大模型学习笔记——.bin、.pth、.model文件
第一种方式其实是在保存模型的时候,序列化的数据被绑定到了特定的类(代码中的模型类)和确切的目录,本质上是不保存模型结构(代码)本身,而是。2.bin文件是二进制文件,是huggingface的保存格式,保存的是模型的参数,类似于torch第二种保存方式。,并且在加载的时候会使用,因此当在其他项目里使用或者重构的时候,这种方式加载模型的时候会出错。而huggingface的bin模型的代码已经内置在
1.torch中写一个简单的模型,然后训练。训练完成之后保存有两种方式:
1)保存模型架构与参数
torch.save(model, 'model.pth')
#使用
model = torch.load('model.pth')
output = model(input)2)仅保存参数
torch.save(model.state_dict(), 'model_params.pth'
# 使用就需要先实例化模型
#例如
class MoE():
def __init__(self):
def forward(self):
# 实例化模型
model = MoE()
# 加载参数
model.load_state_dict(torch.load('model_params.pth'))
# 推理
output = model(input)注意:第一种方式其实是在保存模型的时候,序列化的数据被绑定到了特定的类(代码中的模型类)和确切的目录,本质上是不保存模型结构(代码)本身,而是保存这个模型结构(代码)的路径,并且在加载的时候会使用,因此当在其他项目里使用或者重构的时候,这种方式加载模型的时候会出错。
2. bin文件是二进制文件,是huggingface的保存格式,保存的是模型的参数,类似于torch第二种保存方式。
而huggingface的bin模型的代码已经内置在包里,例如
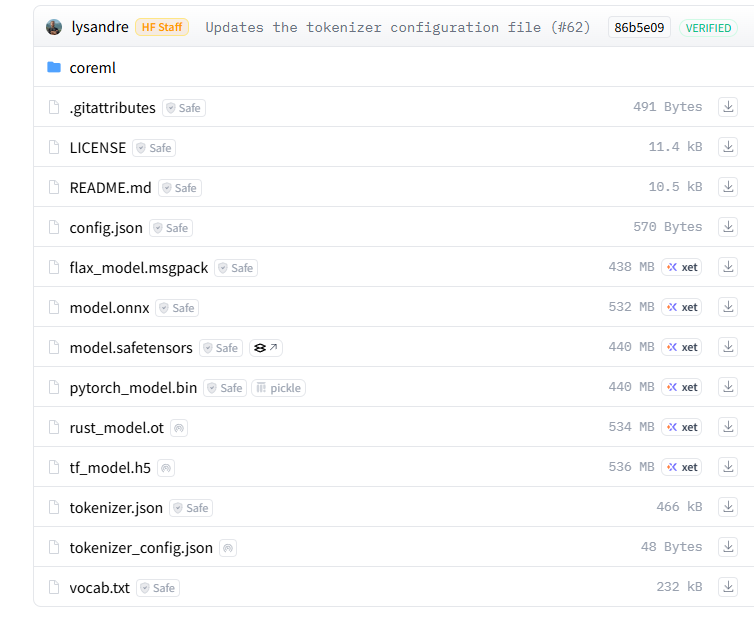
from transformers import AutoTokenizer, Bert
model = Bert.from_pretrained("bert")3. .model文件
使用的是 SentencePiece 分词器,它会将分词规则训练成一个 .model 文件
注意:.model 文件(如某些基于 SentencePiece 的模型才会有)
例如:Llama-2有.model文件,但是没有 vocab.txt
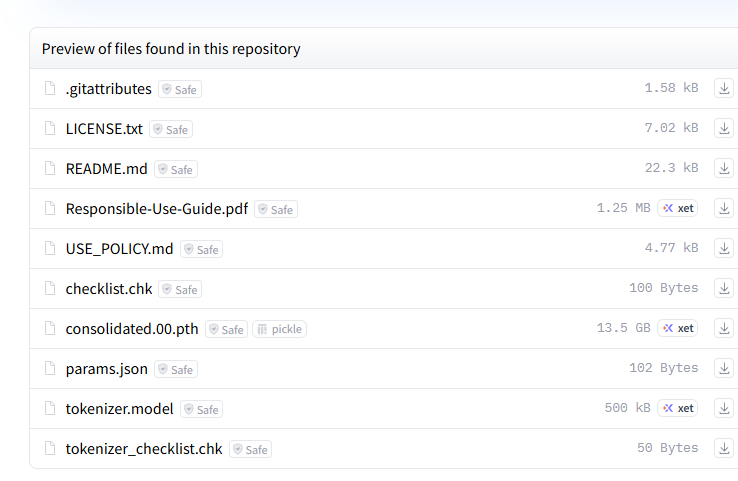
Bert使用的是 WordPiece 分词器,其词汇表是通过 vocab.txt 文件定义的,而不是使用 .model 文件

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)