文本转语音(TTS,Text-to-Speech)技术详解
本文概述了语音合成技术的发展历程,从早期拼接式合成和HMM方法,到近年来基于深度学习的模型演进。重点介绍了WaveNet(2016)的因果卷积和膨胀卷积结构、Tacotron(2017)的编码器-解码器架构、FastSpeech(2019)的非自回归并行化设计、VITS(2021)融合VAE/GAN/Flow的混合模型,以及最新的Bark(2023)和SoundStorm(2023)多任务音频生成
·
早期方法
- 拼接式语音合成(Concatenative TTS):从真人录音中切出音素/音节/词语,然后拼接组合。
- 隐马尔可夫模型(HMM-based TTS):通过统计模型生成频谱相关参数,然后合成声音。
WaveNet(2016)
由Google提出
- 因果卷积:输出只依赖于当前和之前的采样点,类似RNN,但可并行。
- 膨胀卷积:用少量的卷积获得更大的感受野。
- 生成方式:输入过去的几个音频 sample,模型预测下一个点是哪个值,然后把它拼进序列中,重复预测下一个点,直到生成完全部音频。
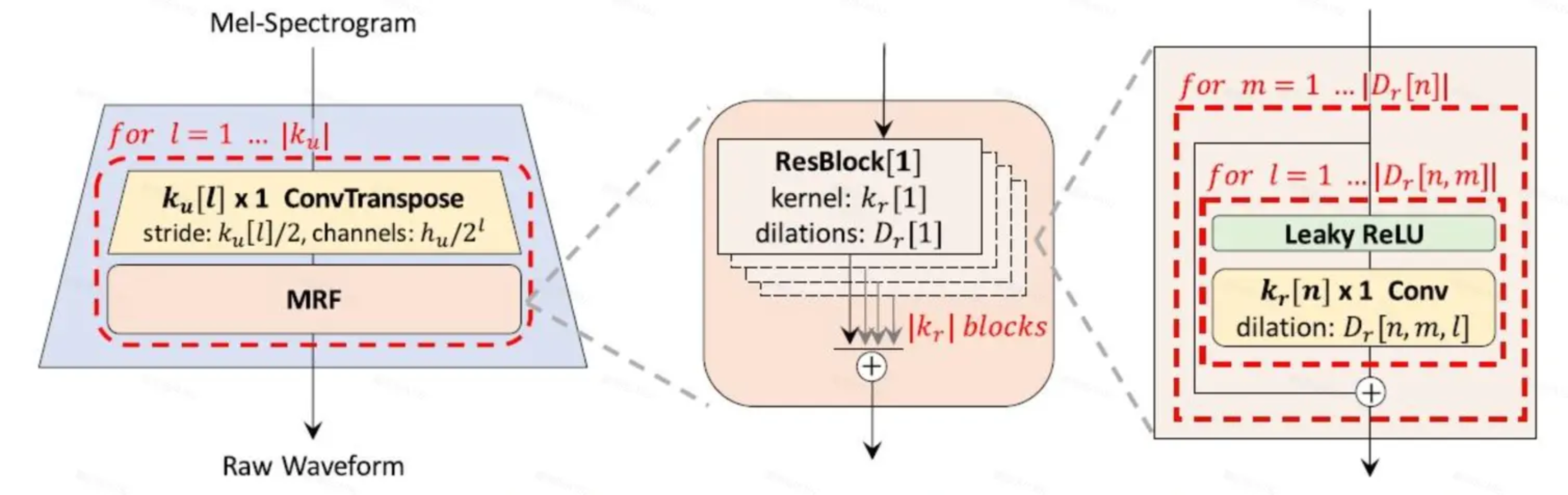
HiFi-GAN(2020)
- HiFi-GAN 是一个端到端的、全卷积式 vocoder,输入 mel-spectrogram,输出高保真的 waveform,通过多维度的判别器 + 特征匹配 loss 实现快且稳的 GAN 训练。
- Generator Loss:Adversarial Loss(标准 GAN loss)+ Spectrogram Loss(L1 loss between mel(真实) vs mel(生成)) + Feature Matching Loss(从判别器中间层抽特征,比差距)
- Discriminator Loss:标准判别器 loss + 来自多个判别器并平均(MPD + MSD 时域周期性(破音,虚音)和波形结构(异常点,假音))
Tactron(2017)
Tactron 1
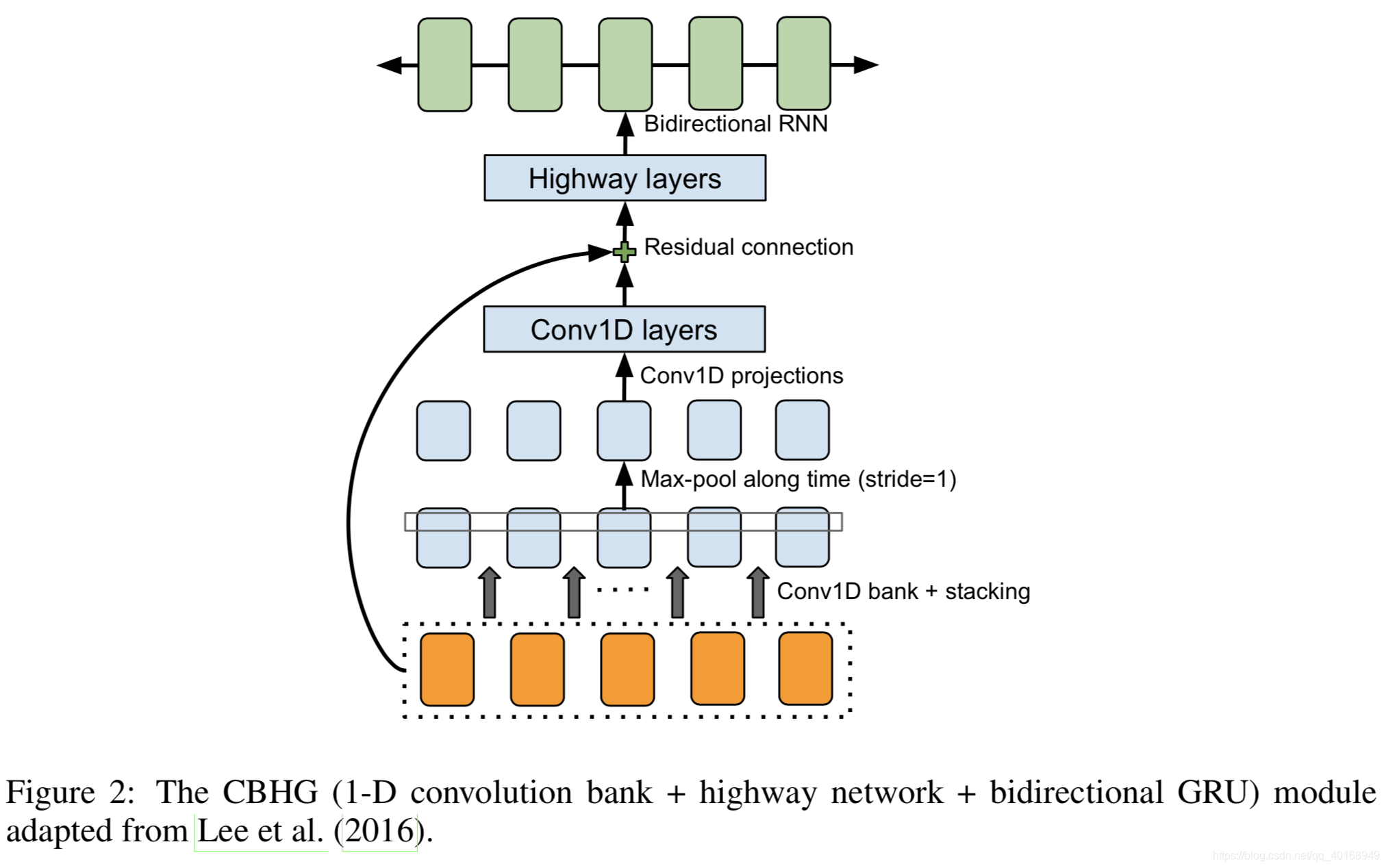
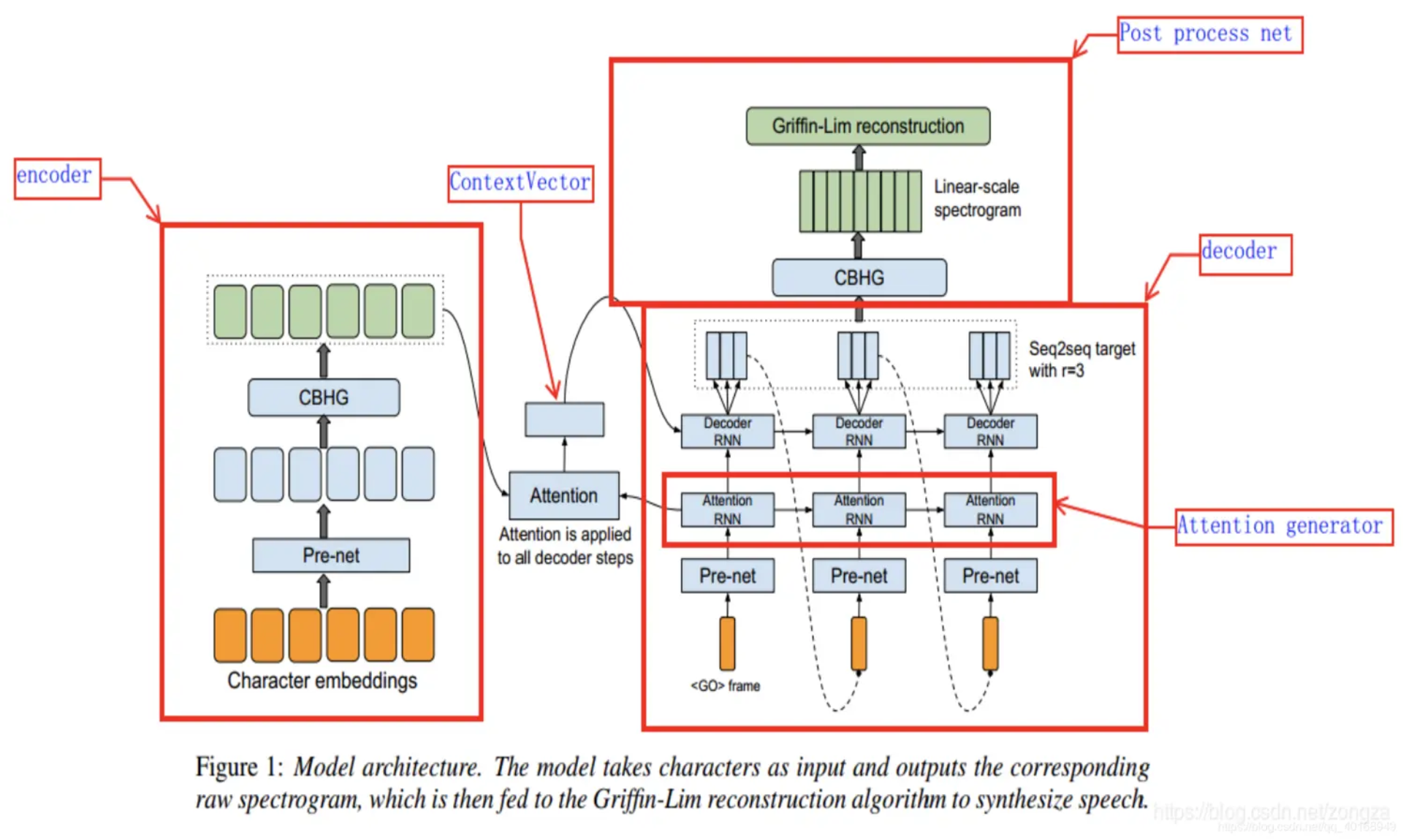
由Google提出,有点类似Transformer的架构,是一个编码器解码器架构,但是由RNN组成。
- Encoder 模块:Pre-Net(类似前馈网络)+CBHG(不同维度的卷积+GRU,类似self-attn层)
- Attention模块:Pre-Net加堆叠的RNN
- Post-processing Net:把 decoder 输出的梅尔谱图 → 转换为线性谱图,通过CBHG模块与Griffin-Lim重建音频信号
Tactron 2
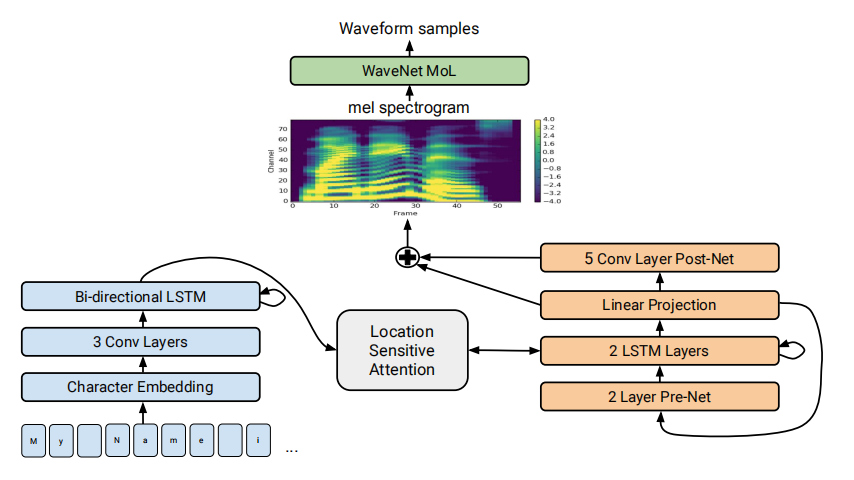
- 编码器:文本嵌入+三层卷积+双向LSTM
- 解码器:前馈网络+LSTM+Location Sensitive Attention(融入历史卷积信息的Attention)+CNN作为细化的音频特征加回到原始mel图上
- 音频合成:基于梅尔谱图通过WaveNet生成音频信号
📌Demo:示例音频
FastSpeech(2019)
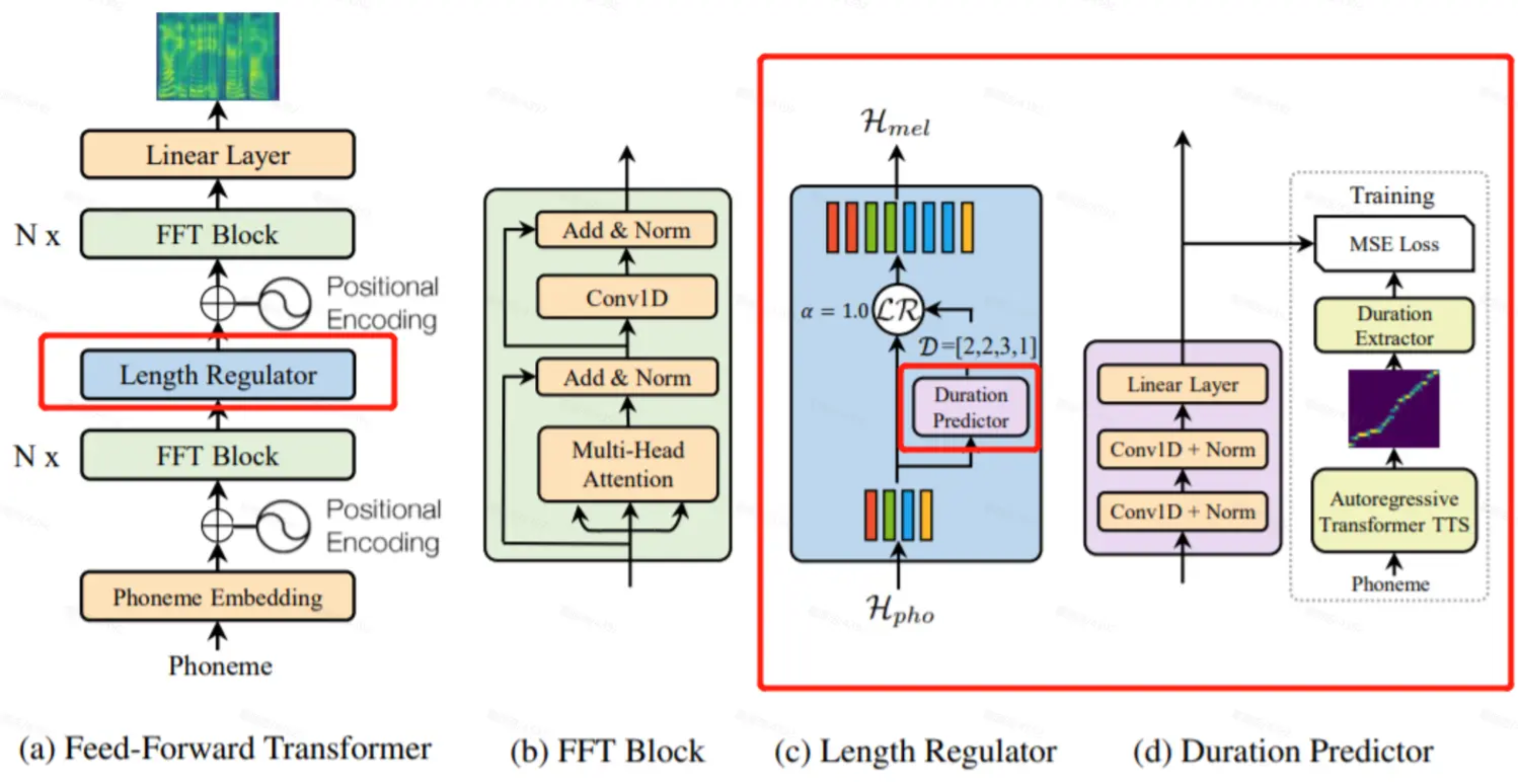
- 由微软提出,有点类似Decoder-only架构,非自回归结构,采用音素作为输入,对音素进行编码,通过 Self-Attention + FFN提取特征,并行化高,生成速度快。
- 通过Duration Predictor输出每个音素的时长,之后在序列扩展器把每个音素按预测的时长重复展开,不需要在之后再动态对齐
- Mel L1 Loss加Duration Loss(从 Tacotron 2 attn matrix 中提取出来,作为 ground truth)
📌Demo:示例音频
VITS(2021)
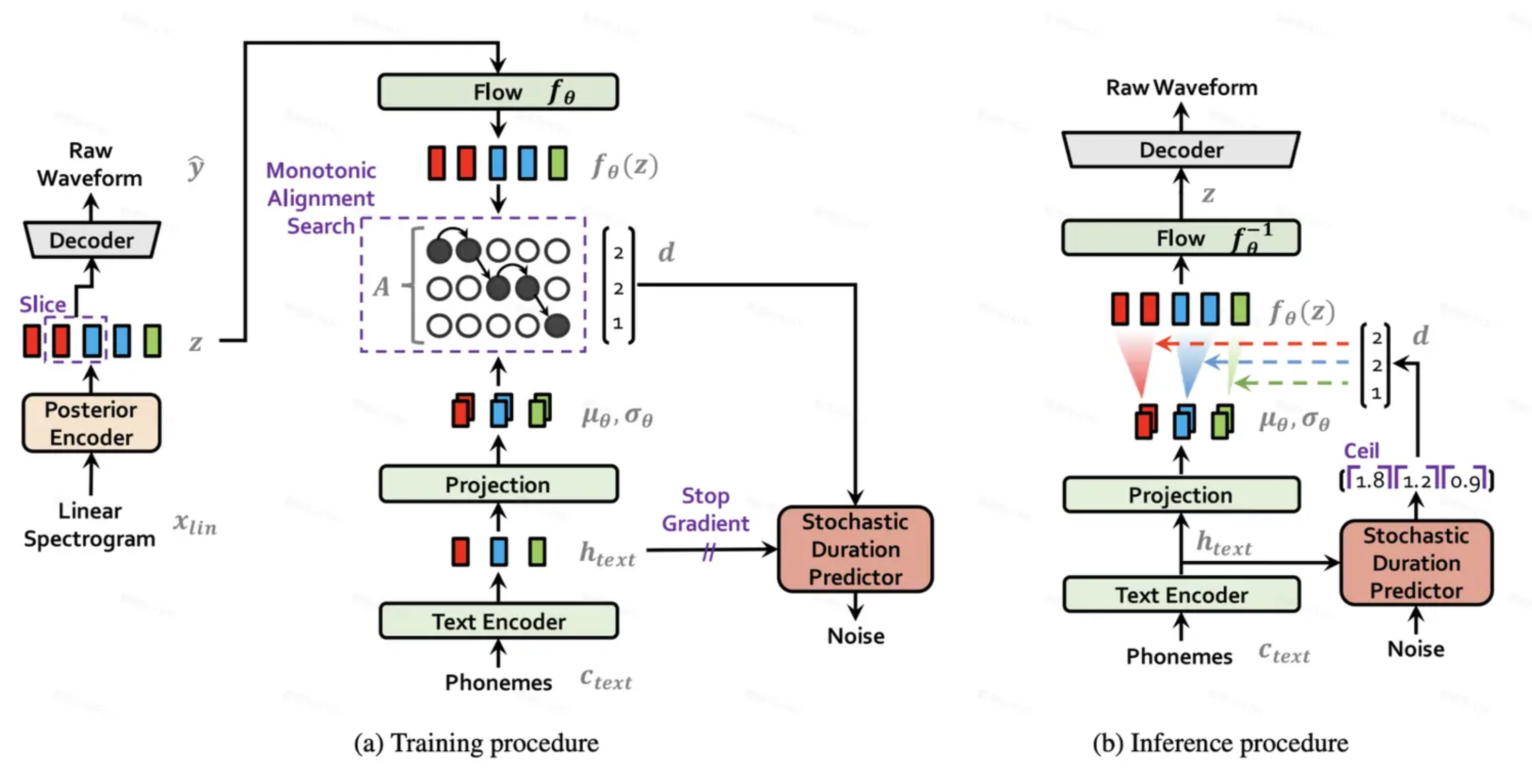
- 由韩国科学院提出,解决了之前TTS模型中缺乏情感和变化的问题。
- 大杂烩,融合传统算法,VAE,GAN,Flow-based模型,在训练阶段,从真实语音中“学出潜在变量 z”,然后让生成模型去匹配这个潜在空间,从 spectrogram(线性谱)中提取真实的 latent 变量 z,经 Posterior Encoder 得到,之后用 Flow(可逆变换)把 zzz成一个简单分布,目标是和前面 Text Encoder 输出的 μ,σ分布一致,Decoder是一个GAN的生成器。
- Monotonic Alignment Search,这是它的一个核心模块,不像Tactron那样硬对齐,使用动态规划的方法找到最优路径
- Stochastic Duration Predictor:每个音素生成一个合理的时长,训练时,输入htext和噪声,输出对应A预测的d,在推理时,输入噪声和htext,得到预测的d引入到原始模型中
📌Demo:示例音频
Bark(2023)
Suno 公司开发的一款前沿的开源文本转音频模型,类似于一种音频 GPT,可以通过promt调整音频生成,可以进行多种任务,比如TTS,风格迁移,音乐生成。
Github地址:GitHub - suno-ai/bark: 🔊 Text-Prompted Generative Audio Model
中文音频合成器:Personal TTS - a Hugging Face Space by kevinwang676
📌Demo:示例音频
SoundStorm(2023)
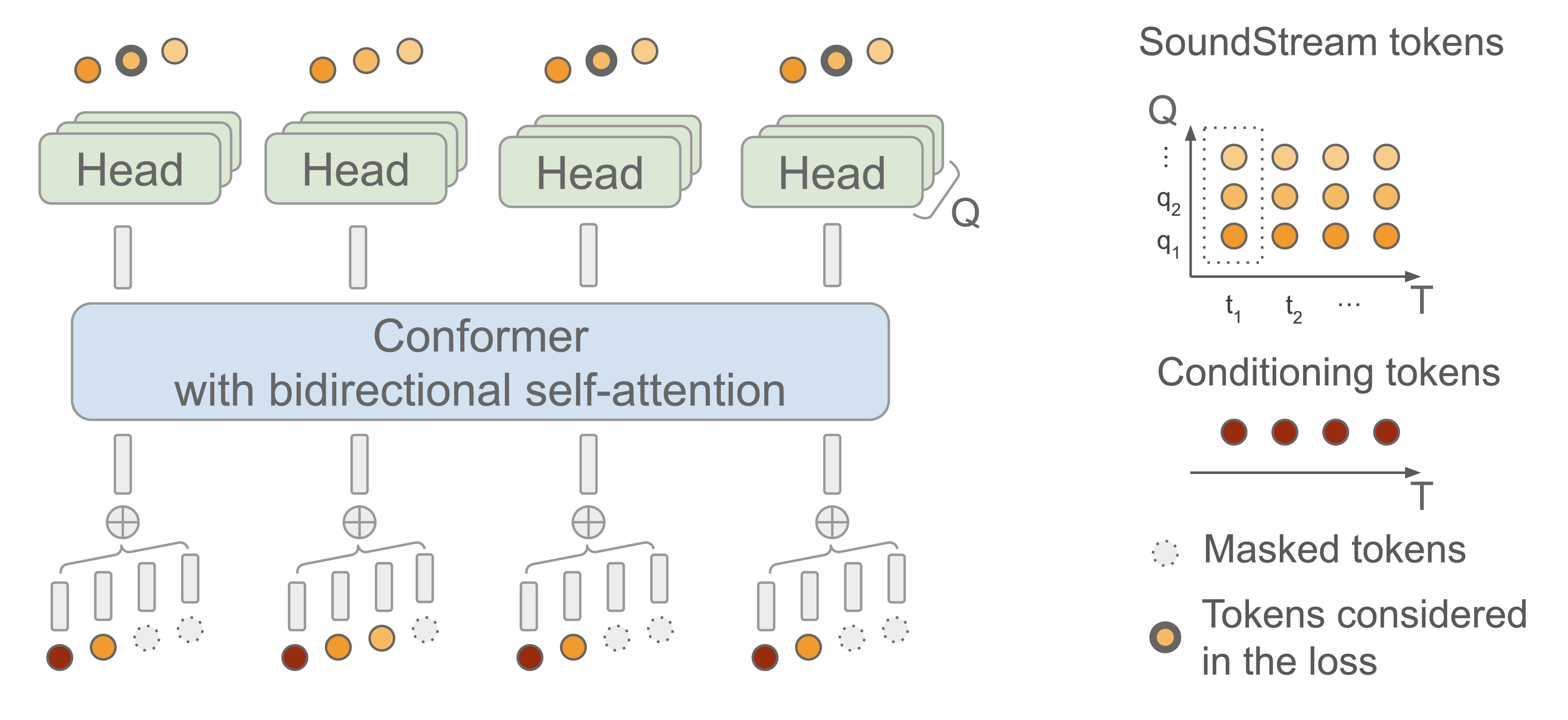
- 由Google推出,在Libri-Light数据集上训练,它包含了6w小时的多说话人语音数据
- 分块并行:把整段语音 token 按时间分成多个 “chunk”,块内部可以并行
- 块间串行:使用Causal Attention,只依赖过去信息进行Attention计算
- 多任务预测:多个FFN,进行不同任务的合成,多个指标上,效果>Bark
- 可以同时接受音频输入,适应多说话人场景,根据一段音频,和文字,续接后面的内容
📌Demo:示例音频

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)