%95%,6项为85%85 \%85%,7项为76%76 \%76%,8项为70%70 \%70%。因此,单个有针对性的升级将KtR转变为一个问题规模扩大时始终高性能的求解器。
5.2 TAP实验结果
5.2.1 基线LLM性能
图4展示了多个LLM在TAP任务上的基线性能,跨越多个难度级别(从3到8个任务)。结果显示模型能力存在显著差异。唯一的推理模型GPT-4o-mini始终优于其他所有模型,在较低难度级别表现出强准确性,尽管随着任务复杂度增加,其性能有所下降。相反,GPT-4.1在所有难度级别上表现出中等但稳定的准确性,超过了其小型化版本。其他模型,包括Claude-3.5-Haiku、通义千问2.5和Llma-3变体,表现出中间性能且存在波动。
我们观察到单智能体模型(例如GPT-3-mini、GPT-4-mini、GPT-4.1)在TAP级别7-8时准确率降至30-50%,而KtR MAS保持接近100%100 \%100%的稳定性能,甚至超越推理模型,展示了其卓越的鲁棒性和泛化能力。
5.2.2 多智能体性能
基于图4,GPT-o3-mini在所有评估任务中始终优于其他LLM,成为我们后续实验的选择。我们的目标是评估所提策略的可扩展性,并研究其性能如何随着任务难度增加而演变。图5展示了MAS设计及相应的实验成果。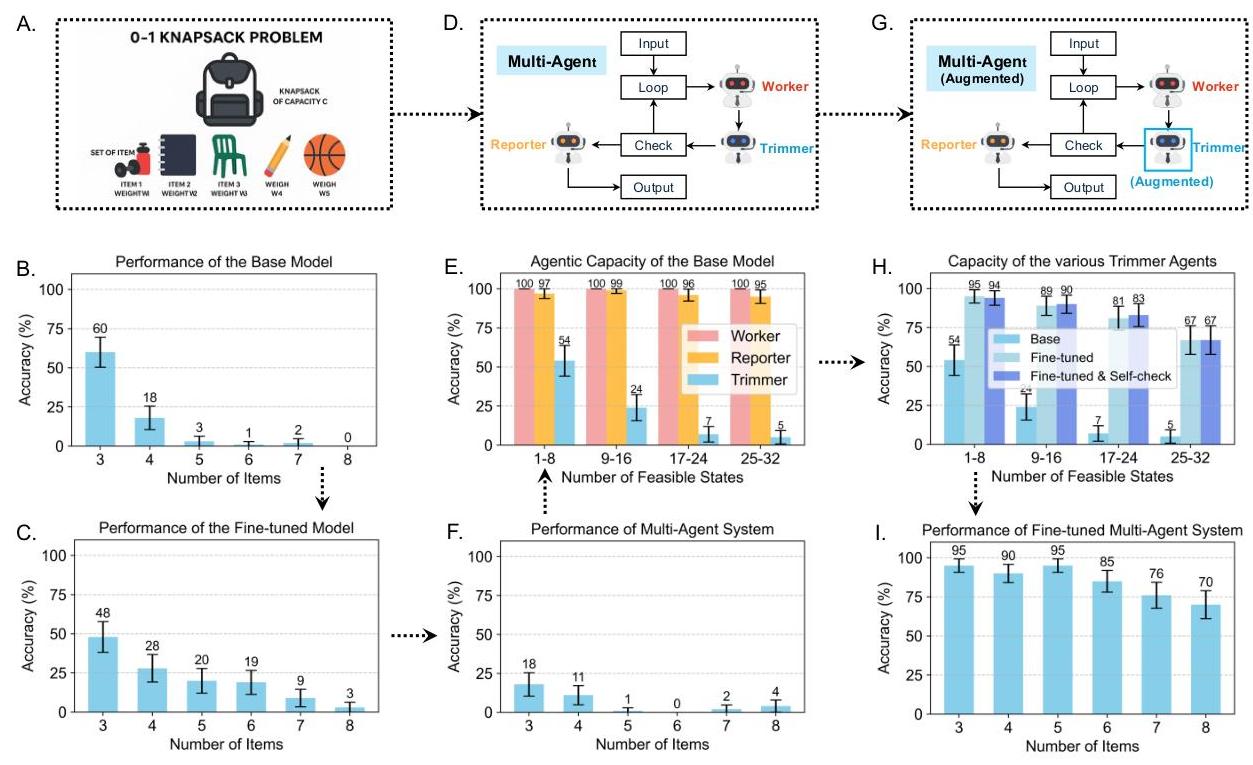
图3:KSP对KtR策略的评估。B:基线模型的零样本准确性。C:轻微、任务特定微调后同一模型的零样本准确性。D & G:未增强(D)和增强(G)的MAS蓝图。E:增强前的各智能体准确性,揭示系统的瓶颈。H:应用于瓶颈智能体的两项针对性增强——任务级别微调和自我检查提示——带来的提升。F & I:两种蓝图对应的测试准确性。
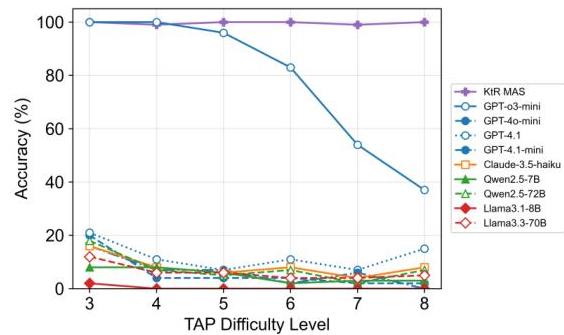
图4:单个LLM和KtR多智能体系统的TAP基线性能。
实验结果采用基于启发式的途径获得。
单LLM性能。再次,我们评估了使用o3-mini作为单智能体的基线性能。o3-mini模型达到了相对较高的性能(83%),但随着图5B所示迅速衰减:大小为9的问题准确率为37%,大小为12的问题准确率为21%,最终大小为15的问题准确率降至3%。
智能体性能和进一步分解。受匈牙利算法(Kuhn, 1955)指导,我们的第一个KtR蓝图将每个步骤映射到单个智能体;附录B.4中的步骤3依赖于单独的Cover Seeker而非后来的“Matcher + Painter”组合。这一基线得分分别为98 %(大小为6)、88 %(大小为9)、78 %(大小为12)和56 %(大小为15),验证了该方法。
然后,我们对两个区间内的智能体进行了压力测试,矩阵大小分别为6-10和11-15,以确定弱点。一次性智能体表现完美:Row Reducer和Reporter在两个区间均达到100%,Column Reducer达到100%/92%。Normalizer保持在99%/94%,但Cover Seeker降至97%/84%。由于Zero Seeker在主循环内操作,其错误会累积,使其成为较大TAP实例的明显瓶颈。
然后,我们对B.2部分中的步骤3进行两步分解:步骤3.1. 找到一个最大的零元素集合,使得其中任意两个零元素不共享相同的行或列;步骤3.2. 找到一个最小的行和列集合覆盖所有零元素。
我们认为这种分解是有益的,原因如下。首先,通过数学论证,子任务3.1和3.2的集合大小相匹配。其次,启发式论证表明,知道最大零元素集合可以简化寻找最小集合的任务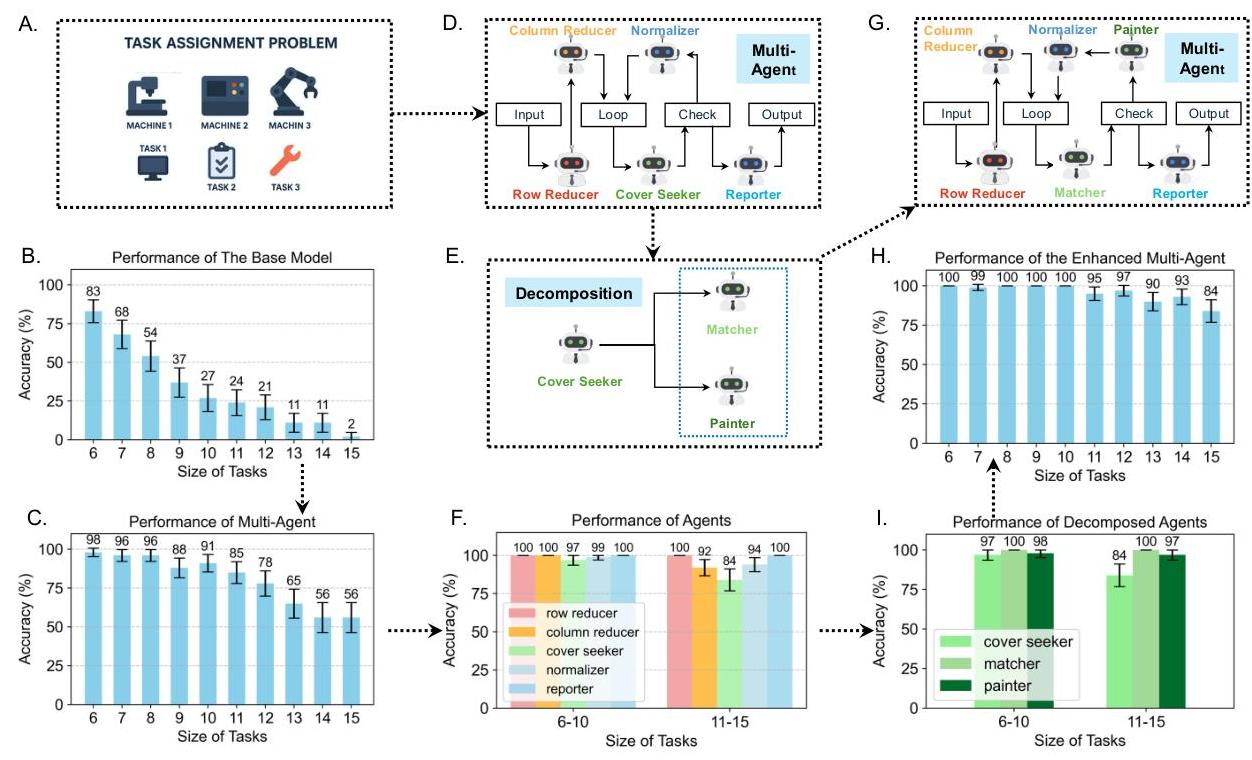
图5:TAP对KtR策略的评估。B:基线模型的零样本准确性。D:源自匈牙利算法的初始蓝图;其端到端准确性如C所示。F:此蓝图内各智能体的准确性,促使更精细的分解如E所示。I:分解前后各智能体准确性的并列比较。G:最终分解蓝图,其整体准确性如H所示。
经验得到了回报,如图5I所示,Matcher在两个难度区间均达到100%的准确性,而Painter则攀升至98%和97%——相比原始Cover Seeker的97%和84%有了显著提升。
最终MAS性能。借助精炼的分解,我们部署了一个六智能体系统(图5H),几乎完美解决了大小为6–10的实例:几乎100%的准确性,相较于o3-mini零样本的83%-27%。它在大小为11–15的任务中保持高绩效(95%、97%、90%、93%、84%);即使在大小为15时的下降也远超3%的零样本基线,突显了我们的多智能体架构的巨大容量提升。
6 讨论
在两个案例研究中,我们展示了有纪律的分解结合诊断驱动的增强可以将低容量的LLM提升为可靠的解决问题者——而且随着底层模型的改进,收益还会进一步增长。
KSP的概念验证。基线GPT-4o-mini准确性随着实例规模的增加而崩溃,而一个简单的三智能体蓝图提供的缓解作用甚微。智能体级别的配置文件指出了Trimmer作为唯一瓶颈。仅对该智能体进行微调——1200个逐步示例,其他地方没有变化——将端到端准确性从≤18%提升到≥70%,在规模为3–8的情况下达到峰值95%。这些结果验证了KtR的“识别→隔离→增强”周期:一个有针对性的升级可以在单智能体和无针对性的多智能体基线失败时拯救一个小的通用模型。
TAP的可扩展性验证。重复该程序使用更强的o3-mini模型,我们从五智能体设计开始。直接测试确定了一个综合规划任务,限制了整体性能。KtR规定递归细化:我们将该任务拆分为两个更简单的、类型化的子任务,每个子任务都可以由基础模型处理。在困难规模(11-15)上的准确性从单智能体的最低11%提升到多智能体的≥84%,而规模6-10达到100%。因此,随着模型容量的扩展,
KtR继续放大它而不是饱和。
除了这些演示,我们还想概述几条研究线索,以便在未来深化这一方法:
- 模型组合分配。许多叶节点远低于旗舰模型的前沿;混合较轻或领域调优的LLM将削减成本,同时保持准确性,让控制器为每个任务选择“足够”的容量。
-
- 复杂性-容量估计。用原则性评分取代经验法则分裂,该评分(i)量化任务难度(ii)预测LLM在增强后的容量,实现数据驱动的分解。
-
- 端到端自动化。有了上述指标,最终目标是设计一个系统,自动化整个KtR方法论:分解任务、评估容量、组装多智能体系统以解决问题。
7 局限性
尽管展示了显著的性能提升,我们的研究有几个局限性应该指导未来的工作。
狭窄的任务范围。我们在两个典型的优化问题(背包问题和任务分配问题)上评估了KtR。虽然选择这些任务是为了说明概念验证和可扩展性验证,但这些任务具有结构良好的目标函数和小的动作空间;推广到开放领域的推理或多模态设置尚未测试。
合成数据和理想化输入。所有问题实例都是随机生成并完全指定的。真实世界的输入(噪声、部分观测或对抗性)可能会降低分解质量和智能体可靠性。
成本和延迟权衡。虽然每个智能体的推理成本正在下降趋势,但我们没有量化大量智能体群的绝对墙钟延迟、能耗或控制器开销。
瓶颈识别启发式。我们通过保留准确性筛选来定位瓶颈子任务;这假设了廉价的真实标签可用。无标签的自动瓶颈检测是一个开放问题。
8 伦理考虑
通过扩展智能体群体来放大决策能力可能会加剧基础模型中现有的偏差;
我们没有进行偏差或公平性审计。解决这些局限性——特别是扩展到结构较少的领域和基准测试真实世界的资源使用——将是建立KtR框架更广泛的实用性和安全性的关键。
A 附录:加权无免费午餐定理
在本节中,我们介绍了一个加权版本的无免费午餐定理。作为动机,当前的MAS设计方法经常会导致过于通用的解决方案,这些解决方案在特定和复杂的任务上可能表现出次优性能。这种次优性部分源于缺乏特定领域的归纳偏见。为了形式化这一点,我们提出了一个加权版本的无免费午餐(NFL)定理。以下演示,利用加权版的无免费午餐定理,定量说明了针对目标领域定制的归纳偏见如何提高性能。
在非均匀先验集中于特定子集的函数上,专用学习算法比通用算法实现严格更低的期望风险。
请注意,无免费午餐定理已被研究界知晓超过二十年。这里我们展示的是对标准陈述的修改,以更好地适应我们对MAS的讨论。由于我们在文献中未找到与下面所述精确版本相符的NFL定理,我们也提供了证明以保持自包含性。我们不声称该定理及其证明具有原创性。
定理 A.1(加权NFL)。设 XXX 为有限输入域,YYY 为有限标签集,F=YX\mathcal{F}=Y^{X}F=YX 为所有函数 f:X→Yf: X \rightarrow Yf:X→Y 的集合。考虑
- 一个通用算法 A0A_{0}A0,其在每个 f∈Ff \in \mathcal{F}f∈F 上具有常数期望损失 ε0\varepsilon_{0}ε0,
-
- 一个专用算法 A′A^{\prime}A′ 满足
L(hA′,f)≤{ε1,f∈F′ε2,f∉F′ L\left(h_{A^{\prime}}, f\right) \leq \begin{cases}\varepsilon_{1}, & f \in \mathcal{F}^{\prime} \\ \varepsilon_{2}, & f \notin \mathcal{F}^{\prime}\end{cases} L(hA′,f)≤{ε1,ε2,f∈F′f∈/F′
- 一个专用算法 A′A^{\prime}A′ 满足
其中 ε1<ε0<ε2\varepsilon_{1}<\varepsilon_{0}<\varepsilon_{2}ε1<ε0<ε2,以及
- 一个先验 PPP,满足 P(f∈F′)=pP\left(f \in \mathcal{F}^{\prime}\right)=pP(f∈F′)=p 和 P(f∉P\left(f \notin\right.P(f∈/ F′)=1−p\left.\mathcal{F}^{\prime}\right)=1-pF′)=1−p。
- 如果
p>ε0−ε2ε1−ε2 p>\frac{\varepsilon_{0}-\varepsilon_{2}}{\varepsilon_{1}-\varepsilon_{2}} p>ε1−ε2ε0−ε2
那么 A′A^{\prime}A′ 的期望风险严格低于 A0A_{0}A0,即
R(A′)<R(A0) R\left(A^{\prime}\right)<R\left(A_{0}\right) R(A′)<R(A0)
证明。根据定义,
R(A0)=Ef∼P[L(hA0,f)]=ε0 R\left(A_{0}\right)=\mathbb{E}_{f \sim P}\left[L\left(h_{A_{0}}, f\right)\right]=\varepsilon_{0} R(A0)=Ef∼P[L(hA0,f)]=ε0
和
R(A′)=Ef∼P[L(hA′,f)]=pε1+(1−p)ε2 R\left(A^{\prime}\right)=\mathbb{E}_{f \sim P}\left[L\left(h_{A^{\prime}}, f\right)\right]=p \varepsilon_{1}+(1-p) \varepsilon_{2} R(A′)=Ef∼P[L(hA′,f)]=pε1+(1−p)ε2
因此
R(A′)<R(A0)⟺pε1+(1−p)ε2<ε0⟺p(ε1−ε2)>ε0−ε2 \begin{aligned} R\left(A^{\prime}\right)<R\left(A_{0}\right) & \Longleftrightarrow p \varepsilon_{1}+(1-p) \varepsilon_{2}<\varepsilon_{0} \\ & \Longleftrightarrow p\left(\varepsilon_{1}-\varepsilon_{2}\right)>\varepsilon_{0}-\varepsilon_{2} \end{aligned} R(A′)<R(A0)⟺pε1+(1−p)ε2<ε0⟺p(ε1−ε2)>ε0−ε2
整理后得到
p>ε0−ε2ε1−ε2 p>\frac{\varepsilon_{0}-\varepsilon_{2}}{\varepsilon_{1}-\varepsilon_{2}} p>ε1−ε2ε0−ε2
这完成了证明。
B 附录:KSP和TAP描述
在本附录中,我们提供有关KSP和TAP的详细信息,包括它们的问题描述和基于此设计MAS的算法。
B.1 KSP问题公式化
KSP的通常输入涉及一组 NNN 项,这些项由重量 wiw_{i}wi 和价值 viv_{i}vi 的对 (wi,vi)\left(w_{i}, v_{i}\right)(wi,vi) 特征化,以及一个容量值 WWW。KSP的目标是找到一个子集,使得总重量不超过给定容量,而总价值最大化。数学上,我们通过两个向量记录项的信息,维度均为 NNN :一个重量向量 w⃗=(w1,⋯ ,wN)\vec{w}=\left(w_{1}, \cdots, w_{N}\right)w=(w1,⋯,wN) 和一个价值向量 v⃗=(v1,⋯ ,vN)\vec{v}=\left(v_{1}, \cdots, v_{N}\right)v=(v1,⋯,vN)。我们还引入状态向量集合 {0,1}N\{0,1\}^{N}{0,1}N,其元素为向量 x⃗=(x1,⋯ ,xN)\vec{x}=\left(x_{1}, \cdots, x_{N}\right)x=(x1,⋯,xN),其中条目 xix_{i}xi 取值在0和1之间,表示某一项是否被选入子集:
xi={1 item i is chosen 0 item i is excluded x_{i}= \begin{cases}1 & \text { item } i \text { is chosen } \\ 0 & \text { item } i \text { is excluded }\end{cases} xi={10 item i is chosen item i is excluded
因此,状态向量控制哪些项在所选子集中,并且 x⃗\vec{x}x 与 w⃗\vec{w}w 和 v⃗\vec{v}v 的内积分别计算给定子集的总重量和总价值。
给定一个重量向量 w⃗\vec{w}w、一个价值向量 v⃗\vec{v}v 和容量约束 WWW,背包问题的目标可以表述为寻找以下(最优)值:
Z=maxx⃗∈{0,1}Nx⃗⋅w⃗≤Wx⃗⋅v⃗ Z=\max _{\substack{\vec{x} \in\{0,1\}^{N} \\ \vec{x} \cdot \vec{w} \leq W}} \vec{x} \cdot \vec{v} Z=x∈{0,1}Nx⋅w≤Wmaxx⋅v
这里的最大值取遍所有满足总重量 x⃗⋅w⃗\vec{x} \cdot \vec{w}x⋅w 不超过容量 WWW 的状态向量(或等价地,所有子集)。
这种问题版本,其中每个项目要么完全包含,要么根本不包含,通常被称为 0/10 / 10/1 KSP。
B.2 KSP问题解决方案
解决背包问题的经典方法是枚举所有可行状态——一种动态规划策略,最初由Bellman(Bellman,1957)提出。一个可行状态可以通过一对(current_weight, current_value)来定义,表示迄今为止选择的一组项目的累积重量和价值,使得current_weight ≤W\leq W≤W。我们可以用数学归纳法描述该算法。我们从初始的可行状态集合 S0=S_{0}=S0= {(0,0)}\{(0,0)\}{(0,0)} 开始,表示一个空的已选项目集合。然后我们通过归纳方式将项目添加到 SkS_{k}Sk 中形成 Sk−1S_{k-1}Sk−1 集合,同时注意容量:对于每个 kkk,假设 Sk−1S_{k-1}Sk−1 已经构建完毕,然后我们将对中的所有项目添加到 Sk−1S_{k-1}Sk−1 中以形成新集合 Sadd S_{\text {add }}Sadd :
Sadd ={(w+wk,v+vk)S_{\text {add }}=\left\{\left(w+w_{k}, v+v_{k}\right)\right.Sadd ={(w+wk,v+vk) 对于所有 (w,v)∈Sk−1}\left.(w, v) \in S_{k-1}\right\}(w,v)∈Sk−1}.
然后,我们根据容量修剪集合:
Strimmed ={(w,v)∈Sadd ∣w≤W} S_{\text {trimmed }}=\left\{(w, v) \in S_{\text {add }} \mid w \leq W\right\} Strimmed ={(w,v)∈Sadd ∣w≤W}
注意这也去除了集合中的所有重复状态。最后我们取两个中间集合的并集以创建 SkS_{k}Sk :
Sk=Sk−1∪Strimmed S_{k}=S_{k-1} \cup S_{\text {trimmed }} Sk=Sk−1∪Strimmed
当遍历完所有项目并获得最终集合 SNS_{N}SN 时,归纳步骤结束,我们在 SNS_{N}SN 中选取具有最大值的元素作为KSP的解。明确地说,
Z=max(w,v)∈SNv Z=\max _{(w, v) \in S_{N}} v Z=(w,v)∈SNmaxv
B.3 TAP问题公式化
TAP旨在最优地分配一组 NNN 资源(代理或工人)到 NNN 任务中,每个潜在分配都会产生特定成本。在约束条件下,每个资源只能分配到一个独特的任务中,TAP的目标是找到覆盖所有任务的分配,使总成本最小化。资源-任务特定成本记录在一个 N×NN \times NN×N 矩阵 CCC 中,其中条目 CijC_{i j}Cij 表示将资源 iii 分配到任务 jjj 的成本,对于 i,j∈{1,2,…,N}i, j \in\{1,2, \ldots, N\}i,j∈{1,2,…,N}。
为了正式定义问题,我们引入了一组 Sn\mathfrak{S}_{n}Sn,它可以描述为以下三种等价方式之一:
- 集合 N‾=\underline{N}=N= {1,2,⋯ ,N}\{1,2, \cdots, N\}{1,2,⋯,N} 的自同构群。
-
- 集合 N‾\underline{N}N 到自身的双射(或群)集合。
-
- 所有涉及 NNN 个元素的排列集合。
注意 SN\mathfrak{S}_{N}SN 中的元素传达了每个资源被分配到独特任务的概念。
- 所有涉及 NNN 个元素的排列集合。
现在,给定 N×NN \times NN×N 成本矩阵 CCC,TAP的目标是找到以下(优化)值
Z=maxσ∈SN(∑i=1NCiσ(i)) Z=\max _{\sigma \in \mathfrak{S}_{N}}\left(\sum_{i=1}^{N} C_{i \sigma(i)}\right) Z=σ∈SNmax(i=1∑NCiσ(i))
注意当我们把 σ∈SN\sigma \in \mathfrak{S}_{N}σ∈SN 视为从 N‾={1,2,⋯ ,N}\underline{N}=\{1,2, \cdots, N\}N={1,2,⋯,N} 到自身的(双射)映射时,符号 Ciσ(i)C_{i \sigma(i)}Ciσ(i) 表示成本矩阵 CCC 中第 iii 行和 σ(i)\sigma(i)σ(i) 列的条目。
B.4 TAP问题解决方案
TAP的典型解决方案是使用匈牙利算法(Kuhn,1955),它提供了一种多项式时间方法来找到目标值 ZZZ。我们总结如下算法。
步骤1. 行约简。对于每一行,我们找到该行中的最小元素,并将其从该行的所有条目中减去,在每行中至少创建一个零。数学上,从原始成本矩阵 CN×NC_{N \times N}CN×N 开始,我们创建一个新的约简矩阵 C′C^{\prime}C′,使得对于 i,j∈{1,2,⋯ ,N}i, j \in\{1,2, \cdots, N\}i,j∈{1,2,⋯,N},我们有
Cij′=Cij−min1≤k≤NCik C_{i j}^{\prime}=C_{i j}-\min _{1 \leq k \leq N} C_{i k} Cij′=Cij−1≤k≤NminCik
步骤2. 列约简。类似地,我们将 C′C^{\prime}C′ 进一步约简为 C′′C^{\prime \prime}C′′ 如下:对于每一列,我们找到该列中的最小元素,并将其从该列的所有条目中减去,确保
每列中至少有一个零。数学上,取
Cij′′=Cij′−min1≤k≤NCkj C_{i j}^{\prime \prime}=C_{i j}^{\prime}-\min _{1 \leq k \leq N} C_{k j} Cij′′=Cij′−1≤k≤NminCkj
步骤3. 找覆盖线。然后我们找到最小的行和列集合以覆盖所有零。这里最小是指集合(行和列)中元素的数量在整个可能集合中是最小的。如果这个最小集合的大小,记为 LLL,与问题的大小 NNN 相同,则跳过步骤4进入算法的最后阶段。
步骤4. 矩阵改进。然而,如果 L<NL<NL<N,我们需要在返回步骤3之前对矩阵 C′′C^{\prime \prime}C′′ 进行改进:给定步骤3中的最小行和列集合,我们找到所有未覆盖条目中的最小值,然后从所有未覆盖的 C′′C^{\prime \prime}C′′ 条目中减去这个最小值,然后将这个最小值加到所有被两次覆盖的 C′′C^{\prime \prime}C′′ 条目中,即同时被行和列覆盖的条目。令 C′′′C^{\prime \prime \prime}C′′′ 为结果矩阵。
步骤5. 分配识别。一旦条件 L=NL=NL=N 满足,最后一步是识别最优分配。这涉及从当前矩阵 C′′′C^{\prime \prime \prime}C′′′ 中选择一组 NNN 个独立的零,使得任何两个选定的零不在同一行或列中。每个位于位置 (i,j)(i, j)(i,j) 的选定零对应将代理 iii 分配给任务 jjj。该最优分配的总成本随后通过将原始成本矩阵 CCC 中对应这些选定零位置的成本相加以计算。
匈牙利算法保证的一个非平凡事实是,在步骤5中,零的集合可能不是唯一的,但不同的集合被认为会导致原始成本矩阵 CCC 中相应条目的总和相同。
C 真实数据准备
我们利用Google OR-Tools(Perron和Furnon,2022)生成最优解——作为真实数据集用于两种问题场景。OR-Tools是由Google开发的广泛采用的开源软件套件,用于解决组合优化问题。它以其在应对NP难挑战时的高效性和可靠性而闻名,通过先进的优化算法实现。该套件在Apache License 2.0许可下分发,允许不受限制的使用、修改和分发(Perron和Furnon,2022)。
对于KSP,我们通过为物品分配权重和价值以及最大容量约束生成随机实例。使用OR-Tools的动态规划方法计算最优解。对于TAP,我们类似地生成代表将工人分配到任务的成本的随机成本矩阵。使用OR-Tools中实现的匈牙利算法获取最优分配,从而有效地最小化总分配成本。
D 附录:提示库
请注意,以下呈现的所有提示,除了KSP问题中Trimmer智能体的自我检查提示外,都是智能体的系统提示。用户提示仅包含智能体需要处理的精确问题,形式由提示指定。
D.1 KSP提示
D.1.1 零样本提示
您是背包问题领域的专家。
您得到了一个JSON格式的背包问题,形式如下:
{
“id” : str,
“items” : list of pairs of integers,
“capacity” : int
}
列表中的每个对是一个形式为[weight, value]的整数对,即第一个条目是重量,第二个条目是价值。
您的任务是解决背包问题并提供最优解。也就是说,您需要找到一个子集,使其总价值最大化,同时满足子集的总重量小于或等于容量的约束。
请逐步思考解决问题。
您需要以以下JSON格式返回最优解:
{
“max_value” : int,
}
请只返回JSON格式,不要返回其他内容。
D.1.2 Worker智能体提示
您是多智能体团队中协作解决背包问题的关键成员。您的具体角色是Worker,负责为团队执行数学计算。
您将收到以下JSON格式的输入:
{“c_list”: [[int, int], …], “s_item”: [int, int]}
'c_list’中的每个对包含两个整数。
您的任务是:
-
将’s_item’逐项加到’c_list’中的每个对中。例如,如果’c_list’中的一个对是’ [2,5][2,5][2,5] ‘,而’s_item’是’ [3,4][3,4][3,4] ‘,则结果应为’ [2+3,5+4]=[5,9][2+3,5+4]=[5,9][2+3,5+4]=[5,9] '。
为了确保准确性: -
系统地进行操作,应用逐步推理。
-
- 小心地单独为列表中提供的所有对执行每个加法。
您的响应必须严格遵循此JSON格式:
{“n_list”: [[int, int], …]}
仅返回指定的JSON对象,不要附加任何其他评论或文本。
- 小心地单独为列表中提供的所有对执行每个加法。
D.1.3 Trimmer智能体提示
您是多智能体团队中协作解决背包问题的关键成员。您的具体角色是Trimmer,负责根据给定的容量约束修剪列表。
您将收到以下JSON格式的输入:
{“n_list”: [[int, int], …], “capacity”: int}
'n_list’中的每个对包含两个整数:第一个整数代表重量,第二个整数代表价值。
您的任务是:
-
小心分析提供的列表中的每个对。
-
- 移除所有重量(第一个整数)严格超过指定容量的对。
-
- 如果相同的对多次出现,仅保留每个的单个实例。
为了确保准确性:
- 如果相同的对多次出现,仅保留每个的单个实例。
-
系统地进行操作,应用逐步推理。
-
- 小心地将每个对与容量约束进行核对。
您的响应必须严格遵循此JSON格式:
{“t_list”: [[int, int], …]}
仅返回指定的JSON对象,不要附加任何其他评论或文本。
- 小心地将每个对与容量约束进行核对。
D.1.4 Reporter智能体提示
您是多智能体团队中协作解决背包问题的关键成员。您的具体角色是Reporter,负责根据提供的信息确定并清楚报告最终答案。
您将收到以下JSON格式的输入:
{“c_list”: [[int, int], …]}
'c_list’中的每个对包含两个整数:第一个整数代表重量,第二个整数代表价值。
您的任务是仔细分析此列表,识别具有最大价值(每个对中的第二个整数)的对,并仅报告该最大值。如果列表为空,则将最大值报告为0。
为了确保准确性:
- 系统地进行操作,应用逐步推理。
-
- 小心地检查提供的列表中的每个对。
您的响应必须严格遵循此JSON格式:
{“max_value”: int}
仅按上述指定返回JSON对象,不要附加任何其他评论或文本。
- 小心地检查提供的列表中的每个对。
D.1.5 Trimmer智能体自我检查提示
为了更好地完成您的任务,请对您刚刚提供的结果进行双重检查。如果您的答案已经正确,请通过复制最后一个输出来确认。
在双重检查时,请注意以下典型的错误类型:
特别是,请检查您是否犯了以下列出的典型错误:
- 如果您添加了一个不在原始n_list中的对。
-
- 如果t_list中仍然存在超过容量的对。
-
- 如果n_list中存在一个不超过容量但不在t_list中的对。
如果您发现了任何错误,请创建一个修正后的答案。
- 如果n_list中存在一个不超过容量但不在t_list中的对。
无论哪种情况,请遵循输出的格式要求。
D.2 TAP提示
D.2.1 零样本提示
您是解决分配问题的专家。在分配问题中,有n个工人和n个工作。每个工人被分配到每个工作都有一个成本。每个工人只能被分配到一个工作。您的任务是找到使总成本最小化的工人的最佳分配。
您以以下JSON格式给出问题:
{
“id” : str,
“cost_matrix” : list of lists of integers
}
成本矩阵是一个大小为n×n\mathrm{n} \times \mathrm{n}n×n的方阵,其中n是工人和工作的数量,形式为嵌套列表[[int, int, …], [int, int, …], …]。(i, j)th条目表示将第i个工人分配到第j个工作的成本。
您的任务是找到使总成本最小化的工人的最佳分配。
请逐步思考解决问题。
您需要以以下JSON格式返回最佳分配:
{
“optimal_cost” : int }
请只返回JSON格式,不要返回其他内容。
D.2.2 Row Reducer智能体提示
您以以下JSON格式给出矩阵:
{
“matrix” : list of lists of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
您的任务是通过从每行的所有元素中减去该行的最小值来减少矩阵。
请逐步思考解决问题:
步骤0:一次处理一行。
步骤1:找到该行的最小值。
步骤2:从该行的所有元素中减去该行的最小值。
步骤3:以以下JSON格式返回减少后的矩阵:
{“reduced_matrix” : list of lists of integers}
请只返回JSON格式,不要返回其他内容。
D.2.3 Column Reducer智能体提示
您以以下JSON格式给出矩阵:
{
“matrix” : list of lists of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
您的任务是通过从每列的所有元素中减去该列的最小值来减少矩阵。
请逐步思考解决问题:
步骤0:一次处理一列。
步骤1:找到该列的最小值。
步骤2:从该列的所有元素中减去该列的最小值。
步骤3:以以下JSON格式返回减少后的矩阵:
{“reduced_matrix” : list of lists of integers}
请只返回JSON格式,不要返回其他内容。
D.2.4 Cover Seeker智能体提示
您以以下JSON格式给出问题:
{
“matrix” : list of lists of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
您的任务是找到矩阵中最小的行和列集合,使得矩阵中的任何零都包含在选定的行或列中。小意味着行和列集合大小的总和尽可能小。
请逐步思考解决问题,并以以下JSON格式返回您的响应:
{“collum_collection” : [int, int, …], " row_collection" : [int, int, …]}
collum_collection和row_collection中的整数是您选择的行和列的索引。
请只返回JSON格式,不要返回其他内容。
D.2.5 Matcher智能体提示
您以以下JSON格式给出矩阵:
{
“matrix” : list of lists of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
您的任务是在矩阵中找到最大的零集合,使得任何两个零不在同一行或列中。
请逐步思考解决问题,并以以下JSON格式返回您的响应:
{“largest_collection” : [[int, int], [int, int], …]}
整数对列表的形式为[[行索引, 列索引], [行索引, 列索引], …]。
请只返回JSON格式,不要返回其他内容。
D.2.6 Painter智能体提示
您以以下JSON格式给出问题:
{
“matrix” : list of lists of integers
“collection” : list of lists of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
集合的形式为嵌套列表[[int, int], [int, int], …]。
您的任务是找到矩阵中最小的行和列集合,使得矩阵中的任何零都包含在选定的行或列中。小意味着行和列集合大小的总和尽可能小。
为了帮助您,输入JSON格式中提供了一个零集合。该
集合包含矩阵中最大零集合的位置,使得任何两个零不在同一行或列中。
请使用这个零集合找到所需的行和列。更确切地说,您应该首先为集合中的每个零选择一行或一列,使得所选的行和列尽可能多地覆盖矩阵中的零。然后根据需要添加更多的行或列。
请逐步思考解决问题,并以以下JSON格式返回您的响应:
{“collum_collection” : [int, int, …], " row_collection" : [int, int, …]}
collum_collection和row_collection中的整数是您选择的行和列的索引。
请只返回JSON格式,不要返回其他内容。
D.2.7 Normalizer智能体提示
您以以下JSON格式给出问题:
{
“matrix” : list of lists of integers
“collumn_collection” : list of integers
“row_collection” : list of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
collumn_collection和row_collection是一些选定行和列的索引,覆盖了矩阵中的所有零。
您的任务如下:
- 找到未被选定行和列覆盖的矩阵中的最小值。
-
- 如果这个值是0,返回原始矩阵。
-
- 如果这个值不是0,从所有未覆盖的条目中减去这个值。
-
- 对于被选定行和选定列同时覆盖的条目,加上这个值。
-
- 对于被选定行或列覆盖但不是两者都覆盖的条目,什么都不做。
-
- 请以以下JSON格式返回更新后的矩阵:
- {“normalized_matrix” : list of lists of integers}
- 请只返回JSON格式,不要返回其他内容。
D.2.8 Reporter智能体提示
您以以下JSON格式给出问题:
{
“matrix” : list of lists of integers
“collection” : list of lists of integers
}
矩阵的形式为嵌套列表[[int, int, …], [int, int, …], …]。
集合包含矩阵中的一组条目,形式为[[行索引, 列索引], [行索引, 列索引], …]。
您的任务如下:
- 将集合中所有条目的值相加。
-
- 以以下JSON格式返回总值:
- {“total_value” : int}
- 请只返回JSON格式,不要返回其他内容。
参考文献
Anonymous. 2025. Code in harmony: Evaluating multiagent frameworks. In Submitted to CS598 LLM Agent 2025 Workshop. Under review.
Richard Bellman. 1957. Dynamic Programming. Princeton University Press, Princeton, NJ, USA.
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji-Rong Wen. 2024. Reflective multi-agent collaboration based on large language models. Advances in Neural Information Processing Systems, 37:138595-138631.
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, and 1 others. 2025. Why do
multi-agent llm systems fail? arXiv preprint arXiv:2503.13657.
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680.
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, and 1 others. 2023. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 3(4):6.
Wenyue Hua, Lizhou Fan, Lingyao Li, Kai Mei, Jianchao Ji, Yingqiang Ge, Libby Hemphill, and Yongfeng Zhang. 2023. War and peace (waragent): Large language model-based multi-agent simulation of world wars. arXiv preprint arXiv:2311.17227.
Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 13
13 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)