QWen2-VL
参考:https://www.bilibili.com/video/BV1ybtBe1EkN?spm_id_from=333.788.videopod.sections&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245论文:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localiza
QWen-VL
参考:
https://www.bilibili.com/video/BV1ybtBe1EkN?spm_id_from=333.788.videopod.sections&vd_source=a671b6c09bdc87f50b8d9fbbf85c6245
论文:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
网络结构
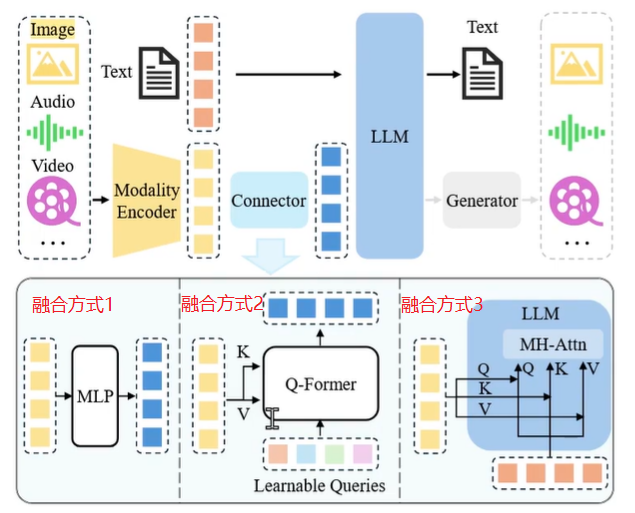
QWen2-VL
一、研究动机
1. 现有方法局限性
- 1)固定图像输入限制
- 尺度捕获不足: 传统方法将图像统一缩放填充至固定分辨率(如224×224或448×448),导致高分辨率图像细节显著丢失,无法像人类视觉系统那样感知不同尺度信息
- 长宽比失真: 强制1:1的方形处理会破坏原始图像比例,影响模型对真实场景的理解能力
- 2)静态视觉编码器依赖
- CLIP风格限制: 多数多模态模型使用冻结的 CLIP视觉编码器,其生成的视觉token数量可能不足以处理复杂推理任务
- 微调局限性: 虽然部分工作通过微调视觉编码器缓解此问题,但无法从根本上解决多尺度适应性问题
- 3)视频理解能力缺失
- 三维建模缺陷: 标准一维位置嵌入无法有效建模视频的时空三维关系(高度、宽度、时间)
- 扩展研究不足: 多模态大模型在数据和模型规模扩展方面的性能变化规律尚未充分探索
2. 解决思路
- 动态分辨率处理: 将不同分辨率图像动态转换为可变数量视觉token
- 多模态位置编码: 提出M-RoPE将位置信息分解为时间、高度、宽度三个维度
- 统一训练策略: 混合图像和视频数据进行联合训练
二、Qwen2-VL技术亮点
1. 多分辨率理解能力
- 先进基准表现: 在DocVQA、InfoVQA、WordQA、MathVQA等视觉基准测试中达到领先水平
- 动态适应能力: 支持任意分辨率和长宽比输入,保持原始图像比例不变
2. 多模态Agent能力
- 交互操作支持: 具备操作手机UI界面和控制机器人的功能调用能力
- 长视频理解: 可处理超过20分钟的视频内容,支持高质量问答和内容创作
3. 多语言支持能力
语言覆盖范围: 支持英语、中文、欧洲语言、日语、韩语、阿拉伯语、越南语等图文理解
全球化适配: 专门优化多语言上下文理解能力服务全球用户
4. 72B模型性能表现
对标顶尖模型: 72B版本在多模态基准测试中与GPT-4o、Claude3.5-Sonnet表现相当
开源策略: 开源2B/7B模型,提供72B版本API服务
三、Qwen2-VL主体结构
-
- 模型架构概述
参数配置: 采用675M参数的ViT视觉编码器,保持与语言模型规模无关的计算负荷
框架继承: 延续Qwen-VL框架,但升级语言模型主干为更强大的Qwen2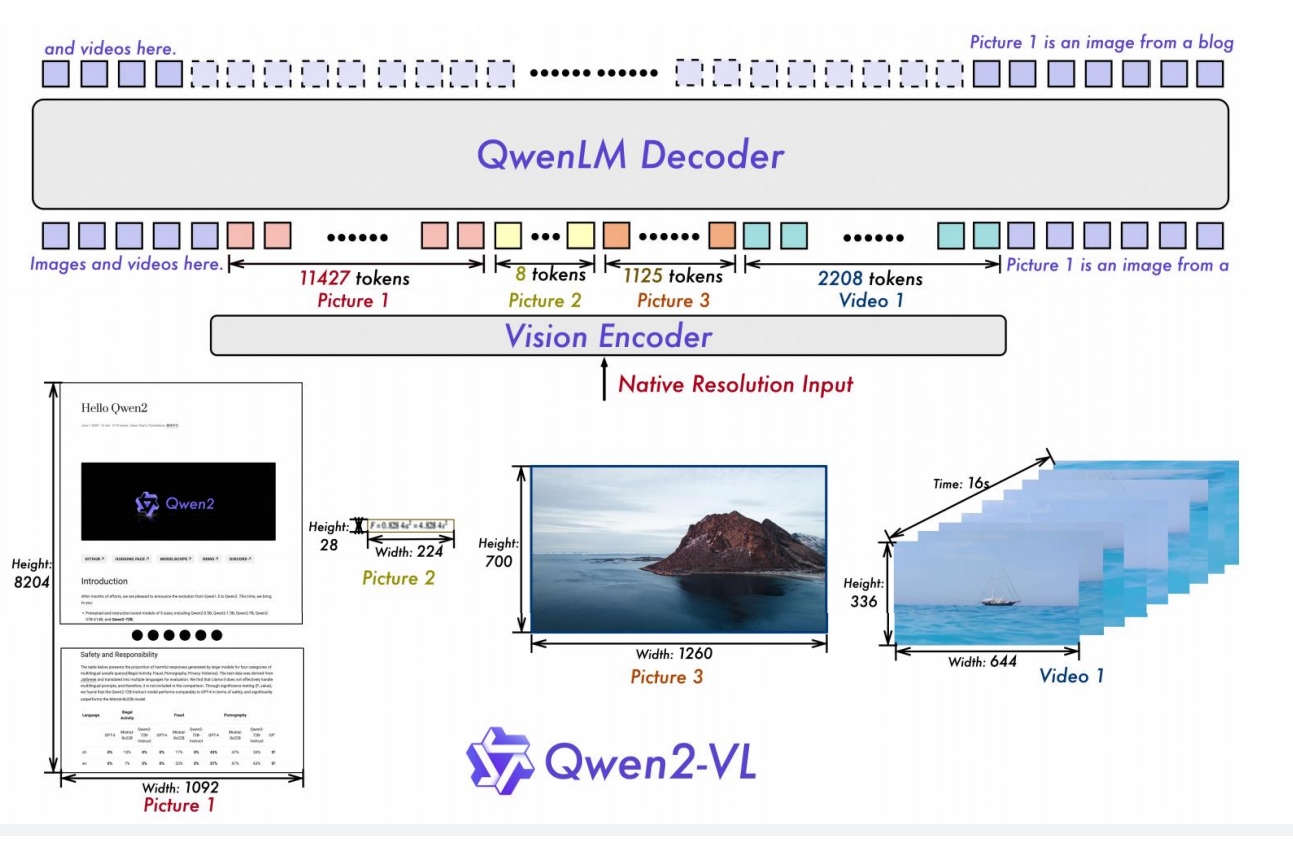
- 模型架构概述
-
- 原始动态分辨率
- 1)NaViT实现
- 核心修改: 移除ViT绝对位置嵌入,采用获取二维位置信息
- 智能缩放: 图像处理需满足三个条件:(1)长宽能被factor整除 (2)总像素在范围内 (3)尽量保持原始长宽比
- 批量训练优化: 借鉴语言模型思路,将不同图像patch打包到同一训练序列,显著提升效率
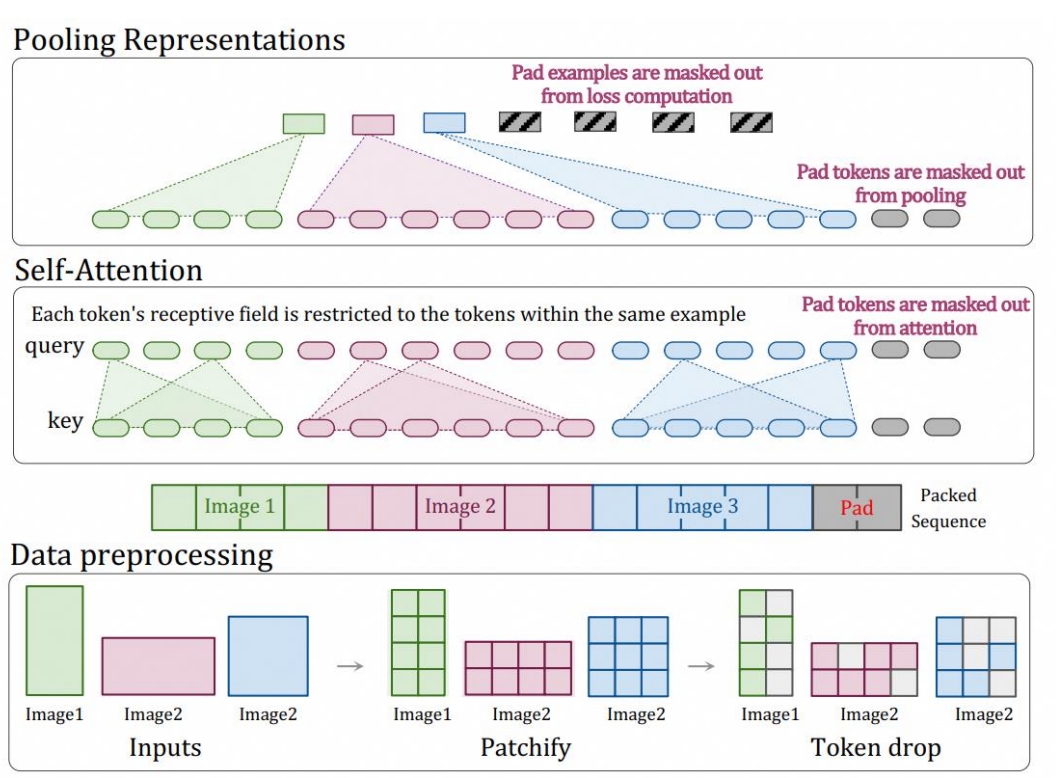
- 2)Token压缩机制
- 降维处理: 使用MLP层将相邻2×2的视觉token压缩为单个token
- 标记设计: 在压缩后的视觉token序列首尾添加特殊[vision_start]和[vision_end]标记
-
- 多模态旋转位置嵌入
- 1)三维位置编码

- 组件分解: 将位置信息分解为时间、高度、宽度三个维度(如三元组)
- 文本处理: 文本token三个维度使用相同ID,保持与一维RoPE的功能等价性
- 跨模态衔接: 新模态的起始位置ID为前一模态最大ID+1(如视频最大ID=3则文本从4开始)
- 2)视频模态处理
- 时间维度扩展: 视频帧时间ID逐帧递增(0,1,2…),同帧内token时间ID相同
- 空间保持机制: 单帧内高度/宽度ID分配方式与静态图像完全一致
- 外推优势: 基于相对位置编码的特性,支持推理时处理更长序列
-
- 统一训练策略
-
1)3D卷积处理
- 时空压缩: 使用kernel_size为[2,14,14]的3D卷积,在时间维度压缩为原长度1/2
- 图像适配: 静态图像被视为两帧相同画面输入,保持处理一致性
-
2)动态分辨率调整
- 计算优化: 将每个视频token总数限制在16384,平衡长视频处理与训练效率
- 灵活采样: 动态调整视频帧分辨率,避免固定分辨率带来的信息损失
四、Qwen2-VL训练流程
-
- 三阶段训练
- 1)视觉文本对齐
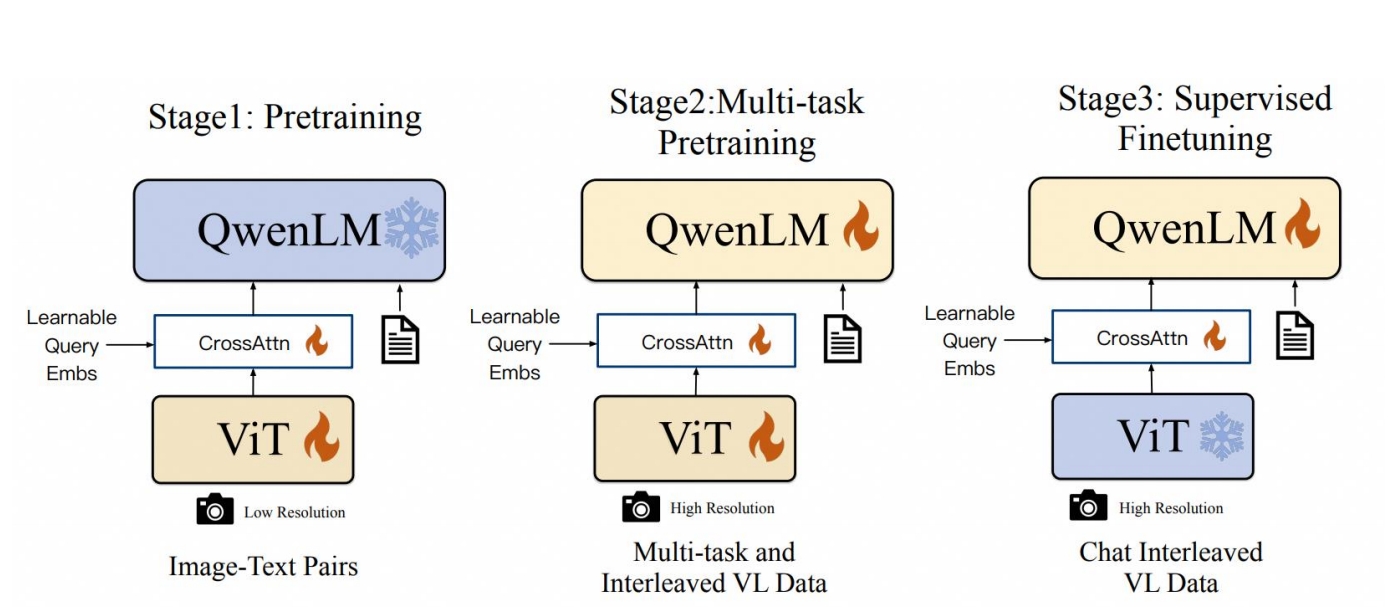
- 训练目标:专注于视觉编码器训练,实现视觉特征与文本特征对齐
- 数据规模:处理约6000亿个Token(包含文本和图像Token)
- 核心任务:
- OCR任务:建立视觉文本相关性理解
- 图像分类:强化基础视觉特征提取能力
- 训练特点:仅对文本Token提供监督信号,使用大量图文对照数据
- 2)多任务预训练
- 训练目标:解冻所有参数,提升视觉与语言信息的交互理解
- 数据扩展:新增8000亿Token的混合图文数据(总量达1.4万亿)
- 任务扩展:
- 视觉问答:增强图像问题应答能力
- 纯文本生成:维持语言模型基础能力
- 关键优势:多任务数据集整合显著提升模型在复杂现实场景的泛化能力
- 3)指令微调阶段
- 训练策略:冻结视觉编码器参数,仅训练输入投影与大模型主干
- 数据组成:
纯文本对话数据
多模态对话数据(含图像问答/文档解析/多图对比/视频理解等)
能力培养:通过多样化任务增强模型处理复杂多模态交互的鲁棒性
五. 消融实验
- 1)动态分辨率验证
- 鲁棒性验证:调整图像尺寸仅引起小幅度性能波动(±3%) ,固定576 tokens时,RealWorldQA得分65.88,动态策略达70.07
- 效率优势:动态分辨率平均消耗1924 tokens,低于固定3136 tokens方案
OCRBench任务中动态策略保持866分,优于固定3136 tokens的786分 - 分辨率选择原则:感知任务(如InfoVQA)随分辨率提升至75.89分,OCR任务过度放大(min_pixels过高)会导致性能下降30%+
合理范围:560×560至840×840像素表现最佳
- 2)M-RoPE有效性
- 视频任务优势:PerceptionTest得分47.4,优于1D-RoPE的46.6 ,NextQA视频理解提升2.1分(46.0 vs 43.9)
- 长度外推能力:训练时最大16K tokens,推理时80K tokens仍保持稳定性能。Video-MME Medium测试中,推理长度超训练长度4倍时准确率仅下降1.7%
- 3)模型规模影响
- 规模效应:数学能力提升最显著:72B模型比7B提升25.3分。OCR任务小模型表现强劲:7B模型DocVQA已达82.5分
- 训练数据量影响:
文本图形理解任务随token量线性增长(相关系数0.92)。VQA任务在400B tokens后出现±3%波动 - 最佳平衡点:72B参数+600B训练tokens组合

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)