NLTK数据集实战:自然语言处理的基石
NLTK(Natural Language Toolkit)是Python中最流行的自然语言处理库之一。它提供了丰富的工具集,可以用来进行语言模型、词性标注、文本分类等NLP任务。首先,需要确保你的环境中安装了Python。

简介:自然语言处理(NLP)是人工智能的关键领域,涉及理解和生成人类语言的能力。nltk_data是Python自然语言处理库NLTK的核心数据资源,包括了丰富的语料库、词性标注器、停用词列表和语法解析模型等。nltk_data.zip是这些资源的压缩包,由于原始资源网站失效,本zip文件作为备份,保证了NLP研究和开发的连续性。nltk_data-gh-pages指向了GitHub上的数据集版本,方便用户在线获取。NLTK和nltk_data对于学习和实验NLP至关重要,推动了该领域的发展。 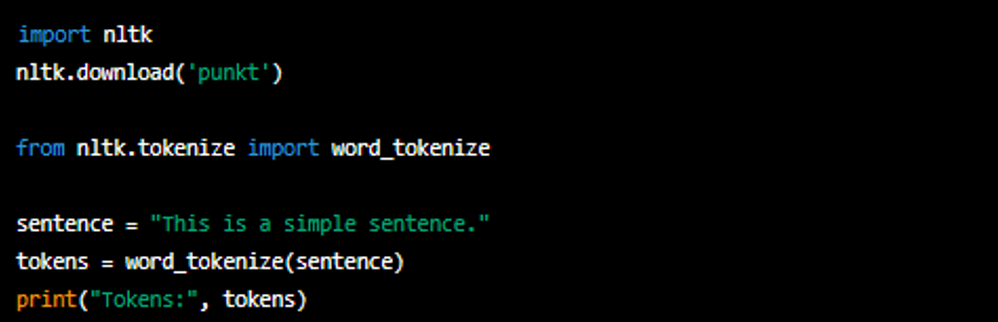
1. 自然语言处理(NLP)应用概览
自然语言处理(NLP)是计算机科学、人工智能和语言学领域结合的产物,旨在让计算机能够理解、解释和生成人类语言。NLP的应用广泛,从搜索引擎、语音识别、机器翻译到情感分析等领域,它已变得不可或缺。本章将简要介绍NLP在现实世界中的应用以及它的历史演进,为进一步深入了解其技术细节和相关工具库打下基础。
graph LR
A[NLP应用概览] --> B[搜索引擎]
A --> C[语音识别]
A --> D[机器翻译]
A --> E[情感分析]
A --> F[聊天机器人]
NLP技术的迅猛发展,不仅得益于机器学习特别是深度学习技术的进步,还得益于大规模语料库的建设和开放。下一章我们将聚焦于Python中的NLP工具库——NLTK(Natural Language Toolkit),它是学习和开发NLP应用的重要资源。
2. Python NLTK库介绍
2.1 NLTK库的安装与环境配置
2.1.1 安装NLTK库的步骤
NLTK(Natural Language Toolkit)是Python中最流行的自然语言处理库之一。它提供了丰富的工具集,可以用来进行语言模型、词性标注、文本分类等NLP任务。
首先,需要确保你的环境中安装了Python。打开命令行工具(例如Windows中的cmd,macOS/Linux中的Terminal),输入以下命令来安装NLTK及其依赖库:
pip install nltk
安装完成之后,为了验证安装是否成功,可以启动Python解释器,并尝试导入nltk模块:
import nltk
如果没有任何错误提示,则表示NLTK库已经成功安装在你的Python环境中。
2.1.2 配置NLTK环境的基础要求
安装NLTK只是开始。为了能够充分利用NLTK的功能,你还需要下载一些额外的数据集和模型。例如,词性标注器、分词器和停用词表等。在Python中,可以通过以下方式下载这些数据:
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
在进行上述操作前,请确保你的网络连接正常,并注意下载的数据集版本和兼容性问题,因为NLTK在不同版本间可能会有所差异。
接下来,你将探索NLTK库的核心功能组件,包括语料库的加载与管理、文本标记化、分词与词干提取以及词性标注和命名实体识别等。
2.2 NLTK库的核心功能组件
2.2.1 语料库的加载与管理
NLTK提供了一个丰富的语料库集合,可以用来执行各种语言学研究和开发任务。你可以使用NLTK提供的语料库管理功能来下载、加载和处理这些语料库。
加载语料库的代码示例:
from nltk.corpus import brown
# 访问布朗语料库中的第一篇文档
document = brown.words()[0:100]
print(document)
在上述代码块中,我们首先导入了 brown 语料库,然后加载了其第一个文档的前100个单词。NLTK的语料库能够轻松地用于NLP实验,这为开发人员提供了极大的便利。
2.2.2 标记化、分词与词干提取
标记化(Tokenization)是将文本分割为单独的单词或符号的过程。分词(Segmentation)关注于将文本分割为有意义的元素,如词或词组。词干提取(Stemming)则试图将词汇还原到基本形式。
标记化、分词和词干提取的示例代码:
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
# 将句子进行标记化
tokens = word_tokenize("NLTK is a leading platform for building Python programs to work with human language data.")
# 创建词干提取器并提取词干
stemmer = PorterStemmer()
stems = [stemmer.stem(token) for token in tokens]
print(tokens)
print(stems)
执行这段代码后,你将看到原始句子被标记化为单词列表,并且每个单词被还原到其词干形式。这在进行文本预处理时非常有用。
2.2.3 词性标注和命名实体识别
词性标注(Part-of-Speech Tagging)是识别单词在句子中的语法类别(名词、动词、形容词等)。命名实体识别(Named Entity Recognition, NER)是从文本中识别和分类具有特定意义的实体,比如人名、地名、组织名等。
下面展示了如何使用NLTK进行词性标注和命名实体识别:
from nltk import pos_tag, ne_chunk
# 对标记化后的词进行词性标注
tagged = pos_tag(tokens)
# 命名实体识别
chunked = ne_chunk(tagged)
print(tagged)
print(chunked)
通过上述操作,你可以识别出句子中的每个词的语法类别和句子中出现的命名实体。这在理解句子结构和上下文中非常有用。
接下来,我们将探讨NLTK在NLP中的实践案例,包括文本分类、情感分析、语言模型和自动翻译等。这些案例展示了如何将NLTK库应用到实际问题的解决中。
2.3 NLTK在NLP中的实践案例
2.3.1 文本分类与情感分析
文本分类是将文本数据分配到一个或多个类别中的过程。情感分析是文本分类的一个子集,它关注于识别和提取文本中的主观信息。
使用NLTK进行情感分析的示例代码:
from nltk.sentiment import SentimentIntensityAnalyzer
# 创建情感分析器
sia = SentimentIntensityAnalyzer()
# 分析文本情感倾向
sentiment_score = sia.polarity_scores("I love NLTK library, it's very powerful and easy to use!")
print(sentiment_score)
在上述代码中,我们首先导入了 SentimentIntensityAnalyzer ,然后对一个表示积极情感的句子进行了情感分析。分析器返回了一个包含消极、中性、积极评分的字典。
2.3.2 语言模型和自动翻译
NLTK还能够支持更复杂的语言处理任务,如语言模型构建和自动翻译。尽管NLTK本身不直接提供翻译模型,但可以使用它来训练语言模型并整合到翻译工作流程中。
一个简单的语言模型示例:
from nltk import bigrams
from collections import Counter
# 示例句子
sentence = "Natural language processing is fascinating"
# 提取二元语法
sentence_bigrams = bigrams(sentence.split())
# 统计二元语法出现频率
bigram_freq = Counter(sentence_bigrams)
print(bigram_freq)
此代码段演示了如何使用NLTK提取句子中的二元语法(bigrams)并统计其频率,这是构建语言模型的基础。
NLTK库的使用和功能组件为NLP的入门和深入研究提供了极佳的支持。随着学习的深入,你将能够利用NLTK完成更多复杂的自然语言处理任务。接下来,让我们深入探讨nltk_data资源,这是NLTK生态中不可或缺的一部分。
3. nltk_data资源的重要性与组成
3.1 nltk_data资源的介绍
3.1.1 nltk_data资源的基本概念
在自然语言处理(NLP)领域,一个强大的语言资源库是不可或缺的。NLTK(Natural Language Toolkit)作为一个流行的Python库,集成了丰富的NLP资源,这些资源被组织在 nltk_data 目录中。 nltk_data 不仅包括了预处理好的语料库,还有各种词汇、语法和句法分析器等预训练模型。这些资源使得研究人员和开发者能够在构建复杂的NLP应用时节省大量时间。
nltk_data 资源主要分为以下几类:
- 语料库(Corpora):包括已标注好的文本数据集,例如诗句、小说、对话等,是NLP的基础材料。
- 分词器(Tokenizers):这些工具将文本分割成更小的单元,例如句子、词或字符。
- 语块分析器(Taggers):能够识别文本中的词性,如名词、动词等。
- 词干提取器(Stemmers):用于提取单词的词根或词干。
- 语义分析工具:包括词义消歧、实体识别和依存分析工具。
- 语言模型:用于统计建模,为自动翻译、文本生成等任务提供基础。
3.1.2 nltk_data资源的下载与使用
为了下载和使用 nltk_data 资源,需要先安装NLTK库。在Python环境中,使用pip安装命令如下:
pip install nltk
安装完成后,在Python脚本中,可以使用NLTK提供的接口来下载和加载资源。以下是一个示例代码,用于下载并加载一系列的语料库和模型:
import nltk
# 确保nltk_data目录存在,且包含所需的资源
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('wordnet')
# 代码逻辑:下载并使用punkt的分词模型,进行句子分词
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
# 示例:对一段文本进行分词
text = "Natural language processing (NLP) is a field of artificial intelligence."
words = word_tokenize(text)
print(words)
# 示例:进行词干提取
lemmatizer = WordNetLemmatizer()
lemma = lemmatizer.lemmatize('processing')
print(lemma)
# 示例:对一段文本进行词性标注
tagged = nltk.pos_tag(words)
print(tagged)
这段代码展示了如何使用NLTK下载并应用不同类型的NLP资源。首先,我们导入 nltk 模块,并使用 nltk.download() 函数下载了句子分词( punkt )、词性标注( averaged_perceptron_tagger )和词义网络( wordnet )数据集。然后,我们使用这些数据集进行分词、词干提取和词性标注等操作。
3.2 nltk_data资源的结构组成
3.2.1 语料库、模型和分词器
nltk_data 资源包含了多种语料库,这些语料库经过精心挑选和处理,覆盖了广泛的语言现象和应用需求。一个典型的例子是Brown语料库,它是一个大约100万词的英文样本,广泛用于统计语言模型。除了标准语料库,还有更多特定用途的语料库,如命名实体识别、词义消歧、情感分析等任务所需的。
预训练的分词模型也是 nltk_data 的重要组成部分。如上例所示,NLTK使用了Punkt分词器模型,它能够自动学习如何将文本分割成句子和单词。这是NLP任务中不可或缺的第一步,特别是在处理不同语言和领域时。
3.2.2 nltk_data资源的自定义与扩展
nltk_data 资源虽然提供了大量的预处理资源,但用户也可以根据需要添加和扩展资源。例如,如果有一个特定的文本数据集需要进行分析,用户可以创建一个新的语料库模块,使其能够被NLTK工具所使用。
此外,社区开发者也可以贡献自己的资源,例如新的分词器、词干提取器或者词义标注器。用户只需将这些新资源下载到本地的 nltk_data 目录下,NLTK就会自动检测并集成这些资源。
graph LR
A[开始使用nltk_data资源] --> B[使用内置资源]
B --> C[下载额外的nltk_data资源包]
C --> D[自定义新的语料库和模型]
D --> E[贡献新的资源到社区]
E --> F[更新nltk_data资源]
通过上述流程图,我们可以看到从开始使用 nltk_data 资源到最终资源的扩展和贡献的整个过程。用户首先可以使用NLTK提供的内置资源,随后根据需要下载更多的资源包,进一步定制化和开发,最后还可以将自己开发的资源贡献给社区,以供他人使用。
接下来,我们将深入了解 nltk_data.zip 备份文件的作用与重要性。
4. nltk_data.zip备份文件的作用与重要性
4.1 nltk_data.zip的创建与备份策略
4.1.1 nltk_data.zip的生成过程
在处理自然语言处理(NLP)项目时,对数据和资源进行定期备份是一种良好的实践,确保在发生意外情况时能够快速恢复到之前的状态。 nltk_data.zip 文件是NLTK库中用于备份和恢复 nltk_data 资源的一个关键组件。创建这个压缩文件的过程相对简单,但需要一些前置准备工作。
首先,需要确保你已经正确安装了NLTK库,并且在你的环境中配置了 nltk_data 目录。通常,这个目录会在安装NLTK时自动创建,或者你可以手动指定一个位置。
import nltk
nltk.download('punkt')
上述代码会使用NLTK的下载器,尝试下载分词器数据到 nltk_data 目录。如果数据已经存在,你可以继续备份。
备份的过程可以通过Python脚本来自动化,使用内置的 zipfile 模块,创建一个压缩文件,包含 nltk_data 目录下的所有内容。这可以通过以下代码实现:
import zipfile
import os
# nltk_data的路径,根据实际情况进行修改
nltk_data_path = 'path/to/nltk_data'
zip_path = 'nltk_data_backup.zip'
# 使用ZipFile创建压缩文件并添加nltk_data目录
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(nltk_data_path):
for file in files:
zipf.write(os.path.join(root, file),
os.path.relpath(os.path.join(root, file),
os.path.join(nltk_data_path, '..')))
在这段代码中,我们使用 os.walk() 遍历 nltk_data 目录,并将每个文件添加到压缩文件中。 relpath 方法用于计算相对于 nltk_data 目录的文件路径,确保在解压时能正确地重建目录结构。
4.1.2 备份 nltk_data.zip的最佳实践
创建备份时,应该遵循一些最佳实践,以确保备份的完整性和可用性。首先,应当定期进行备份操作,可以使用定时任务(例如Linux的cron作业或者Windows的任务计划程序)来自动化这一过程。
0 1 * * * python /path/to/backup_script.py
其次,在备份之前,应该确保没有其他程序正在修改 nltk_data 目录中的文件,以避免数据一致性问题。可以使用文件锁定机制或者确保备份操作在系统负载较低时执行。
此外,还应该考虑备份文件的存储位置。理想情况下,备份文件不应仅保存在同一物理磁盘上,而应该异地备份或者使用云存储服务,以防设备损坏或数据丢失。
4.2 nltk_data.zip的恢复与使用
4.2.1 nltk_data.zip的恢复步骤
当需要从备份中恢复 nltk_data 时,可以使用以下步骤。首先,要确定一个适当的恢复位置。通常,这将是原来存放 nltk_data 的位置,或者任何新指定的位置。
接下来,使用 zipfile 模块来提取备份文件:
import zipfile
import os
zip_path = 'nltk_data_backup.zip'
nltk_data_path = 'path/to/new_nltk_data' # 或者原来的路径
# 确保nltk_data路径存在
if not os.path.exists(nltk_data_path):
os.makedirs(nltk_data_path)
# 打开zip文件并提取内容
with zipfile.ZipFile(zip_path, 'r') as zipf:
zipf.extractall(path=nltk_data_path)
在执行上述代码后, nltk_data 目录中的文件将被恢复到指定路径。重要的是在提取文件之前确认路径是正确的,以避免数据丢失。
4.2.2 使用 nltk_data.zip进行资源管理
nltk_data.zip 不仅可以用于灾难恢复,还可以在进行资源管理和版本控制时发挥作用。例如,当需要将NLTK资源的特定配置复制到另一台机器上,或者在多个项目中使用相同的资源集时,可以通过复制和解压 nltk_data.zip 来快速部署所需的资源。
此外,可以在版本控制系统中管理不同版本的 nltk_data.zip 文件,允许开发人员回退到旧版本的数据集,或者追踪数据集随时间的变化。
总结以上, nltk_data.zip 文件对于NLP项目的资源管理是非常有价值的工具。无论是为了数据备份,还是为了资源管理和版本控制,都应该熟练掌握它的创建和恢复步骤,并将其融入到日常的工作流程中。
5. nltk_data在GitHub上的版本访问
5.1 GitHub上nltk_data的版本迭代
5.1.1 如何追踪 nltk_data的版本更新
在NLP开发和研究中,对于nltk_data的跟踪是确保我们使用的是最新、最稳定数据集和模型的关键。要追踪nltk_data的版本更新,首先需要访问其在GitHub上的存储库。
-
访问GitHub上的nltk_data仓库:进入 GitHub nltk_data仓库 ,这是nltk_data版本更新和代码维护的官方地址。
-
熟悉仓库结构:在仓库页面中,你将看到不同的文件夹和文件。了解这些结构对追踪更新至关重要。文件夹包括了数据集、模型、分词器等,文件则可能是安装脚本、文档等。
-
关注Release通知:GitHub仓库中的Releases部分是一个重要工具,用于追踪nltk_data的官方发布版本。在这里你可以看到所有发布的版本标签,这些标签后面通常带有版本号和发布说明,方便用户了解每个版本的更新点。
-
订阅更新通知:在GitHub仓库页面中,你可以点击"Watch"按钮来订阅该仓库的更新通知。这样你将会在每次仓库有新的提交、发布或是其他重要活动时,通过GitHub的邮件通知系统收到提醒。
-
使用GitHub监视器:此外,还可以使用一些第三方服务,如 GitHut ,来追踪GitHub上项目活跃度。这个工具可以让你了解哪些项目是最活跃的,哪些文件被修改最频繁,从而间接了解nltk_data的更新情况。
5.1.2 版本间的差异与升级指南
当nltk_data发布新版本时,了解版本间的差异对于升级现有项目至关重要。以下是检查和理解版本差异并进行升级的步骤。
-
查看版本差异:在GitHub的Releases页面,每个版本旁边通常会有一个"Compare"按钮。点击此按钮,可以查看该版本和前一个版本之间的差异。这一功能非常有用,它会以高亮的方式展示添加、删除或修改的文件。
-
理解变更的影响:一旦识别出版本间的差异,需要评估这些变更对你的项目可能产生的影响。特别是如果使用了nltk_data中的特定数据集或模型,你需要检查这些资源是否发生了重大变化。
-
升级指南:查看GitHub仓库的文档或README文件,通常会包含升级指南,告诉你如何从一个版本迁移到新版本。此外,确保阅读发布的官方说明或Changelog,这些文档会详细说明版本更新的内容以及推荐的升级步骤。
-
升级本地或云资源:根据升级指南,手动升级本地系统或云服务上的nltk_data。如果涉及Python代码,可能需要更新代码中的nltk_data加载路径,确保程序引用正确的新版本资源。
-
测试新版本:在正式部署新版本前,进行充分的测试是必不可少的。针对使用nltk_data的各个组件执行单元测试和集成测试,以确保升级后的应用能够稳定运行。
5.2 nltk_data在GitHub的社区与贡献
5.2.1 参与 nltk_data的开发流程
作为一个社区驱动的开源项目,nltk_data的持续发展离不开广大贡献者的参与。参与nltk_data的开发流程是改进和增强其功能的一个重要途径。以下是参与nltk_data开发的步骤:
-
Fork仓库 :在GitHub上找到nltk_data的官方仓库,点击"Fork"按钮,将仓库复制到你自己的GitHub账号下。这样做可以让你在自己的账号中对项目进行修改而不影响原始仓库。
-
创建开发分支 :在你的fork中,创建一个新的分支用于开发。通常情况下,分支的命名应反映你工作的主题或目标,比如
add-vectors。 -
编写代码或文档 :根据需要改进或添加的功能,开始编写代码或更新文档。确保遵循nltk_data的代码风格和文档指南。
-
提交更改 :完成更改后,使用
git commit将更改添加到你的分支。每提交一次更改,都应该包括有意义的提交信息,以便其他开发者了解这次提交的目的和内容。 -
发起Pull Request :代码和文档准备就绪后,返回到GitHub页面,点击“New pull request”按钮。这会将你的分支与原始仓库的对应分支进行比较。创建Pull Request时,提供清晰的描述和更改的背景。
-
等待审查和反馈 :nltk_data的维护者和其他贡献者将对你的更改进行审查,可能会提供反馈或建议。与社区保持沟通,根据反馈修改你的提交,直到被接受合并到主仓库。
5.2.2 社区贡献的途径与方法
nltk_data项目鼓励社区成员通过多种方式做出贡献。除了直接贡献代码或文档外,还有其他一些途径可以参与:
-
报告问题和需求 :如果你在使用nltk_data时遇到了问题,或者认为某个新功能或数据集对项目有用,可以在GitHub仓库的Issues页面提交问题报告或建议。详细描述你遇到的问题,或者清楚地阐述需求。
-
编写教程和案例研究 :通过编写使用nltk_data的教程或案例研究,可以帮助其他用户更有效地使用该资源。这些教程可以被集成到官方文档中,为社区提供价值。
-
参与讨论 :加入到nltk_data的邮件列表、论坛或聊天室中,参与项目讨论。你可以帮助回答新用户的问题,或者分享你的使用经验。
-
提供使用反馈 :你的使用反馈对于项目的发展至关重要。不论你是初学者还是经验丰富的开发者,都可以分享你的使用感受和改进建议。
-
支持和赞助 :对于那些不能直接贡献代码的社区成员,可以通过经济支持来帮助项目。GitHub Sponsors允许你对项目贡献者进行赞助,以支持他们的工作。
通过上述途径,社区成员可以以各种方式参与nltk_data的开发和维护,共同推动NLP技术的发展和应用。
6. nltk_data对NLP研究和开发的贡献
自然语言处理(NLP)技术的不断发展,与可访问高质量资源的可利用性密切相关。nltk_data库是一个存放语言处理所需资源的仓库,它为NLP的研究和开发提供了极大的便利。本章将探讨nltk_data在学术研究和商业开发中的作用。
6.1 nltk_data对学术研究的支持
6.1.1 nltk_data在研究中的应用场景
在NLP学术研究中,nltk_data提供了大量的语料库和预训练模型,这些资源是进行语言分析、模型训练和实验的基础。例如,使用nltk_data中的"treebank"语料库可以训练句法分析器,而"wordnet"则用于词义消歧和语义分析。此外,nltk_data还提供了一些基本的预处理工具,如分词器、词性标注器等,极大地简化了研究者在数据预处理阶段的工作。
import nltk
from nltk.corpus import wordnet
# 示例:使用nltk_data中的wordnet进行词义查找
for syn in wordnet.synsets('dog'):
print(syn.name(), '---', syn.definition())
6.1.2 nltk_data对研究成果转化的促进作用
nltk_data的资源广泛地应用于NLP领域的教育和研究中,促进了新算法和技术的快速发展。通过共享这些资源,研究者能够复现他人的实验结果,验证新模型的准确性,加速了研究的迭代过程。同时,nltk_data支持多种编程语言环境,降低了研究者使用门槛,让更多的人能够参与到NLP的研究中来。
6.2 nltk_data在商业开发中的作用
6.2.1 nltk_data在产品开发中的重要性
在商业开发领域,nltk_data同样扮演着重要角色。现代的聊天机器人、语音识别系统和推荐引擎都需要大量的语言数据和资源作为支撑。通过nltk_data,开发者可以快速获取到训练模型所需的数据集和工具,缩短产品的研发周期,加速产品上市的步伐。
# 示例:使用nltk_data中的Punkt tokenizer进行文本分词
from nltk.tokenize import PunktTokenizer
tokenizer = PunktTokenizer()
tokens = tokenizer.tokenize("This is an example of tokenizing text with NLTK's Punkt tokenizer.")
print(tokens)
6.2.2 nltk_data对提升产品质量的贡献
质量是产品成功的关键因素之一。nltk_data提供的高质量语料库和预处理工具,使得商业产品的语言理解和处理功能更加准确、高效。例如,通过使用nltk_data中的语言模型和词性标注器,可以显著提升搜索引擎的关键词提取和查询理解能力,进而提升用户体验。另外,随着机器学习技术的融入,nltk_data中的资源可以帮助构建更加智能化的产品功能,如情感分析、自动文摘等。
nltk_data不仅提供了技术资源,也促进了学术界和产业界之间的交流与合作。通过共享资源和开源代码,各方可以共同推动NLP领域的发展,同时将研究成果快速转化为实际可用的产品和服务。随着NLP技术的不断进步,nltk_data将继续发挥其在资源共享方面的关键作用,为全球的研究者和开发者提供强有力的支持。
简介:自然语言处理(NLP)是人工智能的关键领域,涉及理解和生成人类语言的能力。nltk_data是Python自然语言处理库NLTK的核心数据资源,包括了丰富的语料库、词性标注器、停用词列表和语法解析模型等。nltk_data.zip是这些资源的压缩包,由于原始资源网站失效,本zip文件作为备份,保证了NLP研究和开发的连续性。nltk_data-gh-pages指向了GitHub上的数据集版本,方便用户在线获取。NLTK和nltk_data对于学习和实验NLP至关重要,推动了该领域的发展。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)